本篇文章Testing the Limits of PandasAI (Part 1)适合对数据科学感兴趣的读者了解PandasAI。文章的技术亮点在于它可以通过自然语言与数据进行交互,简化数据分析过程,特别是在简单的探索性数据分析(EDA)中表现良好。方法适用场景主要是处理常见的、重复性的查询,但在复杂问题上可能会遇到限制。
文章目录
- [1 前言](#1 前言)
- [2 什么是 PandasAI?](#2 什么是 PandasAI?)
-
- [2.1 PandasAI 的工作原理?](#2.1 PandasAI 的工作原理?)
- [3 PandasAI 的实践](#3 PandasAI 的实践)
-
- [3.1 简单的 EDA 测试](#3.1 简单的 EDA 测试)
- [3.2 测试结果](#3.2 测试结果)
- [4 等等......速度和效率如何?](#4 等等……速度和效率如何?)
- [5 充分利用 PandasAI](#5 充分利用 PandasAI)
- [6 你是否在日常工作中充分利用了 AI?](#6 你是否在日常工作中充分利用了 AI?)
- [7 结论(第一部分)](#7 结论(第一部分))
- [8 PandasAI 的极限测试: 构建语义层以获取更深洞察](#8 PandasAI 的极限测试: 构建语义层以获取更深洞察)

1 前言
测试极限(第一部分)。
我记得我第一次听说 PandasAI 是在 2023 年底。
ChatGPT-4 刚刚发布,我们看到第一波人们尝试将 LLM 整合到真实的数据工作流中。
那是一个多么激动人心的时刻!
自然地,我必须亲自尝试 PandasAI,看看它到底有什么过人之处。我主要想看看你是否真的能"与数据对话",并最终解决我忘记 Pandas 和 Matplotlib 语法的难题。
长话短说,PandasAI 虽酷,但在实践中却不怎么实用。

2023 年的 PandasAI 试图为我做 EDA。
对于我们数据科学家来说,我们已经要处理无数的工具和语法,如果添加新步骤不能真正带来价值,那么它就不值得。
快进到 2025 年,LLM 已经变得好得多,尤其是在逻辑和编码任务方面,而 PandasAI 自然也一直在发展。
所以几个月前,我决定再试一次,因为我一直在将 AI 更多地整合到我的数据科学工作流中(更多内容请参阅文章末尾 😉)。
现在我想分享 PandasAI 的现状,最重要的是,它能(和不能)如何帮助我们简化工作。
以下是我们将涵盖的内容预览:
- 什么是 PandasAI 以及它幕后工作原理的概览
- 一些实际示例:筛选、聚合和快速绘图
- 在小型和大型数据集上的基准测试,以及为什么 I/O 不是真正的考验
- 常见问题,如字段名称不清晰、查询模糊和 LLM 延迟
- 实用技巧,使其在你的工作流中更好地发挥作用
- 高级功能展望,如代理和领域训练,我将在第二部分深入探讨
2 什么是 PandasAI?
对于那些还没有接触过它的人来说,PandasAI 是一个开源的 Python 库,它通过自然语言能力扩展了流行的 pandas 库。
PandasAI GitHub 仓库预览。
你无需编写 pandas 或 matplotlib 代码,而是可以用简单的英语向 DataFrame 提问,例如 "显示按总支出排名前 10 的客户",PandasAI 将为你生成、执行代码并输出答案。
其承诺很简单:减少 pandas 编码的重复开销,让你更专注于分析本身。
2.1 PandasAI 的工作原理?
现在,让我来分解一下当你向 PandasAI 提问时幕后实际发生的事情:
- 输入 :你通过
DataFrame.chat()或Agent.chat()提问。 - 提示构建:PandasAI 从你的 DataFrame 收集列名、一些预览行和元数据,然后将其与你的问题一起插入到 LLM 的模板中。
- LLM 输出:LLM 生成一段旨在回答你的查询的 Python 代码片段。
- 验证:代码被解析、检查安全性并准备执行。
- 执行:代码使用 pandas 或 DuckDB 在你的 DataFrame 上本地运行。
- 结果:输出以数字、表格或图表的形式返回,并存储在对话内存中,以便你可以提出新的问题。
💡 这意味着,PandasAI 不会将你的整个 DataFrame 发送给 LLM,它只发送必要的上下文,然后执行必要的代码来找到你的答案。这是我们将在后面章节讨论的关键信息。
在下一节中,我将通过几个示例向你展示这在实践中是什么样子。
3 PandasAI 的实践
现在我们已经理解了 PandasAI 的理论工作原理,让我们看看它在实践中是如何表现的。
在撰写本文时,我正在测试 PandasAI 3.0(确切地说是 3.0.0b2)。我不会详细介绍如何安装它,你可以在 GitHub 仓库 或 完整文档 中找到这些信息。
但你需要知道,这是你开始使用 PandasAI 所需的大部分代码:

PandasAI 基本 Python 设置的分解。
它非常简单:
- 你以与 pandas 相同的方式导入数据
- 你使用
.chat()函数与数据对话
3.1 简单的 EDA 测试
好的,对于我运行的测试,我使用了我在 Kaggle 上找到的这个"电子商务客户行为"数据集。
此数据用于使用 RFM 分割分析电子商务客户行为并可视化客户模式。它大约有 5000 行和 9 列,是你会用来构建仪表板或进行一些轻量级 EDA 的典型数据集。
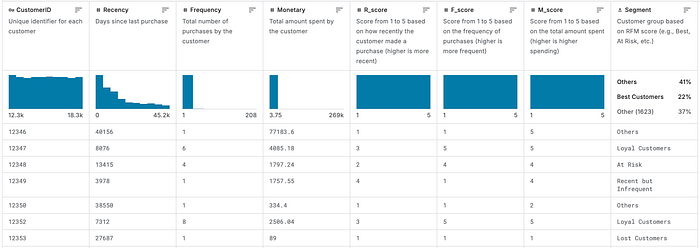
"电子商务客户行为"数据集预览
我提出了 7 个问题,这些是你进行此数据集探索性分析时通常会进行的转换:
- 每个细分市场有多少客户?
