Boundary Difference Over Union Loss For Medical Image Segmentation
Abstract
医学图像分割对于临床诊断至关重要。然而,目前用于医学图像分割的损失函数主要关注整体分割结果,而提出用于指导边界分割的损失函数相对较少。现有的那些针对边界分割的损失函数通常需要与其他损失函数结合使用,且效果不佳。为解决这一问题,我们开发了一种简单而有效的损失函数,称为边界交并差损失(Boundary Difference over Union Loss,简称 Boundary DoU Loss),用于指导边界区域的分割。该损失函数是通过计算预测结果与真实标签差异集与差异集和部分交集合并集的比率得到的。我们的损失函数仅依赖于区域计算,易于实现且训练稳定,无需任何额外的损失函数。此外,我们利用目标大小自适应地调整对边界区域的关注度。在两个数据集(ACDC 和 Synapse)上使用 UNet、TransUNet 和 Swin-UNet 进行的实验结果表明,我们提出的损失函数是有效的。代码可在 https://github.com/sunfan-bvb/BoundaryDoULoss 获取。
Introduction
医学图像分割是图像分割领域的一个重要分支16,4,23,9,15,5,在临床上可用于对人体器官、组织和病变进行分割。基于深度学习的方法在医学图像分割任务中取得了巨大进展,并获得了良好的性能,包括早期的基于卷积神经网络(CNN)的方法18,25,11,10,以及最近利用Transformer架构的方法24,22,8,21,7。从CNN到Transformer,人们提出了许多不同的模型架构,以及一系列训练损失函数。
这些损失函数主要可分为三类。
第一类以交叉熵损失(CrossEntropy Loss)为代表,用于计算预测概率分布与真实标签之间的差异。焦点损失(Focal Loss)14旨在解决难以学习的样本问题。
第二类包括Dice损失及其改进版本。Dice损失17基于预测结果与真实标签之间的交集和并集进行计算。Tversky损失19通过平衡精确率和召回率来改进Dice损失。广义Dice损失20将Dice损失扩展到多类别分割任务。
第三类则侧重于边界分割。豪斯多夫距离损失(Hausdorff Distance Loss)12旨在优化豪斯多夫距离,而边界损失(Boundary Loss)13则通过计算预测边界上每个点与对应真实标签点之间的距离作为权重,对每个点的预测概率进行加权求和。然而,当前用于优化分割边界的损失函数往往依赖于结合不同的损失函数,或存在训练不稳定的问题。为解决这些问题,我们提出了一种受边界交并比(Boundary IoU)指标6启发的简单边界损失函数,即边界交并差损失(Boundary DoU Loss)。
我们提出的边界交并差损失通过类似于Dice损失的区域计算方式,增强了对靠近边界区域的关注。通过计算真实标签与预测结果之间的差异集,我们获得了边界附近的错误区域,然后通过降低该差异集与差异集和部分交集合并集的比率来减小这一错误区域。为评估我们提出的边界交并差损失的性能,我们在ACDC1和Synapse数据集上使用UNet18、TransUNet3和Swin-UNet2模型进行了实验。实验结果表明,与其他损失函数相比,我们的损失函数表现出了优越的性能。
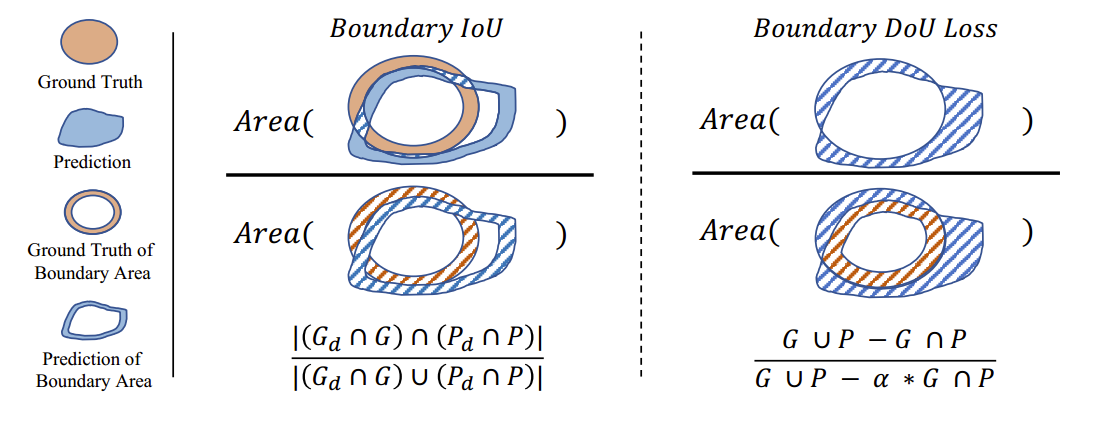
