一、索引概述
(一)索引的概念
索引是数据库中用于快速查找数据的数据结构,它就像书籍的目录,能帮助数据库管理系统快速定位到目标数据所在的位置,从而提升查询效率。需要注意的是,诸如二叉树等简单的索引结构只是示意,并非 MySQL 实际采用的索引结构。
(上述二叉树索引结构只是一个方便理解的示意图,并不是真实的索引结构)
(二)索引的优点
- 提升查询速度:对于大数据量表,索引可快速定位目标数据,避免全表扫描,大幅减少数据检索时间。
- 降低资源消耗:通过缩小数据扫描范围,减少磁盘 I/O 操作以及 CPU 资源的占用。
- 优化操作效率 :利用索引的有序性,能够优化排序(
ORDER BY)、分组(GROUP BY)和连接(JOIN)等操作,减少额外的计算开销。
(三)索引的缺点
- 增加写操作开销 :在执行
INSERT、UPDATE、DELETE等写入操作时,需要同步维护索引结构,会降低写操作的性能。 - 占用存储空间:索引文件会占用额外的存储空间,在某些情况下,索引文件的大小甚至可能与数据文件相当。
- 过度索引的影响:过度创建索引会进一步降低写性能,并且维护大量索引会给数据库带来沉重负担。
- 场景局限性:对于小表或者频繁进行全表扫描的场景,索引可能因为额外的维护和查找开销而无法发挥优化作用,甚至导致性能下降。
二、索引结构
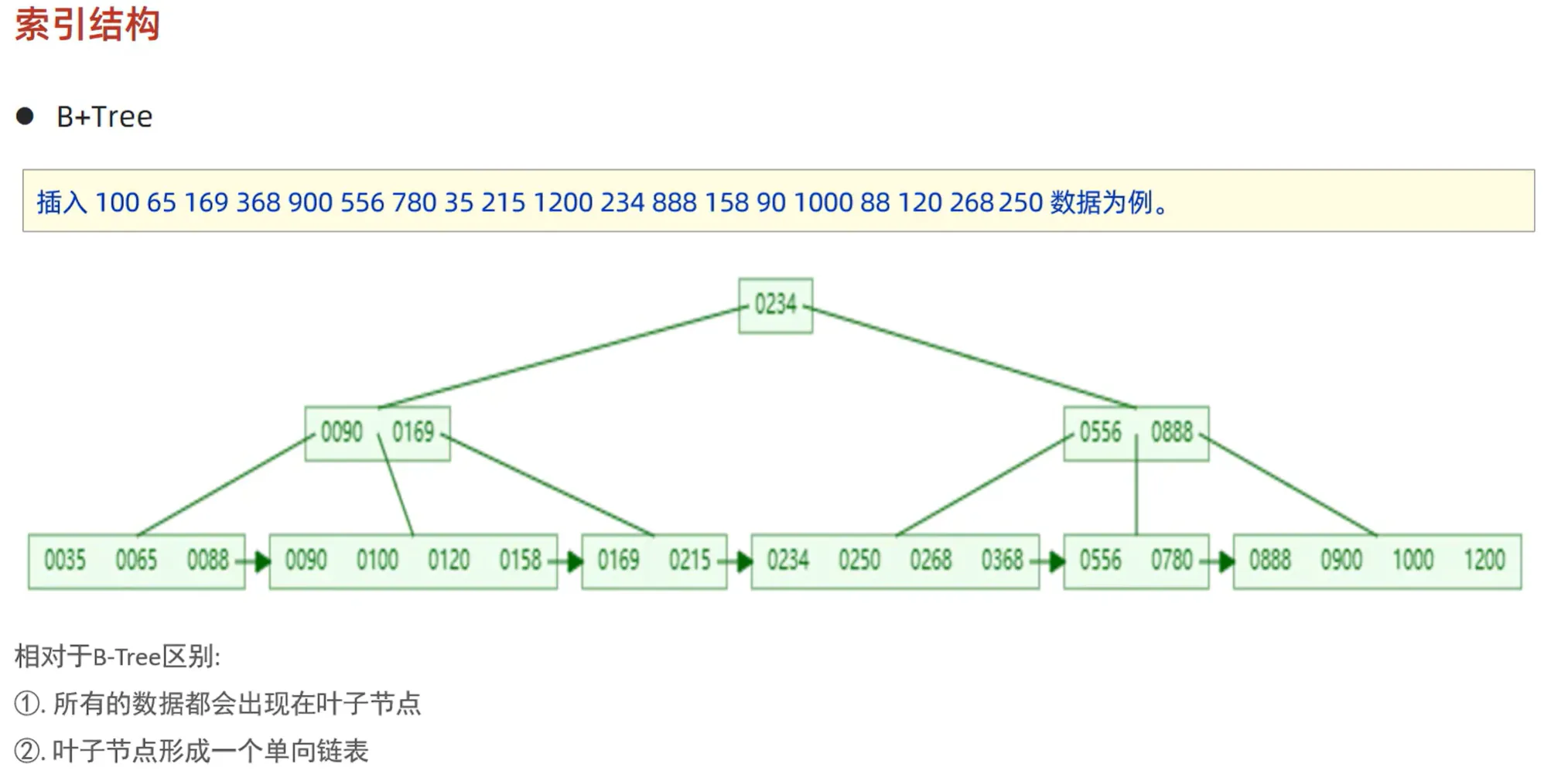
(一) B+Tree 结构
二叉树存在诸多缺点,比如在数据分布不均匀时,可能退化成链表,导致查询效率大幅降低。为解决这些问题,引入了 B 树。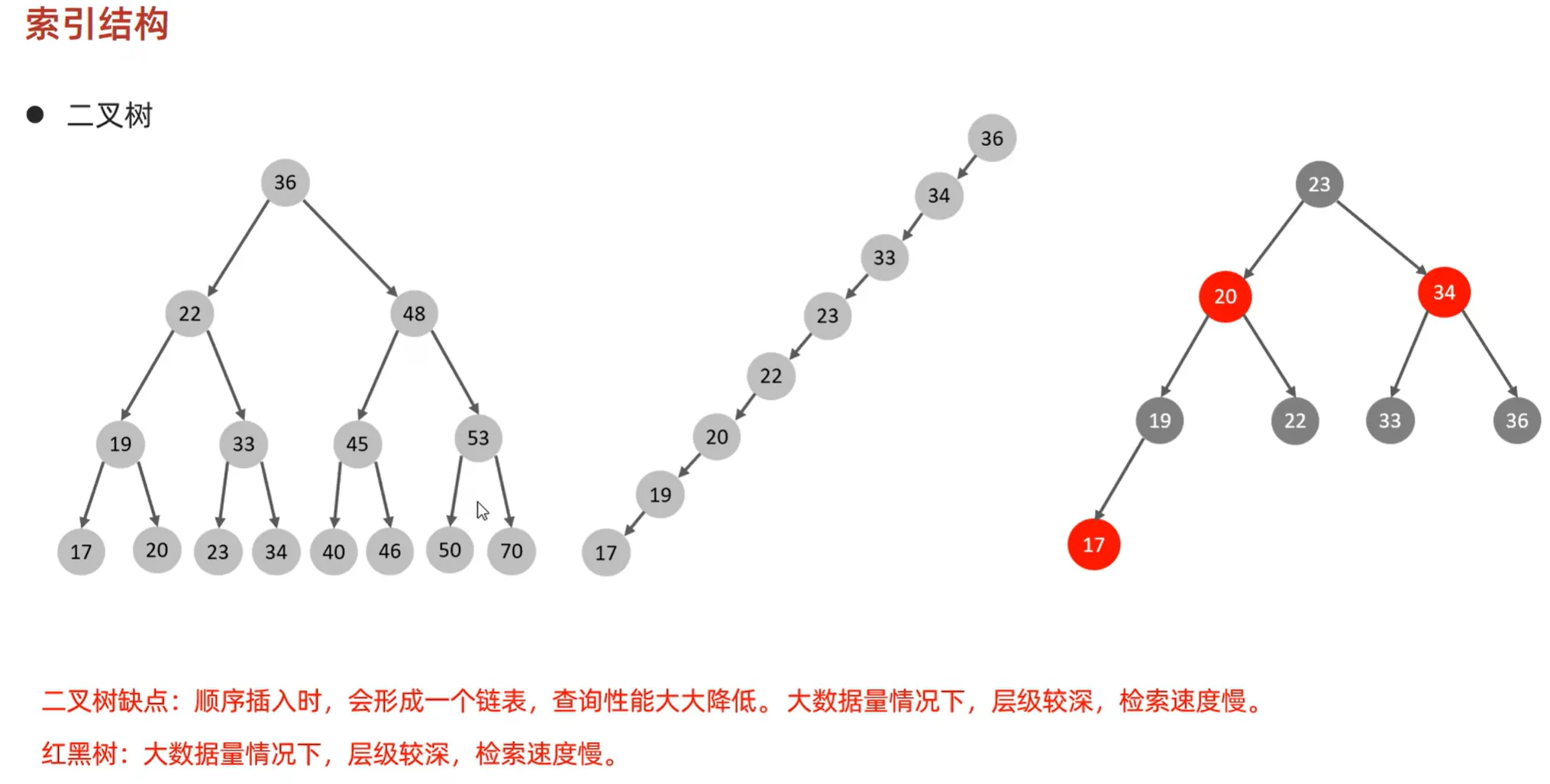 在引入B+树,之前先简单了解B树的结构
