现在我们的 Agent 已能通过工具采取行动,是时候赋予它们更接近人类 的智能:记忆 与知识 。本章将探索如何超越无状态交互,让 Agent 具备记住过往消息 、保留重要事实 、并在生成回答时引用外部信息源的能力。这将使 Agent 在对话性、助益性与情境感知方面实现飞跃。
你将学到:
- 短期记忆 :学习如何用消息列表、循环与
Sessions类跟踪会话历史,构建多轮、能记住本会话早先内容的 Agent - 长期记忆 :使用
SQLiteSession在会话之间持久化记忆 ,并通过函数工具 存储/回忆关键事实,进一步实现结构化记忆 - 训练知识 :理解模型从预训练 中已有的知识,以及微调如何改变这些知识
- 检索型知识 :通过检索增强生成(RAG)引入动态实时信息------既包括结构化 (数据库查询、API 调用),也包括非结构化数据(向量化与语义搜索)
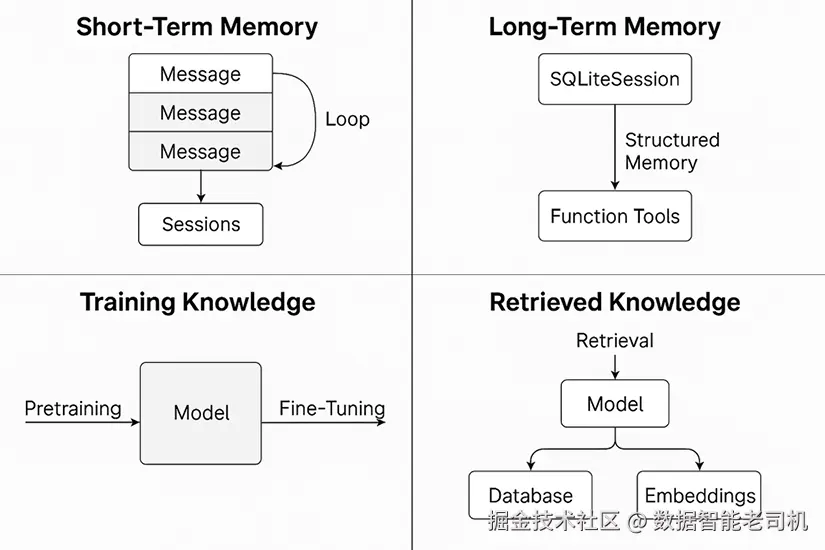
图 5.1:记忆与知识模式
读完本章,你将会让 Agent 更聪明:能够进行有意义的对话、记住偏好,并在需要时访问外部数据源。让我们开始吧。
技术要求
请按照第 3 章的步骤完成环境搭建。
全书各章的示例与完整代码可在配套仓库获取:
github.com/PacktPublis...
建议克隆仓库,复用并按需改造示例代码。
工作记忆(Working memory)
如前所述,工作记忆 (又称短期记忆 )是存放在当前会话交互历史 中的信息。此前举过的例子:先问"太阳有多热(How hot is the sun?)",再问"它有多大(How big is it?)",Agent 能判断第二句里的 "it" 指代太阳。
到目前为止,我们的 AI Agent 都没有通过 这项测试:它们没有记忆的概念。事实上,它们一直是无状态(stateless)的,也就是不会保留以往交互的信息;每次调用都像是一个全新的系统,对此前发生的事一无所知 。无状态系统在计算机世界很常见------例如大多数 API 都是独立事务 ,不会记住你之前问过什么。相反,有状态(stateful)系统会保留交互历史并据此产生下一步输出;比如你的 Netflix 页面就是有状态的:它记住你看过什么,从而推荐相似影片。记忆让 AI Agent 从无状态 转变为有状态。
如何选择无状态还是有状态的 AI Agent?取决于用途 。需要对话互动(聊天机器人) 、需要多步输入 或答案需依赖上下文 的场景,必须采用有状态 系统------没有记忆的聊天体验会让用户抓狂。相反,若 Agent 的目标是简单、常规、一次性、可重复、且不需要学习 ,无状态也完全可行。需要注意的是,让 Agent 有状态是有成本的:管理记忆会带来开销,本章有一半篇幅用于讨论它。
管理输入与响应
给 Agent 增加记忆的最基础方式是手动管理 。回忆一下,Agent 通过 Runner 类执行,它接收一个输入参数:
arduino
Runner.run_sync(agent, "How hot is the sun?")该输入既可以是字符串 (我们之前一直这么做),也可以是一个由 ResponseInputItem 组成的列表 。ResponseInputItem 是 OpenAI 的标准规范,用来表示一条消息;每条消息包含 "role" 与 "content" 字段。若你用过 OpenAI API,这应当很熟悉。示例:
json
{"role": "user", "content": "How hot is the sun?"}"role" 可取三类值:
"system":作为 LLM 的总体指令集"user":用户提交的消息,优先级低于 system 消息"assistant":LLM 生成的消息
为了给 Agent 提供记忆,我们只需把 ResponseInputItem 追加到一个运行中的列表 ,并在每次调用 Agent 时将该列表传给 Runner。动手试试。创建 memory_tracking_messages_simple.py 并运行:
python
from agents import Agent, Runner
# Create the agent
agent = Agent(
name="QuestionAnswer",
instructions="You are an AI agent that answers questions.",
)
# Create empty list (this will contain messages)
messages = []
# Initial message,
messages.append({"role": "user", "content": "How hot is the sun?"})
# Call agent
result = Runner.run_sync(agent, messages)
print(result.final_output)
# Add response to message
messages.append({"role": "assistant", "content": result.final_output})
