一、背景
随着人工智能技术的飞速发展,多模态检索增强生成(RAG)系统逐渐成为研究热点。LlamaIndex作为一个强大的开发框架,为多模态RAG系统的构建提供了有力支持。本文将详细介绍如何使用LlamaIndex实现一个多模态RAG系统,涵盖系统架构、功能实现、代码解析以及界面设计等多个方面,帮助读者全面掌握相关开发要点。
二、多模态RAG系统架构
多模态RAG系统的核心在于整合多种模态的数据(如文本、图像等),通过检索增强的方式提升生成模型的性能。以下是该系统架构的代码形式展示:
python
class MultiModalRAGSystem:
def __init__(self, embedding_model, vector_database, llm, visual_model):
self.embedding_model = embedding_model
self.vector_database = vector_database
self.llm = llm
self.visual_model = visual_model
def process_user_input(self, user_input):
# 将用户输入嵌入为向量
embedded_input = self.embedding_model.embed(user_input)
# 在向量数据库中检索相关数据
retrieved_data = self.vector_database.retrieve(embedded_input)
# 处理检索到的数据
processed_data = self.process_retrieved_data(retrieved_data)
# 将处理后的数据与用户输入一起传递给LLM
response = self.llm.generate(user_input, processed_data)
return response
def process_retrieved_data(self, retrieved_data):
processed_data = []
for data in retrieved_data:
if data['type'] == 'text':
processed_data.append(self.process_text(data))
elif data['type'] == 'image':
processed_data.append(self.process_image(data))
elif data['type'] == 'table':
processed_data.append(self.process_table(data))
return processed_data
def process_text(self, text_data):
# 处理文本数据
return text_data['content']
def process_image(self, image_data):
# 使用视觉模型处理图像数据
image_description = self.visual_model.describe(image_data['image'])
return image_description
def process_table(self, table_data):
# 解析表格数据
table_content, table_description = self.visual_model.describe_table(table_data['table'])
return {'content': table_content, 'description': table_description}架构说明
embedding_model:负责将用户输入的文本嵌入为向量,以便在向量数据库中进行检索。vector_database:存储和检索嵌入的向量数据,支持快速查找与用户输入最相关的数据。llm:基础大语言模型,用于生成最终的响应结果。visual_model:视觉模型,用于处理图像和表格数据,生成描述性文本。
示例
python
# 初始化系统
embedding_model = TextEmbeddingModel()
vector_database = VectorDatabase()
llm = LargeLanguageModel()
visual_model = VisualModel()
system = MultiModalRAGSystem(embedding_model, vector_database, llm, visual_model)
# 处理用户输入
user_input = "请描述一下这张图片的内容。"
response = system.process_user_input(user_input)
print(response)三、多模态RAG功能实现
(一)rag/multimodal_rag.py
这段代码定义了一个MultiModalRAG类,用于处理PDF、PPT和图片文件,并将提取的内容转换为文档对象。以下是代码的主要功能和流程说明:
python
import os
import fitz # PyMuPDF库, 用于处理PDF文件
from llama_index.core import Document
from llama_index.core.async_utils import run_jobs
from .base_rag import RAG
from .utils import (
describe_image, # 描述图像内容
process_text_blocks, # 处理文本块
extract_text_around_item, # 提取项目周围的文本
process_table, # 处理表格
convert_ppt_to_pdf, # 将PPT转换为PDF
convert_pdf_to_images, # 将PDF转换为图像
extract_text_and_notes_from_ppt, # 从PPT中提取文本和备注
save_uploaded_file # 保存上传的文件
)
class MultiModalRAG(RAG):
@staticmethod
def parse_all_tables(filename, page, pagenum, text_blocks, ongoing_tables):
# 解析表格
pass
@staticmethod
def parse_all_images(filename, page, pagenum, text_blocks):
# 解析图像
pass
@staticmethod
def process_pdf_file(pdf_file):
# 处理PDF文件
pass
@staticmethod
def process_ppt_file(ppt_file):
# 处理PPT文件
pass
async def load_data(self) -> list[Document]:
"""Load and process multiple file types."""
documents = []
tasks = []
for file_path in self.files:
file_name = os.path.basename(file_path)
file_extension = os.path.splitext(file_name.lower())[1]
if file_extension in ('.png', '.jpg', '.jpeg'):
# 处理图片文件
pass
elif file_extension == '.pdf':
# 处理PDF文件
pass
elif file_extension in ('.ppt', '.pptx'):
# 处理PPT文件
pass
else:
# 处理文本文件
pass
await run_jobs(tasks, show_progress=True, workers=3)
return documents(二)功能说明
- 表格提取:从PDF页面中提取表格,保存为Excel文件,并生成包含表格内容和元数据的文档对象。
- 图像提取:从PDF页面中提取图像,生成描述性文本,并创建包含图像及其元数据的文档对象。
- 文本提取:从PDF页面中提取文本块,排除页眉和页脚,并生成文档对象。
- PPT处理:将PPT转换为PDF,提取幻灯片中的文本和备注,并生成文档对象。
- 异步加载:支持异步处理多种文件类型(PDF、PPT、图片、文本),并返回所有提取的文档对象。
(三)控制流图
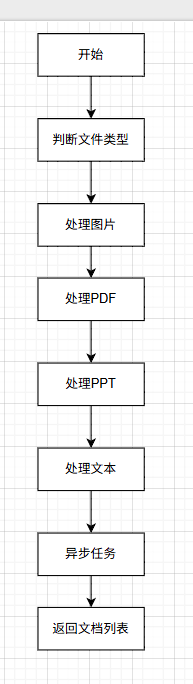
(四)流程说明
- 开始:程序启动。
- 判断文件类型:根据文件扩展名判断文件类型(图片、PDF、PPT、其他)。
- 处理图片 :调用
describe_image生成描述,并创建Document对象。 - 处理PDF :
- 提取表格、图像和文本。
- 表格保存为Excel,图像生成描述,文本排除页眉页脚。
- 创建对应的
Document对象。
- 处理PPT :
- 转换为PDF,提取幻灯片中的文本和备注。
- 生成
Document对象。
- 处理文本 :读取文件内容并创建
Document对象。 - 异步任务:初始化任务列表,添加任务,执行所有任务,返回文档列表。
四、总结
通过本文的详细介绍,我们全面了解了如何使用LlamaIndex开发一个多模态RAG系统。从系统架构的设计到各个功能模块的实现,再到用户界面的搭建,每一步都至关重要。多模态RAG系统的强大之处在于它能够整合多种模态的数据,并利用检索增强的方式提升生成模型的性能,从而为用户提供更准确、更丰富的回答。借助LlamaIndex框架和相关技术,开发者可以更高效地构建出满足实际需求的多模态RAG系统,为人工智能应用的发展注入新的活力。