1 相关性概述
1.1 什么是相关性(Relevance)
-
在搜索引擎中,相关性 是描述一个文档与查询语句匹配程度的度量标准 ,通过为匹配查询条件的文档计算相关性评分(_score) 来实现,评分越高表示文档与查询语句的匹配程度越高;
-
搜索是用户和搜索引擎的"对话",用户关心的相关性维度包括:
-
是否可以找到所有相关的内容
-
有多少不相关的内容被返回
-
文档的打分是否合理
-
能否结合业务需求,平衡结果排名
-
-
例:查询"JAVA多线程设计模式"。通过关键词与文档ID的匹配关系,可判断文档相关性:
关键词 文档ID JAVA 1,2,3 设计模式 1,2,3,4,5,6 多线程 2,3,7,9 - 查询"JAVA多线程设计模式"时,文档2、3同时匹配三个关键词,因此文档2、3的相关性评分更高;
-
ElasticSearch的相关性实现
-
ElasticSearch使用评分算法,根据查询条件与索引文档的匹配程度确定每个文档的相关性;
-
支持用户自定义评分,以满足各种特定业务需求;
-
检索结果中,
_score字段直观体现文档与查询的匹配程度(由正浮点数表示,分数越高相关性越高),例如下图·中_score: 3.4454226就反映了该文档的相关性水平;

-
1.2 计算相关性评分
-
ElasticSearch相关性评分的算法演进:
-
ElasticSearch使用布尔模型查找匹配文档,通过"实用评分函数"计算相关性。该函数借鉴了TF-IDF(词频-逆向文档频率)和向量空间模型,还加入了协调因子、字段长度归一化、词/查询语句权重提升等现代特性;
-
版本差异:
- ElasticSearch 5之前,评分机制基于TF-IDF实现;
- ElasticSearch 5及以后,默认打分机制改为Okapi BM25(BM是Best Match的缩写,25是经25次迭代调整的算法,由TF-IDF进化而来);
-
-
TF-IDF原理(Term Frequency-Inverse Document Frequency)
-
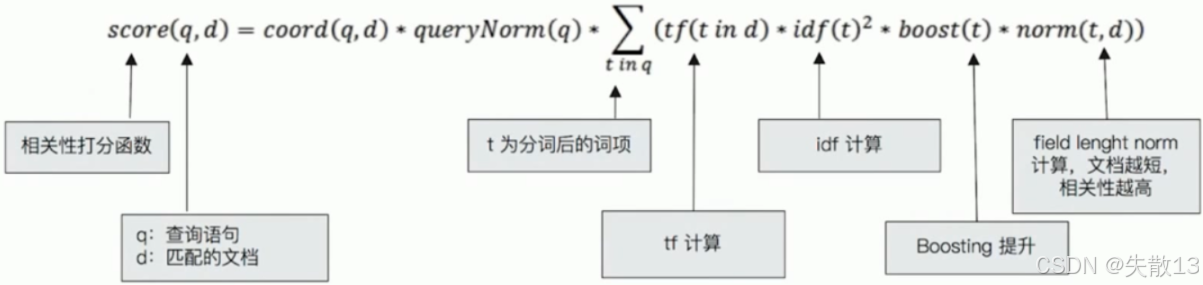
TF-IDF通过**词频(TF)和逆向文档频率(IDF)**两个核心指标,衡量文档与查询的相关性,公式为:
-
词频(Term Frequency) :检索词在文档中出现的频率,词频越高,文档与该词的相关性越高。公式为:
词频( T F ) = 某个词在文档中出现的次数 / 文档的总词数 词频(TF)=某个词在文档中出现的次数 / 文档的总词数 词频(TF)=某个词在文档中出现的次数/文档的总词数 -
逆向文档频率(Inverse Document Frequency) :衡量检索词的"稀有度",某词在所有文档中出现的频率越高,权重越低(相关性越低);反之,在文档中越罕见,得分越高。公式为:
逆向文档频率( I D F ) = l o g (语料库的文档总数 / ( 包含该词的文档数 + 1 ) 逆向文档频率(IDF)=log(语料库的文档总数 / (包含该词的文档数+1) 逆向文档频率(IDF)=log(语料库的文档总数/(包含该词的文档数+1) -
字段长度归一值(field-length norm):检索词出现在短字段(如title)比出现在长字段(如content)权重更大;
-
-
这三个因素在索引时计算并存储,最终结合起来计算单个词在特定文档中的权重;
-
-
BM25原理(Okapi BM25)
-
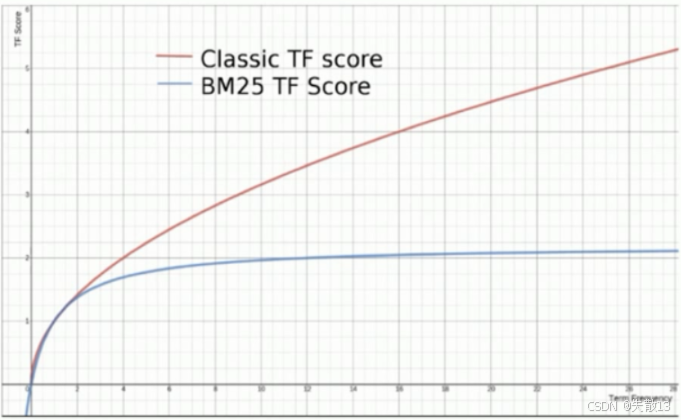
BM25是对TF-IDF的改进,解决了TF-IDF中"TF(t)越大,评分无上限增长"的问题,让评分随TF(t)增大趋于稳定;
-
公式:
bm25 ( d ) = ∑ t ∈ q , f t , d > 0 log ( 1 + N − d f t + 0.5 d f t + 0.5 ) ⋅ f t , d f t , d + k ⋅ ( 1 − b + b ⋅ l ( d ) a v g d l ) \text{bm25}(d) = \sum_{t \in q, f_{t,d}>0} \log \left(1 + \frac{N - df_t + 0.5}{df_t + 0.5}\right) \cdot \frac{f_{t,d}}{f_{t,d} + k \cdot \left(1 - b + b \cdot \frac{l(d)}{avgdl}\right)} bm25(d)=t∈q,ft,d>0∑log(1+dft+0.5N−dft+0.5)⋅ft,d+k⋅(1−b+b⋅avgdll(d))ft,d -
改进点:从下图中可看出,经典TF评分(Classic TF score)随词频增长无限制上升,而BM25的TF评分(BM25 TF Score)会趋于一个稳定数值,实用性更强;
-
-
示例:通过Explain API查看TF-IDF。通过ElasticSearch的API操作,可直观查看TF-IDF的评分计算过程:
-
数据导入 :通过
PUT /test_score/_bulk批量导入4条文档,内容涉及"ElasticSearch"及相关描述; -