# Add second question to message
messages.append({"role": "user", "content": "How big is it?"})
# Call agent
result = Runner.run_sync(agent, messages)
print(result.final_output)让我们逐步看看第二条消息被处理时,Agent 如何记住第一条消息。我们先创建一个空列表 messages,用于保存完整交互历史 ;将用户第一条消息"How hot is the sun? "追加到列表,并传入 Runner.run_sync();模型返回温度相关的回答,被保存在 result.final_output 中,我们再把它以 "assistant" 角色追加回消息历史(因为它是模型输出)。
接着追加用户的追问 :"How big is it? "。此时历史中有三条:
- 用户首问(How hot is the sun?)
- 模型回答(The sun is ...)
- 用户追问(How big is it?)
再次把完整消息列表 传给 Runner.run_sync(),模型即可访问既往对话,从而正确判断第二句中的 it 指代太阳。示例响应如下:
vbnet
## First response
The Sun's temperature varies in different regions:
1. Core: Around 15 million degrees Celsius (27 million degrees Fahrenheit).
2. Surface (photosphere): Approximately 5,500 degrees Celsius (9,932 degrees Fahrenheit).
3. Corona: Ranges from 1 to 3 million degrees Celsius (1.8 to 5.4 million degrees Fahrenheit).
...
## Second response
The Sun has a diameter of about 1.39 million kilometers (864,000 miles). It is roughly 109 times the diameter of Earth and makes up over 99% of the total mass of the solar system.这种维护并追加消息列表 的方式,是为 Agent 构建工作记忆的最简单手段;它与大多数聊天界面的记忆实现方式一致,也直接对应 OpenAI API 的消息结构。
聊天会话
我们可以把上面的代码写得更动态:不再硬编码用户消息,而是让用户像真实聊天一样,连续输入多条消息。
借助 Python 的 input 与 while 循环即可。创建 memory_tracking_messages_simple_loop.py 并运行:
python
from agents import Agent, Runner
# Create the agent
agent = Agent(
name="QuestionAnswer",
instructions="You are an AI agent that answers questions.",
)
messages = []
while True:
question = input("You: ")
messages.append({"role": "user", "content": question})
result = Runner.run_sync(agent, messages)
print("Agent: ", result.final_output)
messages.append({"role": "assistant", "content": result.final_output})程序会在终端中提示你输入内容;它会给出 Agent 的回复,并继续询问下一条消息,同时保留消息历史 。至此,我们把 Agent 从一次性 系统改造成了多轮对话系统(在同一会话中记住先前消息)。每一轮循环的步骤为:
- 让用户输入提示;
- 将该提示作为
ResponseInputItem追加到运行中的列表messages; - 通过
Runner把messages传给 Agent; - 将模型输出作为
ResponseInputItem再追加回messages。
该循环会一直持续,直到报错或用户Ctrl + C 退出。下面是一个能证明 Agent 具有记忆(记住了我的名字)的对话示例:
vbnet
You: My name is Henry
Agent: Nice to meet you, Henry! How can I assist you today?
You: What's my name?
