
🫧 励志不掉头发的内向程序员 :个人主页
✨️ 个人专栏: 《C++语言》《Linux学习》
🌅偶尔悲伤,偶尔被幸福所完善
👓️博主简介:

文章目录
前言
不知道大家是否曾经有疑惑,那就是不知道内存和外存的区别,像买电脑是除了有 1TB 的存储空间外,还有一个 4/8GB 的内存不知道是什么,本章节我们就来聊聊这个问题,让我们一起来看看吧。

一、研究平台
-
kernel 2.6.32
-
32 位平台
二、程序地址空间回顾
我们在讲解 C 语言时,我们肯定都会接触这样的空间布局图。
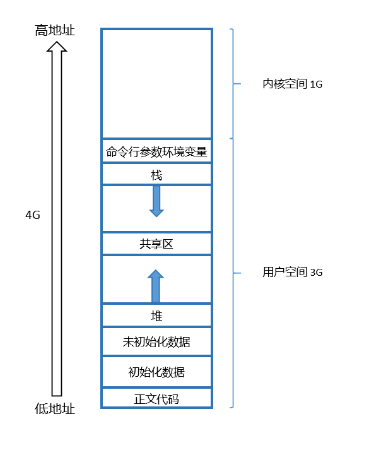
但是我们实际的内存空间是长这样的吗?其实这个根本就不是内存,我们仔细想想,如果我们一个程序的内存空间长这样,那我们其他的程序的内存空间该怎么排布呢。所以我们上面的图不叫程序内存空间,而是进程内存空间。它是系统的概念而不是语言的概念。我们来看看这个代码来验证。
c
#include<stdio.h>
#include<unistd.h>
int gval = 100;
int main()
{
pid_t id = fork();
if(id == 0)
{
while(1)
{
printf("子: gval: %d, &gval: %p, pid: %d, ppid: %d\n", gval, &gval, getpid(), getppid());
sleep(1);
gval++;
}
}
else
{
while(1)
{
printf("父: gval: %d, &gval: %p, pid: %d, ppid: %d\n", gval, &gval, getpid(), getppid());
sleep(1);
}
}
return 0;
}运行后我们惊讶的发现。
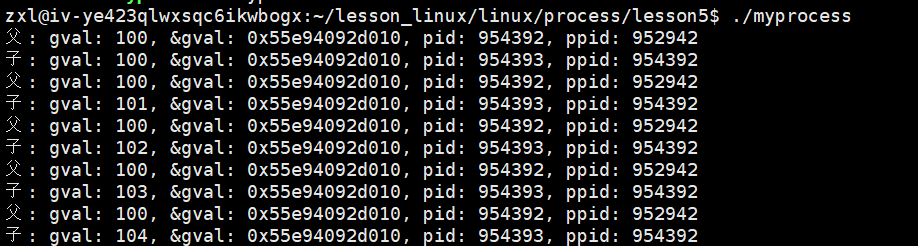