在引入B+树,之前先简单了解B树的结构
B 树是一种多路平衡查找树,它允许每个节点有多个子节点,能够更好地利用磁盘的预读特性,减少磁盘 I/O 次数,从而提升大数据量下的查询性能。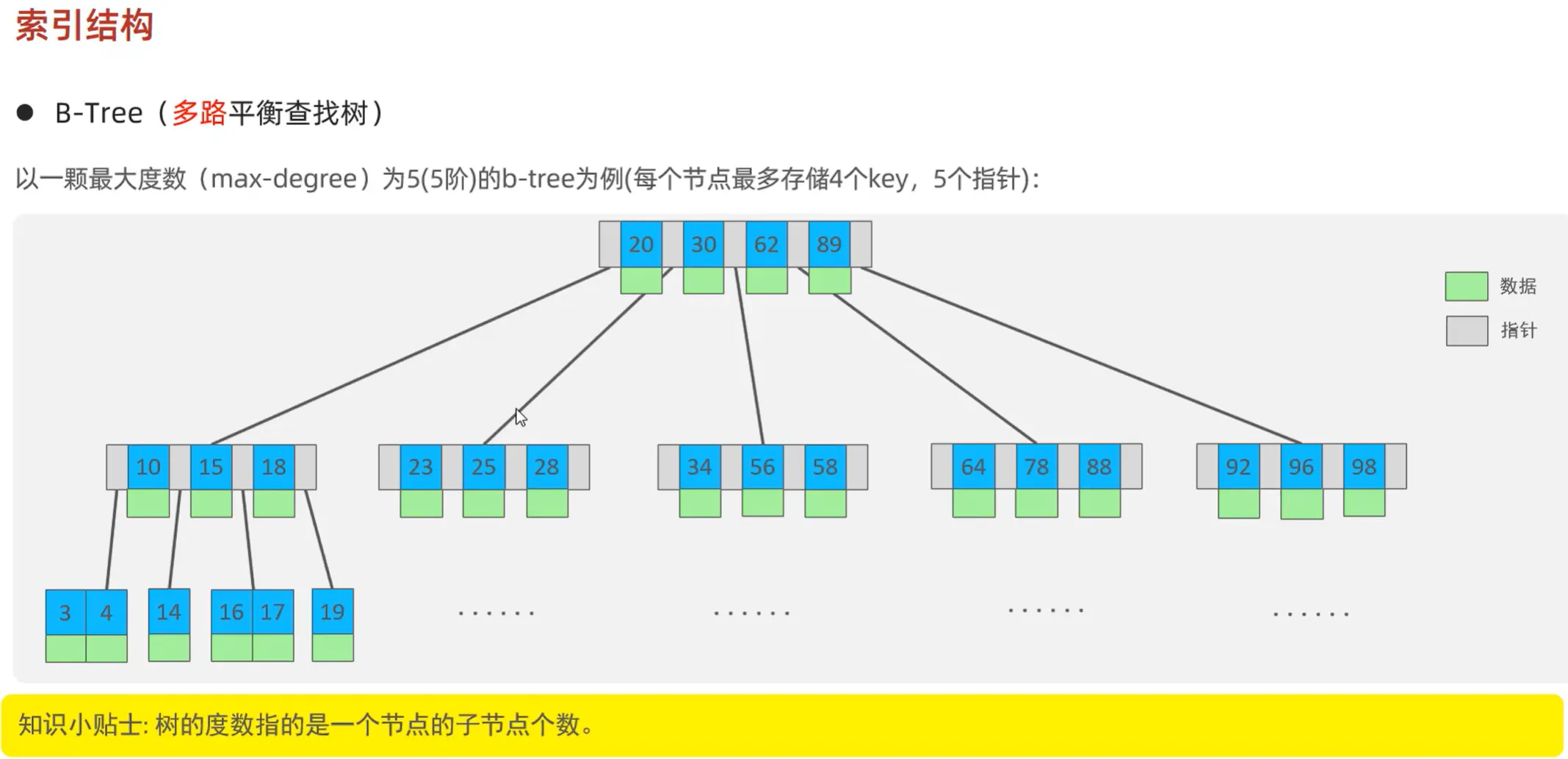
B树演变过程
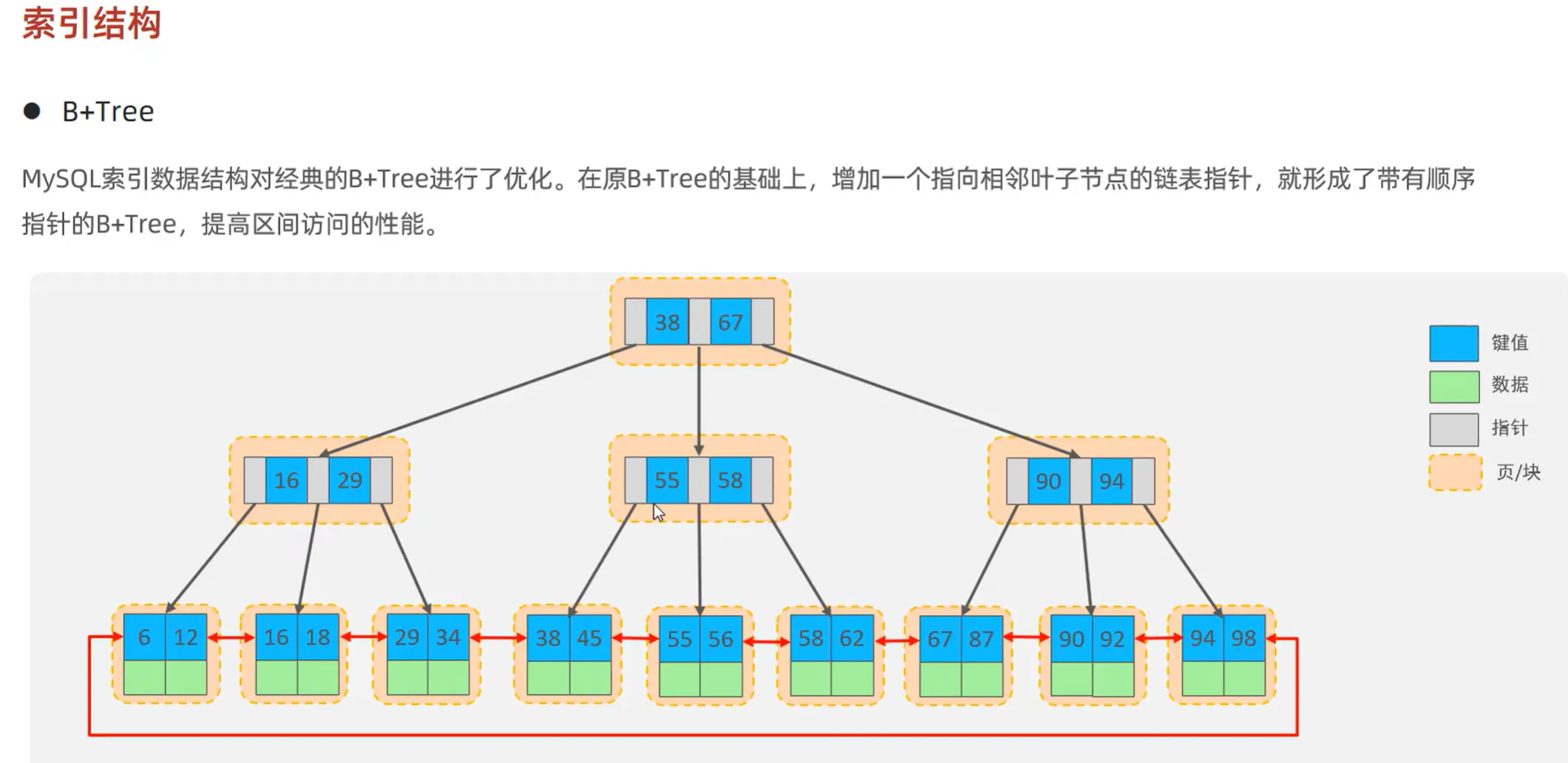
B+Tree 是在 B 树基础上的改进结构,具有以下特点:
- 所有的数据记录都存放在叶子节点中,非叶子节点只用于索引引导。
- 叶子节点之间通过链表相互连接,形成一个有序的链表结构,这使得范围查询变得更加高效,无需像 B 树那样在非叶子节点和叶子节点之间来回查找。
 (二)Hash 结构
(二)Hash 结构
Hash 索引基于哈希表实现,它通过计算数据的哈希值来快速定位数据。其优点是等值查询速度极快,但缺点也很明显,无法进行范围查询,且在哈希冲突较多时,性能会受到影响。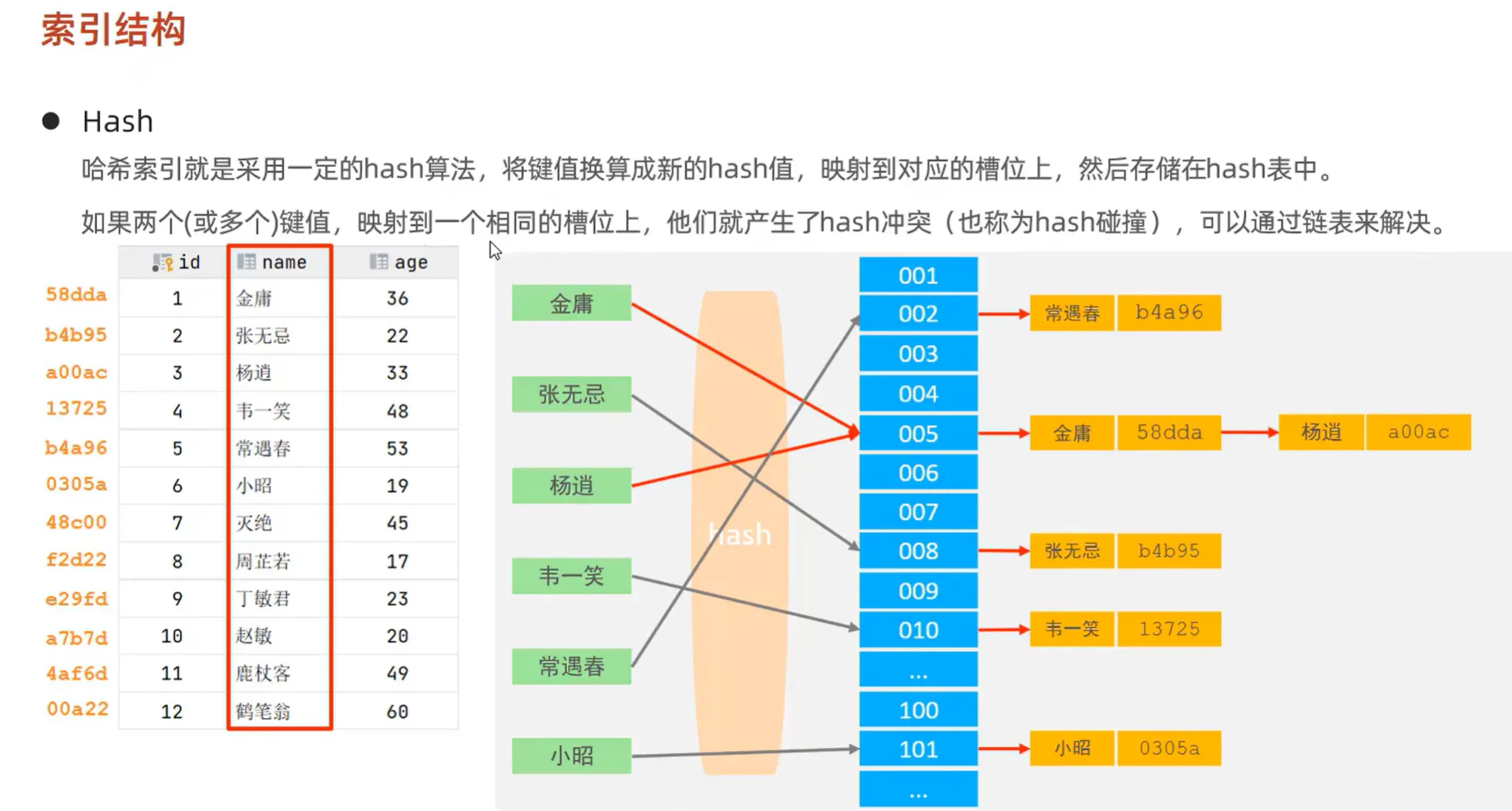
三、索引分类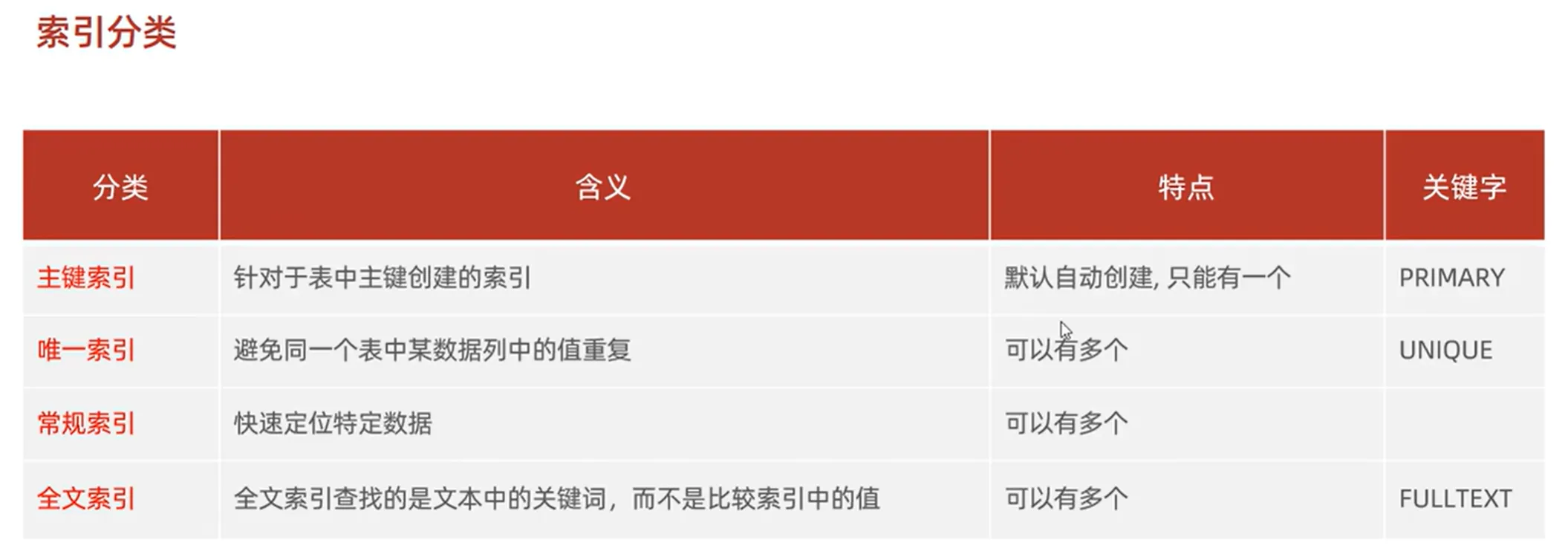
(一)聚集索引与二级索引(以 InnoDB 存储引擎为例)
在 InnoDB 存储引擎中,若表定义了主键,InnoDB 会默认将主键作为聚集索引的键;如果没有主键,会按规则选择一个唯一非空列 作为聚集索引键;要是连唯一非空列都没有,会隐式创建一个自增的隐藏列作为聚集索引键。
- 聚集索引:键为表的主键,值为完整的行数据,数据在磁盘上会按照主键的顺序进行物理存储。例如创建如下表:
sql
