
前言
在大模型狂飙突进的今天,开源社区似乎陷入一种奇特的悖论:模型权重免费公开,但真正能复现结果的人寥寥无几。你下载一个号称"SOTA"的多模态模型,跑起来却发现效果平平;想自己训练?数据来源模糊、训练脚本缺失、超参配置像谜语------开源成了"半开源",复现成了玄学。这种困境,在视觉语言模型(VLM)领域尤为突出。
而 LLaVA 系列,从 2023 年初的横空出世,到如今 LLaVA-OneVision-1.5 的全面开放,恰恰是在试图打破这一僵局。它不再满足于"放出权重",而是把整个训练厨房------锅碗瓢盆、食材清单、火候控制------全部摊开在你面前。这不仅是一次技术迭代,更是一场关于"开源精神"的自我救赎。
在企业纷纷押注私有模型、闭源API的当下,LLaVA-OV 1.5 的出现,为那些想真正掌控技术命脉的团队提供了一条清晰、低成本、可验证的落地路径。本文将深入剖析这个模型为何值得你停下脚步,认真对待。
1. LLaVA 的进化:从"能看图说话"到"统一多模态接口"
1.1 从 LLaVA-1.0 到 LLaVA-OneVision:一条清晰的能力跃迁曲线
2023 年 4 月,LLaVA-1.0 的诞生改变了开源多模态的格局。
它是一个没有从头设计复杂的架构,而是巧妙地将现成的 CLIP 视觉编码器与 Vicuna 语言模型通过一个简单的 MLP 投影层连接起来。训练方式也极为务实:用 GPT-4 生成图文指令对,再微调整个系统。这种"视觉指令微调"(Visual Instruction Tuning)策略,让开源模型首次具备了与用户进行图文对话的能力,且成本极低。
短短半年后,LLaVA-1.5 引入更高分辨率的 ViT-L/14(336px),训练时间压缩至单机 8 卡 A100 一天内完成,却在 11 项基准测试中刷新纪录。这标志着 LLaVA 团队开始追求"高效"与"简洁"的平衡------不靠堆资源,而靠数据质量和训练策略取胜。
2024 年,进化加速。LLaVA-NeXT 将图像输入分辨率提升至 1344px,在 OCR 和复杂推理任务上显著超越 Gemini Pro。随后的 LLaVA-NeXT-Video 则展示了惊人的泛化能力:一个仅在图像上训练的模型,竟能零样本理解视频内容。到了 LLaVA-NeXT-Interleave,模型已能统一处理单图、多图、视频甚至 3D 多视图输入。最终,所有分支汇聚为 LLaVA-OneVision,实现了"一个模型,多种输入"的统一接口。
这条进化路径清晰地表明:LLaVA 团队的目标不仅是提升性能,更是构建一个通用、灵活、可扩展的多模态基础框架。
1.2 开源的"鸿沟":权重开放 ≠ 能力可复现
尽管 LLaVA 系列不断进步,整个开源多模态社区仍面临一个根本性问题:模型权重可以下载,但训练路径无法复制。许多号称"开源"的模型,如 Qwen2.5-VL、InternVL3.5,虽然性能强劲,却只公布部分训练细节。数据清洗规则、混合比例、采样策略、学习率调度等关键"配方"往往语焉不详。这导致社区无法验证其结果,更难以在其基础上改进。
Molmo 项目尝试用更干净的数据流水线逼近闭源模型,Open-Qwen2VL 则证明少量高质量数据也能取得优异效果。这些探索共同指向一个结论:当前多模态模型的瓶颈,已从架构设计转向训练工程的可复现性。LLaVA-OneVision-1.5 正是在这一背景下诞生的"破局者"。
2. LLaVA-OneVision-1.5 的核心突破:可复现性作为第一原则
2.1 三阶段训练:从对齐到全能的系统化路径
LLaVA-OneVision-1.5 的训练被明确划分为三个阶段,每一阶段目标清晰,互为支撑:
-
阶段1:语言-图像对齐