我们的父子的 gval 的地址相同,但是我们的 gval 的值不同!!!也就是同一个地址却有两个不同的值。如果是程序的内存,那也太可怕了,所以这个不是我们的程序地址,而是虚拟地址。我们之前的指针用到的地址,全都是虚拟地址。
三、虚拟地址
上面我们知道了我们的虚拟地址空间不是物理内存,实际上,我们的虚拟地址空间不止一个,而是有多个,并且一个进程一个虚拟地址空间。我们创建进程时我们的 task_struct 都要对应一个虚拟地址空间,我们的虚拟地址空间的宽度是 1 字节,而在 32 位机器上就是 232 个地址(4G),64 位机器就是 264 个地址(8G)。我们一般研究 32 位机器,因为 64 位机器地址太长了。我们的 32 位机器中,有 1G 的内核空间(暂不考虑)和 3G 的用户空间。
四、进程地址空间
我们所能看到的地址都是虚拟地址,也就是进程的地址空间内的地址。当我们自己定义了一个全局变量 g_val = 100。那他肯定会在内存中开辟一个内存。而在我们的地址空间上也得有一个 4 字节的全局变量的虚拟地址。也就是说在内存上存在一个物理地址和地址空间上一个虚拟地址。而在我们的 OS 在创建进程时要为每一个进程构建一个叫页表的东西,和虚拟地址空间一样,我们一个进程一个页表。这个页表的左侧填充的是我们的虚拟地址,右侧填充的是我们的物理地址,当我们的进程想要访问我们的虚拟地址是,我们的操作系统可以通过我们的页表转换成内存上的物理地址,进而访问指定变量,所以我们的页表是来做我们的虚拟地址和物理地址映射的。
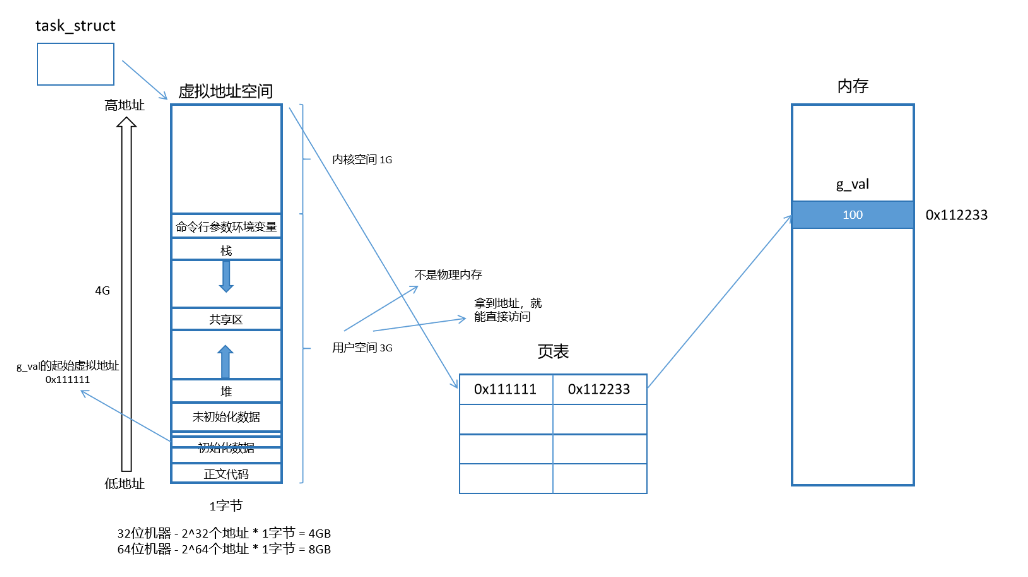
我们的所有的数据都有地址,他们全都是通过页表映射到我们的物理内存位置的。但是我们的 g_val 是整型啊,应该有 4 字节,也就是应该有 4 个地址啊,但是取地址时只能取到一个地址,也就是这四个地址中最小的那个,但是一个地址只能访问一个字节啊,所以说这个时候我们的类型就诞生了,不同类型偏移量不同,这样就能找到我们的所有地址了。