Agent: Your name is Henry.注意
你可能会问:如果
messages无限增长怎么办?确实需要考虑历史消息的增长问题。别担心,我们会在本章后面讨论处理策略。
SDK 还提供了一个便捷函数,用于从结果对象中取回消息列表 :result.to_input_list() 返回一个 ResponseInputItem 列表;你可以在此基础上继续追加新的消息,使代码更简洁(功能一致):
ini
from agents import Agent, Runner
# Create the agent
agent = Agent(
name="QuestionAnswer",
instructions="You are an AI agent that answers questions.",
)
messages = []
while True:
question = input("You: ")
messages.append({"role": "user", "content": question})
result = Runner.run_sync(agent, messages)
print("Agent: ", result.final_output)
messages = result.to_input_list()在实践中,这一技巧构成了有状态对话 Agent 的地基 。在此之上,你可以逐步叠加更高级的记忆技术:跨会话持久化、抽取结构化数据、记忆修剪/更新、处理超长对话等。但一切都始于跟踪会话历史。
使用 Sessions 进行会话管理
OpenAI Agents SDK 提供了一个用于会话管理的原语 Sessions 。它是一个类,用于自动 在会话中存储、回放与编辑 消息。也就是说,你不必手动调用 .to_input_list() 或手动维护消息列表------SDK 会替你处理 。Sessions 类只需要一个输入:代表会话唯一标识符的字符串 session_id。
让我们在上一段脚本的基础上加入 Session。创建 conversations_with_sessions.py 并运行:
ini
from agents import Agent, Runner, SQLiteSession
# Create the agent
agent = Agent(
name="QuestionAnswer",
instructions="You are an AI agent that answers questions.",
)
# Create a session
session = SQLiteSession("first_session")
while True:
question = input("You: ")
result = Runner.run_sync(agent, question, session=session)
print("Agent: ", result.final_output)运行后(可以看到代码更简单),再次尝试我们的测试用例:
vbnet
You: My name is Henry
Agent: Nice to meet you, Henry! How can I assist you today?
You: What's my name?
Agent: Your name is Henry.在这个例子里,会话历史由 Sessions 类管理。无需手动追加消息或调用 .to_input_list(),session 对象会在幕后追踪完整交互历史。
当需要管理多个用户或多路会话 时,Sessions 尤其有用。通过为每条交互线程使用唯一的 session_id ,Agent 可以维护相互隔离 的记忆上下文。比如,你可以基于"用户名 + 会话 ID"生成 session_id,确保每位用户/每个会话都有独立历史。
这为构建真正有状态、在长对话中更自然、响应更及时且更智能的 Agent 打下基础。
注:
SQLiteSession默认是内存型 (进程重启后不保留)。如何将会话持久化到磁盘 会在"长期记忆"章节讨论。但在此之前,我们需要先解决大体量对话的管理问题------即便"短期记忆"也有容量上限。
管理大体量会话
为什么大体量会话会成为 Agent 的问题?因为 Agent 背后是 LLM ,而 LLM 存在上下文窗口有限 这一根本限制(一次只能接收处理一定数量的字符/"Token")。如果对话持续增长、我们还不断把消息无脑追加 进去,最终会触碰上限,提示过长而失败。
即便没有 这个技术限制,也值得管理长对话:更长的提示 与上下文会显著拉慢响应 并增加成本 。因此,管理短期记忆时,应丢弃或压缩较不重要的旧信息。
本节介绍两种常见策略:滑动消息窗口 与消息摘要。
滑动消息窗口(Sliding message window)
最简单、最经济的记忆策略。做法是仅保留消息日志中最近的 N 条消息 ------相当于一个 FIFO 队列。新消息进入、旧消息被挤出,确保提示始终不超过模型的上下文上限。
适用于只需要短期记忆的 Agent(如聚焦解决单一问题线程的客服 Agent)。但它的风险是遗忘重要上下文 :例如用户在对话早期提供了姓名、目标或约束 ,如果窗口过小,这些信息可能会被完全丢失。
消息摘要(Message summarization)
更高级的策略是把旧消息摘要化 :不是直接忘记,而是将其压缩为一段更短的摘要 ,在会话中持续保留 。这样 Agent 能在长对话里保留关键事实、决策与偏好,起到衔接短期与长期记忆的作用。
常见做法:
- 持续监控消息历史的大小,当超过阈值时,收集最旧的 N 条消息;
- 将这 N 条消息交给 LLM,使用专门的提示词让其生成摘要;
- 在消息日志中用摘要 替换这 N 条旧消息。由于摘要比原 N 条更短,从而有效缩短消息日志的上下文长度。
此法能在不超 Token 限制 的前提下保留长期上下文。权衡在于:成本与时延 会增加------每次摘要都需要额外的一次 LLM 调用 。实践里,很多 Agent 会组合 两种策略:用滑动窗口删除 更旧的消息,再用摘要链压缩保留关键上下文。
短期记忆的核心是在单个会话 内让 Agent 具备情境感知 。在 OpenAI Agents SDK 中,启用短期记忆最直接的方式就是用 Sessions 。不过要想可扩展 (不超上下文限制),就需要像滑动窗口 或消息摘要这样的策略。
下面是一个滑动窗口模式示例:
python
from agents import Agent, Runner
from collections import deque
# Create the agent
agent = Agent(
name="QuestionAnswer",
instructions="You are an AI agent that answers questions."