检索并开启评分解释 :执行
GET /test_score/_search,设置"explain": true,查询"ElasticSearch"关键词的匹配结果,同时通过GET /test_score/_explain/2单独查看文档ID为2的评分细节,以此理解TF-IDF在实际场景中的计算逻辑;
jsonPUT /test_score/_bulk {"index":{"_id":1}} {"content":"we use ElasticSearch to power the search"} {"index":{"_id":2}} {"content":"we like ElasticSearch"} {"index":{"_id":3}} {"content":"Thre scoring of documents is caculated by the scoring formula"} {"index":{"_id":4}} {"content":"you know,for search"} GET /test_score/_search { "explain": true, "query": { "match": { "content": "ElasticSearch" } } } GET /test_score/_explain/2 { "query": { "match": { "content": "ElasticSearch" } } } -
1.3 ElasticSearch 自定义评分
-
自定义评分是优化ElasticSearch默认评分算法的有效方法,核心是通过修改评分来调整文档相关性,从而在搜索结果最前面的位置返回用户最期望的内容,以满足特定应用场景的需求;
-
ElasticSearch自定义评分的主要作用:
-
排序偏好:为每个文档设置自定义评分,可更好地满足搜索用户的排序偏好;
-
特殊字段权重:给特定字段赋予更高权重,让这些字段对搜索结果的影响更大;
-
业务逻辑需求:根据业务场景定义复杂评分逻辑,使搜索结果更贴合业务需求;
-
自定义用户行为:将用户行为数据(如点击率)作为评分因素,提升用户搜索体验;
-
-
搜索引擎的本质是匹配过程------从海量数据中找到匹配用户需求的内容,"判定内容与用户查询的相关性"是搜索引擎领域的核心研究课题之一。若搜索引擎无法准确识别用户查询意图并将相关结果排前,会导致搜索结果不符合用户需求,进而影响用户对搜索引擎的满意度。而自定义评分正是优化这种"相关性匹配"的关键手段。
2 自定义评分的策略
- 为了让搜索结果最大限度满足用户需求,可从索引层面、查询层面、后处理阶段 着手,主要策略包括:
-
Index Boost:在索引层面修改相关性
-
boosting:修改文档相关性
-
negative_boost:降低相关性
-
function_score:自定义评分
-
rescore_query:查询后二次打分
-
2.1 Index Boost:在索引层面修改相关性
-
定义 :在跨多个索引搜索时,为每个索引配置不同的权重级别,适用于索引级别调整评分;
-
实战举例:
-
一批数据有不同标签,数据结构一致,需将不同标签存储到不同索引(A、B、C),并严格按标签分类展示(先A类,再B类,最后C类);
-
实现方式:借助
indices_boost提升索引权重,让A排在最前,其次是B,最后是C; -
步骤1:创建三个索引并插入文档
jsonPUT my_index_100a/_doc/1 { "subject":"subject 1" } PUT my_index_100b/_doc/1 { "subject":"subject 1" } PUT my_index_100c/_doc/1 { "subject":"subject 1" } -
步骤2:无权重的基础查询(仅匹配结果,无排序优先级)
jsonPOST my_index_100*/_search { "query": { "term": { "subject.keyword": { "value": "subject 1" } } } } -
步骤3:带
indices_boost的查询(指定索引权重,实现排序优先级)jsonPOST my_index_100*/_search { "query": { "term": { "subject.keyword": { "value": "subject 1" } } }, "indices_boost": [ { "my_index_100a": 1.5 }, { "my_index_100b": 1.2 }, { "my_index_100c": 1 } ] } -
通过给
my_index_100a设置最高权重(1.5),my_index_100b次之(1.2),my_index_100c默认(1),实现了按索引标签优先级排序的需求。
-
2.2 boosting:修改文档相关性
-
boosting是在查询时修改文档相关性 的策略,通过调整
boost值来改变满足查询条件的文档评分;-
若
boosting值为0~1 (如0.2):代表降低评分; -
若