如果是父子进程呢?我们之前说了,一个进程一个虚拟地址空间和页表,所以说我们的子进程也有相应的虚拟地址空间和页表。子进程也要有它的代码和数据。我们的子进程的 task_struct 是拷贝父进程的,那虚拟地址空间和页表呢,答案就是也是拷贝父进程的。这就发生了简单的浅拷贝了。
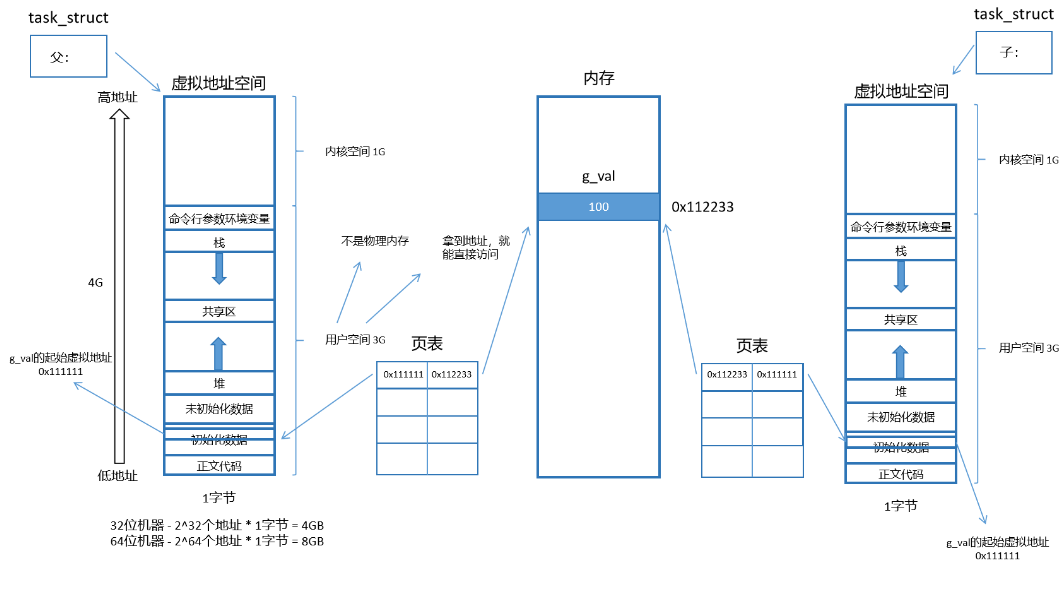
这也就是为什么我们打印的父子进程的地址是相同的了,因为子进程是拷贝父进程的虚拟地址的。变量是这样,我们的代码也是相同的,他们两个人全部发生浅拷贝的关系,我们的父子进程在默认情况下不就是数据共享,代码共享了嘛。
这个时候我们的子进程的变量要进行修改了,要进行 ++ 操作了,这个时候,由于我们的进程具有独立性,如果我们的子进程通过我们的页表找到我们的内存空间后进行修改,由于和父进程页表指向同一个位置,那我们的父进程不就也修改了?所有我们的操作系统为了防止这个事情的发生,就会在发现 ++ 操作时,我们的子进程要修改,我们的 OS 就会重新开辟一个内存空间来,把我们老变量的内容拷贝出来得到一个新变量后也得到了一个新的物理地址,这个时候 OS 就不会让我们的子进程在映射到父进程映射的地址,而是变成了我们新的地址了,这样就构成了我们的新的映射关系了。
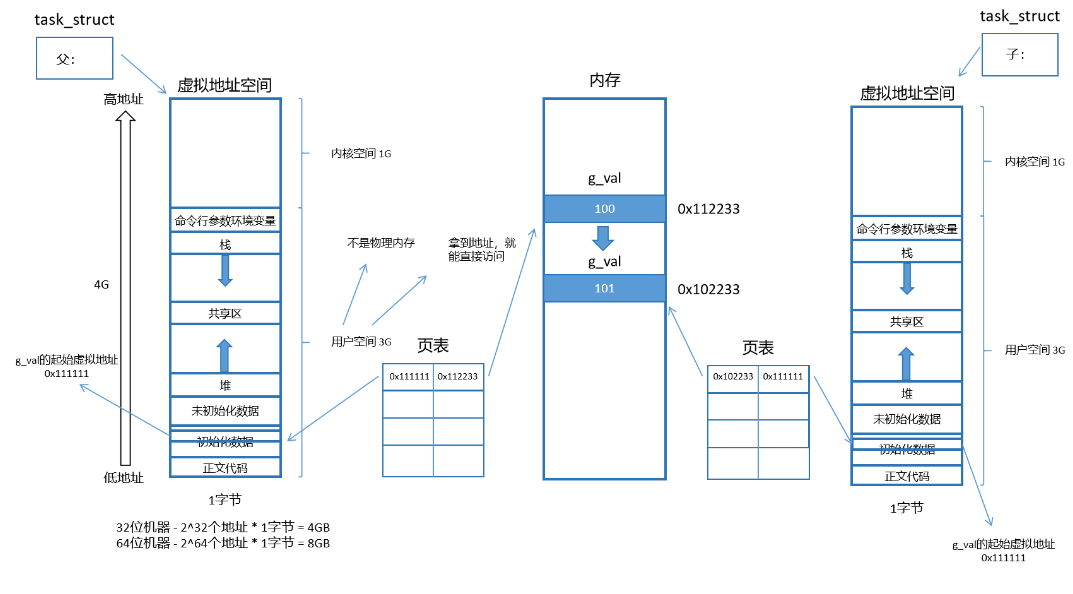
这个时候我们的虚拟地址不变,但是我们的物理地址发生了改变,也就是发生了写实拷贝。这就是为什么我们之前同一个地址确实不同的内容的原因,因为它提供的是虚拟地址而不是物理地址。
这个时候我们也就可以来解释说明我们的历史遗留问题了,就是进程概念中的问题 3(为什么一个变量既等于 0 又大于 0)。就是因为发生了写实拷贝,他们拿着相同的虚拟地址,但是映射了不同的物理地址,所以有两个不同的变量但是是同一个地址。
我们现在是了解到了我们的原理,但是我们的虚拟地址空间到底是什么呢?
