《------往期经典推荐------》
二、机器学习实战专栏【链接】 ,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录
- 基本功能演示
- 研究背景
- 应用场景
- 主要工作内容
- 一、软件核心功能介绍与操作说明
- 二、YOLO11简介
- 三、模型训练、评估与推理
-
- [1. 数据集准备与训练](#1. 数据集准备与训练)
- [3. 训练结果评估](#3. 训练结果评估)
- [4. 模型推理](#4. 模型推理)
- 四、可视化系统制作
- 【获取方式】
基本功能演示
基于深度学习的CT扫描图像脑肿瘤智能检测与分析系统【python源码+Pyqt5界面+数据集+训练代码】
摘要:甲状腺结节是临床常见的内分泌疾病,其发病率在全球范围内持续上升。
虽然大多数结节为良性,但仍有部分存在恶性风险(如甲状腺癌),早期准确鉴别良恶性对制定合理的治疗策略至关重要。本文基于YOLOv8深度学习框架,通过3493张甲状腺结节超声图像,训练了一个进行甲状腺结节的目标分割模型,可以检测分割出甲状腺结节的具体位置,并判断是良性还是恶性。最终基于此模型开发了一款带UI界面的甲状腺结节智能检测分割与诊断系统,可用于实时检测场景中的甲状腺结节智能检测与诊断,更便于实际应用。该系统是基于python与PyQT5开发的,支持图片、批量图片、视频以及摄像头进行目标检测分割,并保存检测结果。本文提供了完整的Python代码和使用教程,给感兴趣的小伙伴参考学习,完整的代码资源文件获取方式见文末。
文章目录
- 基本功能演示
- 研究背景
- 应用场景