boosting值**>1**(如1.5):代表提升评分;
-
-
适用于特定查询场景,用户可自定义修改满足某查询条件的结果评分,以此调整文档相关性排序;
-
例:以"搜索包含
apple,ipad的博客文档,并调整title和content字段的评分权重"为例-
导入测试数据:
jsonPOST /blogs/_bulk {"index":{"_id":1}} {"title":"Apple iPad","content":"Apple iPad,Apple iPad"} {"index":{"_id":2}} {"title":"Apple iPad,Apple iPad","content":"Apple iPad"} -
带boosting的查询:
jsonGET /blogs/_search { "query": { "bool": { "should": [ { "match": { "title": { "query": "apple,ipad", "boost": 4 // title字段boost值>1,提升其评分权重 } } }, { "match": { "content": { "query": "apple,ipad", "boost": 1 // content字段boost值为1,保持默认权重 } } } ] } } } -
此查询中,
title字段的boost设为4,意味着包含关键词的title字段对文档评分的影响更大,从而让"title更匹配关键词"的文档排序更靠前(如文档2的title包含两次"Apple iPad",会因title的高boost权重获得更高评分)。
-
2.3 negative_boost:降低相关性
-
当对某些返回结果不满意,但又不想用
must_not完全排除这些结果时,可采用negative_boost来降低其相关性; -
原理说明:
-
negative_boost仅对查询中定义为negative的部分生效; -
计算评分时,不修改
boosting部分的评分,仅对negative部分的评分乘以negative_boost的值; -
negative_boost取值范围为0~1.0(如0.3);
-
-
例:要求苹果公司的产品信息优先展示
-
步骤1:导入测试数据
jsonPOST /news/_bulk {"index":{"_id":1}} {"content":"Apple Mac"} {"index":{"_id":2}} {"content":"Apple iPad"} {"index":{"_id":3}} {"content":"Apple employee like Apple Pie and Apple Juice"} -
步骤2:基础查询(仅匹配含"apple"的文档)
jsonGET /news/_search { "query": { "bool": { "must": { "match": { "content": "apple" } } } } }- 此时文档1、2、3都会被返回,但文档3是关于苹果员工和食品的内容,并非产品信息,需调整其相关性;
-
步骤3:用
must_not完全排除含"pie"的文档jsonGET /news/_search { "query": { "bool": { "must": { "match": { "content": "apple" } }, "must_not": { "match": { "content": "pie" } } } } }- 这种方式会直接排除文档3,但如果业务上不希望完全排除,仅需降低其优先级,就需要用到
negative_boost;
- 这种方式会直接排除文档3,但如果业务上不希望完全排除,仅需降低其优先级,就需要用到
-
步骤4:用
negative_boost降低含"pie"文档的相关性jsonGET /news/_search { "query": { "boosting": { "positive": { "match": { "content": "apple" } }, "negative": { "match": { "content": "pie" } }, "negative_boost": 0.2 } } }-
positive部分:匹配含"apple"的文档,正常计算评分 -
negative部分:匹配含"pie"的文档(即文档3) -
negative_boost: 0.2:将文档3的评分乘以0.2,大幅降低其相关性,从而让苹果产品文档(1、2)优先展示,同时保留文档3的结果(只是排序靠后)
-
-
2.4 function_score:自定义评分
-
function_score支持用户自定义一个或多个查询语句及脚本,实现对评分的精细化控制,从而对搜索结果进行高度个性化的排序设置。适用于需复杂查询的自定义评分业务场景; -
典型场景为多维度因子结合的相关性排序,例如电子商务中同时考虑"文档与查询的匹配度""销量""浏览人数"等因素,让热门商品在搜索结果中更靠前;
-
案例分析:结合销量和浏览人数提升商品相关度
-
业务需求 :现有商品数据如下,需同时根据销量 和浏览人数提升商品的搜索相关度,让销量、浏览人数高的商品排名更靠前;
