线性时间推理、超长文本处理、硬件高效利用,这条"算法巨蟒"正在悄然蜕变。
在AI领域,Transformer架构自2017年确立统治地位以来,各类"Transformer杀手"就如雨后春笋般涌现。在众多挑战者中 ,基于结构化状态空间序列模型(SSM) 架构的Mamba无疑是最具影响力的竞争者之一。
如今,这条"AI巨蟒"已悄然进化至第三代------Mamba-3 已进入ICLR 2026盲审环节,凭借其在长文本处理 和低延迟推理方面的显著优势,正成为Transformer最有力的挑战者。

Mamba系列进化简史
- Mamba-1:选择性记忆的突破
Mamba-1的核心创新在于引入了选择性机制,让模型能够根据当前输入动态调整信息保留与遗忘。这解决了传统RNN的"记忆模糊"问题,使SSM在语言建模等离散任务上表现大幅提升。
虽然Mamba-1在小规模模型上展现出与Transformer媲美的性能,但其训练和推理效率仍有优化空间。
- Mamba-2:对偶加速的理论飞跃
Mamba-2通过结构化状态空间对偶(SSD)理论,揭示了SSM与注意力机制在数学上的等价性。这一理论突破使得Mamba-2在GPU上的推理速度比前代提升了2-8倍,同时保持了与Transformer相当的建模能力。
然而,Mamba-2在复杂状态追踪任务上仍存在局限,其状态演化模式相对单一。
Mamba-3的三大破局新技能
Mamba-3在三个关键维度上实现了重大突破,每一项都直指当前序列建模的痛点。
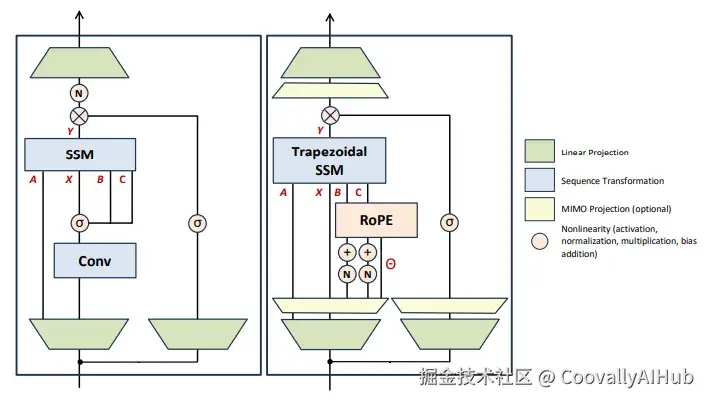
- 梯形离散化:更精确的状态更新
Mamba-3采用广义梯形法则进行离散化,相比Mamba-2使用的欧拉方法,提供了二阶精度的近似。
通俗理解:之前的状态更新就像只凭晚上感受写日记,现在早晚各记一笔再取平均,记忆更加准确。
这种方法减少了状态演化的累积误差,提升了长序列处理质量。实验表明,这种离散化方法与特定的偏置项结合后,甚至取代了传统线性模型中的短卷积组件。
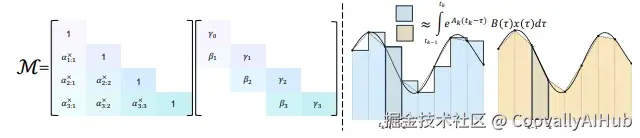
- 复数化状态空间:"钟摆"式记忆机制
Mamba-3大胆引入复数隐状态,使状态向量能够在复平面上演化,等效于在隐藏状态中加入了二维旋转动态。
核心价值:像在模型中安装了一个"节拍器",使其能够捕捉周期性模式和复杂的状态追踪任务。
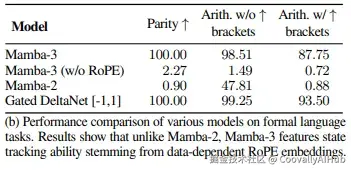
实验证明,这一改进让Mamba-3能够解决奇偶校验、模运算等 Mamba-2无法处理的任务。在形式语言评估中,Mamba-3在奇偶校验任务上达到100%准确率,而Mamba-2仅有0.9%,填补了线性模型在算法推理上的关键能力缺口。
- 多输入多输出(MIMO):硬件效率的极致利用
Mamba-3引入了MIMO架构 ,将状态更新从外积形式转换为矩阵乘法形式,显著提升了算术强度。
形象比喻: 从单车道变为多车道,让GPU计算单元能够"满载运行",不再受内存带宽限制。
这一改进在不增加状态大小的前提下,大幅提升了推理阶段的硬件利用率。当设置MIMO秩r=4时,模型在保持参数总量不变的情况下,在语言理解任务上的平均准确率比SISO版本提升1.2个百分点。

实证表现:全面超越前代
- 质量更优:下游任务全面领先
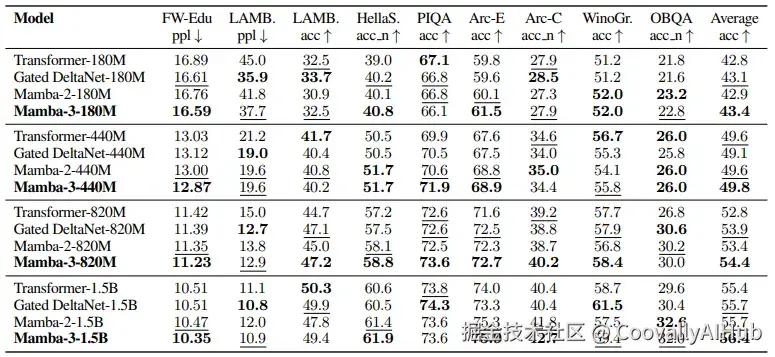
在标准语言建模评估中,Mamba-3在不同规模模型上全面超越Mamba-2、Gated DeltaNet和Transformer基线。
