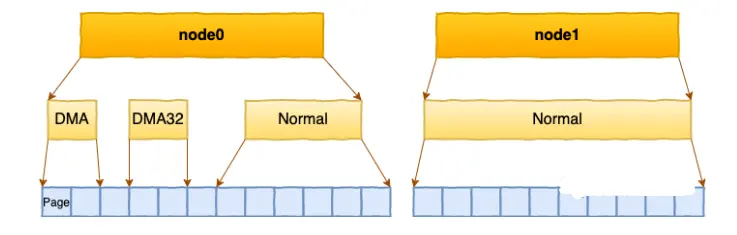
每个 node 又会划分成若干的 zone(区域) 。zone 表示内存中的一块范围
-
ZONE_DMA:地址段最低的一块内存区域,ISA(Industry Standard Architecture)设备DMA访问
-
ZONE_DMA32:该Zone用于支持32-bits地址总线的DMA设备,只在64-bits系统里才有效
-
ZONE_NORMAL:在X86-64架构下,DMA和DMA32之外的内存全部在NORMAL的Zone里管理
在每个zone下,都包含了许许多多个 Page(页面), 在linux下一个Page的大小一般是 4 KB。
在你的机器上,你可以使用通过 zoneinfo 查看到你机器上 zone 的划分,也可以看到每个 zone 下所管理的页面有多少个。
# cat /proc/zoneinfo Node 0, zone DMA pages free 3973 managed 3973 Node 0, zone DMA32 pages free 390390 managed 427659 Node 0, zone Normal pages free 15021616 managed 15990165 Node 1, zone Normal pages free 16012823 managed 16514393
每个页面大小是4K,很容易可以计算出每个 zone 的大小。比如对于上面 Node1 的 Normal, 16514393 * 4K = 66 GB。
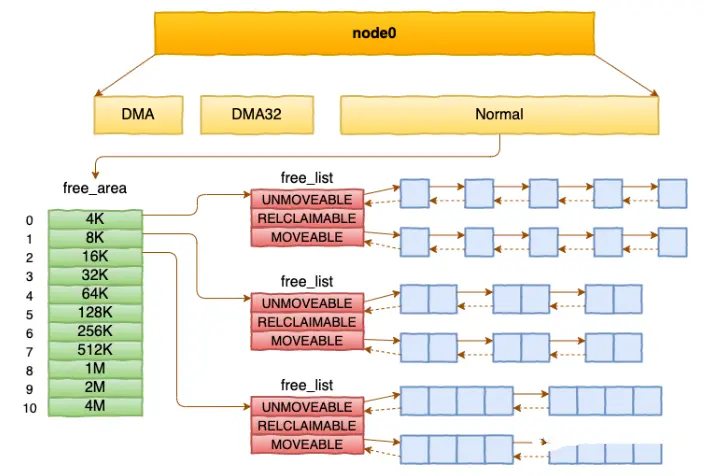
基于伙伴系统管理空闲页面
每个 zone 下面都有如此之多的页面,Linux使用伙伴系统对这些页面进行高效的管理。在内核中,表示 zone 的数据结构是 struct zone。其下面的一个数组 free_area 管理了绝大部分可用的空闲页面。这个数组就是伙伴系统实现的重要数据结构。
Zone
cs
struct zone {
834 /* Read-mostly fields */
835
836 /* zone watermarks, access with *_wmark_pages(zone) macros */
837 unsigned long _watermark[NR_WMARK];
838 unsigned long watermark_boost;
839
840 unsigned long nr_reserved_highatomic;
841
842 /*
843 * We don't know if the memory that we're going to allocate will be
844 * freeable or/and it will be released eventually, so to avoid totally
845 * wasting several GB of ram we must reserve some of the lower zone
846 * memory (otherwise we risk to run OOM on the lower zones despite
847 * there being tons of freeable ram on the higher zones). This array is
848 * recalculated at runtime if the sysctl_lowmem_reserve_ratio sysctl
849 * changes.
850 */
851 long lowmem_reserve[MAX_NR_ZONES];
852
853 #ifdef CONFIG_NUMA
854 int node;
855 #endif
856 struct pglist_data *zone_pgdat;
857 struct per_cpu_pages __percpu *per_cpu_pageset;
858 struct per_cpu_zonestat __percpu *per_cpu_zonestats;
859 /*
860 * the high and batch values are copied to individual pagesets for
861 * faster access
862 */
863 int pageset_high;
864 int pageset_batch;
865
866 #ifndef CONFIG_SPARSEMEM
867 /*
868 * Flags for a pageblock_nr_pages block. See pageblock-flags.h.
