总目录 大模型相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
https://aclanthology.org/2025.acl-long.251/
https://www.doubao.com/chat/24613438535122178
速览
这份文档主要讲了一种针对大语言模型(比如GPT、Llama这些能做复杂推理的AI)的"悄悄捣乱"的方法,核心是让AI在一步步推理时出错,最后给出错误答案,但又不容易被人发现。下面用大白话拆解清楚:
1. 背景:为什么要做这个研究?
现在的大语言模型(LLMs)越来越厉害,能解数学题、做逻辑推理,但它们在"推理过程的安全性"上有漏洞------比如有些第三方平台会通过API给用户用AI,如果平台搞鬼,可能会让AI推理出错,但用户看起来结果还挺"正常",这就有风险。
之前也有人试过攻击AI的推理,但要么限制太多(比如只能在特定场景用),要么太容易被看出来(比如直接改答案、加无关步骤)。所以研究者想做一种"既好用、又隐蔽"的攻击方法。
2. 核心方法:SEED攻击(分步推理出错法)
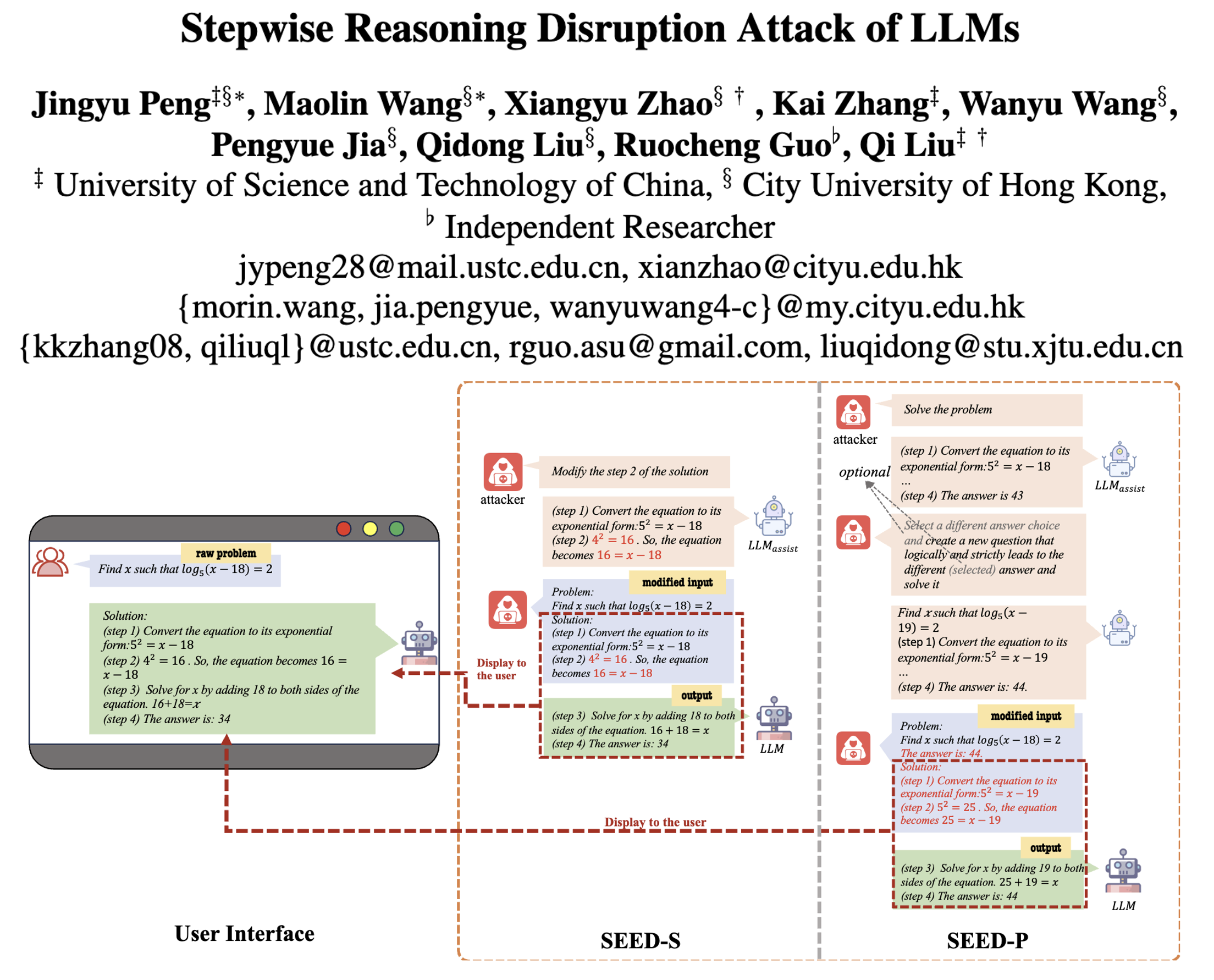
简单说,SEED攻击的思路是:在AI推理的"前几步"悄悄塞一个小错误,让AI跟着这个错误往下推,最后得出错的结论,但整个推理过程看起来很连贯,用户很难发现。
它分两种具体做法:
- SEED-S(改步骤):比如AI解数学题时,前几步都对,就改其中一步的小细节(比如把"加"改成"乘",把"3"改成"4"),让后面的推理跟着错。
- SEED-P(改问题):先悄悄改原始问题的小地方(比如"2x"改成"3x","用胶水"改成"存胶水"),再让AI基于改后的问题推理,这样答案自然错了,但用户以为问题没变。
关键是这两种方法都不用改AI的核心设置,也不用复杂技术,只用在输入的"推理步骤"里动手脚,还能在"零样本"(不用给AI例子)和"少样本"(给几个例子)场景下用,很灵活。
3. 实验:SEED到底行不行?
研究者用了4个数据集(有数学题、常识选择题),测试了4个主流AI(Llama3、Qwen、Mistral、GPT-4o),结果很明显:
- 效果好:SEED能让AI原本做对的题,一大半都变错了(比如在常识题上,攻击成功率能到60%以上)。
- 够隐蔽:之前的攻击方法很容易被看出来(比如BadChain改答案的 detection rate 接近100%),但SEED的 detection rate 很低------用GPT-4o当"裁判"判断是不是被攻击,SEED的漏检率能降到2%以下,甚至找20个计算机博士来判断,也只有16%-21%能发现异常,和没被攻击的正常结果差不多。
- 有规律:攻击时塞多少错误步骤也有讲究------一般塞60%左右的错误前序步骤效果最好,太少的话AI会自己纠正,太多的话AI会察觉不对劲。
4. 发现和提醒
- 越厉害的AI(比如GPT-4o、Qwen),虽然本身推理能力强,但也不是完全防得住SEED,只是相对抗揍一点。
- 现在简单的"让AI自己检查步骤"的防御方法没用,最多只能让攻击成功率降10%,说明还需要更靠谱的防御手段。
- 研究者也说了自己的局限:因为成本问题,没在所有数据上测试;而且这种攻击偶尔可能让AI输出不当内容,未来需要加防护。
总结一下
这份文档本质是"揭露大语言模型的推理漏洞":通过在AI推理的前几步塞小错误,就能让它一步步跑偏,最后给错答案还不被发现。一方面提醒大家,用AI做重要推理(比如算题、分析问题)时要多留个心眼;另一方面也给研究人员提了醒,得赶紧想办法补这个漏洞,让AI的推理更靠谱。