🌟 分布式架构未来趋势:从云原生到智能边缘的演进之路
文章目录
- [🌟 分布式架构未来趋势:从云原生到智能边缘的演进之路](#🌟 分布式架构未来趋势:从云原生到智能边缘的演进之路)
- [🔄 一、分布式架构演进路线回顾](#🔄 一、分布式架构演进路线回顾)
-
- [📜 技术演进时间轴](#📜 技术演进时间轴)
- [📊 架构范式对比分析](#📊 架构范式对比分析)
- [💡 驱动力分析](#💡 驱动力分析)
- [🌐 二、边缘计算与云协同新范式](#🌐 二、边缘计算与云协同新范式)
-
- [🏗️ 边缘计算架构革命](#🏗️ 边缘计算架构革命)
- [⚡ 边缘智能平台架构](#⚡ 边缘智能平台架构)
- [🚗 智能网联车案例实践](#🚗 智能网联车案例实践)
- [⛓️ 三、区块链与分布式信任机制](#⛓️ 三、区块链与分布式信任机制)
-
- [🔗 区块链赋能分布式系统](#🔗 区块链赋能分布式系统)
- [💼 企业级区块链实践](#💼 企业级区块链实践)
- [🌉 区块链与传统系统集成](#🌉 区块链与传统系统集成)
- [🧠 四、AI模型的分布式训练与部署](#🧠 四、AI模型的分布式训练与部署)
-
- [🚀 大规模分布式训练架构](#🚀 大规模分布式训练架构)
- [💻 分布式训练框架实战](#💻 分布式训练框架实战)
- [🔄 智能模型管理系统](#🔄 智能模型管理系统)
- [💫 五、云原生+AI+边缘的融合趋势](#💫 五、云原生+AI+边缘的融合趋势)
-
- [🌉 融合架构设计模式](#🌉 融合架构设计模式)
- [🏗️ 融合平台参考架构](#🏗️ 融合平台参考架构)
- [🔄 自适应调度策略](#🔄 自适应调度策略)
🔄 一、分布式架构演进路线回顾
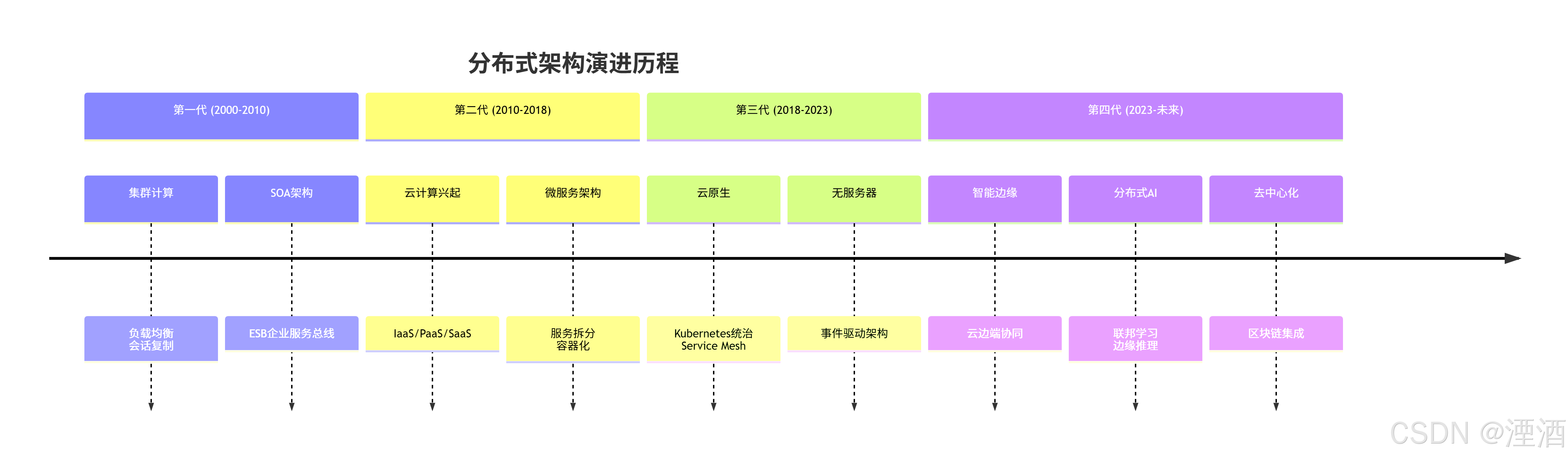
📜 技术演进时间轴
分布式架构四代演进:
📊 架构范式对比分析
各代分布式架构特征对比:
| 维度 | 第二代(微服务) | 第三代(云原生) | 第四代(智能分布式) |
|---|---|---|---|
| 核心单元 | 服务(独立进程/服务实例) | 容器 / Pod(轻量、可移植) | 智能体 / 函数(函数、agent、自治服务) |
| 调度方式 | 静态负载均衡(硬编码/HAProxy) | 动态调度(K8s Scheduler / HPA) | 智能弹性调度(行为感知、SLA 驱动) |
| 数据管理 | 数据库分片、读写分离 | 多模数据服务(关系 + 时序 + 文档 + KV) | 边缘缓存 + 云存储 + 数据流原生(位点感知) |
| 通信模式 | 同步 RPC(REST / gRPC) | 服务网格(mTLS、sidecar、可观测) | 事件驱动 + 消息流(流式处理、事件溯源) |
| 治理方式 | 集中配置(配置中心、手动下发) | 声明式 API / GitOps(声明式、可回滚) | 自主治理 + 策略驱动(策略引擎 + RL/AI 调优) |
💡 驱动力分析
技术演进的核心驱动力:
java
public class ArchitectureEvolutionDriver {
// 业务需求驱动
private BusinessDriver businessDriver = new BusinessDriver(
"实时性要求", // 物联网、金融交易
"数据量爆炸", // 大数据、AI训练
"全球化部署", // 多地域合规要求
"成本优化需求" // 资源利用率提升
);
// 技术能力驱动
private TechnologyDriver techDriver = new TechnologyDriver(
"硬件进步", // 5G、专用AI芯片
"算法突破", // 深度学习、联邦学习
"网络升级", // 低延迟、高带宽
"平台成熟" // 云平台、开源生态
);
// 社会因素驱动
private SocialDriver socialDriver = new SocialDriver(
"隐私保护法规", // GDPR、数据本地化
"可持续发展", // 绿色计算
"去中心化趋势" // Web3.0、数字主权
);
}🌐 二、边缘计算与云协同新范式
🏗️ 边缘计算架构革命
云-边-端协同架构:
云端中心 区域边缘节点 区域边缘节点 现场边缘设备 现场边缘设备 现场边缘设备 现场边缘设备 终端设备 终端设备 终端设备 终端设备
⚡ 边缘智能平台架构
**Kubernetes边缘扩展(K3s/KubeEdge)**:
yaml
# 边缘节点配置示例
apiVersion: apps/v1
kind: Deployment
metadata:
name: edge-ai-inference
namespace: edge-computing
spec:
replicas: 50 # 大规模边缘节点部署
selector:
matchLabels:
app: edge-ai
tier: inference
template:
metadata:
labels:
app: edge-ai
tier: inference
spec:
# 边缘节点特定配置
nodeSelector:
node-type: edge-device
tolerations:
- key: "edge"
operator: "Equal"
value: "true"
effect: "NoSchedule"
containers:
- name: ai-inference
image: registry.cn-hangzhou.aliyuncs.com/company/edge-ai-model:v2.1.0
resources:
requests:
memory: "512Mi"
cpu: "500m"
limits:
memory: "1Gi"
cpu: "1000m"
# 边缘环境变量
env:
