5.ResNet
ResNet的主要特点是采用了残差学习机制。在传统的神经网络中,每一层的输出都是直接通过一个非线性激活函数得到的。但在ResNet中,每一层的输出是通过一个"残差块"得到的,该残差块包含了一个快捷连接(shortcut)和几个卷积层。这样,在训练过程中,每一层只需要学习残差(即输入与输出之间的差异),而不是所有的信息。这有助于防止梯度消失和梯度爆炸的问题,从而使得网络能够训练得更深。
ResNet的网络结构相对简单,并且它的训练速度也比GoogLeNet快。这使得ResNet成为了在许多计算机视觉任务中的首选模型。
ResNet的主要优点是具有非常深的层数,可以达到1000多层,但仍然能够高效地训练。这是通过使用残差连接来实现的,这种连接允许模型学习跨越多个层的残差,而不是直接学习每一层的输出。这使得ResNet能够更快地收敛,并且能够更好地泛化到新的数据集,ResNet论文中共提出了五种结构,分别是ResNet-18,ResNet-34,ResNet-50,ResNet-101,ResNet-152。
论文名称:Deep Residual Learning for Image Recognition
论文地址:https://arxiv.org/abs/1512.03385
- 网络的结构
在paper中给出了网络结构的表,如下图所示:
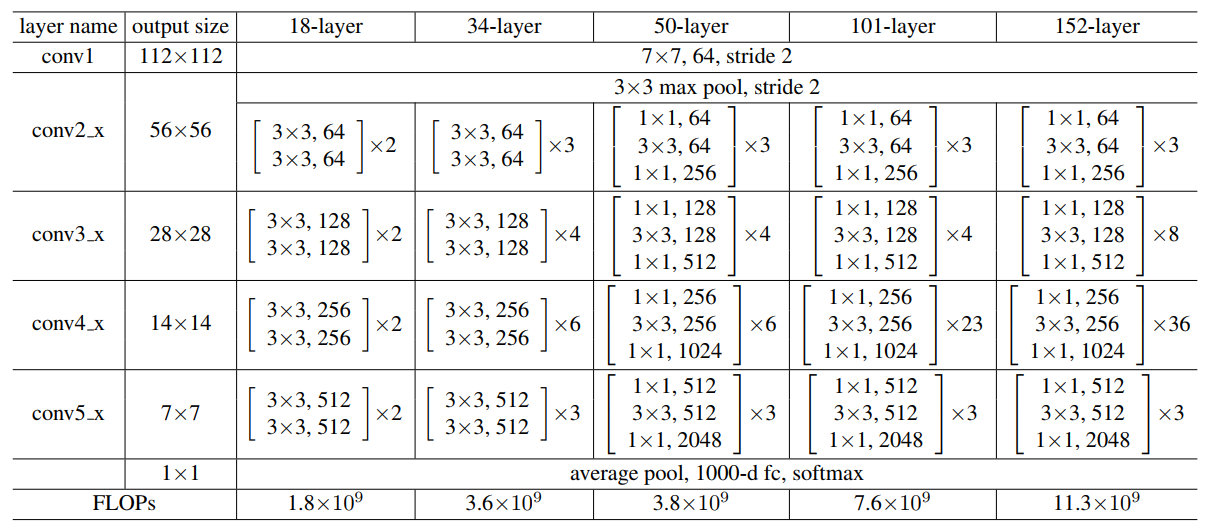
残差连接的34 层网络结构图

- 网络的创新
2.1 残差结构解决更深的网络层数带来的问题
2.1.1更深的网络层数带来的问题?
如果想要搭建一个更深的网络,是不是可以类似于它们那样直接进行卷积和池化的堆叠呢?
答案是否定的,直接的堆叠网络错误率如下图所示:
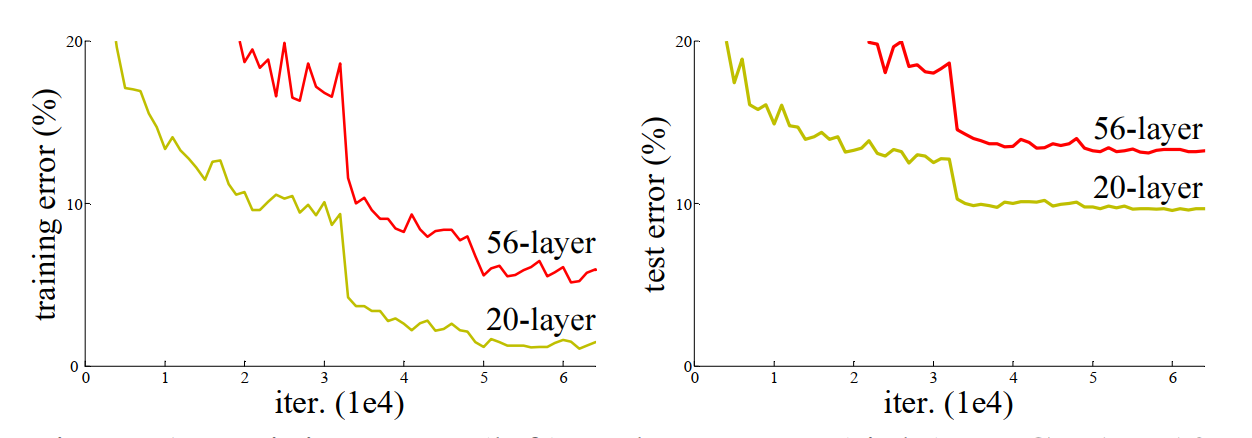
上图都是直接堆叠神经网络的结果,在左侧图中,黄色线是训练过程中20层网络的训练损失曲线,红色线是训练过程中56层网络的训练损失曲线,理论上讲,网络深可以带来更小的损失,但是实时恰恰相反,56层的错误率要高于20层的错误率。
发生这种情况的原因是什么呢?