- 每个客户细分市场的平均货币价值是多少?
- 哪个细分市场的平均频率最高?
- 显示按货币价值排名前 5 的客户
- 忠诚客户占客户总数的百分比是多少?
- 绘制条形图显示不同细分市场中客户的分布。
- 绘制条形图显示不同细分市场中客户的分布,每个细分市场应采用不同的颜色,并且条形图应标有客户数量。
让我们看看结果如何......
3.2 测试结果
查询 #1: "每个细分市场有多少客户?"
预期结果格式 :表格 ✅
结果准确性:正确 ✅
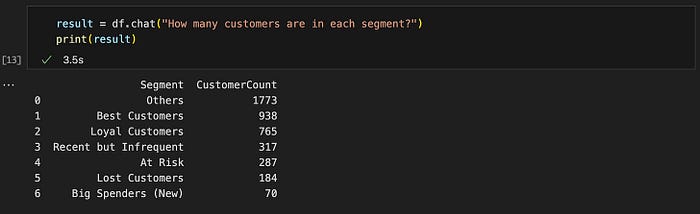
查询 #1 的结果。
查询 #2: "每个客户细分市场的平均货币价值是多少?"
预期结果格式 :表格 ✅
结果准确性:正确 ✅
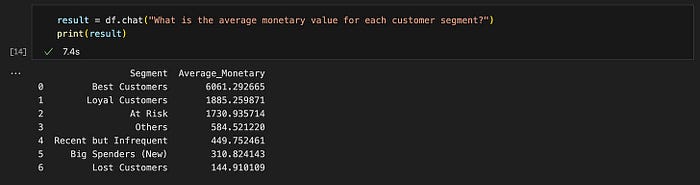
查询 #2 的结果。
查询 #3: "哪个细分市场的平均频率最高?"
预期结果格式 :句子 ✅
结果准确性:正确 ✅

查询 #3 的结果。
查询 #4: "显示按货币价值排名前 5 的客户?"
预期结果格式 :列表 ✅
结果准确性:正确 ✅
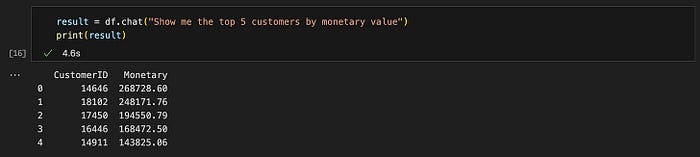
查询 #4 的结果。
查询 #5: "忠诚客户占客户总数的百分比是多少?"
预期结果格式 :单个数字(或句子)✅
结果准确性:正确 ✅

查询 #5 的结果。
查询 #6: "绘制条形图显示不同细分市场中客户的分布。"
预期结果格式 :图表 ✅
结果准确性:正确 ✅
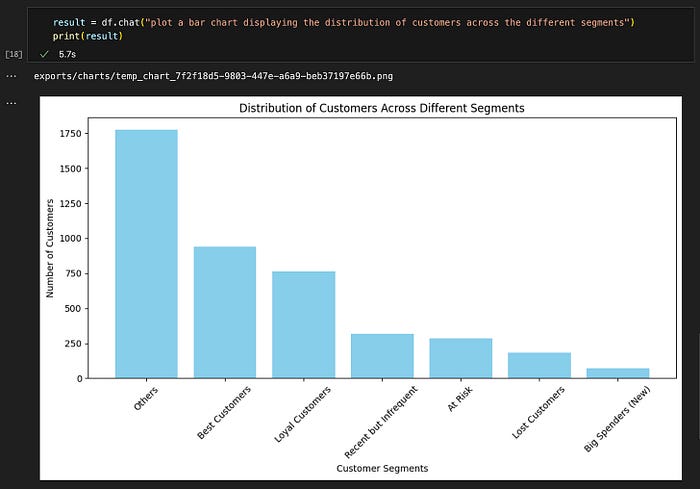
查询 #6 的结果。
查询 #7: "绘制条形图显示不同细分市场中客户的分布,每个细分市场应采用不同的颜色,并且条形图应标有客户数量。"
预期结果格式 :图表 ✅
结果准确性:正确 ✅
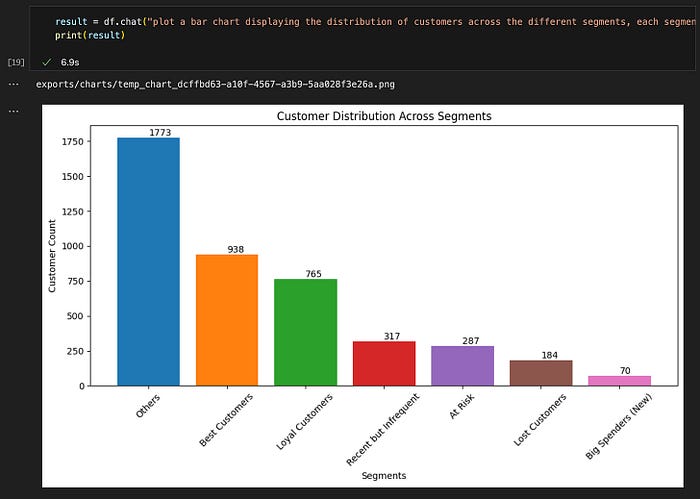
查询 #7 的结果。
我运行的 EDA 测试虽然简单但很实际,PandasAI 以我期望的格式给出了正确的输出。老实说,这感觉比我几年前第一次尝试时有了很大的进步,这正是我希望看到的。
💡 顺便说一句,如果你想运行我用于此测试的代码,这里是 GitHub 仓库。
4 等等......速度和效率如何?