- name: EDGE_NODE_ID
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: MODEL_UPDATE_URL
value: "https://cloud-center/model-update"
# 健康检查适应边缘网络
livenessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 60
periodSeconds: 30
timeoutSeconds: 10
---
# 边缘自治策略
apiVersion: policy.k8s.io/v1
kind: PodDisruptionBudget
metadata:
name: edge-ai-pdb
spec:
minAvailable: 80% # 允许20%边缘节点离线
selector:
matchLabels:
app: edge-ai🚗 智能网联车案例实践
车云协同计算架构:
java
// 边缘计算车联网服务
@Service
public class VehicleEdgeService {
// 本地实时决策(低延迟)
@EdgeComputing(latencyRequirement = 50) // 50ms延迟要求
public DrivingDecision makeRealTimeDecision(SensorData sensorData) {
// 使用本地轻量模型进行实时推理
return localAIModel.inference(sensorData);
}
// 云端模型训练(高算力)
@CloudComputing(computeIntensive = true)
public void trainAIModel(TrainingDataset dataset) {
// 在云端进行大规模模型训练
cloudTrainingService.distributedTraining(dataset);
}
// 边云协同决策
@HybridComputing
public CollaborativeResult collaborativeDecision(
VehicleContext context, CloudAI cloudModel) {
// 1. 边缘快速响应
EdgeResponse edgeResponse = makeRealTimeDecision(context.getSensorData());
// 2. 云端深度分析(异步)
CompletableFuture<CloudAnalysis> cloudFuture =
cloudModel.analyzeAsync(context.getHistoricalData());
// 3. 结果融合
return fuseDecisions(edgeResponse, cloudFuture.get());
}
}
// 边缘设备管理
@Component
public class EdgeDeviceManager {
/**
* 动态模型下发策略
*/
public void deployModelToEdge(String modelId, List<EdgeDevice> devices) {
devices.parallelStream().forEach(device -> {
// 根据设备能力选择模型版本
ModelVersion version = selectModelVersion(device.getCapability());
// 差分更新,减少网络传输
DifferentialUpdate diffUpdate = modelService.generateDiffUpdate(
device.getCurrentModel(), version);
// 可靠传输(断点续传)
reliableTransferService.sendUpdate(device, diffUpdate);
});
}
/**
* 边缘设备健康监控
*/
@Scheduled(fixedRate = 30000)
public void monitorEdgeHealth() {
edgeDevices.forEach(device -> {
HealthStatus status = deviceHealthChecker.check(device);
if (status == HealthStatus.DEGRADED) {
// 自动降级处理
degradeModelComplexity(device);
} else if (status == HealthStatus.OFFLINE) {
// 云端接管服务
cloudTakeoverService.takeover(device.getResponsibilities());
}
});
}
}⛓️ 三、区块链与分布式信任机制
🔗 区块链赋能分布式系统
区块链分布式信任架构:
应用层 智能合约 共识层 网络层 存储层 跨链互操作 去中心化身份 拜占庭容错 P2P网络 分布式账本
💼 企业级区块链实践
Hyperledger Fabric联盟链架构:
java
// 智能合约(链码)示例
@Contract
public class SupplyChainContract {
@Transaction
public void createProduct(Context ctx, String productId,
String manufacturer, String details) {
// 权限验证
ClientIdentity client = ctx.getClientIdentity();
if (!client.assertAttributeValue("role", "manufacturer")) {