CREATE TABLE user (
id INT PRIMARY KEY AUTO_INCREMENT, -- 主键
name VARCHAR(50) NOT NULL
) ENGINE=InnoDB; -- InnoDB 引擎执行后,InnoDB 会自动为id(主键)创建聚集索引,无需手动声明。
- 二级索引:键为表中的非主键字段,值为对应记录的主键值。当通过二级索引查询数据时,需要先通过二级索引找到主键值,再通过聚集索引回表查询完整的行数据。
(二)主键索引与唯一索引
在数据库中,主键约束(PRIMARY KEY)和唯一约束(UNIQUE)会自动创建对应的索引。主键索引具有唯一性和非空性,用于唯一标识表中的每一行数据;唯一索引则确保索引列的值唯一,但允许存在NULL值(最多一个NULL)。
聚集索引 键:主键 值:行数据
二级索引 键:字段 值:对应主键值
四、索引语法
MySQL 提供了丰富的索引操作语法,用于创建、删除、查看索引等。例如:
-
创建索引
sqlCREATE INDEX index_name ON table_name (column_name); -
删除索引
sqlDROP INDEX index_name ON table_name; -
查看表的索引
sqlSHOW INDEX FROM table_name;
五、性能优化相关工具与方法
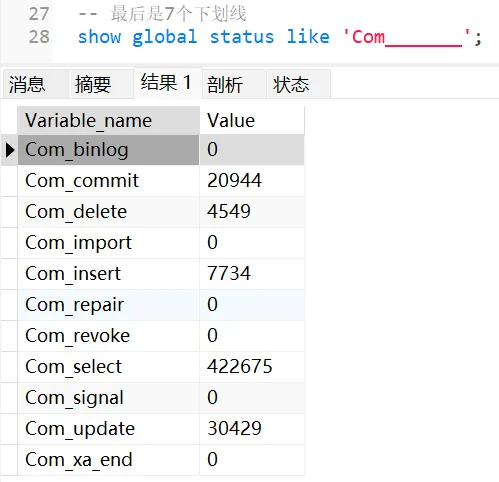
(一)查看执行频次
可以通过相关命令查看 SQL 语句的执行频次,了解哪些 SQL 被频繁执行,以便针对性地进行优化。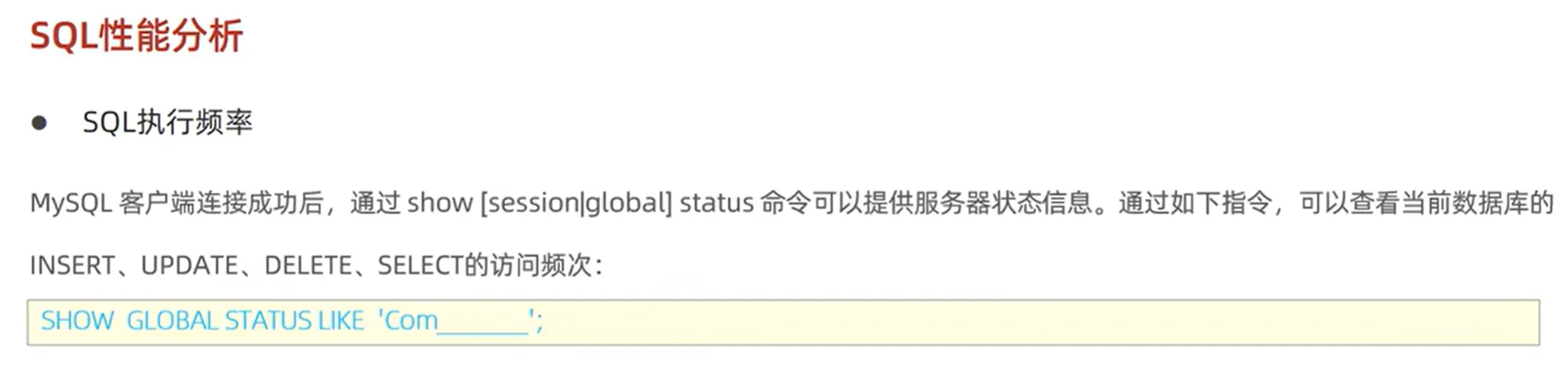