你们可能都在想 PandasAI 在不同数据集大小下的表现如何。乍一看,你可能会认为延迟会随着数据变大而增加。
但事情并非如此。
正如我们之前提到的,PandasAI 不会将你的整个数据集流式传输到 LLM。相反,它只发送元数据(如列名、行预览和上下文)。LLM 生成 Python 代码,然后 pandas 在本地执行它。
这意味着瓶颈几乎总是 LLM 的往返时间,而不是数据集大小。
在实践中,我的基准测试证实了这一点。无论我使用 5K、10K 还是 20K 行,平均响应时间都保持在相同的范围内(所有查询大约在 24-26 秒之间):
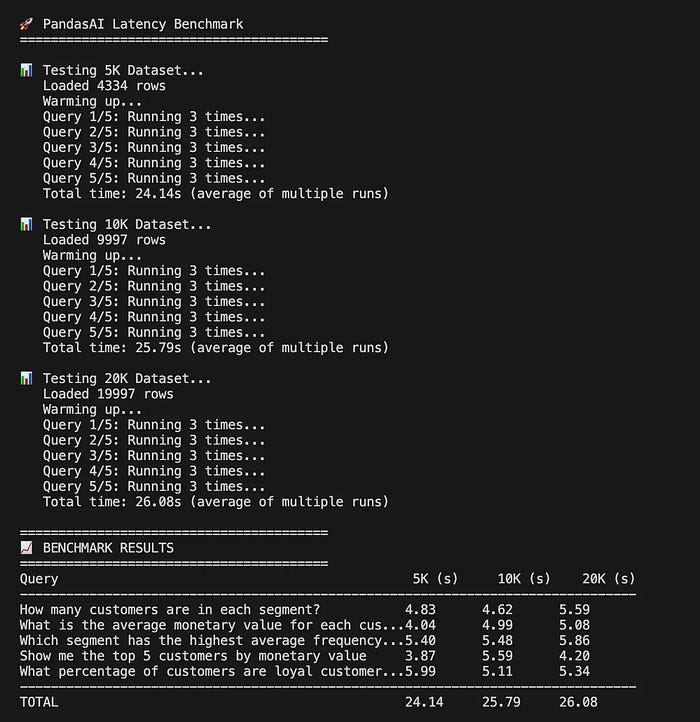
基准测试结果。
💡 所以这里的教训很简单 :不要费心在原始 I/O 上对 PandasAI 进行基准测试。你真正测试的是 LLM 解释你的问题并生成可工作的 pandas 代码的能力。
5 充分利用 PandasAI
PandasAI 并非万能药。它在直接的 EDA 方面表现出色,但一旦你开始提出更复杂的问题,它的局限性就变得显而易见。
根据我的经验,当你尝试多部分查询导致误解或生成的代码笨拙时,会出现更大的问题。然而,大多数时候,这归结于错误地使用 PandasAI,并且在设置方面过于随意。
以下是 5 条经验教训,可帮助你有效地使用它:
- 保持查询专注: 不要问"计算每个细分市场的平均购买价值并绘制分布图",而是将其分成两个独立的步骤。
- 清晰命名你的字段:
customer_id和purchase_amount_usd比cid和p_amt好得多。模糊的名称会让 LLM 猜测,这通常会适得其反。 - 需要时添加领域提示: "monetary_value 是以美元计的购买金额"这样的简短说明为模型提供了它无法自行推断的上下文。
- 逐步迭代: 如果你需要复杂的图表,首先请求摘要统计数据,然后转到可视化。更小的步骤会产生更可靠的输出。
- 坚持探索: PandasAI 非常适合快速检查和健全性测试,但不要指望它能构建完整的管道或生产就绪的脚本。
6 你是否在日常工作中充分利用了 AI?