使用 LLaVA-1.5 的 558K 高质量图文对,仅训练投影层(MLP),使视觉特征能被语言模型正确理解。这一步确保模型具备基本的跨模态对齐能力。
-
阶段1.5:高质量知识注入(中期训练)
这是性能跃升的关键。模型所有参数解冻,在 8500 万样本的 LLaVA-OneVision-1.5-Mid-Training 数据集上进行全参数训练。研究发现,仅扩展此阶段数据,无需复杂训练范式,即可达到 SOTA 水平。这颠覆了"必须用多阶段、多损失函数"的行业惯性思维。
-
阶段2:视觉指令微调(SFT)
使用 2200 万样本的 LLaVA-OneVision-1.5-Instruct 数据集,覆盖标题生成、图表理解、代码数学、定位计数等七类任务,使模型具备遵循复杂指令的能力。
这种三阶段设计,将"基础对齐"、"知识扩展"、"任务适配"解耦,既保证训练稳定性,又便于社区分阶段复现和调试。
2.2 数据即壁垒:概念均衡与高质量过滤
模型能力的上限由数据决定。LLaVA-OneVision-1.5 在数据构建上投入巨大精力:
-
概念均衡采样(Concept Balancing)
传统数据集依赖图片原始标题,但这些标题往往偏向常见物体(如"狗""车"),忽略罕见概念(如"分光计""拓扑结构")。LLaVA 团队引入 50 万个预定义概念词条,将每张图片通过向量相似度匹配到最相关概念。由于概念本身是均衡分布的,采样时会主动提升罕见概念图片的权重,确保模型"知识面广而不偏"。
-
严格的质量过滤
所有图文对均经过多轮过滤:去除低分辨率图像、模糊文本、重复内容、低信息量描述等。中期训练数据中,OCR 相关样本占比显著提升,直接支撑其在文档理解任务上的优势。
这种数据策略,使得 LLaVA-OneVision-1.5 在 ScienceQA、DocVQA 等知识密集型任务上表现尤为突出。
3. 架构与工程:效率与性能的双重优化
3.1 视觉编码器的革新:RICE-ViT 的精准感知
LLaVA-OneVision-1.5 没有沿用主流的 SigLIP 或 DFN,而是选择 RICE-ViT 作为视觉编码器。这一选择极具战略意义:
- 区域感知能力:RICE-ViT 能精准聚焦图像中的特定区域,尤其擅长处理文档中的文字块、图表元素,而非仅做全局理解。
- 原生支持可变分辨率:无需对不同尺寸图像进行切块或特殊微调,简化了预处理流程,提升了工程效率。
- 统一损失函数:仅用一个聚类判别损失,同时优化通用理解、OCR 和目标定位能力,避免多任务冲突。
消融实验证明,RICE-ViT 在 OCR 和文档理解任务上显著优于 CLIP-ViT-L。
3.2 语言模型主干:Qwen3 的强大推理基座
语言模型选用 Qwen3,其在代码生成、数学推理、长文本理解方面表现优异,为 LLaVA 的复杂任务处理提供了坚实基础。8B 和 4B 两个版本均基于 Qwen3 微调,确保了语言能力的上限。
3.3 训练效率革命:离线数据打包与 Megatron-LM 优化
训练大模型的最大成本之一是 padding 浪费。传统方式中,短样本需填充至批次最大长度,导致 GPU 利用率低下。
LLaVA 团队提出 离线并行数据打包 :在预处理阶段,将多个短样本合并为接近最大长度的序列。在 8500 万样本上,该方法实现 11 倍压缩比,大幅减少无效计算。
训练框架基于 Megatron-LM ,支持 MoE、FP8、长序列并行等高级特性。中期训练在 128 张 A800 GPU 上仅耗时 3.7 天 ,总成本约 16000 美元(按 A100 $0.6/小时计)。这使得中小团队也能负担顶级模型的训练。
4. 性能实测:全面超越,尤其在企业刚需场景
4.1 基准测试结果:8B 模型碾压同级竞品
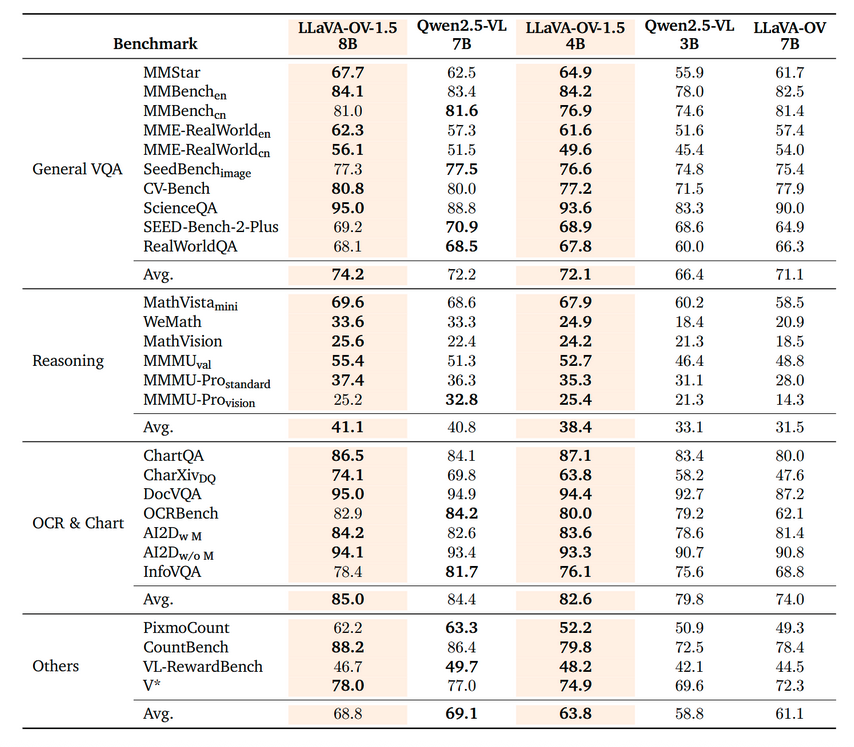