举个例子:
我们有一个有钱的富翁有 10 亿资产,他有 4 个私生子,相互之间不认识,富翁对他们分别画大饼说如果他死了,他的 10 亿资产就是他们的,但是我们知道他没有那么多钱,所以不可能给他们分别 10 亿,但是如果他们需要几百几千或者几万元富翁都会满足。我们的富翁就是我们的 OS,进程就是私生子,而我们富翁画的饼就是我们的虚拟地址空间了。我们的每一个进程都认为自己有 4GB 的物理内存。
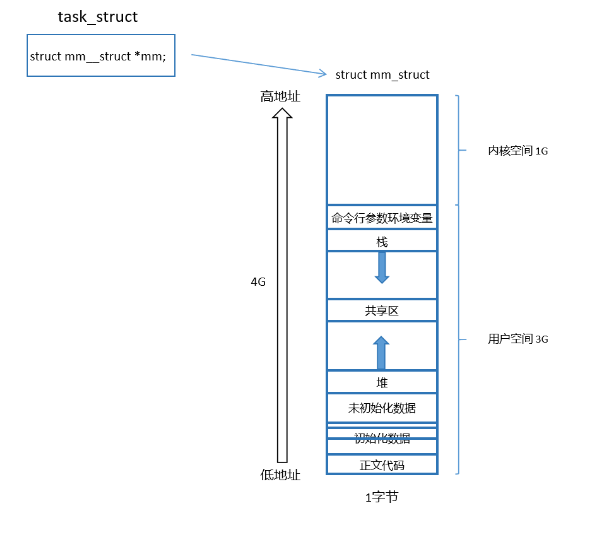
但是如果我们画的饼很多呢?换句话说,我们的饼要不要管理呢?答案是要的,不然我们会忘记的。也就是先描述,再组织。所以说我们的虚拟地址空间本质上就是一个结构体变量的数据结构,叫做 mm_struct。
五、虚拟内存管理
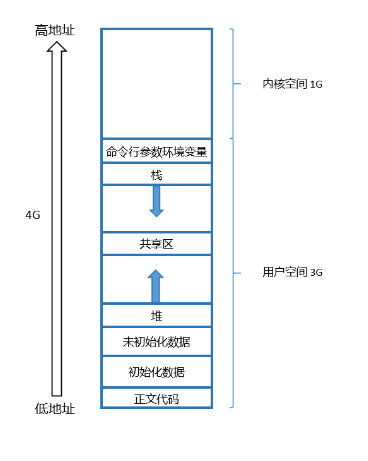
我们可以看到我们的地址空间有很多的区域。在我们了解他们的不同区域是,我们先来了解了解什么叫做区域划分。
再举个例子:
上幼儿园的时候我们可能会遇到这种情况,我们和我们的同桌相互之间不对付,这个时候我们可能会在我们的桌子上划线,叫三八线,如果越过了线就打对方,如果这个时候有人越过了线,另一个人就很快的打了对方一下,他就明白他越过线了。在桌子上划线的行为本质就是区域划分。
用计算机量化一下小女孩区域划分的行为
c
struct Destop
{
int zs_start; // 记录张三桌子的开始位置
int zs_end; // 记录张三桌子的结束位置
int ls_start; // 记录李四桌子的开始位置
int ls_end; // 记录李四桌子的结束位置
};struct Destop area = {0, 49, 50, 99};
以上就实现了我们小女孩的区域划分,我们的张三的区域就在桌子 0-49 的位置,而李四的区域就在 50-99 的位置。
所以说我们的区域划分只需要确认区域的开始和结束即可。
我们把这 100 长度分割成 100 分,我们的张三占有 0-49 个刻度,我们的张三可以在 0-49 的任意位置做他想做的事情,那这个刻度就是我们的地址。我们的分割行为叫做将我们的桌子统一编址。
所以说我们的桌子就是我们的地址空间,桌子上的刻度就是我们地址空间上的地址,我们的一个地址空间上有 7 个小朋友(除开内核空间)。每个小朋友都有它对应的区域。所以我们的 mm_struct 中就会保存各种区域的起始地址。
c
struct mm_struct
{
long code_start;
long code_end;
long init_start, init_end;
long uninit_start, uninit_end;
....
};如果我们的一个人把我们的三八线更改了,我们把这个行为叫做区域调整。
我们接下来就可以更加细致化的了解我们的虚拟内存空间了。