(二)慢查询日志
慢查询日志的作用是记录执行时间较长、效率低下的 SQL 查询。通过分析慢查询日志,能够找出需要优化的 SQL 语句。
(三)show profile
SHOW PROFILE 是 MySQL 中用于分析 SQL 执行过程资源消耗的工具,能精准定位 SQL 执行缓慢的具体环节,核心总结如下:
1. 核心作用
- 跟踪 SQL 执行的完整生命周期,展示从 "语句解析" 到 "数据返回" 各阶段的耗时、CPU 占用、磁盘 I/O 等资源消耗,帮开发者找到性能瓶颈(如某阶段耗时过长)。
2. 关键使用逻辑
- 开启功能 :默认关闭,需先执行
SET profiling = ON;开启(仅当前会话有效); - 执行目标 SQL :运行需要分析的查询语句(如
SELECT * FROM users WHERE id > 100;); - 查看 profile 列表 :执行
SHOW PROFILES;查看所有已记录的 SQL 及其 ID(Query_ID); - 查看详情 :执行
SHOW PROFILE [资源类型] FOR QUERY Query_ID;(如SHOW PROFILE CPU, BLOCK IO FOR QUERY 1;),查看指定 SQL 各阶段的资源消耗。
3. 核心关注信息
- 阶段(State) :SQL 执行的具体步骤(如
starting初始化、Opening tables打开表、Sending data数据传输等); - 耗时(Duration) :各阶段的执行时间(重点关注耗时远超其他阶段的步骤,如
Sending data过长可能是扫描行数过多); - 资源消耗 :可选查看 CPU 占用(