1.梯度消失或梯度爆炸:
梯度消失:例如在一个网络中,每一层的损失梯度的值都小于1,那么连续的链式法则之下,每向前传播一次,都要乘以一个小于1的误差梯度,那么如果网络越深,在经过非常多的前向传播次数之后,那么梯度越来越小,直到接近于0,这就是梯度消失。
梯度爆炸:如果每一层的损失梯度的值都大于1,那么网络越深,在经过非常多的前向传播次数之后,那么梯度越来越大,导致梯度爆炸。
误差梯度不会始终为 1 或接近 1,所以一般通过数据标准化处理,权重初始化等操作进行抑制,但网络太深依然很难很好的抑制,当然Relu也可以抑制梯度消失问题,但是Relu可能会导致原始特征不可逆损失,引出另一个问题,即网络退化问题。
2.degradation problem:直译就是退化问题:随着网络层数的增多,训练集loss逐渐下降,然后趋于饱和,当再增加网络深度,训练集loss反而会增大。注意这并不是过拟合,因为在过拟合中训练loss是一直减小的。
2.1.2 Residual结构(残差结构)
2.1.2.1残差结构效果
当时用残差结构进行网络组合时,可以很明显的解决这个问题,如下图所示:
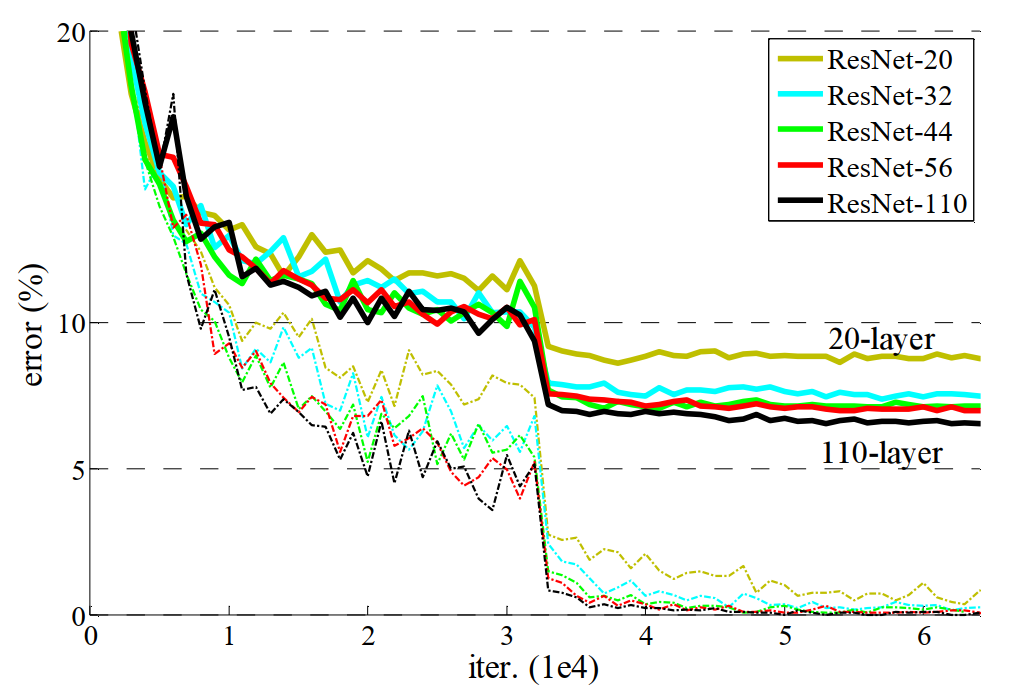
根据上图可以看出,在使用残差结构后,从20层,到110层,错误率都是逐步在降低,残差网络对degradation problem是有抑制作用的。在使用残差网络之后,模型内部的复杂度降低,所以抑制了退化问题。
2.1.2.2 残差结构
ResNet网络两种不同的残差结构
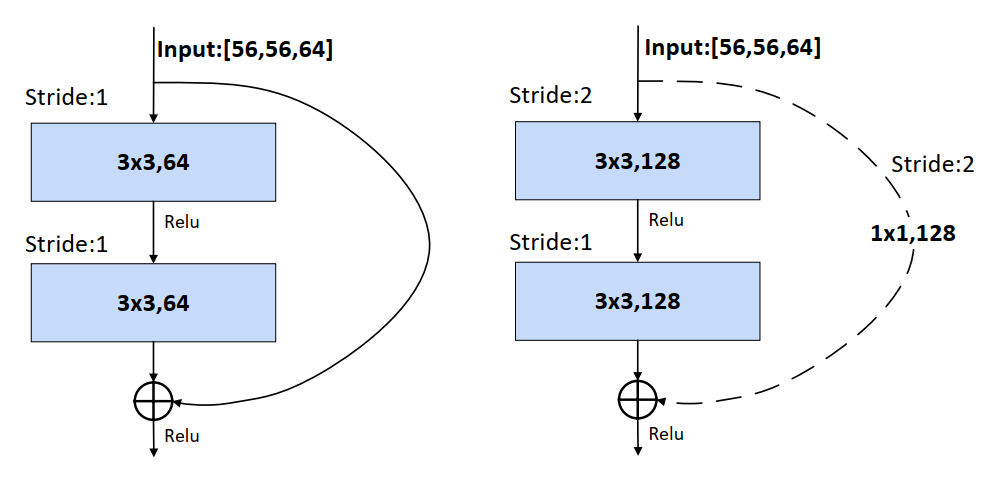
Residual结构是残差结构,有两种不同的残差结构,在ResNet-18和ResNet-34中,用的是如下图中左侧图的结构,在ResNet-50、ResNet-101和ResNet-152中,用的是下图中右侧图的结构。
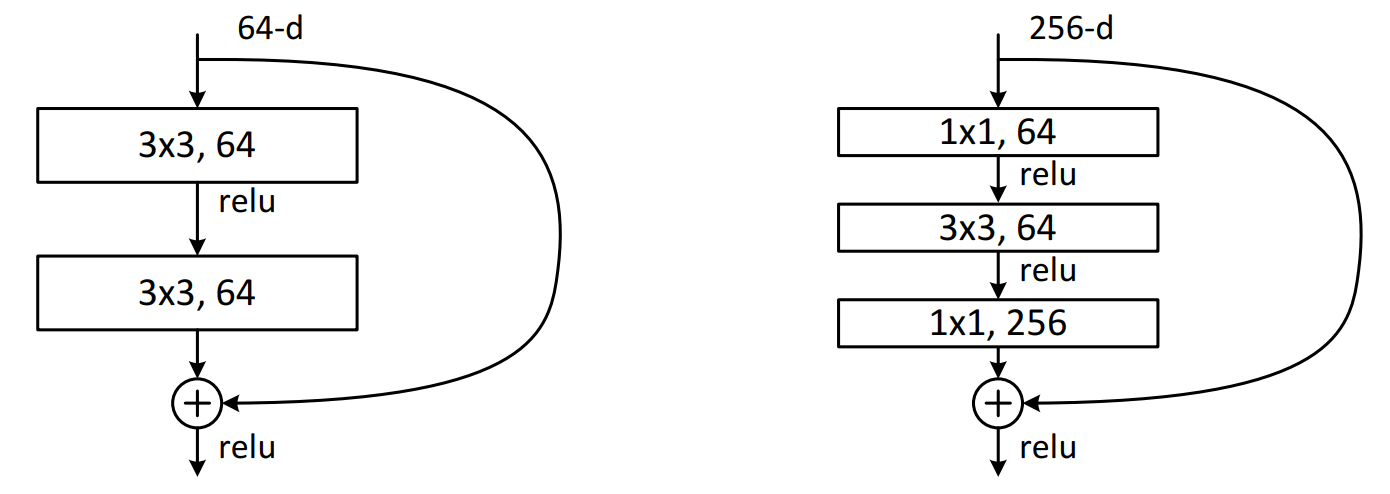
在上图左侧图可以看到输入特征矩阵的channels是64,经过一个3x3的卷积核卷积之后,再进行Relu激活函数的激活,再经过一个3x3的卷积核进行卷积,但是在这之后并没有直接经过激活函数进行激活。并且可以看到,在主分支上有一个圆弧的线从输入特征矩阵直接连到了一个加号,这个圆弧的线是shortcut(捷径分支),它直接将输入特征矩阵加到经过第二次3x3的卷积核卷积之后的输出特征矩阵,注意,这里描述的是加,而不是叠加或者拼接,也就是说是矩阵对应维度位置进行一个和法运算,意味着主分支的输出矩阵和shortcut的输出矩阵的shape必须相同,这里包括宽、高、channels,在相加之后,再经过Relu激活函数进行激活。
在上图右侧图可以看到输入特征矩阵的channels是256,要先经过一个1x1的卷积,之前在GoogLeNet提到过,1x1的卷积是为了维度变换,所以这里也是先用1x1的卷积进行降维到64,然后再使用3x3的卷积进行特征提取,提取完成后,在通过1x1的卷积进行升维到256,之后得到的输出矩阵再和经过shortcut的输入矩阵进行对应维度位置的加法运算,在相加之后,再经过Relu激活函数进行激活。
34层的网络残差结构图如下所示:
上图中残差网络部分也就是shortcut有实线和虚线之分。
实线部分就是之前讲的普通的shortcut,如下图左侧图,从左侧图可以看到,当主分支的输入特征矩阵和输出特征矩阵的shape一致时,输入特征矩阵可以经过shortcut得到输出特征矩阵直接与主分支的输出特征矩阵进行加法运算.
