笔记来自:17小时最全Web3教程:ERC20,NFT,Hardhat,CCIP跨链_哔哩哔哩_bilibili,十分推荐大家学习该课程!
目录
[1)struct 结构体](#1)struct 结构体)
[2)array 数组](#2)array 数组)
[3)mapping 映射](#3)mapping 映射)
一、函数function(续)
1)修改值操作

当函数需要读写时,view就不能声明;当函数无需返回时,returns就不必声明;所以如图,只声明public即可。
我们部署在区块链上的智能合约是无法删除的,在Remix里删除,只不过是把这个函数从Remix UI界面里删除了。如果智能合约有更新,则需要先重新编译,再Deploy部署,否则只点击Deploy部署的还是原始的智能合约代码。
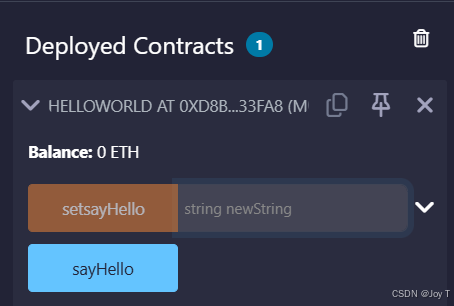
橙色函数表示该函数需要修改一些状态。
2)运算操作
pure:表示本函数只做纯运算(同样也不会修改任何一个变量的值);view表示本函数只做纯读取。
对于internal的函数,Deploy之后不会出现在UI里面,因为外部的钱包或者合约是没办法调用这个函数的(所以意思就是让内部的其他关联的函数间接调用internal函数)。
二、Solidity存储模式
智能合约的变量与运行数据在EVM中遵循严格的存储层级结构。不同存储位置影响Gas成本、生命周期与可读写权限。理解存储模式,是掌握合约成本控制与安全边界的关键。
前三类的显示声明是只针对于存储结构的(mapping映射、struct结构体、数组等),如果是基础数据类型(string是bytes数组-复杂的数据结构,所以需要显示声明存储模式),那么智能的编译器会自动匹配storage/memory/calldata,不需要我们显示声明。
1)storage:链上永久存储
storage用于保存合约的状态变量,由EVM以Merkle Patricia Trie结构写入区块链。数据具有持久性,每次修改都消耗较高Gas。合约变量、映射、结构体与数组等核心状态均存放在storage中,用于反映"合约的长期记忆"。
【永久存在于区块链上,永久存在于合约里面】
【在合约中声明的变量都默认是storage,写了还可能报错,因为编译器太智能,不需要冗余的代码】
2)memory:临时可读写存储
memory为函数执行期间的临时存储空间 ,生命周期随调用结束而销毁。适合存放临时数组、临时字符串等中间变量。读取成本较低,不进行链上持久化存储,在逻辑计算层承担主要角色。
【临时变量的临时空间】
3)calldata:只读参数存储
calldata用于函数外部调用时的参数传输,是只读区域,Gas成本更低,不允许在内部修改。适合修饰外部函数的动态数组或字符串参数,用于降低运行开销并提升安全性。
【与memory的最大区别:calldata在运行时不可修改】
4)stack:EVM底层计算栈
stack是EVM执行指令的核心栈结构,负责运算与临时取值。访问速度最快,但容量受限(1024个slot,每个slot为32 bytes)。大量运算依赖stack完成,不支持复杂数据结构存放。
5)codes:合约字节码区
codes区域保存合约部署后的字节码,并承担合约逻辑的常量载体。该区域只读且不可修改,用于限制代码在部署后保持逻辑确定性,这是智能合约不可篡改特性的基础之一。
6)logs:事件日志记录区
logs由EVM提供,用于记录事件(event),主要面向链外访问。链上无法读取logs,但区块浏览器、后端服务或脚本可订阅事件,用于监听转账、交易以及合约状态变化。logs不作为状态,因此成本远低于storage。
三、Solidity数据结构
智能合约中的数据结构决定了链上数据的组织方式,也直接影响Gas成本、读写性能与可维护性。Solidity的核心数据结构包括struct、array与mapping三类,它们覆盖了对象型、顺序型与键值型数据的主要表达方式。
1)struct 结构体
struct用于组织不同类型的变量,将其组合成一个逻辑实体。常用于描述"人、订单、资产"等具备多字段属性的对象结构。结构体变量可存储在storage、memory或calldata中,适用于具有真实业务含义的数据建模。
示例:
javascript
struct User {
uint id;
address wallet;
string name;
}2)array 数组
可以把多个相同的数据结构/基础数据类型存储在一起。每一个元素数据类型相同,和 java 里的数组定义是一样的。可声明为动态数组或定长数组。Solidity数组具备随机访问能力,按索引读取的时间复杂度为O(1),按值搜索则需要遍历整个数组。
示例:
javascript
uint[] public scores; // 动态数组
uint[5] public fixedScores; // 定长数组数组适合以顺序逻辑组织数据,但在规模较大时,进行删除或搜索会产生较高Gas成本。
3)mapping 映射
mapping是一种键值对(key → value)存储结构,提供常数级时间复杂度的查找性能。其本质是哈希表,用于构建可快速检索的链上关系,例如地址 → 余额或ID → 用户信息。
示例:
javascript
mapping(address => uint) public balance;相较数组,mapping只能按键访问,不支持遍历,也无法通过长度管理,因此常与数组搭配,用于同时满足"快速查找"和"便于遍历"两类需求。