商品 销量 浏览人数 A 10 10 B 20 20 C 30 30 -
将文档的原始评分 与销量+浏览人数 结合,公式为:
评分 = 原始评分 × ( 销量 + 浏览人数 ) \text{评分} = \text{原始评分} \times (\text{销量} + \text{浏览人数}) 评分=原始评分×(销量+浏览人数) -
代码实现(借助
script_score)-
步骤1:导入测试数据
jsonPUT my_index_products/_bulk {"index":{"_id":1}} {"name":"A","sales":10,"visitors":10} {"index":{"_id":2}} {"name":"B","sales":20,"visitors":20} {"index":{"_id":3}} {"name":"C","sales":30,"visitors":30} -
步骤2:基于
function_score实现自定义评分检索jsonPOST my_index_products/_search { "query": { "function_score": { "query": { "match_all": {} // 基础查询(可替换为实际业务查询) }, "script_score": { "script": { "source": "_score*(doc['sales'].value+doc['visitors'].value)" // 自定义评分公式 } } } } } -
此查询中,
_score代表文档与查询的原始匹配度评分,通过脚本将其与"销量+浏览人数"相乘,最终实现"销量、浏览人数越高,商品评分越高、排序越靠前"的效果,非常贴合电商等业务场景的个性化排序需求。
-
-
2.5 rescore_query:查询后二次打分
-
rescore_query是查询后二次打分的机制,指重新计算查询返回结果中文档的得分; -
适用于对初始查询语句的结果不满意,需要重新打分的场景。通过只对结果集的子集(而非全部结果)进行处理,避免全量排序的高开销;
-
ElasticSearch会截取查询返回的前N条结果,使用预定义的二次评分方法重新计算其得分。这种方式可在控制开销的前提下,实现对结果子集的精细化排序;
-
实战案例:结合内容和标题的二次打分优化
-
导入测试数据
jsonPUT my_index_books-demo/_bulk {"index":{"_id":"1"}} {"title":"ES实战","content":"ES的实战操作,实战要领,实战经验"} {"index":{"_id":"2"}} {"title":"MySQL实战","content":"MySQL的实战操作"} {"index":{"_id":"3"}} {"title":"MySQL","content":"MySQL一定要会"} -
基础查询(仅匹配
content含"实战"的文档)jsonGET my_index_books-demo/_search { "query": { "match": { "content": "实战" } } }- 此时会返回文档1、2,但排序可能未完全满足业务需求(比如希望"MySQL标题+实战内容"的文档更靠前)。
-
带rescore_query的二次打分查询
jsonGET my_index_books-demo/_search { "query": { "match": { "content": "实战" // 基础查询:匹配content含"实战"的文档 } }, "rescore": { "query": { "rescore_query": { "match": { "title": "MySQL" // 二次查询:匹配title含"MySQL"的文档 } }, "query_weight": 0.7, // 基础查询的权重 "rescore_query_weight": 1.2, // 二次查询的权重 }, "window_size": 50 // 对前50条结果进行二次打分 } }- 逻辑:先通过基础查询筛选出
content含"实战"的文档(文档1、2),再对这部分结果的前50条(此处即文档1、2)进行二次打分------给title含"MySQL"的文档(文档2)更高权重(1.2),最终让文档2在排序中更靠前,满足"MySQL实战类文档优先"的业务需求。
- 逻辑:先通过基础查询筛选出
-
-
优点:可对检索结果进行二次评分,增加复杂评分逻辑,提供更准确的结果排序;
-
缺点:会增加查询的计算成本与响应时间。
3 多字段搜索场景优化
-
多字段搜索的三种场景
-
最佳字段(Best Fields):
- 多个字段中返回评分最高的;
- 适用于字段间相互竞争又关联的场景(如博客的
title和body字段,评分来自最匹配的字段);
-
多数字段(Most Fields):
- 匹配多个字段,返回各个字段评分之和;
- 常用于英文内容检索,通过主字段(如英文分析器)和子字段(如标准分析器)结合,匹配越多字段则评分越高;
-
混合字段(Cross Fields):