虚线部分不仅仅有channels变化,还有特征矩阵的宽和高变化,虚线部分有一个处理(需要进行下采样 (downsampling),所谓下采样,也就是通过卷积,缩小图片)来让主分支的输出特征矩阵和shortcut的输出特征矩阵保持一致。如下图右侧图。
右侧图主分支上由于步长=2,导致矩阵的宽和高都减半了,同时由于第一个卷积核的个数是128,导致channels从64升到了128,从而channels也不一样了,所以主分支的输出特征矩阵是28,28,128,那么如果将shortcut分支上加一个卷积运算,卷积核个数为128,步长为2,那么经过shortcut分支的输出矩阵也同样为28,28,128,那么两个输出矩阵又可以进行相加了。
为什么残差结构能够抑制degradation problem问题呢?

导数很小的情况下,那么会对网络起不到更新的作用,但是由于加入了输入矩阵的导数,也就保证了网络导数会一直存在,而不会出现导数消失的情况。
简而言之,ResNet网络中的残差结构的堆叠有点这类似下面这个过程:
刚开始的前几个残差结构提取了很重要的一些特征,后几个残差结构负责把一些特征进行细化,如果后几个残差结构学不到东西,但是并不会影响前面的梯度从而造成degradation problem退化问题。
2.2 Batch Normalization
2.2.1概念:
对一个batch 内的数据在通道 尺度上计算均值 和方差,将同批次同通道的数据归一化为均值为0、方差为1的正态分布。
2.2.2 Batch Normalization 为什么要这样做?
一个神经网络在输入图像之前,会将图像进行预处理,这个预处理可能是标准化处理等手段,由于输入数据满足某一分布规律,所以会加速网络的收敛。
虽然在输入第一次卷积的时候满足某一分布规律,但是在输入第二次卷积时,就不一定满足某一分布规律了,再往后的卷积的输入就更不满足了,那么就需要一个中间商,让上一层的输出经过它之后能够某一分布规律,Batch Normalization就是这个中间商,它可以让输入的特征矩阵的每一个channels满足均值为0,方差为1的分布规律。


举例:
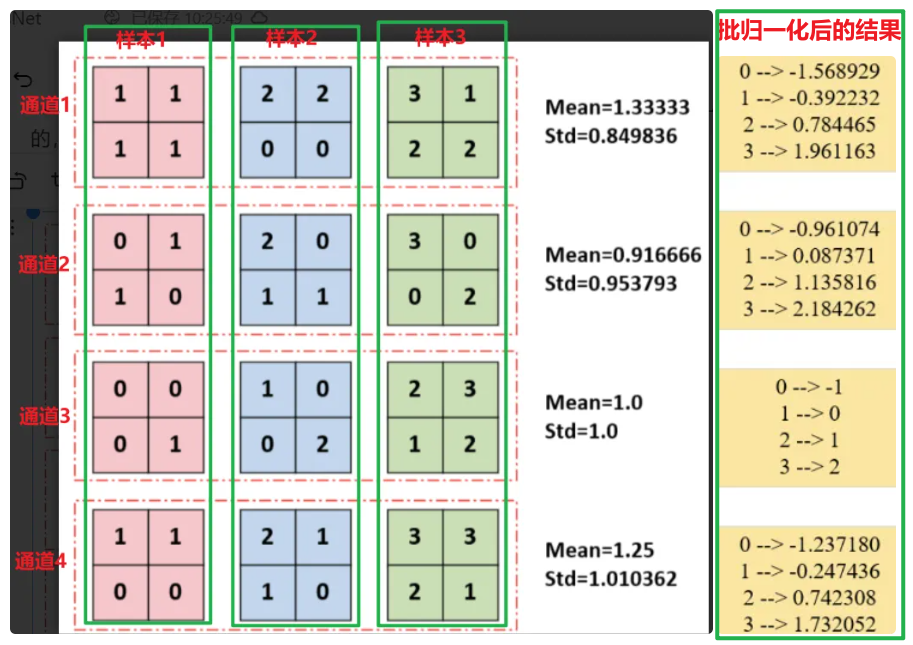
上图展示了大小为3,4,2,2的tensor(批次大小为3,通道数为4,高为2,宽为2)的BatchNorm过程,该过程是针对训练数据的且无缩放和平移。可以看出,BatchNorm是对同一批次内同一通道的所有数据进行归一化。
2.2.3 Batch Normalization 的好处
Batch Normalization对解决梯度消失或者梯度爆炸的抑制起到了作用。
归一化也可以理解成规则化,让数据符合某些特征,这样模型训练时更容易掌握规律
3. 网络的问题
由于ResNet的结构非常复杂,所以它的训练时间比较长。此外,由于它具有非常深的层数,因此它需要大量的数据来进行训练。
4 结构组件介绍
下面结合虚拟仿真的组件,搭建ResNet的网络结构。
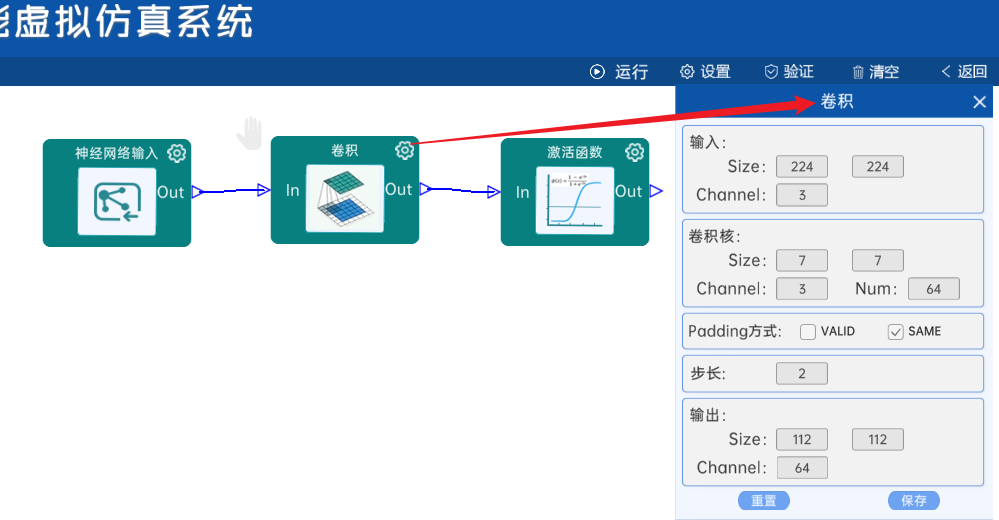
4.1 卷积
输入特征矩阵是(224 x 224 x 3),本层卷积核的宽、高、通道、个数是(7 x 7 x 3 x 64),步长为2,padding方式为SAME,经过计算可知,输出特征矩阵为(112 x 112 x 64)。
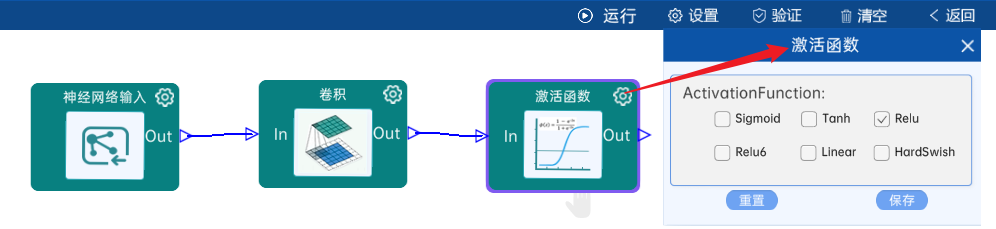
本层之后要经过batchNorm进行归一化,以及ReLU激活函数,如下图:
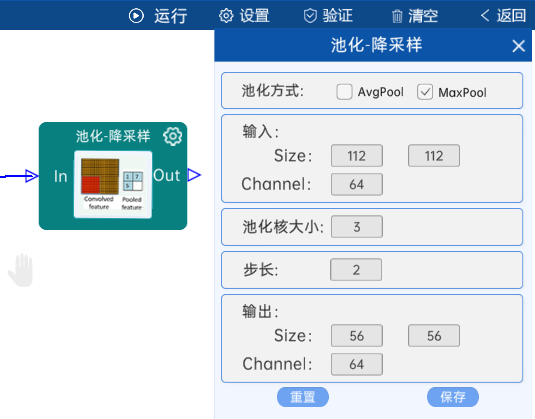
4.2 池化-降采样
池化方式为MaxPool,输入特征矩阵是(112 x 112 x 64),池化核大小为3,步长为2,经过计算可知,输出特征矩阵为(56 x 56 x 64),如下图:
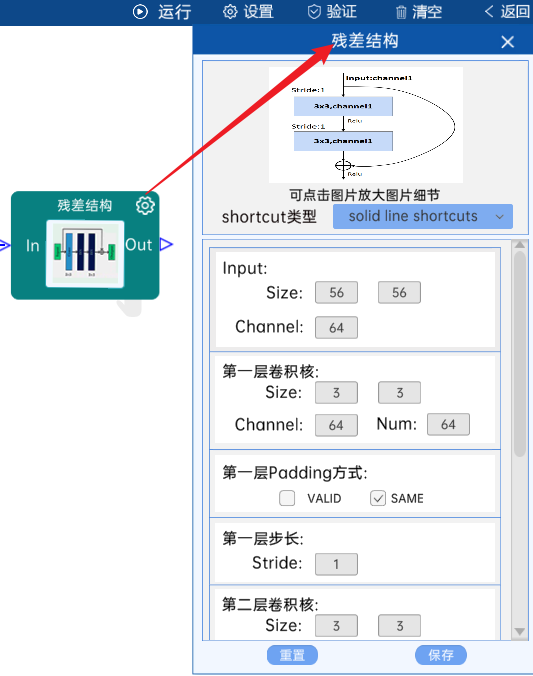
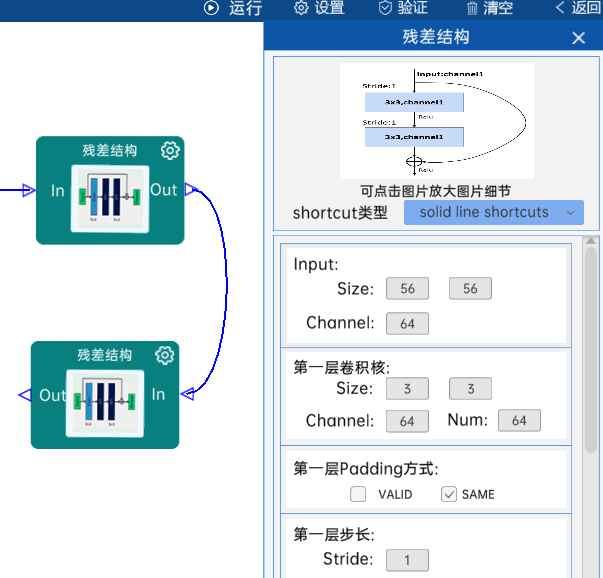
4.3 残差结构
shortcut类型是solid line shortcuts。
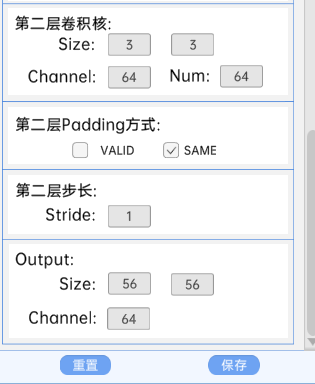
输入特征矩阵是(56 x 56 x 64),第一层卷积核的宽、高、通道、个数是(3 x 3 x 64 x 64),步长为1,padding方式为SAME。