在过去的几个月里,我一直在构建 AI 系统,帮助我简化工作流,从探索性分析到报告,甚至是一个完整的 AI 代理,帮助我公司的利益相关者"与我们的数据对话"。

"与数据对话"Slackbot 预览。
7 结论(第一部分)
尽管"与数据对话"很有趣,但 PandasAI 并非 pandas 或 matplotlib 的神奇替代品。
从我的测试来看,当你将其用于通常需要几分钟才能输入的轻量级、重复性查询时,它的效果最佳。它并非旨在处理 EDA 工作流的每个部分,如果你试图将所有内容都交给它,你可能会感到沮丧。

没有上下文的 PandasAI。
💡 这样想吧 :当你已经有一个干净的数据集并且只想更快地探索它时,PandasAI 就会大放异彩。但是,当涉及到更繁重的工作,如复杂的连接、大规模转换或深度定制的可视化时,你最好还是坚持使用常规的 pandas 和你自己的代码。
8 PandasAI 的极限测试: 构建语义层以获取更深洞察
无论是与人类还是大型语言模型 (LLM) 对话,规则都是一样的:你提供的相关背景信息越多,得到的答案就越好。
问题在于,在与 LLM 对话时,即使你编写了详细且格式良好的提示,在尝试使输出真正适用于你的特定用例时,你仍然会遇到局限性。
因此,"上下文工程"这个术语最近变得如此流行也就不足为奇了。