从上面的讲解我们可以知道,我们的各种区域(堆区、栈区等)都是动态形成的,是进程运行期间 OS 动态申请的。当我们的程序变成进程时,我们的代码和数据是要加载到物理内存的,我们如果要把我们的程序加载到内存要做两件事情:
-
要在虚拟地址空间中申请指定大小的空间;
-
加载程序,申请物理空间。1 <-> 2 经过我们的页表建立映射关系。也就是把我们的物理地址转换成虚拟地址,然后我们的虚拟地址再提供给上层用户使用。
但是我们的 mm_struct 要开辟空间,初始化数据从哪里来呢?有相当一部分是从我们程序
加载到内存时,从加载的过程之中来的。
六、为什么要有虚拟地址空间
我们通过上面的学习就可以意识到了,我们的数据和可执行程序所开辟的内存地址在物理内存层面上开辟的位置已经不重要了。无论加载到什么地方,我们都可以通过页表来映射到指定的区域。这样就可以把我们的无序变成有序了。这就是虚拟空间存在的第一个意义。
当我们要去访问一个变量的地址时,要将我们的虚拟地址转化成我们的物理地址。我们可以简单理解为我们的 OS 自动的去查找页表完成的这一步。但是我们为什么不直接就去内存找,反而要绕一圈呢?其实这和页表有关,我们的页表上面不单单只有两个地址之间的映射关系,还有一些功能,就比如说权限,我们的页表上有一些想 r、w、x 的权限,当我们访问页表时,如果我们要对一个代码区进行写入,但是发现我们居然只有读的权限,我们的 OS 就直接不给你转化,或者直接将进程杀掉,这就实现了对物理内存的保护。也就是说在地址转化的过程中,我们的虚拟地址也可以对你的地址和操作进行合法性判定,进而保护物理内存。
我们的野指针就是指我们要查的地址可能因为释放了或者不存在导致在页表上查询不到,这个时候就因为权限问题被 OS 杀掉了,这就是野指针,野指针可能会导致程序崩溃。
当我们修改一个字符串常量时,我们会查页表,页表显示这个区域是只读的,所以查页表失败,OS 就不会然我们更改,所以程序就会崩溃。这就是我们为什么虚拟地址存在的原因。
如果我们要访问我们的代码部分,但是我们的代码非常的大,有 2G 左右,这个时候我们就可以不一次性把我们的代码全部加载到我们的物理内存中,而是加载 1/4,但是在正文代码的区间还是开辟 2G 的空间,只加载 1/4 的内容,当我们的程序加载加载着发现我们的虚拟地址中有,但是我们的页表却没有映射关系,这个时候就能实现我们的动态加载。这个时候我们再加载 1/4的内容,然后建立映射关系后运行。这种机制叫做缺页中断。
让我们的进程管理和内存管理进行一定程度的解耦合。
注:
-
我们可以不加载代码和数据,只有 task_struct,mm_struct,页表。
-
创建一个进程,先有 task_struct,mm_struct 等,再加载代码和数据。
-
进程挂起就是我们把 S 状态的进程的页表清空,把页表指向的代码和数据全部换出到我们的磁盘的 swap 分区中。
-
我们的堆区不是连续的,但是只有一个 start 和 end 是为什么呢?