- 跨字段匹配,待查询内容在多个字段中都显示;
- 适用于实体类检索(如人名、地址、图书信息),单个字段仅为整体的一部分,需在多个字段中找尽可能多的词。
-
3.1 最佳字段(Best Fields)
3.1.1 问题引出
-
核心逻辑:将与任一查询匹配的文档作为结果返回,采用字段上最匹配的评分作为最终评分;
-
官方文档:Disjunction max query \| Elasticsearch Guide [8.14 | Elastic](https://www.elastic.co/guide/en/elasticsearch/reference/8.14/query-dsl-dis-max-query.html);
-
bool should的缺陷 :当字段间为竞争关系时,bool should会简单叠加多个字段的评分,导致结果不符合预期-
例:
jsonDELETE /blogs PUT /blogs/_doc/1 { "title": "Quick brown rabbits", "body": "Brown rabbits are commonly seen." } PUT /blogs/_doc/2 { "title": "Keeping pets healthy", "body": "My quick brown fox eats rabbits on a regular basis." } # 搜索棕色的狐狸 POST /blogs/_search { "query": { "bool": { "should": [ { "match": { "title": "Brown fox" }}, { "match": { "body": "Brown fox" }} ] } } } -
搜索"Brown fox",用
bool should查询时,会叠加title和body的评分,导致文档1因两个字段都部分匹配(虽无"fox")却获得较高评分,而真正含"Brown fox"的文档2排序可能靠后;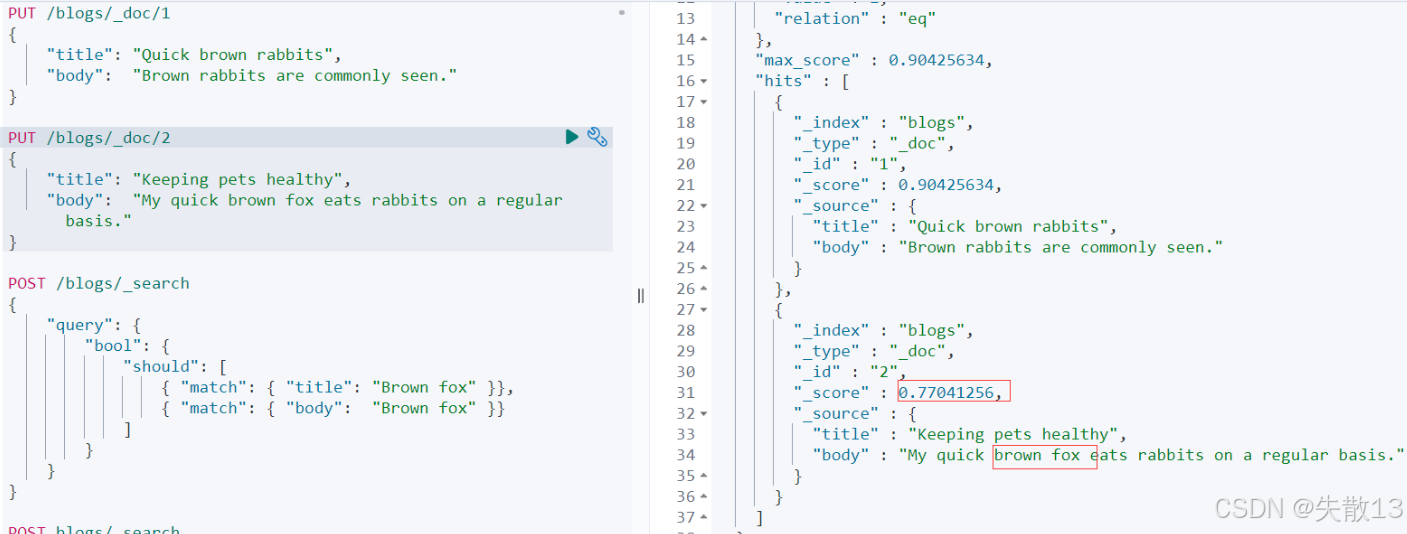
-
3.1.2 dis_max查询
-
dis_max查询会选取多个字段中评分最高的那个作为文档的最终评分,解决字段竞争时的评分叠加问题;jsonPOST /blogs/_search { "query": { "dis_max": { "queries": [ { "match": { "title": "Brown fox" }}, { "match": { "body": "Brown fox" }} ] } } } -
精细化调整:
tie_breaker参数 。tie_breaker是0~1之间的浮点数,用于平衡"最佳字段"和"其他匹配字段"的权重:- 0:仅用最佳匹配字段的评分;
- 1:所有字段评分同等重要;
- 计算逻辑:
最终得分 = 最佳匹配字段得分 + 其他匹配字段得分 × tie_breaker;
jsonPOST /blogs/_search { "query": { "dis_max": { "queries": [ { "match": { "title": "Quick pets" }}, { "match": { "body": "Quick pets" }} ], "tie_breaker": 0.1 } } }
3.1.3 best_fields查询
-
best_fields是multi_match的默认查询类型,等价于dis_max查询,可通过tie_breaker参数精细化控制评分:jsonPOST /blogs/_search { "query": { "multi_match": { "type": "best_fields", "query": "Brown fox", "fields": ["title","body"], "tie_breaker": 0.2 } } }
3.1.4 实战案例:员工信息多字段搜索
-
数据准备:创建
employee索引,设置默认分析器为ik_max_word,并批量导入15条员工数据,包含name、age、deptName、address、content等字段;jsonPUT /employee { "settings" : { "index" : { "analysis.analyzer.default.type": "ik_max_word" } } } POST /employee/_bulk {"index":{"_id":1}} {"empId":"1","name":"员工001","age":20,"sex":"男","mobile":"19000001111","salary":23343,"deptName":"技术部","address":"湖北省武汉市洪山区光谷大厦","content":"i like to write best elasticsearch article"} {"index":{"_id":2}} {"empId":"2","name":"员工002","age":25,"sex":"男","mobile":"19000002222","salary":15963,"deptName":"销售部","address":"湖北省武汉市江汉路","content":"i