第二层卷积核的宽、高、通道、个数是(3 x 3 x 64 x 64),步长为1,padding方式为SAME。
经过计算可知,输出特征矩阵为(56 x 56 x 64)。
每一卷积层之后要经过batchNorm进行归一化,以及ReLU激活函数,如下图:
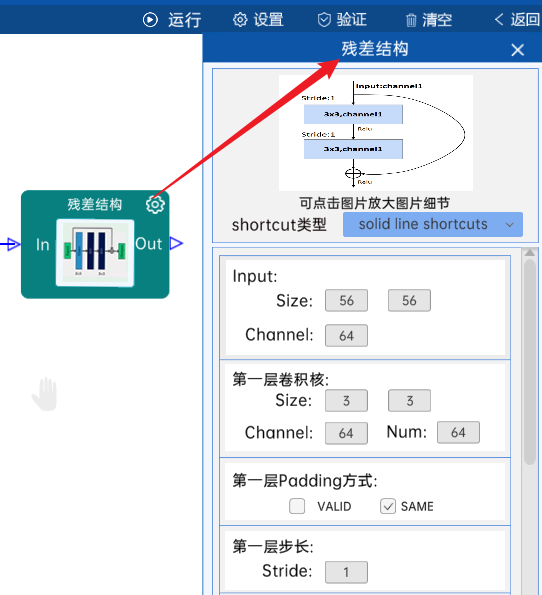
4.4 残差结构
shortcut类型是solid line shortcuts。
输入特征矩阵是(56 x 56 x 64),第一层卷积核的宽、高、通道、个数是(3 x 3 x 64 x 64),步长为1,padding方式为SAME。
第二层卷积核的宽、高、通道、个数是(3 x 3 x 64 x 64),步长为1,padding方式为SAME。
经过计算可知,输出特征矩阵为(56 x 56 x 64)。
每一卷积层之后要经过batchNorm进行归一化,以及ReLU激活函数,如下图:
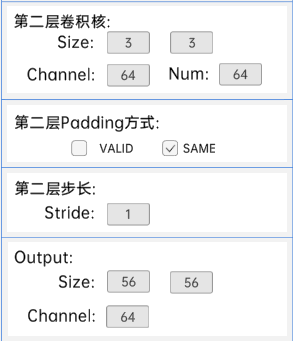
4.5 残差结构
shortcut类型是solid line shortcuts。
输入特征矩阵是(56 x 56 x 64),第一层卷积核的宽、高、通道、个数是(3 x 3 x 64 x 64),步长为1,padding方式为SAME。
第二层卷积核的宽、高、通道、个数是(3 x 3 x 64 x 64),步长为1,padding方式为SAME。
经过计算可知,输出特征矩阵为(56 x 56 x 64)。
每一卷积层之后要经过batchNorm进行归一化,以及ReLU激活函数,如下图:
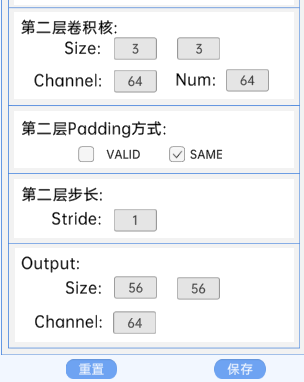
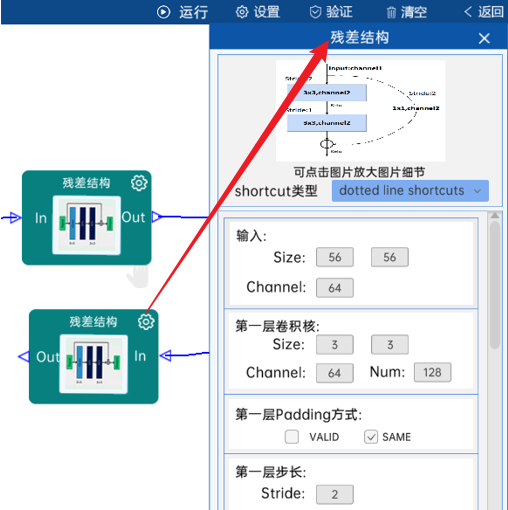
4.6 残差结构
shortcut类型是dotted line shortcuts。
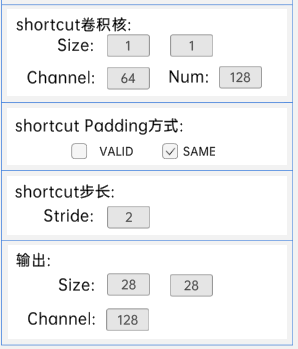
输入特征矩阵是(56 x 56 x 64),第一层卷积核的宽、高、通道、个数是(3 x 3 x 64 x 128),步长为2,padding方式为SAME。
第二层卷积核的宽、高、通道、个数是(3 x 3 x 128 x 128),步长为1,padding方式为SAME。
shortcut的宽、高、通道、个数是(1 x 1 x 64 x 128),步长为2,padding方式为SAME。
经过计算可知,输出特征矩阵为(28 x 28 x 128)。
每一卷积层之后要经过batchNorm进行归一化,以及ReLU激活函数,如下图:
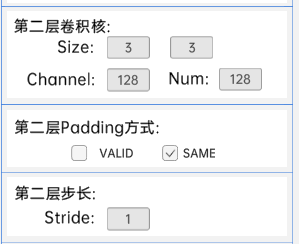
4.7 残差结构
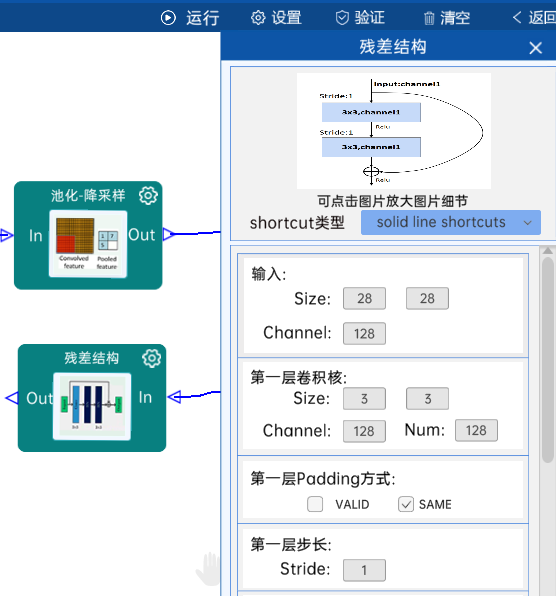
shortcut类型是solid line shortcuts。
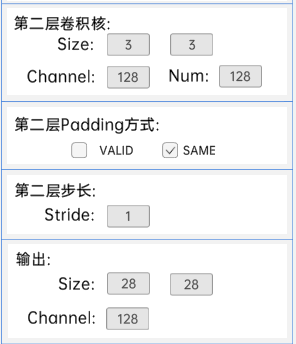
输入特征矩阵是(28 x 28 x 128),第一层卷积核的宽、高、通道、个数是(3 x 3 x 128 x 128),步长为1,padding方式为SAME。
第二层卷积核的宽、高、通道、个数是(3 x 3 x 128 x 128),步长为1,padding方式为SAME。
经过计算可知,输出特征矩阵为(28 x 28 x 128)。
每一卷积层之后要经过batchNorm进行归一化,以及ReLU激活函数,如下图:
4.8 残差结构
shortcut类型是solid line shortcuts。
输入特征矩阵是(28 x 28 x 128),第一层卷积核的宽、高、通道、个数是(3 x 3 x 128 x 128),步长为1,padding方式为SAME。
第二层卷积核的宽、高、通道、个数是(3 x 3 x 128 x 128),步长为1,padding方式为SAME。
经过计算可知,输出特征矩阵为(28 x 28 x 128)。
每一卷积层之后要经过batchNorm进行归一化,以及ReLU激活函数,如下图:
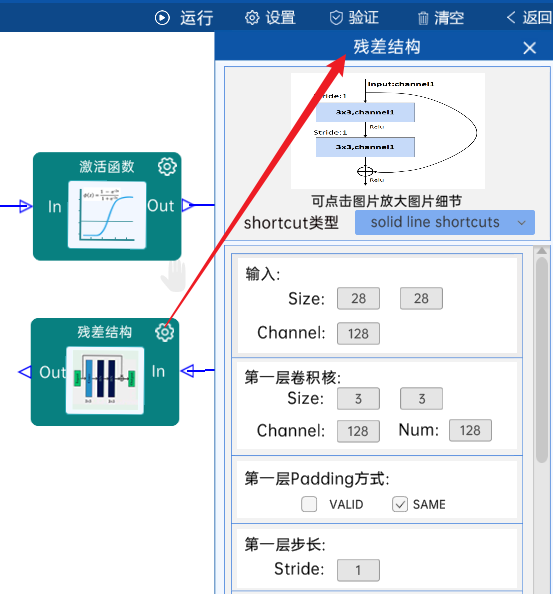
4.9 残差结构
shortcut类型是solid line shortcuts。