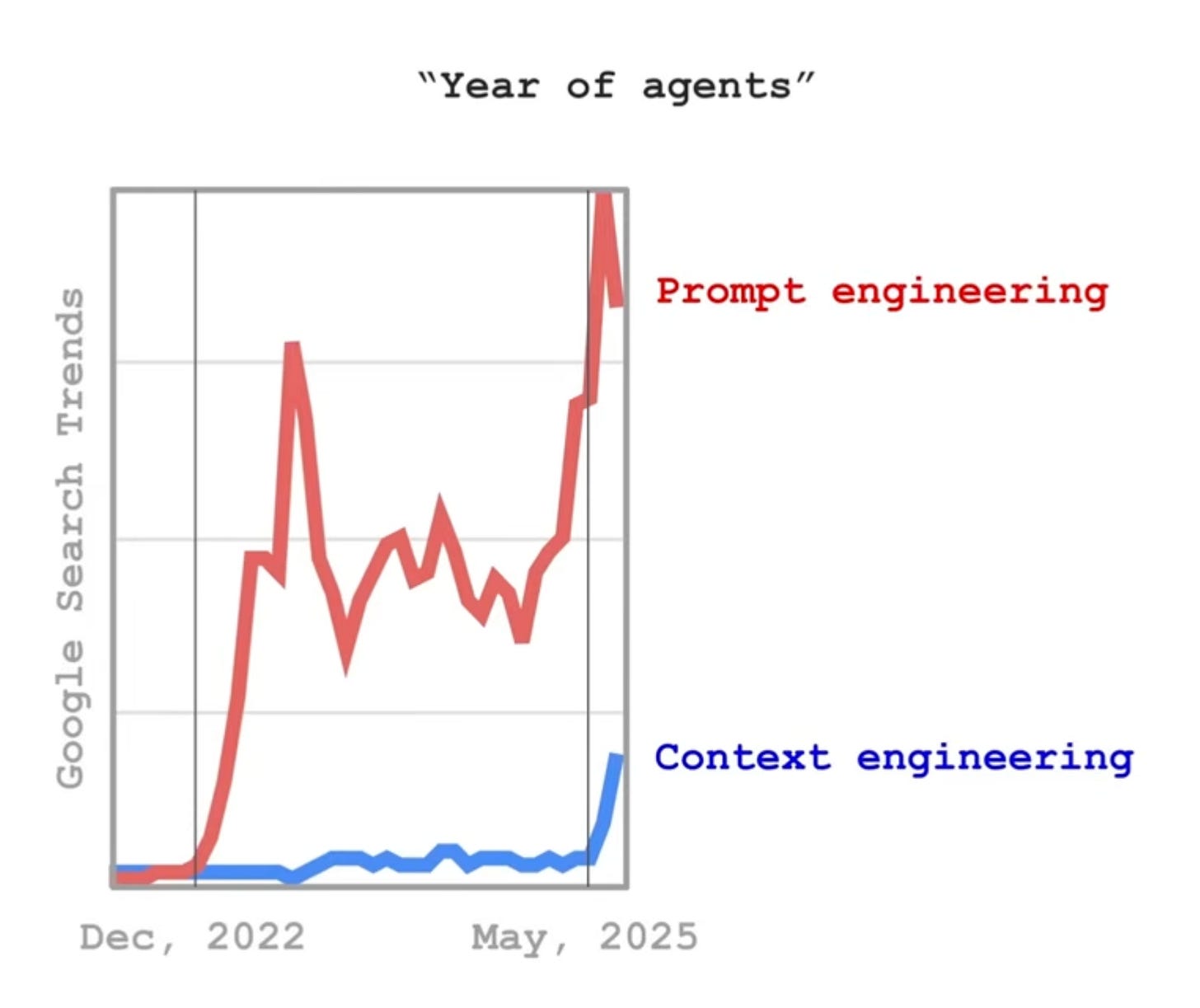
幸运的是,PandasAI 的开发者在开发 v3 时考虑到了这一点。
通过这个新版本,我们能够在代理编写任何代码之前,为其提供更清晰的表格和概念视图。
我们可以创建一个 语义层,将字段名称映射到实际含义,标准化术语,并添加简短的描述符,供模型在生成 pandas 代码时使用。
这就是我将在本文中为你详细介绍的内容。
相信我,通过这个简单的改变,你将开始从 PandasAI 中获得真正的价值。
在第一部分中,我们深入了解了每次你提出"平均收入是多少?"这样的问题时,PandasAI 在底层是如何工作的。
我们看到,当它为 LLM 构建提示时,它不仅包含你的问题,还包含一些它默认收集的额外上下文。
简而言之,PandasAI 从你的数据中收集以下信息:
- 列名
- 几行预览数据
- DataFrame 的元数据
然后将它们与你的问题一起插入到 LLM 的模板中。
尽管这是向前迈出的巨大一步,但它仍然为 LLM 留下了空间,使其对每列的含义以及如何正确转换它们做出假设。
而且,如果在此之上,你还使用神秘的字段名称(顺便说一句,你应该感到羞耻),那么对于 LLM 来说,这完全就是一场纯粹的猜测游戏。