think java is the best programming language"} {"index":{"_id":3}} {"empId":"3","name":"员工003","age":30,"sex":"男","mobile":"19000003333","salary":20000,"deptName":"技术部","address":"湖北省武汉市经济开发区","content":"i am only an elasticsearch beginner"} {"index":{"_id":4}} {"empId":"4","name":"员工004","age":20,"sex":"女","mobile":"19000004444","salary":15600,"deptName":"销售部","address":"湖北省武汉市沌口开发区","content":"elasticsearch and hadoop are all very good solution, i am a beginner"} {"index":{"_id":5}} {"empId":"5","name":"员工005","age":20,"sex":"男","mobile":"19000005555","salary":19665,"deptName":"测试部","address":"湖北省武汉市东湖隧道","content":"spark is best big data solution based on scala, an programming language similar to java"} {"index":{"_id":6}} {"empId":"6","name":"员工006","age":30,"sex":"女","mobile":"19000006666","salary":30000,"deptName":"技术部","address":"湖北省武汉市江汉路","content":"i like java developer"} {"index":{"_id":7}} {"empId":"7","name":"员工007","age":60,"sex":"女","mobile":"19000007777","salary":52130,"deptName":"测试部","address":"湖北省黄冈市边城区","content":"i like elasticsearch developer"} {"index":{"_id":8}} {"empId":"8","name":"员工008","age":19,"sex":"女","mobile":"19000008888","salary":60000,"deptName":"技术部","address":"湖北省武汉市江汉大学","content":"i like spark language"} {"index":{"_id":9}} {"empId":"9","name":"员工009","age":40,"sex":"男","mobile":"19000009999","salary":23000,"deptName":"销售部","address":"河南省郑州市郑州大学","content":"i like java developer"} {"index":{"_id":10}} {"empId":"10","name":"张湖北","age":35,"sex":"男","mobile":"19000001010","salary":18000,"deptName":"测试部","address":"湖北省武汉市东湖高新","content":"i like java developer, i also like elasticsearch"} {"index":{"_id":11}} {"empId":"11","name":"王河南","age":61,"sex":"男","mobile":"19000001011","salary":10000,"deptName":"销售部","address":"河南省开封市河南大学","content":"i am not like java"} {"index":{"_id":12}} {"empId":"12","name":"张大学","age":26,"sex":"女","mobile":"19000001012","salary":11321,"deptName":"测试部","address":"河南省开封市河南大学","content":"i am java developer, java is good"} {"index":{"_id":13}} {"empId":"13","name":"李江汉","age":36,"sex":"男","mobile":"19000001013","salary":11215,"deptName":"销售部","address":"河南省郑州市二七区","content":"i