)
# Sliding window size (keep only the most recent 5 messages)
WINDOW_SIZE = 5
messages = deque(maxlen=WINDOW_SIZE)
while True:
question = input("You: ")
messages.append({"role": "user", "content": question})
# Run the agent with only the most recent N messages
result = Runner.run_sync(agent, list(messages))
print("Agent:", result.final_output)
messages.append({"role": "assistant", "content": result.final_output})接下来,我们将探索长期记忆 ,看看 Agent 如何在跨会话或更长周期内保留信息。
长期记忆
长期记忆 指的是 Agent 能在多次会话、长时间跨度 内记住相关细节的能力。正是这项"超能力"让 Agent 能在不同会话间保留与回忆 信息,是打造真正有状态、个性化、可持续AI 体验的基石。有人把这称作人与 AI 的"最终鸿沟":人类客服能自然而然地记住重要事实、偏好或既往对话,并将其映射到每位来访者;而 AI 往往难以做到。
我们之前在单次会话 中讨论过无状态与有状态的区别;这个区别同样适用于跨会话 。没有长期记忆的 Agent 在会话与会话之间本质上是无状态 的:一旦关闭或重启,它就无法记住用户姓名、以往偏好或已完成的任务。比如,用户曾经告诉客服 Agent:"我希望快递从后门 送达而非前门",一周后再来,有长期记忆的 Agent 会主动把配送方式设为"后门"。
要让 Agent 具备长期记忆,关键在于存储 与回忆 :把记忆写入持久化状态,供未来检索。本节将介绍若干实现模式。
持久化消息日志(Persistent message logs)
实现长期记忆最简单直观的方式:在会话结束时把整段消息日志 存起来,下次启动时再读回 。Agents SDK 提供了我们前面用过的 Sessions 机制(SQLiteSession)。该类除了接收 session_id,还可接收 db_path 参数(本机文件路径),SDK 会自动存取消息日志到本机的 SQL 数据库。
示例,创建 ltm_sessions.py 并运行:
ini
from agents import Agent, Runner, SQLiteSession
# Create the agent
agent = Agent(
name="QuestionAnswer",
instructions="You are an AI agent that answers questions.",
)
# Create a session
session = SQLiteSession("first_session", db_path="messages.db")
while True:
question = input("You: ")
result = Runner.run_sync(agent, question, session=session)
print("Agent: ", result.final_output)这里我们给 session 传入了 db_path,指示 SDK 把会话存到本机,并在下次实例化 Agent 时自动加载。你可以这样测试:运行程序→对话→退出→再次运行→查看是否还记得先前信息。
第一次运行并告知姓名:
vbnet
You: Hello, I'm Henry
Agent: Hi Henry! What would you like to talk about today?按 Ctrl + C 退出后重启程序并询问姓名:
vbnet
You: What's my name?
Agent: You mentioned your name is Henry. How can I assist you further?这就做出了一个具备长期记忆 的 Agent。它会记住你的交互,因为它把消息日志存到了本地并在每次启动时加载。你会在代码根目录看到一个 messages.db 文件------会话与对话就保存在那里。
使用内置会话对象实现持久化的好处是无缝:无需自己设计存储格式或数据库 schema。
但这个模式也有明显的局限 :随着会话数量或对话长度增长,完整存取 消息日志会越来越低效;而且如前所述,消息日志可能膨胀 到超出 LLM 的上下文窗口限制。
此外,逐字保存 所有消息并非最聪明的长期记忆方式。通常我们想保留的并不是每句话,而是关键事实、决策、偏好或结果 。这就需要更结构化的记忆体系。
结构化记忆召回(Structured memory recall)
结构化记忆通过工具调用来解决 Agent 记忆问题,核心思想:
- 不 保存每条消息;而是提供一个保存记忆 的工具,仅保存用户给出的重要信息。
- 不 加载全部历史;而是提供一个读取记忆 的工具,只取相关信息。
如此,当前会话的提示与消息日志保持干净 ;当模型判断需要查阅长期记忆 (比如用户提到了"之前"或过往会话中的内容)时,再调用函数取回相关事实。
示例,创建 ltm_structured_memory_call.py。首先初始化记忆文件:如果 JSON 不存在则创建默认结构。
python
from agents import Agent, Runner, function_tool
import os
import json
# Create JSON file if it does not exist
FILENAME = 'memory.json'
memory_default = {
"user_profile": [],
"order_preferences": [],
"other": []
}
if not os.path.exists(FILENAME):
with open(FILENAME, 'w') as f:
json.dump(memory_default, f, indent=4)
print(f"Created '{FILENAME}' with default data.")
else:
print(f"'{FILENAME}' already exists.")定义保存记忆的工具:
python
@function_tool
def save_memory(memory_type: str, memory: str) -> str:
"""
Saves a memory to a memory store.
Args:
memory_type: the type of memory to store. Choose between user_profile, order_preferences, or other.
memory: the memory to save
"""
with open(FILENAME, 'r') as f:
data = json.load(f)
data[memory_type].append(memory)
with open(FILENAME, 'w') as f:
json.dump(data, f, indent=4)
print(f"Memory ({memory}) saved")
return f"Memory ({memory}) saved"再定义读取记忆的工具:
python
@function_tool
def load_memory(memory_type: str) -> str:
"""
Loads a set of memory from a memory store.