869 * In SPARSEMEM, this map is stored in struct mem_section
870 */
871 unsigned long *pageblock_flags;
872 #endif /* CONFIG_SPARSEMEM */
873
874 /* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */
875 unsigned long zone_start_pfn;
876
877 /*
878 * spanned_pages is the total pages spanned by the zone, including
879 * holes, which is calculated as:
880 * spanned_pages = zone_end_pfn - zone_start_pfn;
881 *
882 * present_pages is physical pages existing within the zone, which
883 * is calculated as:
884 * present_pages = spanned_pages - absent_pages(pages in holes);
885 *
886 * present_early_pages is present pages existing within the zone
887 * located on memory available since early boot, excluding hotplugged
888 * memory.
889 *
890 * managed_pages is present pages managed by the buddy system, which
891 * is calculated as (reserved_pages includes pages allocated by the
892 * bootmem allocator):
893 * managed_pages = present_pages - reserved_pages;
894 *
895 * cma pages is present pages that are assigned for CMA use
896 * (MIGRATE_CMA).
897 *
898 * So present_pages may be used by memory hotplug or memory power
899 * management logic to figure out unmanaged pages by checking
900 * (present_pages - managed_pages). And managed_pages should be used
901 * by page allocator and vm scanner to calculate all kinds of watermarks
902 * and thresholds.
903 *
904 * Locking rules:
905 *
906 * zone_start_pfn and spanned_pages are protected by span_seqlock.
907 * It is a seqlock because it has to be read outside of zone->lock,
908 * and it is done in the main allocator path. But, it is written
909 * quite infrequently.
910 *
911 * The span_seq lock is declared along with zone->lock because it is
912 * frequently read in proximity to zone->lock. It's good to
913 * give them a chance of being in the same cacheline.
914 *
915 * Write access to present_pages at runtime should be protected by
916 * mem_hotplug_begin/done(). Any reader who can't tolerant drift of
917 * present_pages should use get_online_mems() to get a stable value.
918 */
919 atomic_long_t managed_pages;
920 unsigned long spanned_pages;
921 unsigned long present_pages;
922 #if defined(CONFIG_MEMORY_HOTPLUG)
923 unsigned long present_early_pages;
924 #endif
925 #ifdef CONFIG_CMA
926 unsigned long cma_pages;
927 #endif
928
929 const char *name;
930
931 #ifdef CONFIG_MEMORY_ISOLATION
932 /*
933 * Number of isolated pageblock. It is used to solve incorrect
934 * freepage counting problem due to racy retrieving migratetype
935 * of pageblock. Protected by zone->lock.
936 */
937 unsigned long nr_isolate_pageblock;
938 #endif
939
940 #ifdef CONFIG_MEMORY_HOTPLUG
941 /* see spanned/present_pages for more description */
942 seqlock_t span_seqlock;
943 #endif
944
945 int order;
946
947 int initialized;
948
949 /* Write-intensive fields used from the page allocator */
950 CACHELINE_PADDING(_pad1_);
951
952 /* free areas of different sizes */
953 struct free_area free_area[NR_PAGE_ORDERS];
954
955 #ifdef CONFIG_UNACCEPTED_MEMORY
956 /* Pages to be accepted. All pages on the list are MAX_ORDER */
957 struct list_head unaccepted_pages;
958 #endif
959
960 /* zone flags, see below */
961 unsigned long flags;
962
963 /* Primarily protects free_area */
964 spinlock_t lock;
965
966 /* Write-intensive fields used by compaction and vmstats. */
967 CACHELINE_PADDING(_pad2_);
968
969 /*
970 * When free pages are below this point, additional steps are taken
971 * when reading the number of free pages to avoid per-cpu counter
972 * drift allowing watermarks to be breached
973 */
974 unsigned long percpu_drift_mark;
975
976 #if defined CONFIG_COMPACTION || defined CONFIG_CMA
977 /* pfn where compaction free scanner should start */
978 unsigned long compact_cached_free_pfn;
979 /* pfn where compaction migration scanner should start */
980 unsigned long compact_cached_migrate_pfn[ASYNC_AND_SYNC];
981 unsigned long compact_init_migrate_pfn;
982 unsigned long compact_init_free_pfn;
983 #endif
984
985 #ifdef CONFIG_COMPACTION
986 /*
987 * On compaction failure, 1<<compact_defer_shift compactions
988 * are skipped before trying again. The number attempted since
989 * last failure is tracked with compact_considered.