like java and java is very best, i like it, do you like java"} {"index":{"_id":14}} {"empId":"14","name":"王技术","age":45,"sex":"女","mobile":"19000001014","salary":16222,"deptName":"测试部","address":"河南省郑州市金水区","content":"i like c++"} {"index":{"_id":15}} {"empId":"15","name":"张测试","age":18,"sex":"男","mobile":"19000001015","salary":20000,"deptName":"技术部","address":"河南省郑州市高新开发区","content":"i think spark is good"} -
通过
multi_match的best_fields类型,结合tie_breaker参数,实现跨content和address字段的搜索,并优化评分逻辑:jsonGET /employee/_search { "query": { "multi_match": { "query": "elasticsearch beginner 湖北省 开封市", "type": "best_fields", "fields": [ "content", "address" ], "tie_breaker": 0.1 } }, "size": 15 } -
通过
_explainAPI查看文档3的评分计算细节,验证best_fields和tie_breaker的生效逻辑:jsonGET /employee/_explain/3 { "query": { "multi_match": { "query": "elasticsearch beginner 湖北省 开封市", "type": "best_fields", "fields": [ "content", "address" ], "tie_breaker": 0.1 } } }
3.2 多数字段(Most Fields)
-
most_fields策略的核心是获取全部匹配字段的累计得分 (即综合所有匹配字段的得分之和),等价于bool should查询方式; -
实战案例:英文标题检索的问题与优化
-
数据准备与初始问题 。创建
titles索引,设置title字段使用english分析器(用于提取词干、处理英文语义),并添加子字段title.std使用standard分析器(用于精确匹配):jsonDELETE /titles PUT /titles { "mappings": { "properties": { "title": { "type": "text", "analyzer": "english", "fields": { "std": { "type": "text", "analyzer": "standard" } } } } } } -
导入测试数据:
jsonPOST titles/_bulk {"index":{"_id":1}} {"title": "My dog barks"} {"index":{"_id":2}} {"title": "I see a lot of barking dogs on the road"} -
初始查询(仅用
match查询title字段):jsonGET /titles/_search { "query": { "match": { "title": "barking dogs" } } } -
此时结果可能与预期不匹配,因为
english分析器会对"barking"提取词干(如转为"bark"),但单字段匹配无法兼顾"语义匹配"和"精确匹配"的权重平衡;
-
-
多数字段(Most Fields)的优化方案 。通过
multi_match的most_fields类型,同时匹配title(语义层)和title.std(精确层)字段,累加两个字段的评分,提升结果相关性:jsonGET /titles/_search { "query": { "multi_match": { "query": "barking dogs", "type": "most_fields", "fields": [ "title", "title.std" ] } } }- 逻辑:
title字段通过english分析器实现语义匹配(召回更多相关文档),title.std字段通过standard分析器实现精确匹配(提升相关度高的文档排序),两者评分累加后让结果更符合预期;
- 逻辑:
-
字段权重的精细化控制(boost参数) 。通过
boost参数调整不同字段对最终评分的贡献度,例如提升title字段的权重:jsonGET /titles/_search { "query": { "multi_match": { "query": "barking dogs", "type": "most_fields", "fields": [ "title^10", // 提升title字段的权重为10倍 "title.std" ] } } } -