CPU)、磁盘 I/O(BLOCK IO)等,定位资源瓶颈(如高磁盘 I/O 可能是索引缺失导致全表扫描)。
4. 优化核心思路
- 重点排查 "耗时异常阶段"(如
Creating tmp table临时表耗时久,需优化排序 / 分组逻辑;Full scan全表扫描,需加索引); - 结合
EXPLAIN使用:EXPLAIN看执行计划,SHOW PROFILE看实际执行消耗,两者配合定位 "计划与实际消耗不匹配" 的问题。

(四)explain 执行计划
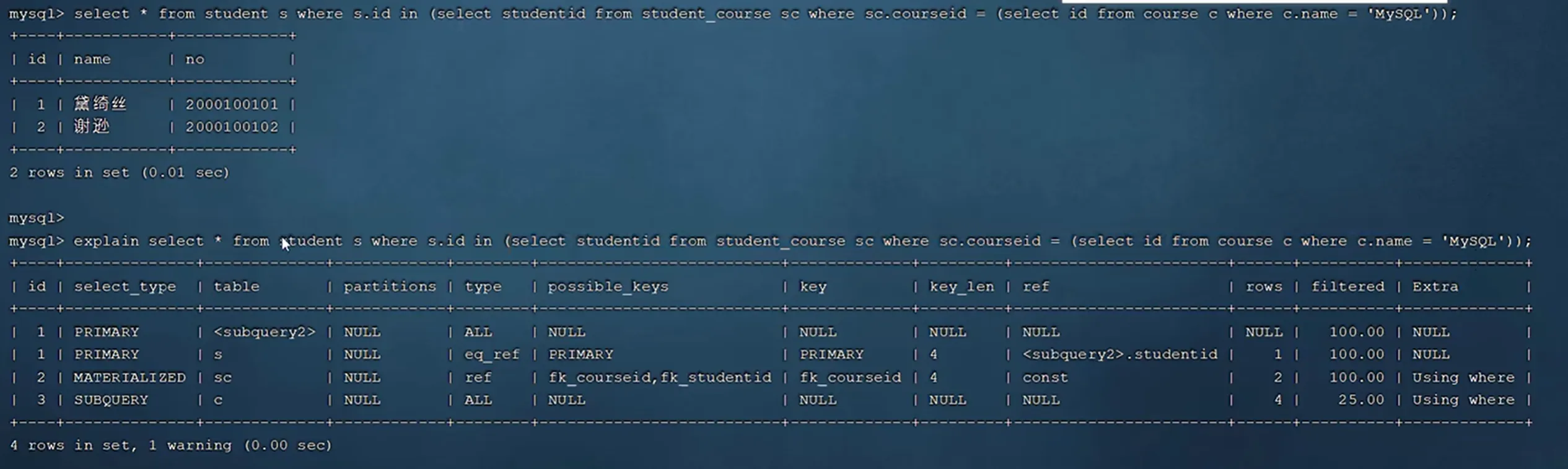
EXPLAIN 是 MySQL 中分析 SQL 查询执行计划的核心工具,能直观展示查询优化器的执行逻辑,帮助定位性能问题,核心总结如下:
1. 核心作用
- 查看表的读取顺序、实际使用的索引、数据扫描方式、预估读取行数等,判断查询是否高效,为优化提供依据。
2. 关键字段及核心含义
| 字段 | 核心作用 |
|---|---|
id |
标识查询中 SELECT 子句的执行顺序:id 相同则从上到下执行,id 不同则值大优先执行。 |
select_type |
区分查询类型(如 SIMPLE 简单查询、PRIMARY 主查询、SUBQUERY 子查询等)。 |
table |
显示查询涉及的表名(派生表 / 子查询显示 <derivedN>/<subqueryN>)。 |
type |
表的连接类型(性能从优到差:null>system > const > eq_ref > ref > range > index > all),避免 all(全表扫描)。 |
key |