990 * compact_order_failed is the minimum compaction failed order.
991 */
992 unsigned int compact_considered;
993 unsigned int compact_defer_shift;
994 int compact_order_failed;
995 #endif
996
997 #if defined CONFIG_COMPACTION || defined CONFIG_CMA
998 /* Set to true when the PG_migrate_skip bits should be cleared */
999 bool compact_blockskip_flush;
1000 #endif
1001
1002 bool contiguous;
1003
1004 CACHELINE_PADDING(_pad3_);
1005 /* Zone statistics */
1006 atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
1007 atomic_long_t vm_numa_event[NR_VM_NUMA_EVENT_ITEMS];
1008 } ____cacheline_internodealigned_in_smp;free_area是一个11个元素的数组,在每一个数组分别代表的是空闲可分配连续4K、8K、16K、......、4M内存链表。
#define MAX_ORDER 10
#define NR_PAGE_ORDERS (MAX_ORDER + 1)
/* free areas of different sizes */ 953 struct free_area free_area[NR_PAGE_ORDERS];
struct free_area { 122 struct list_head free_list[MIGRATE_TYPES]; 123 unsigned long nr_free; 124 };
通过cat /proc/pagetypeinfo, 你可以看到当前系统里伙伴系统里各个尺寸的可用连续内存块数量。
内核提供分配器函数alloc_pages到上面的多个链表中寻找可用连续页面。
struct page * alloc_pages(gfp_t gfp_mask, unsigned int order)
/** 2268 * alloc_pages - Allocate pages. 2269 * @gfp: GFP flags. 2270 * @order: Power of two of number of pages to allocate. 2271 * 2272 * Allocate 1 << @order contiguous pages. The physical address of the 2273 * first page is naturally aligned (eg an order-3 allocation will be aligned 2274 * to a multiple of 8 * PAGE_SIZE bytes). The NUMA policy of the current 2275 * process is honoured when in process context. 2276 * 2277 * Context: Can be called from any context, providing the appropriate GFP 2278 * flags are used. 2279 * Return: The page on success or NULL if allocation fails. 2280 */ 2281 struct page *alloc_pages(gfp_t gfp, unsigned order) 2282 { 2283 struct mempolicy *pol = &default_policy; 2284 struct page *page; 2285 2286 if (!in_interrupt() && !