例:在员工信息索引
employee中,通过most_fields策略对content和address字段进行多字段匹配,累加评分以优化检索结果jsonGET /employee/_explain/3 { "query": { "multi_match": { "query": "elasticsearch beginner 湖北省 开封市", "type": "most_fields", "fields": [ "content", "address" ] } } }- 此查询会综合
content和address字段的匹配评分,让同时匹配多个字段的文档获得更高排序优先级。
- 此查询会综合
3.3 跨字段搜索
- 跨字段搜索是指搜索内容在多个字段中都显示 的检索场景,逻辑类似
bool+dis_max的组合,适用于需在多个字段中同时匹配关键词的业务需求(如地址检索需同时匹配"省份"和"城市"字段)。
3.3.1 实现方式1:cross_fields(多字段跨域匹配)
-
适用场景与优势:适用于需在多个字段中精确匹配关键词的场景,支持
operator参数(如and要求多个字段同时匹配),且可在搜索时为单个字段提升权重(相比copy_to更灵活); -
实战案例:地址检索的问题与解决
-
数据准备:
jsonDELETE /address PUT /address { "settings": { "index": { "analysis.analyzer.default.type": "ik_max_word" } } } PUT /address/_bulk {"index":{"_id":"1"}} {"province": "湖南","city": "长沙"} {"index":{"_id":"2"}} {"province": "湖南","city": "常德"} {"index":{"_id":"3"}} {"province": "广东","city": "广州"} {"index":{"_id":"4"}} {"province": "湖南","city": "邵阳"} -
问题场景 :用
most_fields检索"湖南常德"时,因不支持operator参数,结果可能不符合预期(无法确保"湖南"和"常德"同时匹配)jsonGET /address/_search { "query": { "multi_match": { "query": "湖南常德", "type": "most_fields", "fields": ["province","city"] } } } -
解决方案:cross_fields+operator :通过
cross_fields类型并指定operator: and,确保"湖南"和"常德"分别匹配province和city字段后才返回结果jsonGET /address/_search { "query": { "multi_match": { "query": "湖南常德", "type": "cross_fields", "operator": "and", "fields": ["province","city"] } } }
-
3.3.3 实现方式2:copy_to(字段值复制)
-
原理:通过
copy_to参数将多个字段的值复制到一个组字段中,之后可将该组字段作为单个字段进行查询,从而实现跨字段匹配的效果。但需额外消耗存储空间; -
实战案例:地址检索的copy_to实现
-
数据准备(含copy_to配置):
jsonDELETE /address PUT /address { "mappings": { "properties": { "province": { "type": "keyword", "copy_to": "full_address" }, "city": { "type": "text", "copy_to": "full_address" } } }, "settings": { "index": { "analysis.analyzer.default.type": "ik_max_word" } } } PUT /address/_bulk {"index":{"_id":"1"}} {"province": "湖南","city": "长沙"} {"index":{"_id":"2"}} {"province": "湖南","city": "常德"} {"index":{"_id":"3"}} {"province": "广东","city": "广州"} {"index":{"_id":"4"}} {"province": "湖南","city": "邵阳"} -
检索实现 :对
full_address组字段执行match查询,并通过operator: and确保"湖南"和"常德"同时匹配:jsonGET /address/_search { "query": { "match": { "full_address": { "query": "湖南常德", "operator": "and" } } } }
-