从180M到1.5B的四个模型规模上,Mamba-3在FineWeb-Edu验证集 perplexity 均低于对比模型。特别是在1.5B规模上,Mamba-3以10.35的perplexity显著优于Mamba-2的10.47和Transformer的10.51。
- 能力更强:状态追踪突破性进展
在状态追踪任务上,Mamba-3展现出突破性能力:
- 完美解决奇偶校验任务(100%准确率)
- 在无括号模运算上达到98.51%准确率
- 在带括号模运算上达到87.75%准确率
而Mamba-2在这些任务上的表现接近随机猜测,证明复数化SSM确实带来了质的飞跃。
- 推理更高效:延迟显著降低
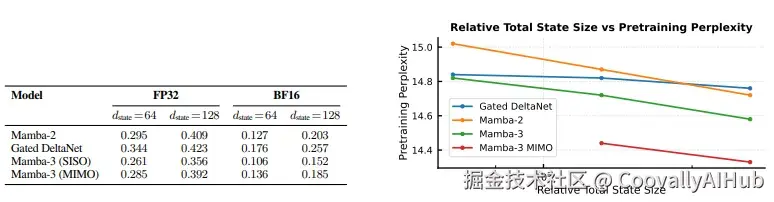
实测数据显示,在常用配置(bf16,d_state=128)下:
- Mamba-3 SISO延迟为0.152ms,比Mamba-2的0.203ms快25%
- Mamba-3 MIMO延迟为0.185ms,比Mamba-2快9%
同时,Mamba-3在固定计算预算下的性能-效率帕累托前沿上实现了明显下移,意味着在相同推理资源下能获得更好性能。
架构精炼:更接近Transformer的设计
Mamba-3在整体架构上也进行了重要调整,使其更接近成熟的Transformer设计:
- 用QK归一化替换预输出投影归一化
- 重新定位归一化层至B、C投影之后
- 使短卷积成为可选组件
- 采用Llama风格的交替块设计
这些调整不仅提升了训练稳定性,也使得Mamba-3能够更好地利用Transformer生态中积累的经验和技术。
应用前景:三大优势场景
- 长文本处理与内容生成
Mamba-3适合处理长文档、DNA序列、日志分析等超长序列任务,不受窗口长度限制,且计算开销随序列长度线性增长而非Transformer的平方级增长。
在大海捞针(NIAH) 测试中,Mamba-3在4096长度上下文中的检索准确率显著高于Mamba-2,展现出出色的长程信息保持能力。
论文表2(第8页)展示了各模型在检索任务上的表现
- 实时推理与交互式AI
在实时对话、在线翻译、语音交互等场景中,Mamba-3的恒定推理延迟和快速响应特性使其成为理想选择。其线性时间推理特性使得响应速度不随对话长度增加而下降,有望在移动设备上实现高质量本地推理。
- 推理阶段成本优化
对云端大模型服务商,Mamba-3提供了降低推理成本 的新路径------在相同推理预算下支持更大模型或更长序列生成,直接转化为吞吐提升和成本节省。
结语
虽然Mamba-3表现出色,但Transformer凭借其成熟的训练技巧和广泛的社区支持,短期内仍将保持主流地位。
Mamba-3在精细推理任务和特定检索场景上仍有提升空间。研究者已开始探索混合架构,结合Mamba-3与检索机制,以弥补固定状态架构的不足。
论文作者指出:"混合Mamba-3架构将是充满希望的方向,同时我们的设计原则也可广泛应用于线性时间序列模型。"
Mamba-3的进化展现了一条不同于Transformer的技术路径:通过更精巧的状态设计而非更大的参数量,在效率与能力间寻找平衡。
从Mamba-1的雏形初现,到Mamba-2的理论突破,再到Mamba-3的全面跃迁,这条"算法巨蟒"正以惊人的速度进化,为序列建模领域带来了新的可能性和想象空间。
在追求更长上下文、更快推理的道路上,Mamba-3证明了一点:Transformer之外,别有洞天。