- 主要工作内容
- 一、软件核心功能介绍与操作说明
- 二、YOLO11简介
- 三、模型训练、评估与推理
-
- [1. 数据集准备与训练](#1. 数据集准备与训练)
- [3. 训练结果评估](#3. 训练结果评估)
- [4. 模型推理](#4. 模型推理)
- 四、可视化系统制作
- 【获取方式】
研究背景
甲状腺结节是临床常见的内分泌疾病,其发病率在全球范围内持续上升。虽然大多数结节为良性,但仍有部分存在恶性风险(如甲状腺癌),早期准确鉴别良恶性对制定合理的治疗策略至关重要。传统甲状腺超声诊断高度依赖医生的经验和主观判断,存在诊断一致性差、工作强度大、基层医疗水平参差不齐等问题。基于YOLO深度学习框架训练的甲状腺结节检测与分割模型,能够自动识别超声图像中的结节区域,并将其分类为"良性"或"恶性",结合图像分析技术实现结节位置标注与特征辅助分析。该智能系统显著提升了甲状腺结节筛查的效率与标准化水平,有助于实现早发现、早诊断、早治疗,对缓解医疗资源压力、提升基层诊疗能力具有重要意义。
应用场景
临床辅助诊断:在超声科或内分泌科,系统可实时分析超声影像,自动标注结节位置并提供良恶性初步判断,辅助医生提高诊断速度与准确性。
大规模人群筛查:适用于体检中心或社区医疗中对甲状腺疾病的快速筛查,高效识别高风险个体,实现精准分流。
基层医疗支持:在缺乏经验丰富的超声医师的基层医疗机构,该系统可作为智能助手,提升结节识别与判读能力,缩小城乡诊疗差距。
多模态诊疗集成:与电子病历系统或医院影像归档系统(PACS)集成,自动记录结节信息,为后续随访、手术或穿刺活检提供数据支持。