Args:
memory_type: the type of memory to load. Choose between user_profile, order_preferences, or other.
"""
with open(FILENAME, 'r') as f:
data = json.load(f)
return "|".join(data[memory_type])最后创建 Agent,授予工具,并运行交互循环:
ini
# Create the agent
agent = Agent(
name="QuestionAnswer",
instructions="You are an AI agent that answers questions. You have access to two tools that enable you to save memories and load memories. Save memories when you learn an important fact. Load memories when something is asked for about the user.",
tools=[save_memory, load_memory]
)
while True:
question = input("You: ")
result = Runner.run_sync(agent, question)
print("Agent: ", result.final_output)代码解析:save_memory 让 Agent 将重要事实按类别 保存(如 user_profile、order_preferences),写入本地 memory.json。例如用户说"我希望从前门配送",Agent 可调用
save_memory("user_profile", "Prefers deliveries through the front door")
把事实写入持久化存储(这里是 JSON,也可替换为数据库)。
相对地,load_memory 用于读取 已存事实。当用户引用过往偏好,比如问"我的配送偏好是什么?",Agent 可调用 load_memory("order_preferences") 拉取并总结该类下的事实。
这组函数为 Agent 提供了结构化、轻量 的长期记忆机制:不是存整段对话,而是只保留重要且可复用的要点 。这比保留所有消息更可扩展 ,也更贴近人类的记忆方式------与朋友聊天得知 TA 喜欢寿司,你不会记住完整对话,而是记录"TA 喜欢寿司"这一关键点。
试运行:输入
vbnet
You: I like to have orders sent to the office
Memory (User prefers orders to be sent to the office.) saved
Agent: Got it! I'll remember that you prefer to have orders sent to the office.此时 Agent 识别到这是有用偏好 ,便调用 save_memory。打开 memory.json 可见:
json
{
"user_profile": [],
"order_preferences": [
"User prefers orders to be sent to the office."
],
"other": []
}退出后重启程序,询问偏好:
vbnet
You: Where do I like my orders sent?
Agent: You like your orders sent to the office.此时 Agent 调用了 load_memory("order_preferences") 取回事实并作答。
这种结构化长期记忆更可扩展 、更语义精准 ,也避免了上下文窗口限制带来的问题。它还能为高级记忆系统打基础------例如将事实进行向量化并索引 以供语义检索 ,或增加时间戳 、来源可信度等元数据。
说明
这里实现的结构化记忆模式简单有效 ,适合"轻量级"场景。但当事实越来越多(或你需要模糊/语义 检索)时,简单的键值 方案会遇到瓶颈。这时就需要向量数据库与语义向量(embeddings) :把每条记忆表示为向量,存入向量库并进行语义搜索。我们会在本章后面讨论其工作原理。
在构建更复杂的 Agent 时,你很可能需要组合 这两类长期记忆模式(持久化消息日志 + 结构化记忆召回 )。OpenAI Agents SDK 足够灵活,完全支持同时采用这两种方案。
训练知识(Training knowledge)
正如第 1 章所述,训练知识 是指通过训练数据"内建"在模型中的信息。每个 LLM 都从海量语料(通常是互联网文本的大型语料库)出发,形成一座庞大的内在知识库。这种内在知识有几大优点:
- 检索速度快:知识被"烘焙"进了模型权重,检索几乎只受模型计算速度限制。
- 覆盖面广:由于训练数据极其庞大(互联网语料),对大量主题都有相当细致的覆盖。
改变模型内在知识的过程称为微调(fine-tuning) 。与只"引导"现有知识的提示工程或检索不同,微调是通过在精心挑选的数据集上再训练 ,直接改变模型权重,让模型习得此前掌握不佳的术语、模式或行为。结果是一个在特定领域/任务上更专门化 、更准确的版本。
以医疗为例:通用模型(如 GPT-4o)能理解健康相关的常识,但面对复杂报告解读 或依据细微指南给出治疗方案时就可能力有不逮。若用结构化病历与医生笔记对其进行微调,便可得到更贴合医疗场景、能回答更细腻健康问题的模型。
不过,微调更适合强专业性、对准确性高度敏感 的场景(如医疗),同时也存在明显局限:
- 算力开销大、成本高 :尤其对大模型,微调需要大量 GPU 资源。即便使用"微调即服务",费用也可能昂贵(动辄 $10,000+ 的训练费,且不含托管成本)。
- 不灵活 :一旦微调出一个模型,它就需要与基础模型分开维护 。基础模型更新或新知识出现时,往往需要重新微调。
- 知识混淆 :新加入的知识可能与原训练知识混杂/冲突 ,导致模型在优先级取舍上出现矛盾输出 。从技术上讲,模型并无法保证优先采纳微调知识。
因此,在许多不需要极致领域控制 的实际应用中,使用提示工程或**检索增强生成(RAG)**往往更经济高效------下面就来讲"检索型知识"。
检索型知识(Retrieved knowledge)
检索型知识 指的是:根据用户请求,实时 从一个知识库中检索信息。与固定在训练时点的"训练知识"不同,检索型知识会随对话上下文动态变化。基本流程如下:
- 用户提问需要外部知识。
- Agent 检索 :通过一个工具调用,从知识源抓取与问题相关的数据(数据库、文本、向量库、搜索 API 等)。
- 信息注入 :把检索结果喂给 LLM。
- 生成回答 :LLM 基于检索信息整合生成答案。
这就是将外部知识 "接入"Agent 的方式。此处"外部"是指不在模型权重里的信息。
回顾第 4 章,我们已经实现过使用检索型知识的 Agent。比如这个比特币价格的例子:
python
import requests
from agents import Agent, Runner, function_tool
# Create the tool
@function_tool
def get_price_of_bitcoin() -> str:
"""Get the price of Bitcoin."""
