🌟 从"读不懂上下文"的AI,到真正理解语言:BERT如何改变NLP世界?
你有没有遇到过这种情况:
朋友发来一句:"他走了。"
你一脸懵:走了?是出门了?还是分手了?还是......去世了?
人类靠上下文就能立刻判断意思。但对AI来说,理解一句话的"言外之意",曾经是个巨大的难题。
直到2018年,谷歌发布了一篇划时代的论文------《BERT 》,全称是 Bidirectional Encoder Representations from Transformers(基于Transformer的双向编码器表示)。
这篇论文就像NLP(自然语言处理)领域的"原子弹",彻底改变了AI理解语言的方式。
今天我们就来拆解它:BERT到底是什么?它为什么这么牛?又是怎么做到的?
🔍 一、在BERT之前,AI是怎么"读书"的?
想象一下,你要教一个学生读文章。传统AI模型就像这样学习:
❌ 单向阅读:从左到右,读完就忘
比如像 GPT 这类模型,它是"从左往右"读句子的:
"我喜欢吃苹果,因为它很___"
当它读到"因为"的时候,它只能根据前面的信息猜测:"很甜"?"很脆"?但它看不到后面的词,也不知道"它"指的是什么。
这就像你蒙着眼睛读书,每读一个字就忘记前面的,怎么可能真正理解?
❌ 另一种方式:从右往左,也一样片面
有些模型是从右往左读,但问题一样:只能看到一半上下文。
这就像是两个人分别从书的开头和结尾读,谁也见不到对方,没法拼出完整故事。
🧠 BERT的革命性突破:双向阅读,上下文全看
BERT的天才之处在于:
它不是"读"句子,而是"遮住"句子,然后猜被遮住的部分。
这就像老师给你一篇课文,把某些词涂黑,让你填空。
✅ 核心思想:完形填空式预训练
BERT的训练方式叫 Masked Language Model (MLM):
-
给模型一句话,比如:
"我喜欢吃MASK,因为它很甜。"
-
让模型根据前后所有词("我""喜欢""吃""因为""它""很""甜")来猜:
MASK 应该是"苹果"。
✅ 因为它能同时看到"前面"和"后面",所以是真正的双向理解!
📌 举个生活例子:
"银行的利息太低了,我决定把钱从MASK取出来。"
- 如果只看前面"银行的利息太低了",你可能猜是"存款"。
- 但如果只看后面"取出来",你也可能猜"ATM"。
- 但BERT能同时看到前后,所以更容易猜对是"存款"。
🔁 第二招:理解句子之间的关系------"下一句预测"
BERT还有一个绝活:它不仅能理解一句话,还能理解两句话之间的逻辑关系。
比如:
- 第一句:"今天天气真好。"
- 第二句:"我们去公园吧。"
这两句是连贯的。但如果是:
- 第二句:"我的狗爱吃骨头。"
就不连贯了。
BERT在训练时会玩一个"真假配对"游戏:
- 50%的时间给它两个真正连续的句子(True)
- 50%的时间随机拼接两个不相关的句子(False)
然后让它判断:"这两句是上下文吗?"
这个任务叫 Next Sentence Prediction (NSP)。
🎯 为什么重要?
因为很多任务,比如问答、文本蕴含,都需要理解句子之间的逻辑。BERT提前学会了这个技能。
🧪 二、BERT是怎么用的?------"先学知识,再上岗"
BERT采用的是 "预训练 + 微调" 的两段式学习法,就像人类先上大学,再参加岗前培训。
📚 第一阶段:预训练(自学成才)
- 在海量文本上训练(比如维基百科 + 书籍语料库)
- 学两个任务:
- Masked LM:猜被遮住的词(学词汇和语法)
- Next Sentence Prediction:判断句子是否连贯(学逻辑和篇章结构)
✅ 这一步让BERT成为一个"语言通才"。
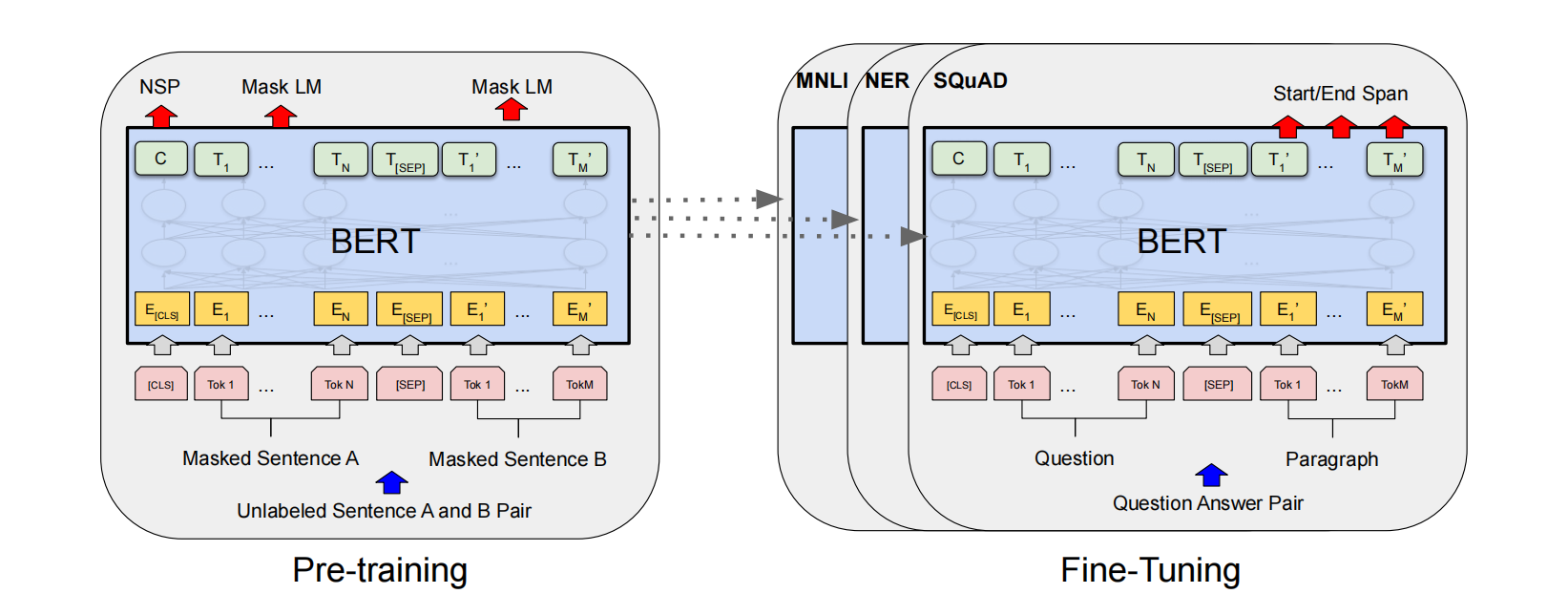