throw new ChaincodeException("权限不足");
}
// 创建产品资产
Product product = new Product(productId, manufacturer, details);
ctx.getStub().putState(productId, product.toJSONString());
// 触发事件
ctx.getStub().setEvent("ProductCreated", productId.getBytes());
}
@Transaction
public void transferOwnership(Context ctx, String productId,
String newOwner, String transferDetails) {
// 获取当前状态
String productJSON = ctx.getStub().getState(productId);
Product product = Product.fromJSON(productJSON);
// 验证当前所有者
if (!product.getCurrentOwner().equals(ctx.getClientIdentity().getId())) {
throw new ChaincodeException("无权转移该产品");
}
// 更新所有权
product.transferOwnership(newOwner, transferDetails);
ctx.getStub().putState(productId, product.toJSONString());
// 记录交易历史
recordTransactionHistory(ctx, productId, "OWNERSHIP_TRANSFER", transferDetails);
}
}
// 分布式身份管理
@Service
public class DecentralizedIdentityService {
/**
* 创建去中心化身份
*/
public DigitalIdentity createIdentity(String owner, Map<String, Object> attributes) {
// 生成DID(去中心化标识符)
String did = "did:example:" + UUID.randomUUID();
// 创建可验证凭证
VerifiableCredential credential = VerifiableCredential.builder()
.id(UUID.randomUUID().toString())
.issuer("did:example:issuer")
.subject(did)
.issuanceDate(Instant.now())
.credentialSubject(attributes)
.build();
// 数字签名
String signedCredential = signCredential(credential);
return DigitalIdentity.builder()
.did(did)
.owner(owner)
.credentials(Collections.singletonList(signedCredential))
.build();
}
/**
* 跨链身份验证
*/
public boolean verifyCrossChainIdentity(String did, String targetChain) {
// 查询源链身份信息
IdentityProof proof = identityChain.queryIdentityProof(did);
// 跨链验证
return crossChainVerifier.verify(proof, targetChain);
}
}🌉 区块链与传统系统集成
混合架构设计模式:
java
// 区块链桥接服务
@Service
public class BlockchainBridgeService {
/**
* 传统数据库与区块链同步
*/
@Transactional
public void syncToBlockchain(BusinessEntity entity, String operation) {
// 1. 传统数据库操作
entityRepository.save(entity);
// 2. 区块链存证(异步)
CompletableFuture.runAsync(() -> {
try {
BlockchainRecord record = BlockchainRecord.builder()
.entityId(entity.getId())
.operation(operation)
.timestamp(Instant.now())
.dataHash(calculateHash(entity))
.build();
blockchainService.recordTransaction(record);
} catch (Exception e) {
// 区块链操作失败不影响主业务
log.error("区块链存证失败: {}", entity.getId(), e);
}
});
}
/**
* 区块链验证服务
*/
public VerificationResult verifyDataIntegrity(String entityId) {
// 从传统数据库获取数据
BusinessEntity entity = entityRepository.findById(entityId);
// 从区块链获取存证
BlockchainRecord record = blockchainService.queryRecord(entityId);