url = "https://api.coingecko.com/api/v3/simple/price?ids=bitcoin&vs_currencies=usd"
response = requests.get(url)
price = response.json()["bitcoin"]["usd"]
return f"${price:,.2f} USD."
# Create the agent
crypto_agent = Agent(
name="CryptoTracker",
instructions="You are a crypto assistant. Use tools to get real-time data.",
tools=[get_price_of_bitcoin]
)
# Run the agent with an example prompt
result = Runner.run_sync(crypto_agent, "What's the price of Bitcoin?")
print(result.final_output)以及这个从数据库检索的例子:
python
from agents import Agent, Runner, function_tool
from pydantic import BaseModel
from typing import List
# create a simulated database
TICKETS_DB = {
"henry@gmail.com": [
{"id": "TCKT-001", "issue": "Login not working", "status": "resolved"},
{"id": "TCKT-002", "issue": "Password reset failed", "status": "open"},
],
"tom@gmail.com": [
{"id": "TCKT-003", "issue": "Billing error", "status": "in progress"},
]
}
# define Pydantic model
class CustomerQuery(BaseModel):
email: str
# define the tool that does a database query
@function_tool
def get_customer_tickets(query: CustomerQuery) -> str:
"""Retrieve recent support tickets for a customer based on email."""
tickets = TICKETS_DB.get(query.email.lower())
if not tickets:
return f"No tickets found for {query.email}."
response = "\n".join(
[f"ID: {t['id']}, Issue: {t['issue']}, Status: {t['status']}" for t in tickets]
)
return f"Tickets for {query.email}:\n{response}"
# create the agent
support_agent = Agent(
name="SupportHelper",
instructions="You are a customer support agent. Use tools to fetch user support history when asked about their tickets.",
tools=[get_customer_tickets]
)
# Run the agent
result = Runner.run_sync(support_agent, "Can you show me the ticket history for henry@gmail.com?")
print(result.final_output)两者都遵循同一模式:
-
用户请求 → Agent 检索 :问题需要"模型外"的信息(实时价格或用户特定数据)。Agent 识别到自身内置知识不足以作答,于是调用检索工具:
- 在 CryptoTracker 中,发起对 CoinGecko API 的 HTTP 请求;
- 在 SupportHelper 中,依据邮箱进行**(模拟)数据库查询**。
-
获得外部知识:工具以结构化格式返回数据(API 的 JSON、数据库的记录列表等),再传回模型。
-
LLM 融合生成:LLM 使用这些外部输入,生成自然语言回答。
这就是你熟悉的 RAG(Retrieval-Augmented Generation) :
检索(Retrieve)→ 增强(Augment)→ 生成(Generate) 。上面的步骤与 RAG 的三段式流程一一对应。
与"固化在权重中的静态知识"不同,检索型知识可以独立于模型训练 更新、贴合用户与场景 、并可溯源到现实世界的数据源。
在 RAG 中,最有挑战的是检索 这一步。前述通过 API/数据库查询的方法,非常适合结构化信息 (加密价格、客户档案等)。但当数据是非结构化文本 (如一组 SharePoint 文档)时,该如何检索?这就需要向量化(embeddings) 、语义搜索与**向量数据库(vector stores)**登场了。
非结构化数据
注意
下面我们给出的是简化概览 ,不会深入背后的复杂数学。若想系统了解 embeddings 的工作原理,可参考本书章节:
www.packtpub.com/en-mx/produ...