这就是 语义层 发挥作用的地方。
简单来说,语义层是你数据的结构化描述。它不是依赖原始列名,而是明确告诉模型:
- 每个字段代表什么
- 它包含什么类型的数据(字符串、整数、浮点数、日期等)
- 任何别名或业务友好的标签
- 用于分组、过滤或转换值的可选规则
把它想象成位于你的 DataFrame 之上的元数据,指导 LLM 进行正确的解释。
💡 这类似于 dbt 或 LookML 等工具在分析工程中所做的事情:创建一个共享词汇表,以便人类和机器都能一致地理解数据。
定义语义层模式最简单的方法是使用 create 方法:
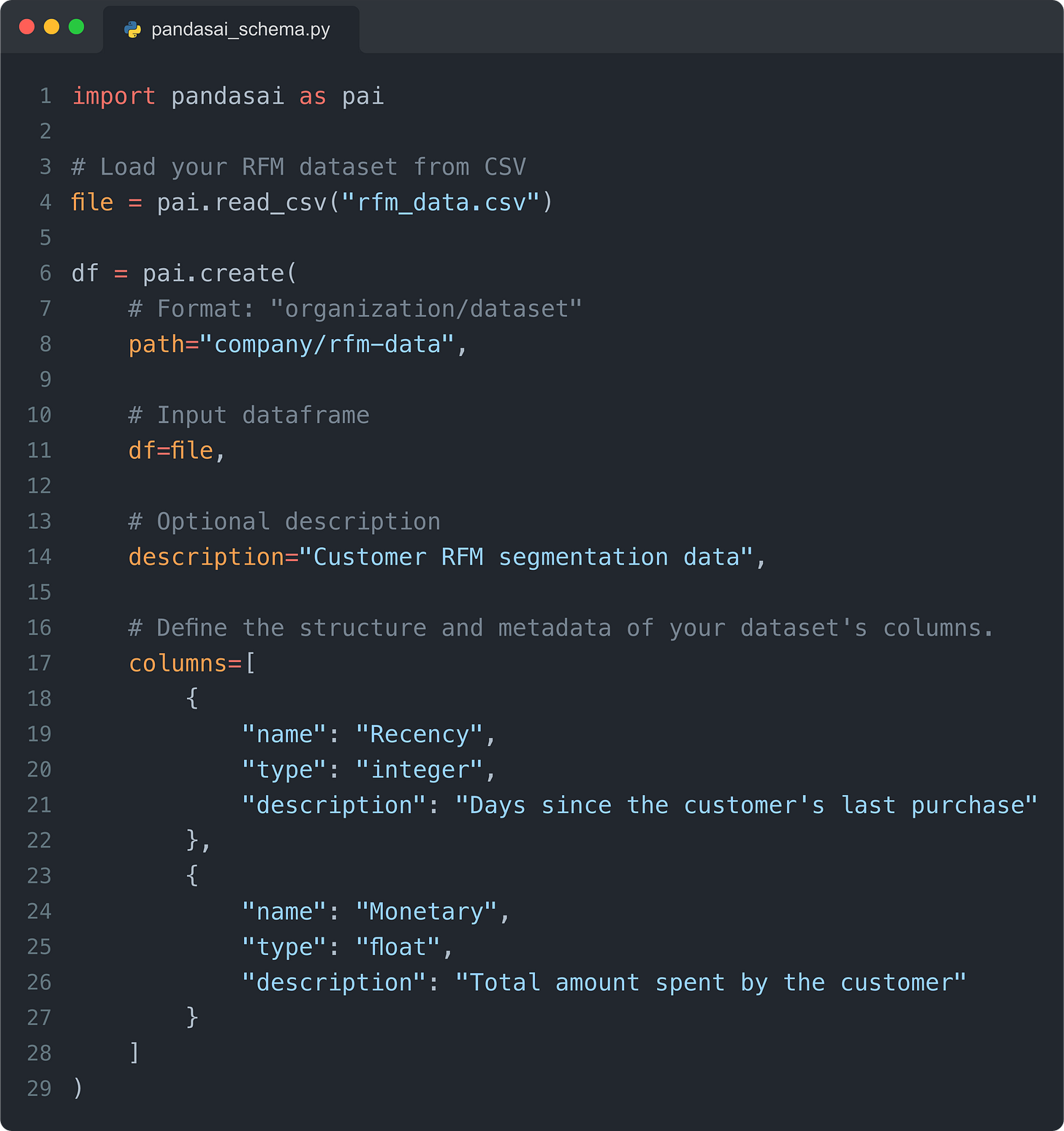
如你所见,它实际上非常简单。但是手动定义列对于演示或甚至快速探索性数据分析 (EDA) 来说是没问题的,但对于生产环境中的工作则不然。
所以让我们探讨如何使这个设置达到生产就绪状态。
在实践中,你的模式已经存在于你的数据仓库中,如果你打算在实际工作流中使用 PandasAI,你将需要一种可重复、自动化的方式来构建和加载该模式到 PandasAI 中。
这是我的正确做法建议:
使用你的仓库的 information_schema(或通过 dbt 或 SQLAlchemy 等客户端进行自省)来提取列名和类型。