输入特征矩阵是(28 x 28 x 128),第一层卷积核的宽、高、通道、个数是(3 x 3 x 128 x 128),步长为1,padding方式为SAME。
第二层卷积核的宽、高、通道、个数是(3 x 3 x 128 x 128),步长为1,padding方式为SAME。
经过计算可知,输出特征矩阵为(28 x 28 x 128)。
每一卷积层之后要经过batchNorm进行归一化,以及ReLU激活函数,如下图:
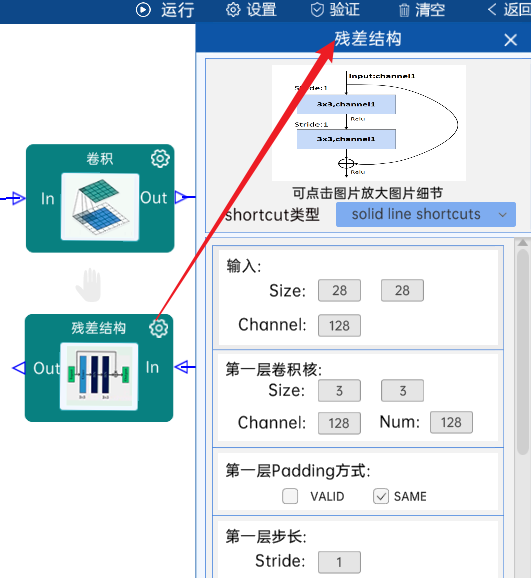
4.10 残差结构
shortcut类型是dotted line shortcuts。
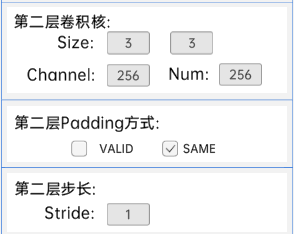
输入特征矩阵是(28 x 28 x 128),第一层卷积核的宽、高、通道、个数是(3 x 3 x 128 x 256),步长为2,padding方式为SAME。
第二层卷积核的宽、高、通道、个数是(3 x 3 x 256 x 256),步长为1,padding方式为SAME。
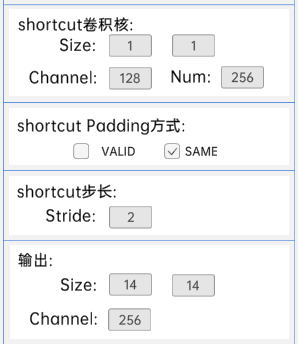
shortcut的宽、高、通道、个数是(1 x 1 x 128 x 256),步长为2,padding方式为SAME。
经过计算可知,输出特征矩阵为(14 x 14 x 256)。
每一卷积层之后要经过batchNorm进行归一化,以及ReLU激活函数,如下图:
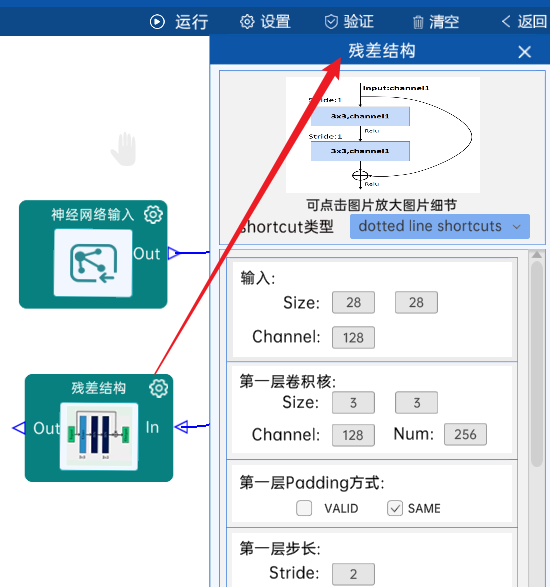
4.11 残差结构
shortcut类型是solid line shortcuts。
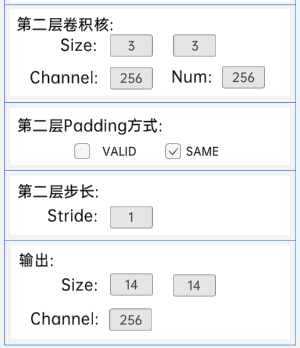
输入特征矩阵是(14 x 14 x 256),第一层卷积核的宽、高、通道、个数是(3 x 3 x 256 x 256),步长为1,padding方式为SAME。
第二层卷积核的宽、高、通道、个数是(3 x 3 x 256 x 256),步长为1,padding方式为SAME。
经过计算可知,输出特征矩阵为(14 x 14 x 256)。
每一卷积层之后要经过batchNorm进行归一化,以及ReLU激活函数,如下图:
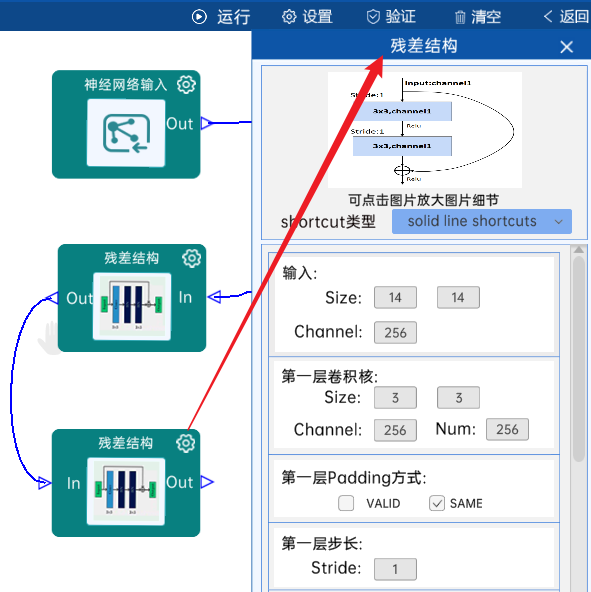
4.12 残差结构
shortcut类型是solid line shortcuts。
输入特征矩阵是(14 x 14 x 256),第一层卷积核的宽、高、通道、个数是(3 x 3 x 256 x 256),步长为1,padding方式为SAME。
第二层卷积核的宽、高、通道、个数是(3 x 3 x 256 x 256),步长为1,padding方式为SAME。
经过计算可知,输出特征矩阵为(14 x 14 x 256)。
每一卷积层之后要经过batchNorm进行归一化,以及ReLU激活函数,如下图:
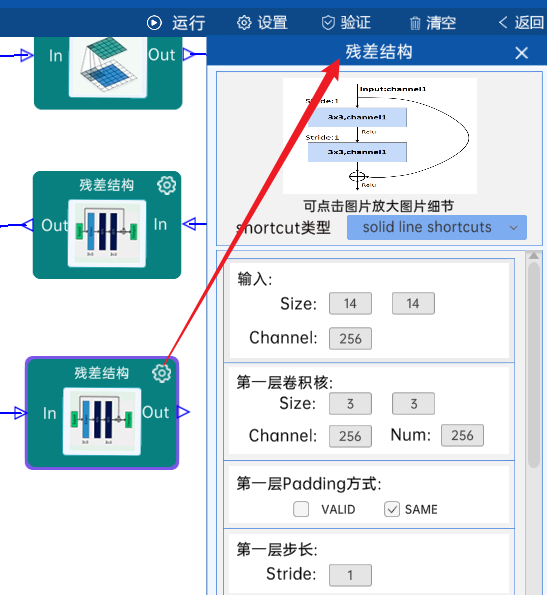
4.13 残差结构
shortcut类型是solid line shortcuts。
输入特征矩阵是(14 x 14 x 256),第一层卷积核的宽、高、通道、个数是(3 x 3 x 256 x 256),步长为1,padding方式为SAME。
第二层卷积核的宽、高、通道、个数是(3 x 3 x 256 x 256),步长为1,padding方式为SAME。
经过计算可知,输出特征矩阵为(14 x 14 x 256)。
每一卷积层之后要经过batchNorm进行归一化,以及ReLU激活函数,如下图:
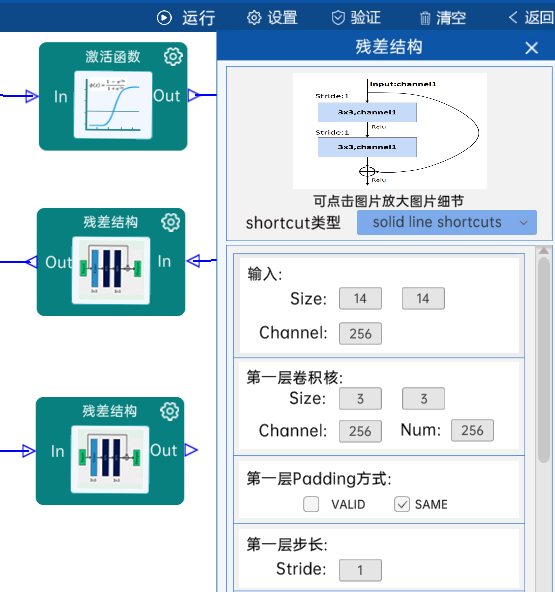
4.14 残差结构
shortcut类型是solid line shortcuts。
输入特征矩阵是(14 x 14 x 256),第一层卷积核的宽、高、通道、个数是(3 x 3 x 256 x 256),步长为1,padding方式为SAME。
第二层卷积核的宽、高、通道、个数是(3 x 3 x 256 x 256),步长为1,padding方式为SAME。
经过计算可知,输出特征矩阵为(14 x 14 x 256)。
每一卷积层之后要经过batchNorm进行归一化,以及ReLU激活函数,如下图:
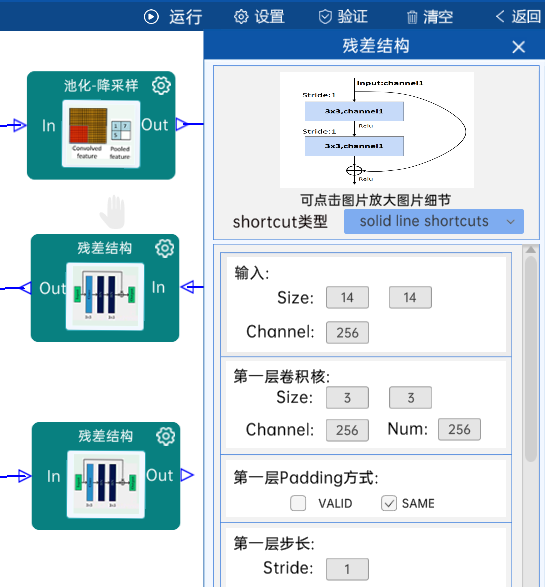
4.15 残差结构
shortcut类型是solid line shortcuts。
输入特征矩阵是(14 x 14 x 256),第一层卷积核的宽、高、通道、个数是(3 x 3 x 256 x 256),步长为1,padding方式为SAME。
第二层卷积核的宽、高、通道、个数是(3 x 3 x 256 x 256),步长为1,padding方式为SAME。
经过计算可知,输出特征矩阵为(14 x 14 x 256)。
每一卷积层之后要经过batchNorm进行归一化,以及ReLU激活函数,如下图:
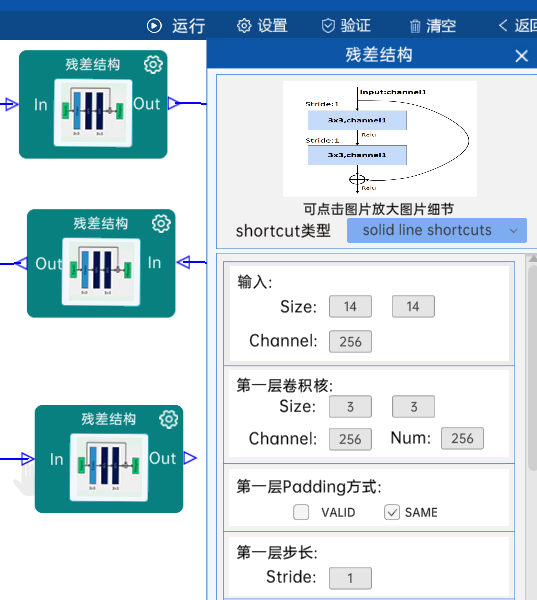
4.16 残差结构
shortcut类型是dotted line shortcuts。
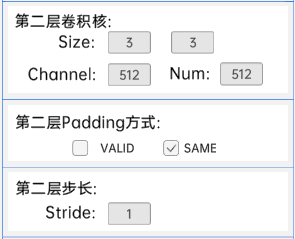
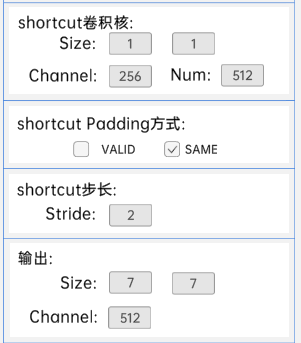
输入特征矩阵是(14 x 14 x 256),第一层卷积核的宽、高、通道、个数是(3 x 3 x 256 x 512),步长为2,padding方式为SAME。
第二层卷积核的宽、高、通道、个数是(3 x 3 x 512 x 512),步长为1,padding方式为SAME。
shortcut的宽、高、通道、个数是(1 x 1 x 256 x 512),步长为2,padding方式为SAME。
经过计算可知,输出特征矩阵为(7 x 7 x 512)。
每一卷积层之后要经过batchNorm进行归一化,以及ReLU激活函数,如下图:
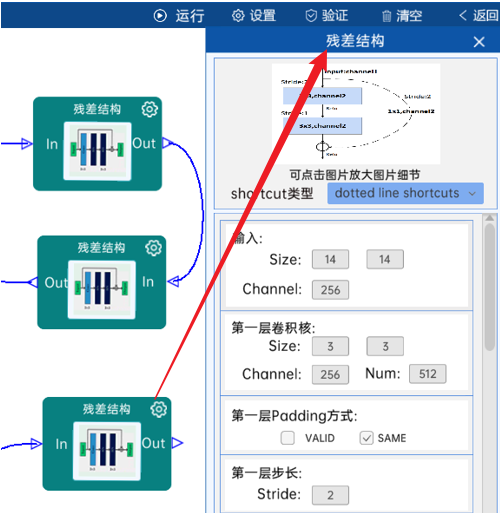
4.17 残差结构
shortcut类型是solid line shortcuts。
输入特征矩阵是(7 x 7 x 512),第一层卷积核的宽、高、通道、个数是(3 x 3 x 512 x 512),步长为1,padding方式为SAME。
第二层卷积核的宽、高、通道、个数是(3 x 3 x 512 x 512),步长为1,padding方式为SAME。
经过计算可知,输出特征矩阵为(7 x 7 x 512)。
每一卷积层之后要经过batchNorm进行归一化,以及ReLU激活函数,如下图:
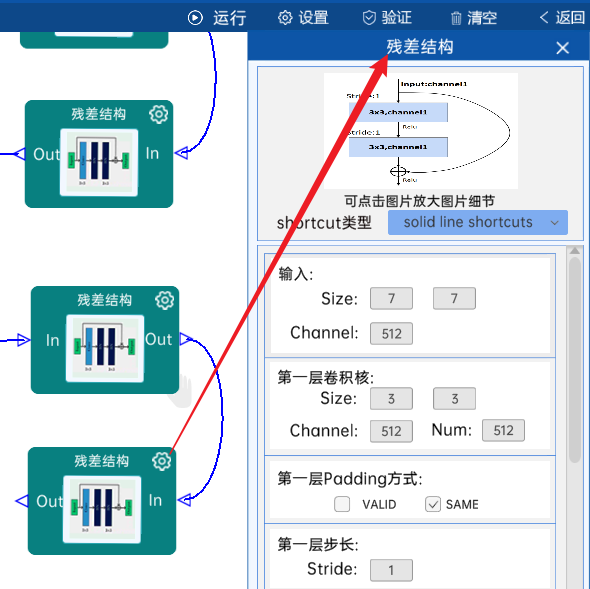
4.18 残差结构
shortcut类型是solid line shortcuts。
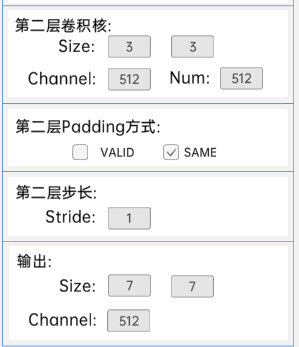
输入特征矩阵是(7 x 7 x 512),第一层卷积核的宽、高、通道、个数是(3 x 3 x 512 x 512),步长为1,padding方式为SAME。
第二层卷积核的宽、高、通道、个数是(3 x 3 x 512 x 512),步长为1,padding方式为SAME。
经过计算可知,输出特征矩阵为(7 x 7 x 512)。
每一卷积层之后要经过batchNorm进行归一化,以及ReLU激活函数,如下图:
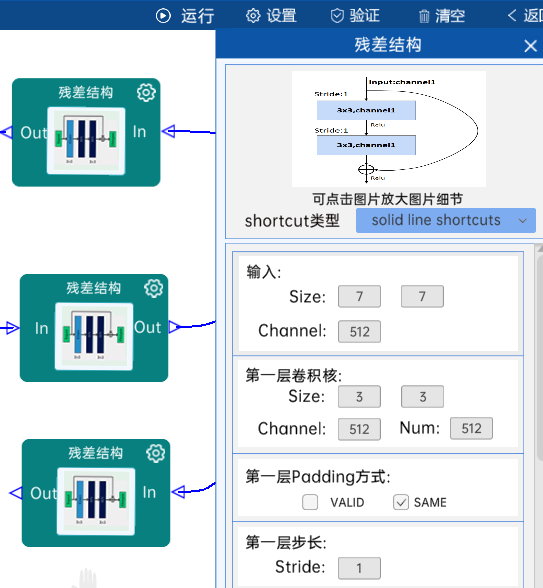
4.19 池化-降采样
池化方式为AvgPool,输入特征矩阵是(7 x 7 x 512),池化核大小为7,步长为1,经过计算可知,输出特征矩阵为(1 x 1 x 512),如下图:
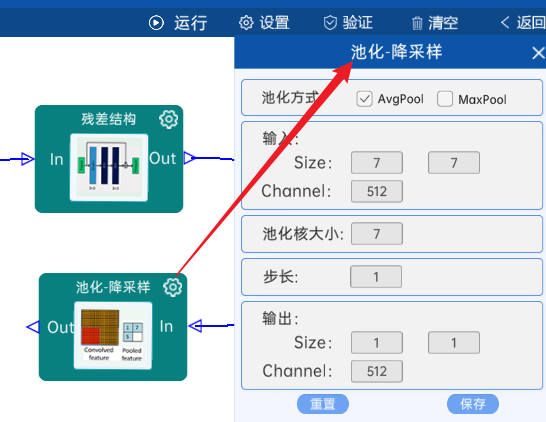
4.20 全连接
输入节点是512,paper中是按照ImageNet数据集做的,所以分类为1000类,输出节点为1000。
如下图:
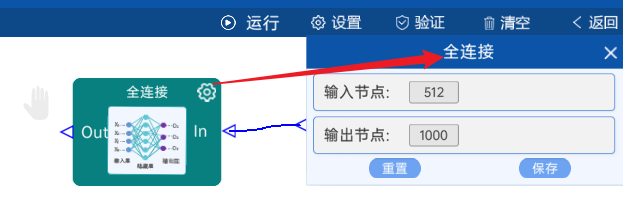
4.21 全连接Softmax
最后通过Softmax实现将多分类的输出值转换为范围在0, 1和为1的概率分布,如下图:
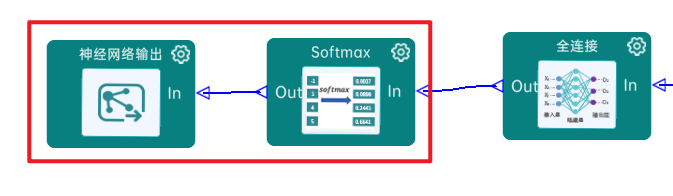
4.22实验验证
本实验主要学习resnet的网络的相关知识,最后需要进行点击"验证",验证成功即代表网络结构连接是正确的。
5.代码
5.2调用torchvision中的已经写好的resnet代码
python
from torchvision.models import resnet34