// 验证数据完整性
String currentHash = calculateHash(entity);
boolean integrity = currentHash.equals(record.getDataHash());
return VerificationResult.builder()
.integrity(integrity)
.blockchainTimestamp(record.getTimestamp())
.currentHash(currentHash)
.storedHash(record.getDataHash())
.build();
}
}
// 事件驱动的区块链集成
@Component
public class BlockchainEventListener {
@EventListener
public void handleBusinessEvent(BusinessEvent event) {
// 根据事件类型决定是否上链
if (needBlockchainRecording(event)) {
BlockchainRecord record = convertToBlockchainRecord(event);
blockchainService.recordTransaction(record);
}
}
@KafkaListener(topics = "blockchain-events")
public void consumeBlockchainEvent(BlockchainEvent event) {
// 处理区块链回调事件
switch (event.getType()) {
case "CONTRACT_EXECUTED":
updateBusinessState(event);
break;
case "ORACLE_DATA_RECEIVED":
processOracleData(event);
break;
default:
log.warn("未知的区块链事件类型: {}", event.getType());
}
}
}🧠 四、AI模型的分布式训练与部署
🚀 大规模分布式训练架构
联邦学习系统架构:
协调服务器 客户端A 客户端B 客户端C ... 本地训练 本地训练 本地训练 模型更新
💻 分布式训练框架实战
PyTorch + Kubernetes分布式训练:
yaml
# 分布式训练Job配置
apiVersion: batch/v1
kind: Job
metadata:
name: distributed-training-job
annotations:
training-framework: "pytorch"
model-type: "transformer"
spec:
parallelism: 8 # 同时运行的Pod数量
completions: 8 # 需要完成的总Pod数量
template:
spec:
containers:
- name: training-worker
image: pytorch-distributed:1.9.0
command: ["python", "-m", "torch.distributed.launch"]
args:
- "--nproc_per_node=1"
- "--nnodes=8"
- "--node_rank=$(POD_NAME)"
- "--master_addr=training-master"
- "--master_port=23456"
- "train.py"
- "--batch_size=1024"
- "--learning_rate=0.001"
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
resources:
requests:
nvidia.com/gpu: 2 # GPU资源
memory: "32Gi"
cpu: "8"
limits:
nvidia.com/gpu: 2
memory: "64Gi"
cpu: "16"
volumeMounts:
- name: training-data
mountPath: /data
- name: model-checkpoints
mountPath: /checkpoints
volumes:
- name: training-data
persistentVolumeClaim:
claimName: training-data-pvc
- name: model-checkpoints
persistentVolumeClaim:
claimName: checkpoints-pvc
restartPolicy: OnFailure
---
# 模型服务配置
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: transformer-model
spec:
predictor:
pytorch:
storageUri: "s3://models/transformer/v1.0"
resources:
requests:
nvidia.com/gpu: 1
memory: "8Gi"
limits:
nvidia.com/gpu: 1
memory: "16Gi"🔄 智能模型管理系统
模型版本控制与部署:
python
# 模型生命周期管理
class ModelLifecycleManager:
def __init__(self, distributed_storage, version_control):
self.storage = distributed_storage
self.version_control = version_control