实际使用的索引(NULL 表示未用索引,需排查原因)。 |
rows |
预估需读取的行数(值越小越好,反映查询扫描范围)。 |
Extra |
额外执行信息(如 Using index 代表覆盖索引,Using temporary/Using filesort 需优化)。 |
type 连接类型含义

3. 优化核心思路
- 看
type:尽量让连接类型接近const/eq_ref,避免all; - 看
key:确保使用合适索引,无索引则需新增或调整查询; - 看
Extra:消除Using temporary(临时表)和Using filesort(文件排序),优先实现Using index(覆盖索引)。
六、索引使用相关规则与场景
(一)最左前缀法则
对于联合索引,需要遵循最左前缀法则,即查询时要从联合索引的最左列开始使用索引,否则可能导致索引失效。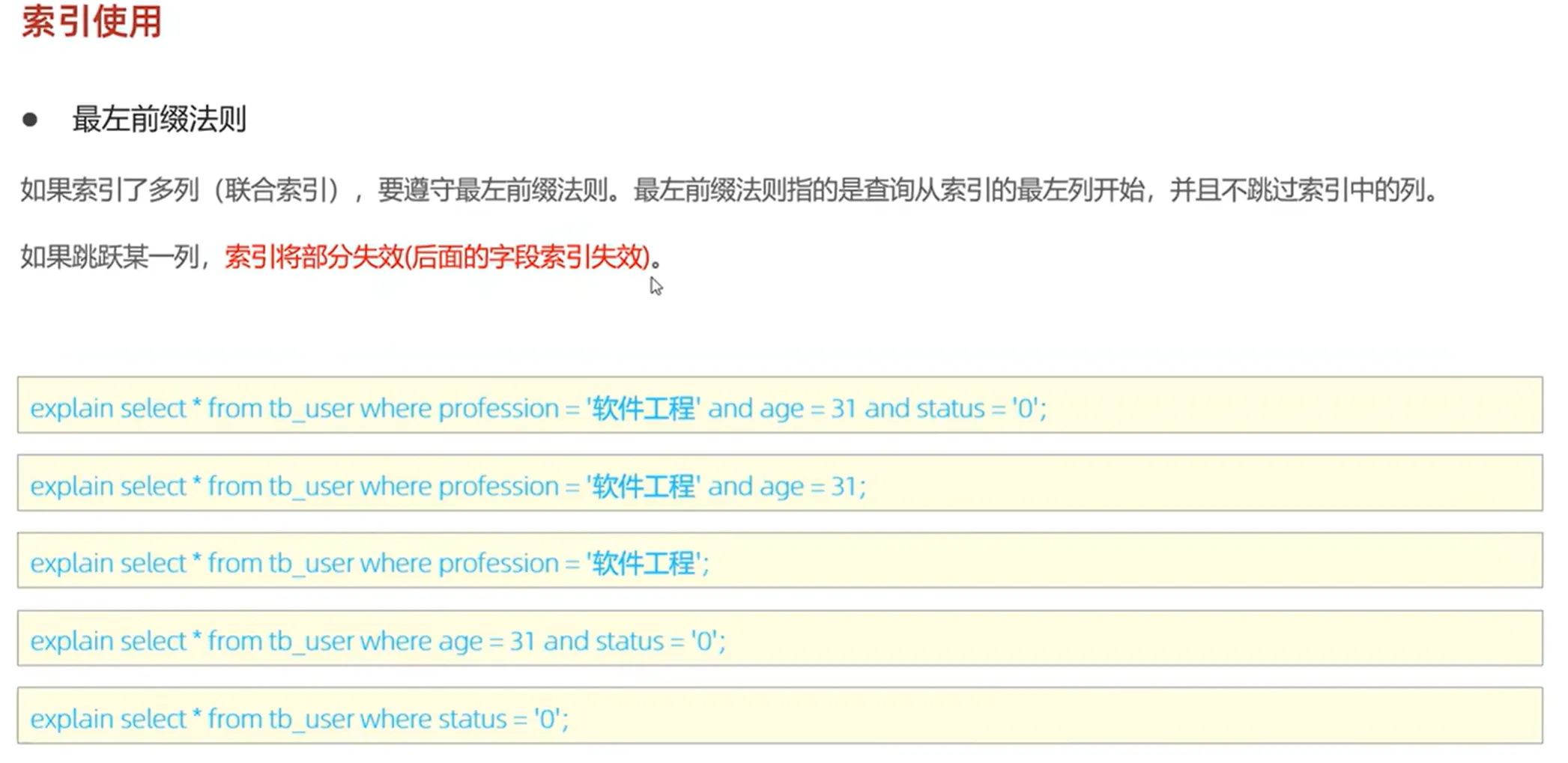
(二)索引失效场景
1. 索引列参与函数操作或计算
对索引列进行函数处理(如SUBSTR()、DATE_FORMAT())或数学运算(如price + 1),会导致索引失效。例:WHERE SUBSTR(username, 1, 3) = 'abc'(对username索引列使用函数)
2. 索引列发生类型转换
索引列与查询条件的值类型不匹配,触发隐式类型转换,导致索引失效。例:WHERE phone = 13800138000(phone是字符串类型,条件用数字)
3. 违反最左前缀法则
联合索引需从最左列开始使用,跳过左侧列会导致索引失效。例:联合索引(a, b, c),查询WHERE b = 2 AND c = 3(跳过a,索引失效)