from torchsummary import summary
import torch
device =torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model=resnet34().to(device)
print(summary(model,input_size=(3,224,224)))手写代码实现
python
import torch
import torch.nn as nn
#定义BasicBlock
class BasicBlock(nn.Module):
expansion=1
def __init__(self,inplanes,planes,stride=1,downsample=None):
super(BasicBlock,self).__init__()
self.conv1=nn.Conv2d(in_channels=inplanes,out_channels=planes,kernel_size=3,stride=stride,padding=1,bias=False)
self.bn1=nn.BatchNorm2d(planes)
self.relu=nn.ReLU(inplace=True)
self.conv2=nn.Conv2d(in_channels=planes,out_channels=planes,kernel_size=3,stride=1,padding=1,bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
def forward(self,x):
identiy=x
out=self.conv1(x)
out=self.bn1(out)
out=self.relu(out)
out=self.conv2(out)
out=self.bn2(out)
if self.downsample is not None:
identiy=self.downsample(x)
out=out+identiy
out=self.relu(out)
return out
#定义bottleneck
class Bottleneck(nn.Module):
expansion=4
def __init__(self,inplanes,planes,stride=1,downsample=None):
super(Bottleneck,self).__init__()
self.conv1 = nn.Conv2d(in_channels=inplanes, out_channels=planes, kernel_size=1, stride=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(in_channels=planes, out_channels=planes, kernel_size=3, stride=stride, padding=1,bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(in_channels=planes, out_channels=planes * self.expansion, kernel_size=1, stride=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self,x):
identity=x
out=self.conv1(x)
out=self.bn1(out)
out=self.relu(out)
out=self.conv2(out)
out=self.bn2(out)
out=self.relu(out)
out=self.conv3(out)
out=self.bn3(out)
#捷径分支有两种
if self.downsample is not None:
identity=self.downsample(x)
out=out+identity
#激活
out=self.relu(out)
return out
#定义resnet类
class ResNet(nn.Module):
def __init__(self,block,layers,num_classes=1000):