def distributed_training(self, training_config):
"""分布式模型训练"""
# 1. 数据分片
data_shards = self.shard_dataset(training_config.dataset)
# 2. 分配训练任务
workers = self.allocate_workers(len(data_shards))
# 3. 并行训练
model_updates = []
with concurrent.futures.ThreadPoolExecutor() as executor:
futures = [
executor.submit(self.train_worker, worker, shard, training_config)
for worker, shard in zip(workers, data_shards)
]
for future in concurrent.futures.as_completed(futures):
model_updates.append(future.result())
# 4. 模型聚合
aggregated_model = self.federated_averaging(model_updates)
# 5. 版本控制
model_version = self.version_control.commit(aggregated_model)
return model_version
def canary_deployment(self, model_version, traffic_percentage):
"""金丝雀部署策略"""
# A/B测试部署
baseline_service = self.get_baseline_service()
new_service = self.deploy_new_version(model_version)
# 流量分流
routing_config = {
'baseline': 100 - traffic_percentage,
'new_version': traffic_percentage
}
# 监控指标收集
monitoring.setup_comparison(baseline_service, new_service)
return routing_config
def auto_rollback(self, model_version, metrics_threshold):
"""自动回滚机制"""
while True:
current_metrics = monitoring.get_metrics(model_version)
if self.should_rollback(current_metrics, metrics_threshold):
logging.warning(f"模型版本 {model_version} 性能下降,触发自动回滚")
self.rollback_to_previous()
break
time.sleep(300) # 5分钟检查一次💫 五、云原生+AI+边缘的融合趋势
🌉 融合架构设计模式
智能云边端协同架构:
云端智能中心 模型管理 数据湖 协调调度 区域边缘集群 边缘节点 边缘节点 终端设备 终端设备
🏗️ 融合平台参考架构
云原生AI平台架构:
yaml
# 融合平台自定义资源定义
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: intelligentworkloads.platform.ai
spec:
group: platform.ai
versions:
- name: v1alpha1
served: true
storage: true
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
workloadType:
type: string
enum: [TRAINING, INFERENCE, FEDERATED_LEARNING]
resourceProfile:
type: string
enum: [CLOUD, EDGE, HYBRID]
modelRequirements:
type: object
properties:
framework:
type: string
accuracyTarget:
type: number
latencyRequirement:
type: integer
dataPolicy:
type: object
properties:
privacyLevel:
type: string
enum: [RAW, ANONYMIZED, FEDERATED]
storageLocation:
type: string
enum: [CLOUD, EDGE, HYBRID]
---
# 智能工作负载实例
apiVersion: platform.ai/v1alpha1
kind: IntelligentWorkload
metadata:
name: real-time-anomaly-detection
spec:
workloadType: INFERENCE
resourceProfile: HYBRID
modelRequirements:
framework: tensorflow
accuracyTarget: 0.95
latencyRequirement: 100 # 100ms
dataPolicy:
privacyLevel: FEDERATED
storageLocation: EDGE
deploymentStrategy:
cloudComponent:
replicas: 2
resources:
requests:
nvidia.com/gpu: 1
limits:
nvidia.com/gpu: 1
edgeComponent:
replicas: 10
resources:
requests:
cpu: 500m
memory: 1Gi
scalingPolicy:
minReplicas: 1
maxReplicas: 20
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70🔄 自适应调度策略
智能资源调度器:
java
// 智能调度策略引擎
@Component
public class IntelligentScheduler {
private final MachineLearningPredictor predictor;
private final ResourceOptimizer optimizer;
/**
* 多目标优化调度
*/
public SchedulingDecision schedule(WorkloadRequest request,
ClusterState clusterState) {
// 1. 预测资源需求
ResourcePrediction prediction = predictor.predictResourceUsage(
request.getWorkloadType(),
request.getHistoricalPattern()
);
// 2. 多目标优化(成本、性能、能耗)
OptimizationObjective objective = OptimizationObjective.builder()
.costWeight(0.4)
.performanceWeight(0.4)
.energyWeight(0.2)
.build();
// 3. 生成调度方案
List<SchedulingOption> options = generateSchedulingOptions(
request, clusterState, prediction);
SchedulingOption bestOption = optimizer.findOptimalSolution(options, objective);
return buildSchedulingDecision(bestOption);
}
/**
* 动态重调度
*/
@Scheduled(fixedRate = 60000) // 每分钟检查
public void dynamicReschedule() {
ClusterState currentState = clusterMonitor.getCurrentState();
List<WorkloadMetrics> metrics = metricsCollector.collectRecentMetrics();
metrics.forEach(metric -> {
if (needReschedule(metric, currentState)) {
RescheduleDecision decision = makeRescheduleDecision(metric);
executeReschedule(decision);
}
});
}
}
// 边缘感知调度器
@Service
public class EdgeAwareScheduler {
/**
* 基于网络状况的调度决策
*/
public EdgeSchedulingDecision scheduleToEdge(EdgeWorkload workload) {
// 评估边缘节点状态
List<EdgeNode> availableNodes = edgeRegistry.getAvailableNodes();
Map<EdgeNode, NodeScore> nodeScores = availableNodes.stream()
.collect(Collectors.toMap(
node -> node,
node -> calculateNodeScore(node, workload)
));
// 选择最优节点
EdgeNode bestNode = nodeScores.entrySet().stream()
.max(Map.Entry.comparingByValue())
.map(Map.Entry::getKey)
.orElseThrow(() -> new SchedulingException("无可用边缘节点"));
return EdgeSchedulingDecision.builder()
.targetNode(bestNode)
.estimatedLatency(calculateLatency(bestNode, workload))
.dataTransferCost(calculateTransferCost(bestNode, workload))
.build();
}
private NodeScore calculateNodeScore(EdgeNode node, EdgeWorkload workload) {
double networkScore = calculateNetworkScore(node.getNetworkStatus());
double computeScore = calculateComputeScore(node.getResourceAvailability());
double locationScore = calculateLocationScore(node, workload.getDataSources());
return new NodeScore(
networkScore * 0.4 + computeScore * 0.4 + locationScore * 0.2
);
}
}