4. 使用不等符号或否定判断
对索引列使用<>、NOT IN、NOT EXISTS、!=等操作,可能导致索引失效(视数据分布而定)。例:WHERE status <> 'active'
5. LIKE以通配符开头
LIKE '%xxx'或LIKE '%xxx%'会导致索引失效(LIKE 'xxx%'可使用索引)。例:WHERE username LIKE '%zhang'
6. OR连接非索引列
OR两侧条件中,若一侧无索引,另一侧有索引,会导致索引失效。例:WHERE id = 1 OR age = 30(age无索引,id索引失效)
7. 全表扫描更高效的场景
- 表数据量极小(如仅几百行),全表扫描比索引查找更快;
- 查询结果占表数据比例过高(如超过 30%),优化器可能选择全表扫描。
8. 索引列使用IS NULL/IS NOT NULL
某些情况下,对索引列使用IS NULL或IS NOT NULL可能导致索引失效(视索引类型和数据分布而定)。
9. 存储引擎不支持的索引类型
如 MyISAM 表的全文索引在特定查询条件下可能失效,或 Hash 索引不支持范围查询。
(三)SQL 提示
可以使用USE INDEX和FORCE INDEX等 SQL 提示来干预查询优化器对索引的选择。
·USE INDEX是建议性的,查询优化器可自主决定是否采纳;
·FORCE INDEX是强制性的,查询优化器必须使用指定索引。
(四)覆盖索引
核心:联合索引,避免回表查询
覆盖索引是指二级索引包含了查询所需的所有字段,此时不需要回表查询。例如,若username、password、status建立了联合索引,当查询这三个字段时,可直接通过该联合索引获取数据,无需回表。需要注意的是,使用select *极易发生回表查询,应尽量避免。
(五)前缀索引
核心:针对 varchar类型和 test类型,避免索引存储空间大量占用
前缀索引是对列的前缀部分建立索引,可减少索引的存储空间,但可能会影响索引的选择性。在回表查询到行数据后,会比对相关字段(如email)是否相同,相同则返回,不同则重新查询二级索引链表上原位置的下一个位置。
(六)单列索引和联合索引
当phone和name都建立了单列索引时,若phone是唯一索引,查询时可能只需要用到idx_user_phone就能查询出结果。在explain的Extra列中,若值为null,说明用到了回表查询。
七、索引设计原则
- 针对于数据量较大,且查询比较频繁的表建立索引。
- 针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引。
- 尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高。
- 如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引。
- 尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率。
- 要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率。
- 如果索引列不能存储 NULL 值,请在创建表时使用 NOT NULL 约束它。当优化器知道每列是否包含 NULL 值时,它可以更好地确定哪个索引最有效地用于查询。