这为你提供了原始元数据:列、类型和可选描述,所有这些都来自你实际的真相来源。
PandasAI 期望每列都具有简化的类型:string、integer、float、datetime 或 boolean。因此,你可能需要从默认的数据仓库类型进行转换。
例如,对于 BigQuery 模式,它大致会是这样:
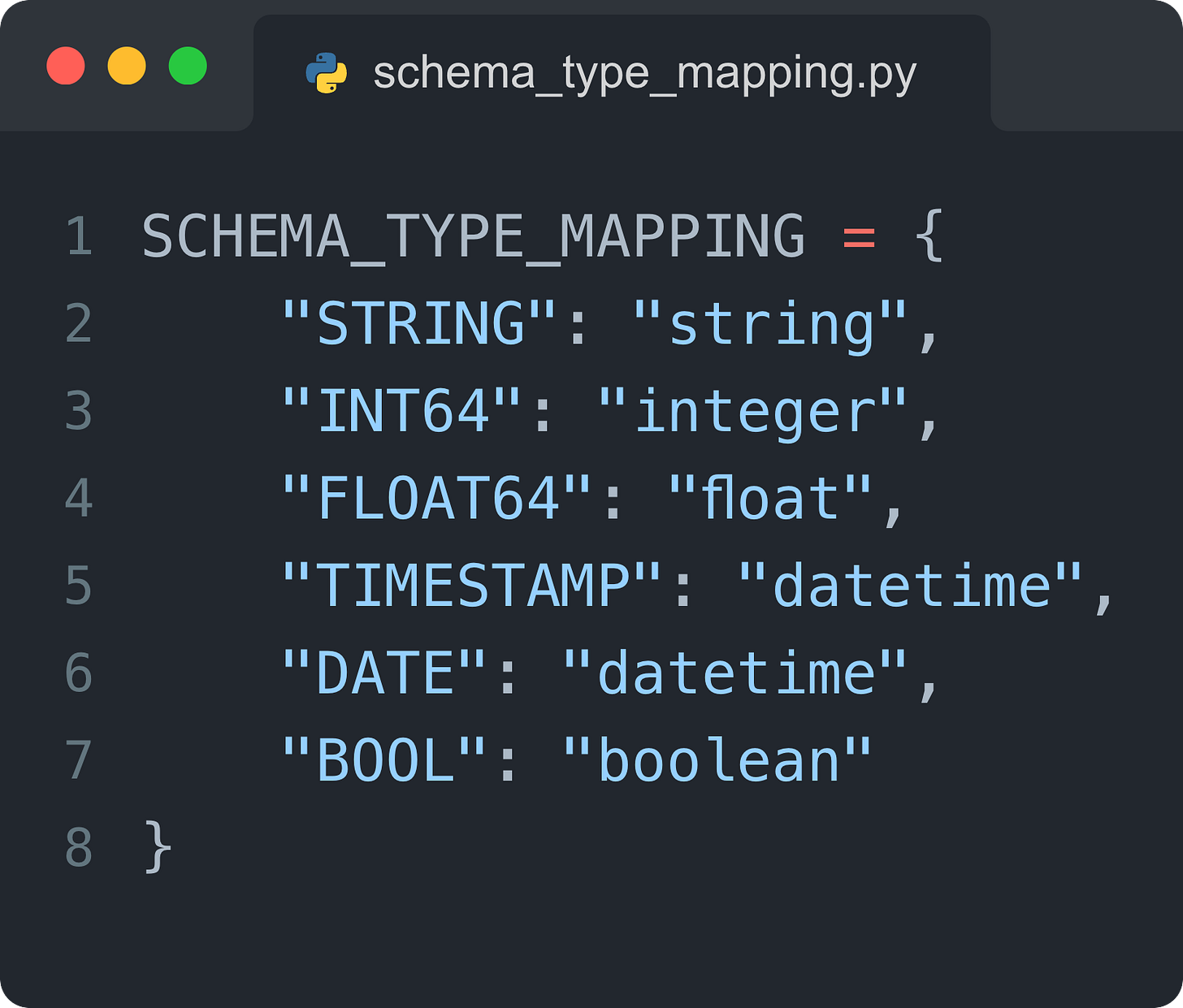
构建一个小型映射层,将你的模式标准化为 PandasAI 期望的格式。
即使你在 Python 中动态生成语义层,你也会希望像代码一样组织和版本化它。一个常见的文件夹结构可能如下所示:
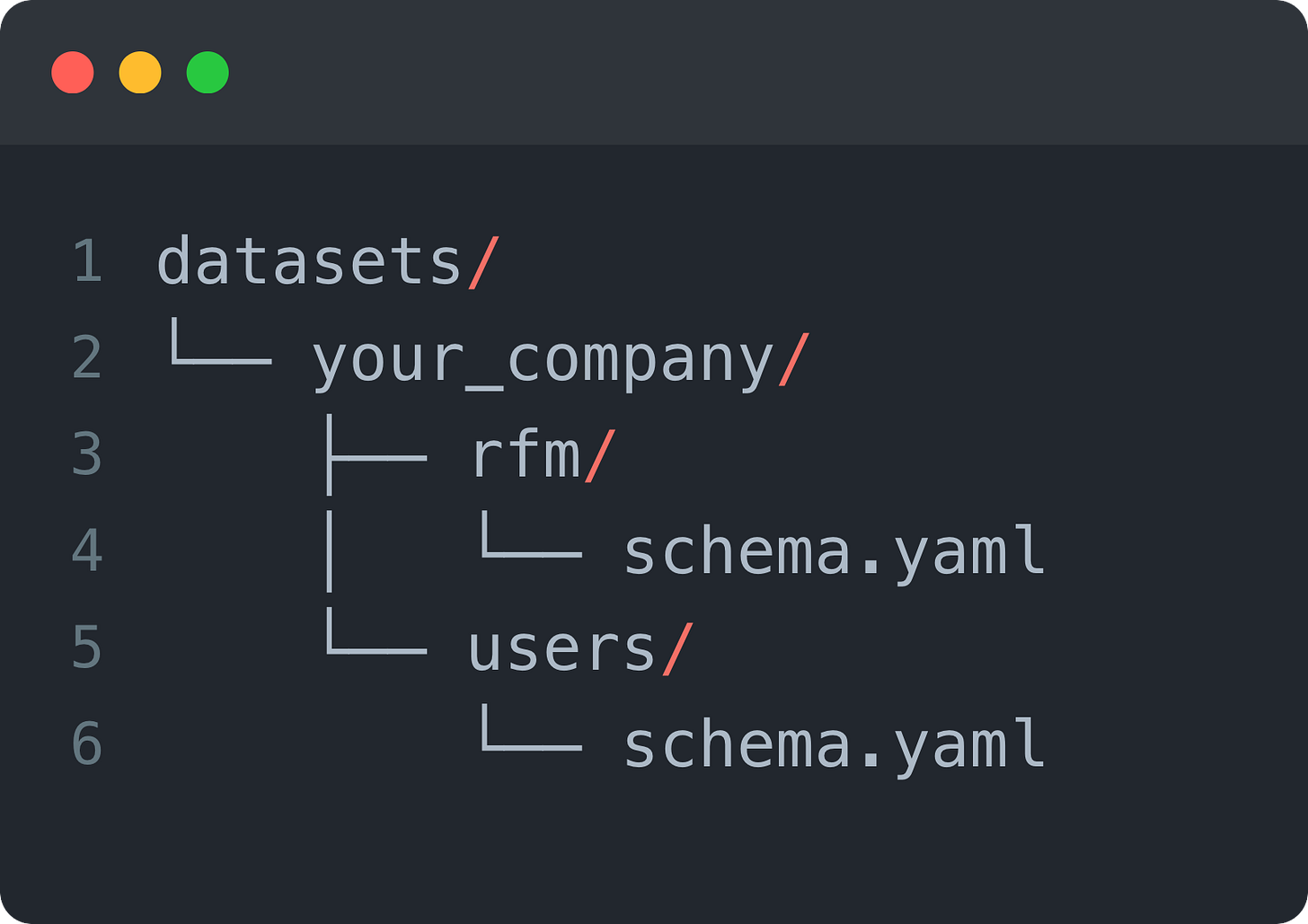
每个 schema.yaml 都应包含你的原始仓库模式的结构化版本。
从一开始就建立一个清晰的结构,可以让你更容易地将模式映射到 PandasAI 期望的格式。
如果你从数十个表中提取数据(很可能你会这样做),这个过程应该自动化,你不会想手动维护这些。
这是你想要的:
- 与你的实际模式保持同步的语义层
- 跨数据集可扩展的版本控制定义
- 感觉像是你的生产堆栈一部分,而不是一个旁实验的 PandasAI 设置
这使你能够在多个项目中可靠地使用 PandasAI,而不仅仅用于一次性任务。