super(ResNet,self).__init__()
#定义输出通道数
self.inplanes=64
#卷积
self.conv1=nn.Conv2d(in_channels=3,out_channels=self.inplanes,kernel_size=7,stride=2,padding=3,bias=False)
self.maxpool=nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
#使用bn
self.bn1=nn.BatchNorm2d(self.inplanes)
#定义激活
self.relu=nn.ReLU(inplace=True)
self.layer1=self._make_layer(block,outplanes=64,blocks=layers[0],stride=1)
self.layer2 = self._make_layer(block, outplanes=128, blocks=layers[1], stride=2)
self.layer3 = self._make_layer(block, outplanes=256, blocks=layers[2], stride=2)
self.layer4 = self._make_layer(block, outplanes=512, blocks=layers[3], stride=2)
#自适应池化
self.avgpool=nn.AdaptiveAvgPool2d((1,1))
self.fc=nn.Linear(512*block.expansion,num_classes)
def _make_layer(self,block,outplanes,blocks,stride=1):
#考虑捷径分支,有两种 一个是普通的捷径分支,一个是特殊的捷径分支
downsample=None
if stride!=1 or self.inplanes!=outplanes*block.expansion:
downsample=nn.Sequential(nn.Conv2d(in_channels=self.inplanes,out_channels=outplanes*block.expansion,kernel_size=1,stride=stride,bias=False),
nn.BatchNorm2d(outplanes * block.expansion)
)
layers=[]
layers.append(block(self.inplanes,outplanes,stride,downsample))
self.inplanes = outplanes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, outplanes))
return nn.Sequential(*layers)
def forward(self,x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
# 展平
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def resnet18(num_class=1000):
return ResNet(BasicBlock,layers=[2,2,2,2],num_classes=1000)
def resnet34(num_class=1000):
return ResNet(BasicBlock,layers=[3,4,6,3],num_classes=1000)
def resnet50(num_class=1000):
return ResNet(Bottleneck,layers=[3,4,6,3],num_classes=1000)
if __name__ == '__main__':
device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model=resnet50(1000).to(device)
from torchsummary import summary
print(summary(model,input_size=(3,224,224)))