下表对比 LLaVA-OneVision-1.5 与 Qwen2.5-VL 在四大任务类别上的表现:
| 任务类别 | LLaVA-OV-1.5 8B | LLaVA-OV-1.5 4B | Qwen2.5-VL 7B | Qwen2.5-VL 3B |
|---|---|---|---|---|
| 通用视觉问答 (VQA) | 74.2 | 72.1 | 72.2 | 66.4 |
| 推理能力 (Reasoning) | 41.1 | 38.4 | 40.8 | 33.1 |
| OCR 与图表理解 | 85.0 | 82.6 | 84.4 | 79.8 |
| 其他任务 (Others) | 68.8 | 63.8 | 69.1 | 58.8 |
LLaVA-OV-1.5 8B 在 27 项基准中的 18 项 领先,尤其在 OCR、推理、VQA 等企业高频场景优势明显。更令人惊讶的是,4B 版本在多数任务上接近甚至超越 Qwen2.5-VL 7B,展现出极高的参数效率。
4.2 企业落地价值:文档理解与知识问答的杀手级应用
对于企业而言,多模态模型的核心价值在于处理非结构化文档:发票、合同、报表、产品图、技术图纸等。LLaVA-OV-1.5 在 DocVQA、ChartQA 等任务上的高分,意味着它能:
- 自动提取发票中的金额、日期、供应商信息;
- 理解销售报表中的趋势并生成文字摘要;
- 回答"这张电路图中 R5 的阻值是多少?"这类定位+OCR 问题。
这些能力直接对应企业自动化、智能客服、知识管理等真实场景,无需微调即可开箱即用。
5. 开源生态:一份真正的"顶级菜谱"
5.1 全栈开放:从数据到日志,无一遗漏
LLaVA-OneVision-1.5 的最大贡献,不是模型本身,而是其完整的可复现生态:
- 数据公开:中期训练数据(85M)、指令微调数据(22M)全部开放;
- 代码开源:训练、推理、评估脚本完整提供;
- 配置透明:所有超参、学习率、批次大小、优化器设置明确列出;
- 日志共享:TensorBoard 训练曲线公开,便于社区验证收敛行为;
- 工具链完善:包含数据打包、概念均衡采样、评测命令生成等工具。
这种"厨房全开"的做法,让任何团队都能从零开始,低成本复现一个顶级多模态模型。
5.2 社区赋能:降低创新门槛
过去,多模态研究被大公司垄断,因其依赖海量数据和算力。LLaVA-OV-1.5 证明:通过高效训练和高质量数据,小团队也能产出 SOTA 模型。这将极大激发社区创新:
- 高校实验室可基于此框架研究新任务;
- 初创公司可快速构建垂直领域多模态助手;
- 企业可安全地在私有数据上微调,避免 API 依赖。
开源不再只是"分享结果",而是"共享能力"。
6. 未来展望:统一多模态的终极形态
LLaVA-OneVision-1.5 已支持图像、多图、视频输入,下一步或将整合音频、3D 点云,迈向真正的全模态统一模型。其三阶段训练范式、概念均衡策略、高效打包方法,也可能成为行业新标准。
更重要的是,它重新定义了"开源"的含义:真正的开源,是让任何人能在合理成本下,复现、验证、改进你的工作。在这个闭源 API 泛滥的时代,LLaVA-OV-1.5 像一盏灯,照亮了技术民主化的可能路径。
结语
LLaVA-OneVision-1.5 的出现,标志着开源多模态进入"可复现时代"。它不靠营销噱头,不靠参数堆砌,而是用扎实的数据、透明的工程、优雅的设计,证明了开源精神依然能驱动技术前沿。对于企业而言,这不仅是一个模型,更是一条可控、可审计、可定制的 AI 落地路径。在这个人人都在谈"AI 落地"的时代,或许最稀缺的不是算力,不是数据,而是一份真正能让你"从零做起"的信任与透明。LLaVA-OV-1.5 给了我们这份礼物------它让我们相信,顶级 AI 的大门,终究是向所有人敞开的。