首先,定义术语。
Embedding(嵌入向量) 是文本的数值表示 。把它想象成一种只有机器能理解的"秘密语言",语法是一串数字。Embedding 能捕捉词、句子乃至整篇文档的"语义本质"。例如(纯示意):
| 句子 | 嵌入向量 |
|---|---|
| I like apples | 3432, 75, 32, ..., 76, 980 |
| I like bananas | 85, 1, 4, ..., 695, 47 |
| This is very difficult | 5, 596, 1254, ..., 7, 1 |
| This is like fitting a square peg into a round hole | 5, 4, 365, ..., 748, 9 |
由于嵌入向量表达语义 ,语义相近的两段文本会得到更相似 的向量。例如,I like apples 的嵌入会比它与下述法律文本之间更相似于 I like bananas :
All legislative Powers herein granted shall be vested in a Congress of the United States, which shall consist of a Senate and House of Representatives. 这就是**语义搜索(semantic search)**要解决的问题。
语义搜索 不是比对关键词,而是通过比较嵌入向量 来比较两段文本。我们常用**余弦相似度(cosine similarity)**来衡量两个向量在向量空间中的夹角,相似度范围在 0~1 之间:
- 接近 1:语义非常相近
- 接近 0:语义无关
示例余弦相似度(示意):
| 测试 | 基准文本 | 比较文本 | 嵌入余弦相似度 |
|---|---|---|---|
| 1 | I like apples | I like bananas | 0.90 |
| All legislative Powers...(美国宪法节选) | 0.71 | ||
| 2 | This is very difficult | I'm fitting a square peg into a round hole | 0.88 |
| All legislative Powers...(美国宪法节选) | 0.64 |
可见,I like apples 与 I like bananas 更"语义相近";同理,This is very difficult 与 I'm fitting a square peg into a round hole 虽然没有共享关键词 ,却语义相似,因此分数很高。
最后是向量数据库(vector store) :这是一类专门保存文本片段及其嵌入 的数据库。普通数据库像表格;向量库则存放高维向量 。向量库还有一个特性:当你加入新文档时,数据库会自动分块(chunking)文本、为每个块生成嵌入 并建立索引 ,以支持快速相似度检索。每个 chunk 通常包含几百个 token,并由专门的嵌入模型编码。
理解了这些术语后,我们来看在非结构化数据 上做 RAG (检索增强生成)时,如何进行文档摄取(ingestion)与检索(retrieval) 。
文档摄取(Document ingestion)
在检索之前,需要把知识库准备好:把原始文本转成向量库可用的形式。典型流程:
- 分块(Chunking) :把原文档拆成较小的片段(chunk),以便后续生成嵌入,并在被检索到时能放进提示词。
- 生成嵌入:将每个 chunk 送入嵌入模型,得到对应向量。
- 入库 :把嵌入及其对应的 chunk 文本存入向量库并建立索引。
此时,向量库就持有了全部非结构化文档 的嵌入。对于每批新文档,这一步只需进行一次。
检索(Retrieval)
文档摄取完成后,就可以在 RAG 的"检索"步骤对非结构化数据进行查询了:
- 查询嵌入 :当用户提问时,系统先用与入库阶段相同的嵌入模型把问题转换为嵌入向量。
- 语义搜索 :向量库基于余弦相似度 将查询向量与所有 chunk 的向量进行比对,返回Top-N 个语义最相关的 chunk。
随后是 augment 与 generate :把这些相关 chunk 附加进提示词,由 LLM 生成答案。区别在于,这里的"检索结果"是语义相近的文本片段,而不是 API 返回的加密货币价格或数据库里的订单状态。
在 Agents SDK 中使用向量库与 FileSearchTool
幸运的是,OpenAI Agents SDK 对非结构化文本的 RAG 流程(摄取与检索)做了托管封装,你无需手工实现。示例步骤如下,先创建向量库:
- 前往 platform.openai.com/ 并登录(使用与你 API Key 相同的账号)。
- 右上角 Dashboard → 左侧 Storage → 切换到 Vector stores。
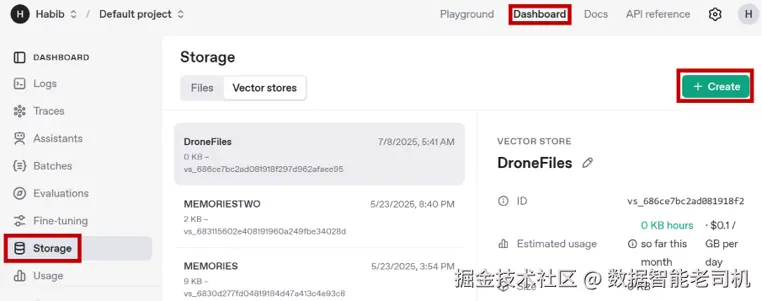 3. 点击 Create 新建向量库,例如命名 USConstitution。
3. 点击 Create 新建向量库,例如命名 USConstitution。
- 点击 + Add files 上传 USConstitution.txt (在本书仓库 Chapter 5 内),文件名仍为 USConstitution.txt ,
Purpose选 user_data ,然后 Attach。 - 平台会自动完成嵌入、索引等 RAG 所需操作。
- 复制保存向量库 ID。
下面用上一节建立的向量库,通过上一章介绍的 FileSearchTool 完成检索。该类接受一个向量库 ID 列表 ,自动搜索并取回合适的 chunk,然后交给 LLM 进行增强。创建 us_constitution_agent.py 并运行:
ini
from agents import Agent, Runner, FileSearchTool, SQLiteSession
# Instantiate the tool
filesearchtool = FileSearchTool(
vector_store_ids=['vs_687ed4bb479c81919b530ab152f373d8'] # 用你自己的向量库ID替换
)
# Create an agent
agent = Agent(
name="USConstitutionTool",
instructions="You are an AI agent that answers questions from the listed vector store, which has the US Constitution. Answer in one sentence.",
tools=[filesearchtool]
)
# Create a session
session = SQLiteSession("first_session")
while True:
question = input("You: ")
result = Runner.run_sync(agent, question, session=session)
print("Agent: ", result.final_output)运行后,你可以随意提问,Agent 会对给定向量库执行 RAG 并作答,例如:
vbnet
You: How old do senators need to be?