(gfp & __GFP_THISNODE)) 2287 pol = get_task_policy(current); 2288 2289 /* 2290 * No reference counting needed for current->mempolicy 2291 * nor system default_policy 2292 */ 2293 if (pol->mode == MPOL_INTERLEAVE) 2294 page = alloc_page_interleave(gfp, order, interleave_nodes(pol)); 2295 else if (pol->mode == MPOL_PREFERRED_MANY) 2296 page = alloc_pages_preferred_many(gfp, order, 2297 policy_node(gfp, pol, numa_node_id()), pol); 2298 else 2299 page = __alloc_pages(gfp, order, 2300 policy_node(gfp, pol, numa_node_id()), 2301 policy_nodemask(gfp, pol)); 2302 2303 return page; 2304 } 2305 EXPORT_SYMBOL(alloc_pages);
⚙️ 关键参数解析
-
gfp_t gfp(GFP flags) : 这是内存分配的控制标志,它告诉内核在何处以及如何分配内存。常见的标志包括:
GFP_KERNEL: 标准的内核内存分配,可能触发直接内存回收,因此只能在进程上下文中使用(不能中断上下文)。GFP_ATOMIC: 用于原子上下文(如中断处理),分配不会休眠,但成功率较低。GFP_DMA/GFP_DMA32: 指定从 ZONE_DMA 或 ZONE_DMA32 分配内存,供需要特定地址范围的DMA设备使用。
-
unsigned int order: 表示请求的连续页数 ,其值为 2 的幂次方。例如,order为 0 表示请求 1 个页,order为 1 表示请求 2 个连续页,依此类推。内核中MAX_ORDER定义了可分配的最大阶数,如果order超过此值,分配会失败。
🚀 伙伴系统分配流程
__alloc_pages 是伙伴系统的主要入口,其内部通过 快速路径 和 慢速路径 来尝试分配:
- 快速路径 :首先尝试
get_page_from_freelist,它直接扫描内存区域(zone)的空闲链表(free_area数组)来寻找足够大小的连续空闲页块。这是最理想的情况,分配速度很快。 - 慢速路径 :如果快速路径失败(例如当前zone空闲内存不足),则进入
__alloc_pages_slowpath。慢速路径会采取更复杂的措施来获取内存,可能包括:- 唤醒
kswapd内核线程进行后台内存回收。 - 如果内存压力大,可能触发直接内存回收。
- 尝试内存压缩以对抗碎片。
- 在极端情况下,可能触发 OOM Killer 终止进程以释放内存。
- 唤醒
alloc_pages是怎么工作的呢?我们举个简单的小例子。假如要申请8K-连续两个页框的内存。为了描述方便,我们先暂时忽略UNMOVEABLE、RELCLAIMABLE等不同类型
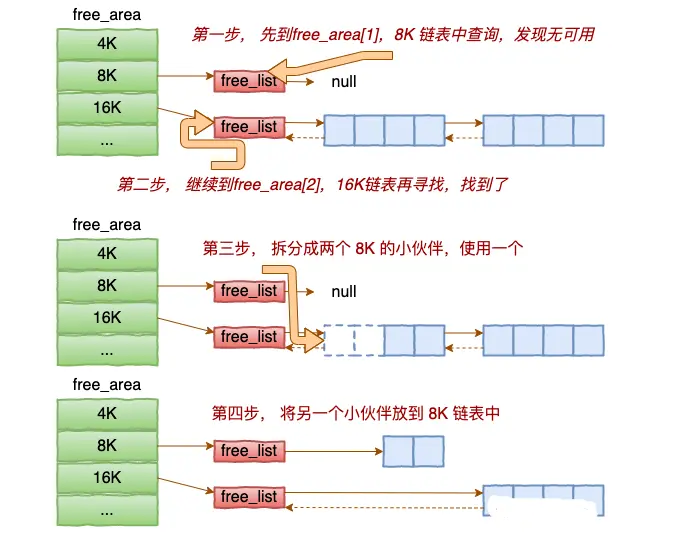
基于伙伴系统的内存分配中,有可能需要将大块内存拆分成两个小伙伴。在释放中,可能会将两个小伙伴合并再次组成更大块的连续内存。
* 重要
理解 /proc/zoneinfo 中 pages free 这个庞大的数字(如你提到的 15021616)是如何产生和变化的,关键在于掌握 Linux 内核管理物理内存的核心机制------伙伴系统。下面这张图清晰地展示了伙伴系统如何通过拆分与合并来管理这些空闲页面:
A[接收内存分配请求<br>order=n] --> B{检查free_area[n]链表} B -- 有空闲块 --> C[从链表取出块并分配] B -- 无空闲块 --> D[向上查找free_area[n+1]] D --> E{找到空闲块?} E -- 是 --> F[进行块拆分] E -- 否 --> G[继续向上查找n+2...<br>直至MAX_ORDER] G --> H{找到空闲块?} H -- 是 --> F H -- 否 --> I[分配失败<br>可能触发内存回收] F --> J[将一块标记为已分配] J --> K[另一块作为伙伴<br>加入free_area[n]链表] K --> C L[释放内存块order=n] --> M{检查其伙伴块<br>是否空闲且大小相同?} M -- 是 --> N[合并两块形成order=n+1的块] N --> O[递归检查合并后的块<br>其伙伴是否可合并] O --> P[将最终合并的块<br>加入对应free_area链表] M -- 否 --> P