医生培训与教学:作为教学工具,帮助年轻医师学习甲状腺结节的超声影像特征,理解良恶性判别标准,提升专业技能。
主要工作内容
本文的主要内容包括以下几个方面:
搜集与整理数据集:搜集整理实际场景中超声图像中甲状腺结节的相关数据图片,并进行相应的数据标注与处理,为模型训练提供训练数据集;训练模型:基于整理的数据集,根据最前沿的YOLOv11目标分割技术训练目标检测模型,实现对需要检测的对象进行有效检测分割的功能;模型性能评估:对训练出的模型在验证集上进行了充分的结果评估和对比分析,主要目的是为了揭示模型在关键指标(如Precision、Recall、mAP50和mAP50-95等指标)上的表现情况。可视化系统制作:基于训练出的分割检测模型,搭配Pyqt5制作的UI界面,用python开发了一款界面简洁的软件系统,可支持图片、视频以及摄像头检测,同时可以将图片或者视频检测结果进行保存。其目的是为检测系统提供一个用户友好的操作平台,使用户能够便捷、高效地进行检测任务。
软件初始界面如下图所示:
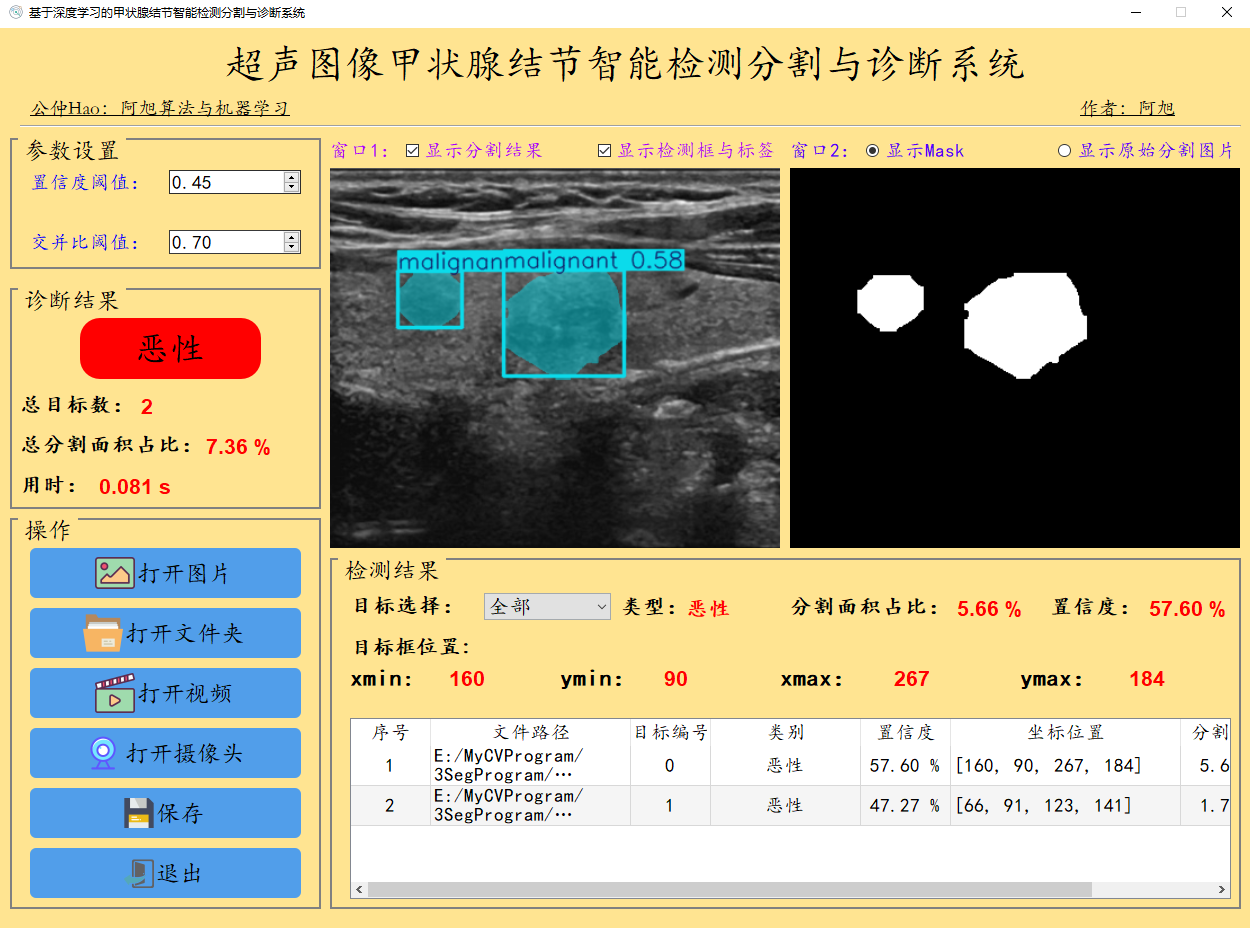
检测结果界面如下:
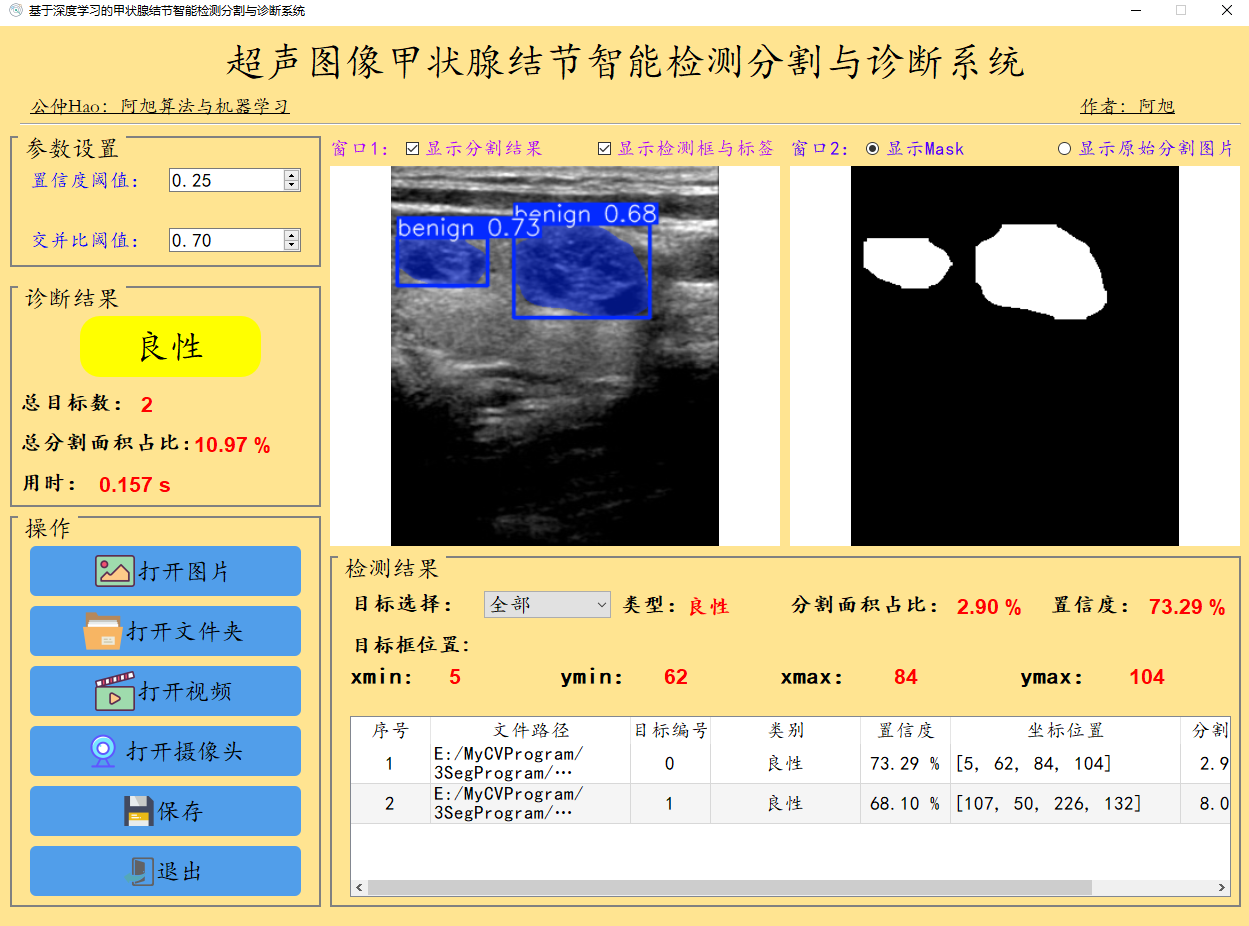
检测结果说明:
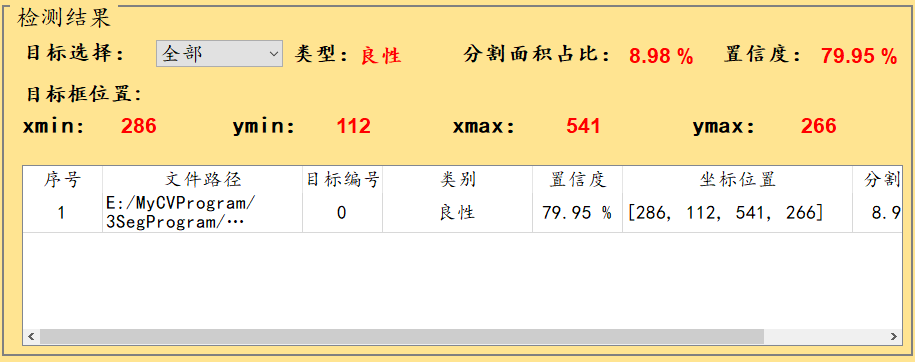
默认显示置信度最大的一个目标相关信息,下拉框可切换目标,显示对应目标检测信息;
表格中包含图像中所有目标的检测相关结果,包含:路径、类别、置信度、目标位置、目标分割占比。
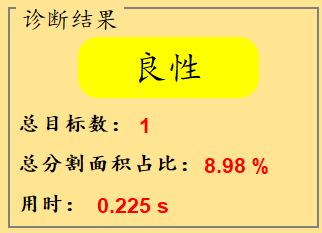