Agent: Senators must be at least 30 years old.你还能在 OpenAI Dashboard 的 Traces 模块查看本次检索返回的所有 chunk:
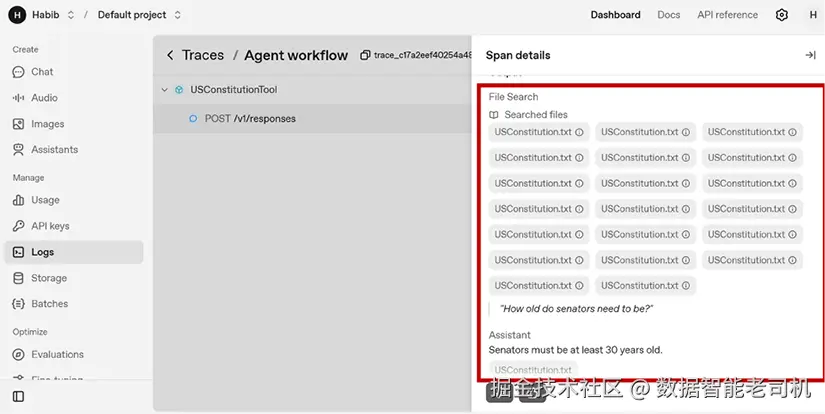
图 5.3:OpenAI Dashboard 日志
借此,Agents SDK 将文档摄取与检索 流程自动化,让你只用少量代码 就能为 Agent 加上检索型知识 的能力。当然,了解其背后在做什么仍然很重要,这有助于你理解流程与局限、并在需要时做出优化。
局限性
为你的 Agent 引入"检索型知识"会带来一些局限与陷阱,尤其在使用非结构化数据时。以下是最常见的三类问题:
- 问题含糊不清 :比如用户问"你们的退货政策是什么?",究竟指网购退货 、门店退货 ,还是某个具体商品?含糊的问题可能让 Agent 给出错误答案。
- 找不到相关信息 :有时知识库里没有 答案,Agent 可能会幻觉并"编造"内容。
- 来源冲突或过多 :如果检索到的信息互相矛盾 (例如两份文档的退货期限不同),Agent 可能会忽略其中一份或整合失败。
总之,构建任何基于知识的 Agent,都需要警惕上述陷阱,并认识到即使最好的 AI 也会偶尔踩雷。和所有依赖现实世界信息的系统一样,信息缺口、矛盾或误读 在所难免。不过,当记忆 与知识 两者兼备后,Agent 的能力已大幅提升:既能保留上下文,又能引入外部事实,更接近一个真正强大实用的智能体。
小结
本章为 Agent 配备了两项让其更聪明的关键能力:记忆 与知识。
-
先从短期记忆 入手:手动维护消息历史,并使用 Sessions 类实现多轮对话;针对上下文膨胀 的问题,介绍了滑动窗口 与消息摘要两种策略。
-
接着探索长期记忆 :通过带文件存储的 SQLiteSession 跨会话持久化;并用工具调用的结构化记忆召回,只存关键事实,既减少记忆冗余,又提升召回的准确性。
-
然后区分了两类模型知识:
- 训练知识:在初始训练中"烘焙"进模型权重的静态信息;
- 检索知识 :运行时通过工具调用 按需获取的动态、情境化数据。我们回顾了 RAG 模式:先检索外部数据(API、数据库、知识库),再将其注入提示,最后由 LLM 生成有依据的回答。
借助这些模式,你的 Agent 现在能够持有记忆 、保留用户上下文 ,并在需要时引入相关知识,离在真实应用场景中发挥价值又近了一步。
下一章,我们将把重心转向多智能体系统,让多个专长各异的 Agent 协同完成更复杂的任务。