一旦你的模式就位,还有一层值得添加。
你可以在同一个 YAML 文件中定义表达式、分组逻辑和列别名。
这不仅仅是额外的元数据。你正在构建的逻辑告诉 PandasAI 如何处理常见问题:计算什么,如何分组,以及人们在引用数据时实际使用的名称。
想象一下,为 RFM 数据集扩展你的 schema.yaml:
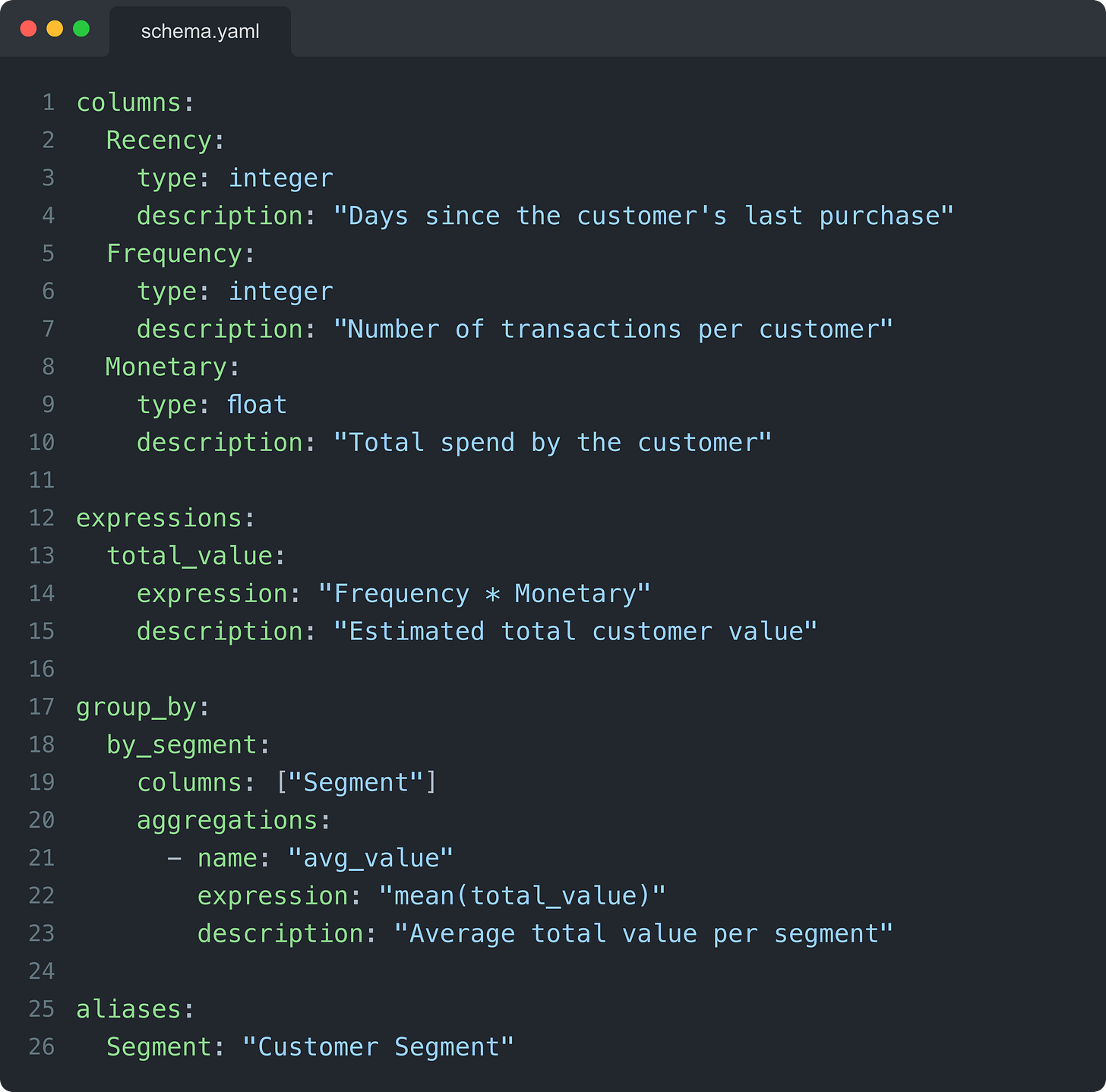
这些小小的补充有助于你的模型更好地推理,并使你的数据集在交互时感觉更人性化。
💡 在这一层你可以做更多的事情。我强烈建议你查看 数据转换 的文档。
在这个短视频中,我谈论了我在工作中构建的一个代理(使用 PandasAI),以帮助利益相关者"与我们的数据对话",以及如何开发一个强大的语义层来释放其全部潜力。
关于 LLM 的许多炒作听起来好像它们应该开箱即用就能"理解一切",但事实是,好的答案需要好的结构。
而结构,尤其是在处理真实数据时,不仅仅意味着列和类型。它还意味着意义、逻辑和反映你的团队实际工作方式的默认设置。
这就是语义层能给你的。
它不仅仅是一种让模型更智能的方式,更是一种让你的数据与人们的思维方式更契合的方式。
一旦你做到了这一点,你不仅能获得更好的输出。你还能提出更好的问题。
这并不是本系列的结局。