⚙️ 空闲页面的分配:伙伴系统的拆分艺术
如图表上半部分所示,当内核需要分配连续物理页时(例如申请 2^order 页),伙伴系统会执行一个精密的拆分过程:
- 寻找合适块 :系统首先在对应
order的free_area链表中查找。如果链表为空,则向上一个更高的order(如order+1)查找,直到找到空闲块。 - 递归拆分 :找到的高阶内存块会被对半拆分成两个"伙伴"块。其中一个伙伴块被放入低一阶的
free_area链表中,另一个则继续参与拆分或用于分配,直到得到所需大小的块。这种机制能有效减少外部碎片,保证大块连续内存的分配。
🔄 空闲页面的回收:伙伴系统的合并智慧
当页面被释放时,伙伴系统会尝试合并以形成更大的连续空闲块,如图表下半部分所示:
- 检查伙伴:释放一个内存块时,系统会计算其"伙伴"块的地址。伙伴块是指大小相同、物理地址连续,且其起始地址是块大小两倍的整数倍的另一个块。
- 递归合并 :如果伙伴块也是空闲的,系统会将这两个伙伴块合并成一个更高
order的块。这个过程会递归进行,直到伙伴块不再空闲或达到最大order。这种合并机制能有效对抗内存碎片。
📊 全局视野:pages free 的来源与水位线
理解了伙伴系统的微观操作后,我们再从宏观视角看 pages free:
- 数据来源 :
/proc/zoneinfo中的pages free数值,正是通过global_zone_page_state(NR_FREE_PAGES)统计所有内存区域(zone)中伙伴系统free_area所有阶链表上空闲页面的总和。 - 水位线的作用 :每个内存区域(zone)都设有三条关键水位线:
WMARK_HIGH:空闲内存充足线。回收操作的目标是使空闲页数达到或高于此线。WMARK_LOW:内存压力预警线。低于此线会唤醒kswapd进行后台回收。WMARK_MIN:最低保障线。低于此线会触发直接回收 ,可能阻塞申请内存的进程。 这些水位线共同调节着pages free的平衡,确保系统在内存充足时积极缓存,在压力增大时及时释放。
💡 深入观察:如何监控与分析
- 查看伙伴系统详细状态:
# 查看每个order的空闲页面数量 cat /proc/buddyinfo
这可以帮你了解不同大小的连续内存块剩余情况。
输出示例
假设你在一台 x86_64 服务器上运行,可能会看到类似这样的输出:
Node 0, zone DMA 1 1 1 0 2 1 1 0 1 1 3
Node 0, zone DMA32 128 100 50 20 10 5 2 1 0 0 0
Node 0, zone Normal 2048 1024 512 256 128 64 32 16 8 4 2
Node 1, zone Normal 1024 512 256 128 64 32 16 8 4 2 1
注:实际输出中,每个 zone 后面有 11 个数字(对应 order 0 到 order 10)。
字段含义
以这一行为例:
Node 0, zone Normal 2048 1024 512 256 128 64 32 16 8 4 2
- Node 0:NUMA 节点编号(单 NUMA 系统只有 Node 0)。
- zone Normal:内存区域类型(DMA / DMA32 / Normal / HighMem 等)。
- 后面的 11 个数字 :分别表示 order 0 到 order 10 的空闲块数量。
✅ 关键点:
- 第 1 个数字(2048) →
order=0:表示有 2048 个大小为 1 页(4KB)的空闲块。 - 第 2 个数字(1024) →
order=1:表示有 1024 个大小为 2 页(8KB)的空闲块。 - ...
- 第 11 个数字(2) →
order=10:表示有 2 个大小为 1024 页(4MB)的空闲块。
📌 每个 order 对应的页数 =
2^order每个 order 对应的字节数 =
2^order * PAGE_SIZE(通常 PAGE_SIZE = 4096)
如何计算总空闲内存?
你可以通过加权求和来估算该 zone 的总空闲物理内存(单位:pages):
总空闲页数 = Σ (空闲块数量order × 2^order)
计算:
= 2048×1 + 1024×2 + 512×4 + 256×8 + ... + 2×1024
= 2048 + 2048 + 2048 + 2048 + ... (这里每项都是 2048!)