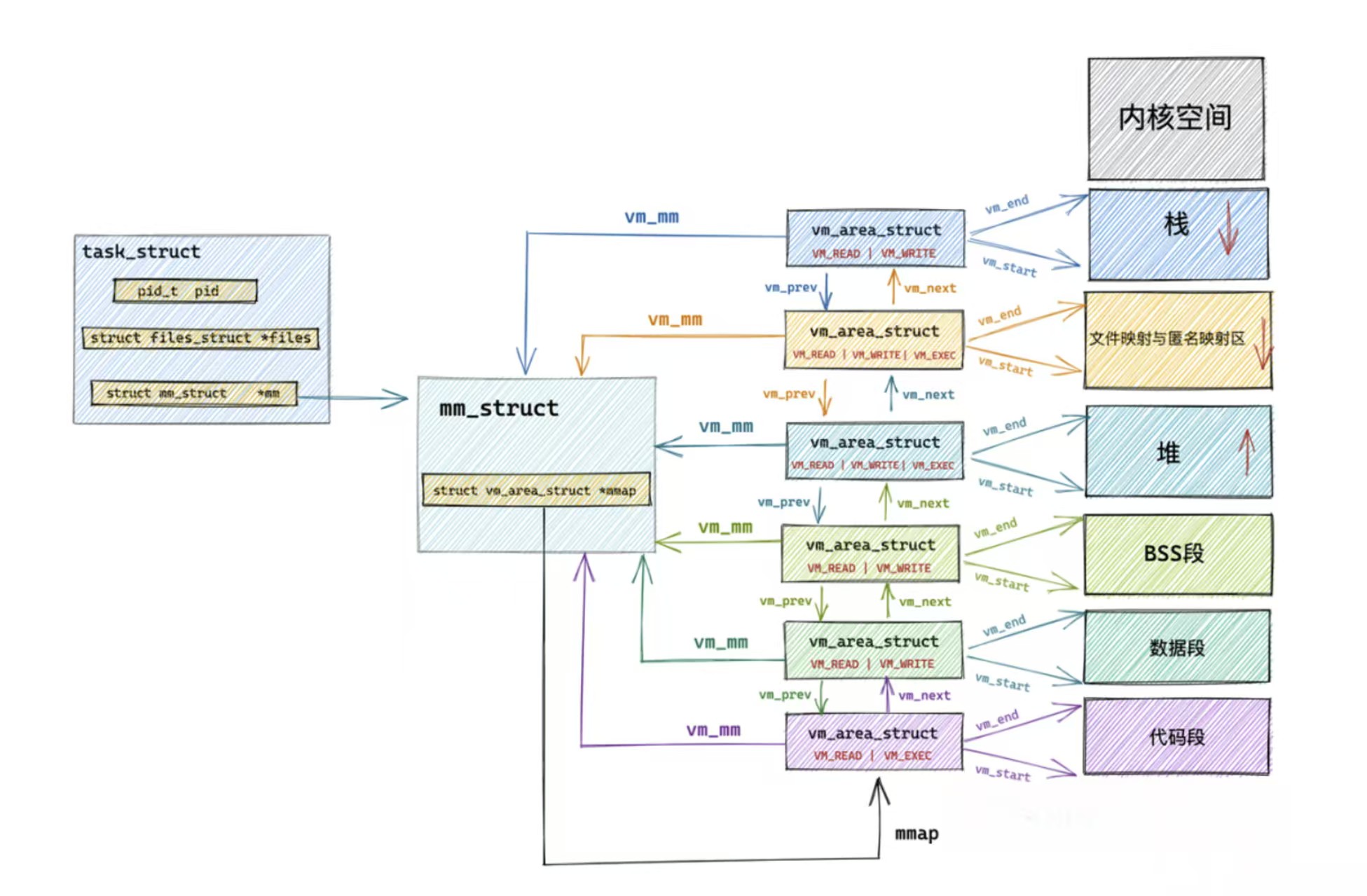
原因是我们的 mm_struct 会维护一张 vm_area_struct 的链表,这个链表会记录下来我们每一个子区域的 start 和 end。
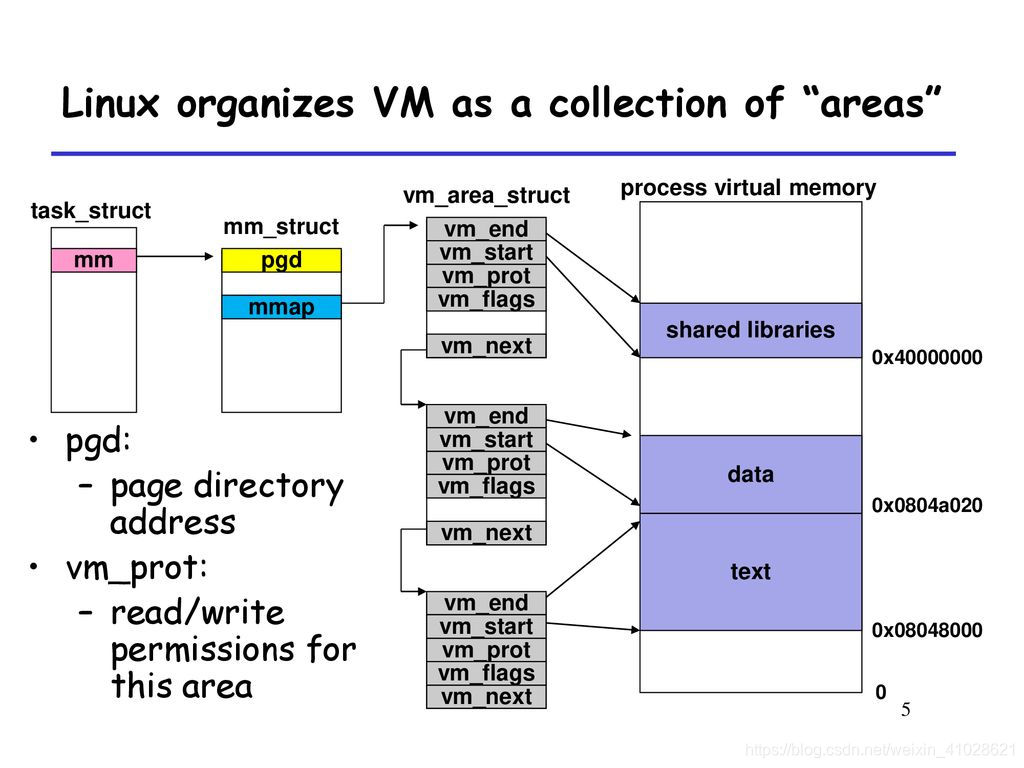
这样我们的堆区不连续也能划分好。
其实我们的每个区域都有我们的 vm_area_struct,堆区有多个。而我们的 mm_struct 中是对我们的各种区域的整体描述。
总结
我们看到的物理内存本质上是和我们虚拟内存不是一个概念,我们 Linux 中在这两个之间加了一个中间层页表来统一这两个概念,我们对页表的深入学习将在后面继续,我们本章节理解什么是物理内存、什么是虚拟内存即可。
🎇坚持到这里已经很厉害啦,辛苦啦🎇 ʕ • ᴥ • ʔ づ♡ど