图1.边界交并比 (BoundaryloU,左图)和边界不确定度损失 (Boundary DoU Loss,右图) 的示意图,图中阴影区域将被计算。GGG和PPP分别表示真实值和预测值,GdG_dGd和PdP_{d}Pd表示它们对应的边界区域。α\alphaα是一个超参数。
2 Method
本节首先回顾边界交并比(Boundary IoU)指标6。随后,我们将详细描述我们提出的边界交并差损失(Boundary DoU loss)函数及其自适应尺寸策略。接下来,我们将讨论边界交并差损失与Dice损失之间的联系。
2.1 Boundary IoU Metric
边界交并比 (Boundary loU) 是一种主要用于评估分割边界质量的指标。给定真实标签的二值掩码G,GdG,G_dG,Gd表示在像素宽度为ddd的范围内的内部边界区域。PPP是预测的二值掩码,而PdP_dPd表示对应的内部边界区域,其大小被确定为相对于图像对角线长度的固定比例 0.5%。然后,我们可以使用以下公式来计算边界交并比指标,如图1左侧所示,
Boundary IoU=∣(Gd∩G)∩(Pd∩P)∣∣(Gd∩G)∪(Pd∩P)∣. Boundary\:IoU=\frac{|(G_d\cap G)\cap(P_d\cap P)|}{|(G_d\cap G)\cup(P_d\cap P)|}. BoundaryIoU=∣(Gd∩G)∪(Pd∩P)∣∣(Gd∩G)∩(Pd∩P)∣.
较大的边界交并比 (Boundary IoU)值表明GdG_dGd和PdP_dPd完美匹配,这意味着GGG和PPP的形状相似,且它们的边界对齐良好。在实际应用中,GdG_dGd和PdP_dPd是通过腐蚀操作 (erode operation)6来计算的。然而,腐蚀操作是不可微的,因此我们无法直接将边界交并比用作损失函数来进行训练,以增加两个边界区域之间的一致性。
2.2 Boundary DoU Loss
如图1左侧所示,我们可以发现,两个边界的并集∣(Gd∩G)∪(Pd∩P)∣|(G_d\cap G)\cup(P_d\cap P)|∣(Gd∩G)∪(Pd∩P)∣实际上与GGG和PPP之间的差集高度相关。交集∣(Gd∩G)∩(Pd∩P)∣|(G_d\cap G)\cap(P_d\cap P)|∣(Gd∩G)∩(Pd∩P)∣与GGG和PPP交集的内部边界相关。如果差集G∪P−G∩PG\cup P-G\cap PG∪P−G∩P减小而G∩PG\cap PG∩P增大,相应的边界交并比(Boundary IoU)将增加。
基于上述分析,我们设计了一种基于差异区域的边界不确定度损失(Boundary DoU Loss),以方便计算和反向传播。首先,我们直接将差集视为GGG和PPP之间不匹配的边界。此外,为了简化计算,我们考虑将交集区域的中间部分作为内部边界去除,这部分通过α∗G∩P(α<1)\alpha*G\cap P(\alpha<1)α∗G∩P(α<1)计算。然后,我们联合计算G∪P−α∗G∩PG\cup P-\alpha*G\cap PG∪P−α∗G∩P作为部分并集。最后,如图1右侧所示,我们的边界不确定度损失可以通过以下公式计算:
LDoU=G∪P−G∩PG∪P−α∗G∩P, \begin{aligned}L_{DoU}=\frac{G\cup P-G\cap P}{G\cup P-\alpha*G\cap P},\end{aligned} LDoU=G∪P−α∗G∩PG∪P−G∩P,
其中,α 是一个超参数,用于控制部分并集区域的影响程度。
Adaptive adjusting α based-on target size:
另一方面,边界区域在整个目标中所占的比例会因目标大小的不同而有所变化。当目标较大时,边界区域仅占很小的一部分,而内部区域则相对容易分割,因此我们鼓励更多地关注边界区域。在这种情况下,使用较大的α值是更合适的。然而,当目标较小时,无论是内部区域还是边界区域都不容易区分,因此我们需要同时关注内部区域和边界区域,此时使用较小的α值更为合适。为了实现这一目标,我们进一步根据边界区域所占的比例自适应地计算α值。
α=1−2×CS,α∈[0,1), \alpha = 1 - 2 \times \frac{C}{S}, \alpha \in [0, 1), α=1−2×SC,α∈[0,1),
其中,C 表示目标的边界长度,S 表示其尺寸(面积)。
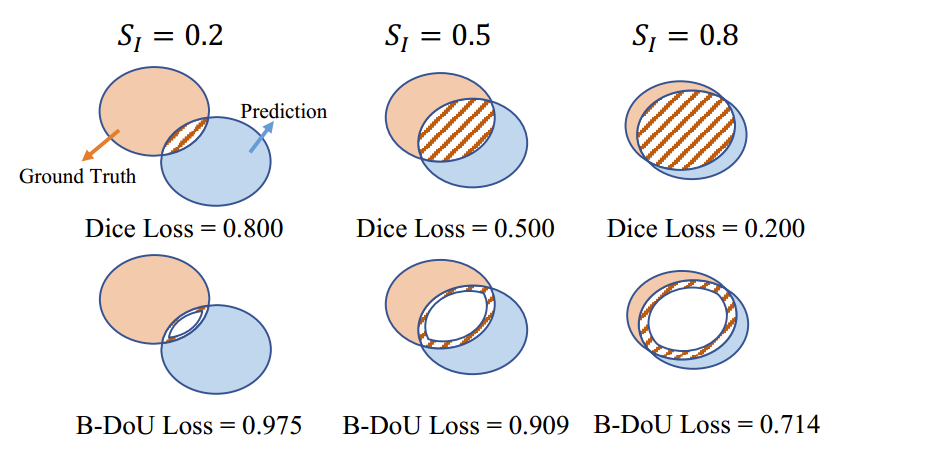
图2. 边界交并差损失(B-DoU Loss)与Dice损失的比较。该图分别展示了在真实标签(Ground Truth)与预测结果(Prediction)交集的20%、50%和80%处计算得到的两种损失的值。我们假设真实标签和预测结果的面积均为1,且α的值为0.8。
2.3 Discussion
在这一部分中,我们将边界交并差损失(Boundary DoU Loss)与Dice损失进行比较。首先,我们可以将我们的边界交并差损失重新表述为:
LDoU=SDSD+SI−αSI=1−α′∗SISD+α′∗SI, L_{DoU}=\frac{S_D}{S_D+S_I-\alpha S_I}=1-\frac{\alpha^{\prime}*S_I}{S_D+\alpha^{\prime}*S_I}, LDoU=SD+SI−αSISD=1−SD+α′∗SIα′∗SI,
其中,SDS_{D}SD表示真实标签 (ground truth)与预测结果 (prediction) 之间差异集的面积,SIS_{I}SI表示两者的交集面
积,且α′=1−α\alpha^{\prime}=1-\alphaα′=1−α。与此同时,Dice损失可以表示为以下形式:
LDice=1−2∗TP2∗TP+FP+FN=1−2∗SI2∗SI+SD, L_{Dice}=1-\frac{2*TP}{2*TP+FP+FN}=1-\frac{2*S_I}{2*S_I+S_D}, LDice=1−2∗TP+FP+FN2∗TP=1−2∗SI+SD2∗SI,
其中,TP、FP和FN分别表示真正例 (True Positive)、假正例 (False Positive) 和假反例 (False Neqative)。可以看出,边界交并差损失(Boundary DoU Loss)与Dice损失的区别仅在于交集面积所占的比例。Dice损失关注的是整个交集面积,而由于α<1\alpha<1α<1,边界交并差损失则更关注边界区域。与Dice损失函数类似,最小化LDoUL_DoULDoU 将促使交集面积增大 (SI↑)(S_I\uparrow)(SI↑) 和差异集面积减小 (SD↓)(S_D\downarrow)(SD↓) 。同时,LDoUL_DoULDoU 会对SD/SIS_D/S_ISD/SI的比值施加更大的惩罚。为了更清晰地验证其有效性,我们在图2中比较了不同情况下LDiceL_{Dice}LDice和LDoUL_{DoU}LDoU 的值。LDiceL_{Dice}LDice随差异集面积的增大而线性减小,而当SIS_ISI足够大时,LDoUL_{DoU}LDoU的减小速度会更快。