= 11 × 2048 = 22528 pages
≈ 22528 × 4KB = 88 MB
典型场景解读
场景 1:系统刚启动,内存充足
- 高 order(如 order=8~10)有较多块 → 内存连续性好,适合大块分配(如 THP)。
场景 2:系统运行很久,内存碎片化严重
- order=0、1 有很多块,但 order≥5 几乎为 0。
- 表示虽然总空闲内存不少,但 无法分配大块连续内存(比如 kmalloc 大 buffer 或透明大页失败)。
场景 3:DMA zone 数值很小
- DMA zone 通常只有 16MB(x86),所以高 order 基本为 0 是正常的。
小结
- 对比
/proc/zoneinfo中的nr_free_pages:应 ≈ 你通过 buddyinfo 计算出的总空闲页数。 - 若 buddyinfo 显示高 order 为 0,但系统频繁 direct reclaim,可能是 内存碎片问题。
附加
快速查看总空闲页(脚本)
bash
# 计算 Node 0 Normal zone 的总空闲页数
awk '/Node 0, zone Normal/ {
total = 0;
for (i = 4; i <= NF; i++) {
order = i - 4;
total += $i * (2 ^ order);
}
print "Total free pages in Node0 Normal:", total;
}' /proc/buddyinfo| 每行 | 对应一个 NUMA Node + Zone |
| 11 个数字 | order 0 到 10 的空闲块数量 |
| 数值大(高 order) | 内存连续性好 |
| 数值集中在低 order | 内存碎片化严重 |
| 用于诊断 | 大页分配失败、OOM、性能下降等问题 |
如果你看到某个 zone 的高 order 块很少,但系统又需要大块内存(比如启用 THP 后性能下降),可能就需要考虑 内存碎片整理(compaction) 或调整工作负载了。
2. 监控水位线和回收活动:
# 查看详细zone信息 cat /proc/zoneinfo | grep -A5 -B5 -i "free\|min\|low\|high" # 查看内存回收统计 grep "pgscan\|pgsteal" /proc/vmstat
- 理解数值变化:
pages free 的下降通常由进程分配内存、文件系统缓存增长引起;
而其上升则源于进程退出、主动释放缓存(如 echo 3 > /proc/sys/vm/drop_caches)或内存回收机制的成功运作。
二.如何监控Zone区域的页面使用情况
监控 Linux 系统中 Zone 区域的内存页面使用情况是性能分析和故障诊断的关键。下面这个表格汇总了核心的监控方法和工具,帮你快速上手。
| 监控方法 | 核心工具/文件 | 主要监控维度 | 适用场景 |
|---|---|---|---|
| 静态快照分析 | /proc/zoneinfo |
Zone 水位线、空闲页面、LRU 链表统计 | 详细分析内存分布、诊断内存压力根源 |
| 静态快照分析 | /proc/meminfo |
系统全局内存使用概况(含各Zone汇总) | 快速查看系统整体内存余量和压力 |
| 动态趋势监控 | vmstat |
系统级页面换入/换出、内存变化趋势 | 观察内存回收、交换等活动的动态变化 |
| 动态趋势监控 | sar -B |
页面扫描(pgscan)、回收(pgsteal)速率 | 量化内存回收压力,判断回收效率 |
📊 深入分析 Zone 状态
要获得每个内存区域最详细的信息,/proc/zoneinfo 是你的首选
。它展示了以下关键信息:
-
内存水位线 :这是内核的"预警机制"。
min、low、high这三条线决定了内存回收的触发时机。你可以根据
pages free与这些水位线的相对位置来判断压力:- 正常 :
free ≥ high。 - 潜在压力 :
free < low,此时内核会唤醒kswapd进行后台回收。 - 紧急状态 :
free < min,会触发直接回收,可能导致进程阻塞和延迟增加。
- 正常 :
-
LRU 链表详情 :
nr_active_anon、nr_inactive_file等指标显示了匿名页和文件缓存页在活跃/非活跃链表中的分布。当需要回收内存时,内核优先从非活跃链表 (如
nr_inactive_file)的末尾开始回收。如果非活跃文件缓存充足,说明系统有较多的"软"内存可供回收,压力相对较小。
🔍 掌握全局与动态监控
虽然 /proc/zoneinfo 很详细,但有时你需要更宏观的视角或观察变化趋势。
-
快速概览 :使用
cat /proc/meminfo或free -h命令。重点关注MemAvailable指标,它估算的是在不引起严重交换的情况下,新应用可用的内存量,比MemFree更能反映真实余量。 -
观察动态行为 :使用
vmstat 1命令(每秒刷新一次)。特别关注si(换入)和so(换出)列,如果持续有值,说明系统正在使用交换分区,内存压力很大。sar -B 1命令则能提供更直接的回收指标,如pgscank(kswapd 扫描的页面)和pgscand(直接回收扫描的页面),帮助你量化回收压力。
💡 实用诊断与优化思路
结合监控数据,你可以采取以下行动:
-
定位内存消耗 :如果
nr_active_anon很高,通常意味着应用程序的堆内存使用量大。如果nr_inactive_file很高,说明系统有大量文件缓存,这在内存充足时是好事,但在压力大时是可回收的资源。
-
手动释放缓存 :在调试或特定场景下,你可以通过
echo 3 > /proc/sys/vm/drop_caches来手动释放干净的页缓存和 slab。请注意,这主要用于测试,在生产环境中慎用,因为它会清除缓存可能导致后续I/O性能暂时下降。
-
调整内核参数 :如果监控发现
free经常低于low水位线,可以谨慎地 调整/proc/sys/vm/min_free_kbytes来提高所有水位线,让 kswapd 更早开始工作
后续完善....