🛠️ 第二阶段:微调(快速上岗)
当你想用BERT做具体任务时,比如:
- 判断两句话是不是一个意思(自然语言推理)
- 找出文章中回答问题的那段话(阅读理解)
- 给电影评论打标签是"好评"还是"差评"(情感分析)
你只需要:
- 把BERT模型拿过来
- 在你的小数据集上再训练几轮
- 它就能立刻适应新任务!
🚀 好处是:不需要从头训练,省时省力,效果还特别好。
🏆 三、BERT有多强?直接刷新11项纪录!
论文一发布,BERT就在11个NLP benchmark任务上刷新了世界纪录,包括:
| 任务 | BERT表现 |
|---|---|
| GLUE(综合理解) | 超越人类水平! |
| SQuAD(阅读理解) | 比人类高5个百分点 |
| SWAG(常识推理) | 准确率提升27.1% |
| MNLI(文本蕴含) | 提升5.1% F1值 |
📌 举个例子:在SQuAD阅读理解任务中,系统要回答:
"爱因斯坦哪年获得诺贝尔奖?"
BERT不仅能找到答案"1921年",还能从上下文中理解"他因光电效应获奖,而非相对论"------这需要真正的理解,不是简单匹配关键词。
🔬 四、BERT的"内部结构"揭秘
BERT其实是一个Transformer编码器的堆叠。
- BERT-Base:12层,1.1亿参数
- BERT-Large:24层,3.4亿参数
它接收输入的方式也很巧妙:
- 每句话被拆成词(或子词)
- 每个词加上三种信息:
- 词本身的意思(Word Embedding)
- 它在句中的位置(Position Embedding)
- 它是第几句(Segment Embedding,用于区分两句话)
然后通过多层Transformer,不断融合上下文信息,最终每个词都"知道"整个句子的背景。
🧩 五、消融实验:哪些设计最关键?
研究人员做了"拆零件"实验,看看BERT的哪些部分最核心:
| 修改方式 | 性能变化 |
|---|---|
| 去掉NSP(不下一句预测) | 性能下降,尤其在句子关系任务 |
| 改成单向(像GPT) | 性能大幅下降 |
| 加BiLSTM | 反而变差 |
结论:双向+NSP是BERT成功的关键。
🌍 六、BERT的影响:开启"预训练大模型"时代
BERT的出现,直接引爆了AI圈的"预训练模型"热潮:
- GPT系列:虽然单向,但靠海量数据和生成能力取胜
- RoBERTa:去掉NSP,加大训练量,更强
- ALBERT:压缩参数,更高效
- ERNIE(百度):加入中文知识
- Chinese-BERT:专为中文优化
可以说,现在几乎所有大模型(包括ChatGPT)都受到了BERT思想的启发。
🧠 总结:BERT的三大核心思想
| 思想 | 说明 | 类比 |
|---|---|---|
| ✅ 双向上下文理解 | 同时看前后词,真正理解语义 | 读文章时能前后对照 |
| ✅ 预训练+微调范式 | 先学通用知识,再快速适配任务 | 先上大学,再培训上岗 |
| ✅ 完形填空式训练(MLM) | 遮住词来猜,学会推理 | 做语文填空题 |
💬 最后一句话
BERT不是第一个预训练模型,但它是第一个真正让AI"理解"语言的模型。
它告诉我们:AI不需要从零开始学每个任务,只要有一个强大的"通识大脑",再稍加指导,就能胜任万千工作。
这就像教育的真谛------
不是灌输知识,而是教会思考。
📚 参考资料
- 论文原文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (Devlin et al., 2018)
- 数据来源:维基百科 + BookCorpus
- 开源地址:https://github.com/google-research/bert