诊断结果区域:分别用'绿色'、'黄色'、'红色'背景代表'正常'、'良性'、'恶性'这3种类别的检测结果。
其中目标总数表示当前图片中检测出的目标总数;
总分割面积占比:表示图片中所有目标分割区域占图片总面积的百分比;
显示效果如下:


一、软件核心功能介绍与操作说明
软件主要功能
1. 可进行超声图像中甲状腺结节的检测与分割,并判断结节类型:['良性', '恶性'],在诊断结果区域显示['正常'、'良性', '恶性']这3种诊断结果;
2. 支持图片、图片批量、视频及摄像头进行检测分割;
3. 可显示总分割面积占比以及单个目标的分割面积占比;
4. 界面可实时显示目标位置、分割结果、分割面积占比、置信度、用时等信息;
5. 结果保存:支持图片、视频及摄像头的分割结果保存;
6. 支持将图片的检测结果保存到csv文件中。
界面参数设置说明

置信度阈值:也就是目标检测时的conf参数,只有检测出的目标置信度大于该值,结果才会显示;交并比阈值:也就是目标检测时的iou参数;窗口1:显示分割结果:表示是否在检测图片中显示分割结果,默认勾选;窗口1:显示检测框与标签:表示是否在检测图片中显示检测框与标签,默认勾选;窗口2:显示Mask或者显示原始分割图片:表示在窗口2中显示分割的Mask或者原始图片分割内容;
IoU:全称为Intersection over
Union,表示交并比。在目标检测中,它用于衡量模型生成的候选框与原标记框之间的重叠程度。IoU值越大,表示两个框之间的相似性越高。通常,当IoU值大于0.5时,认为可以检测到目标物体。这个指标常用于评估模型在特定数据集上的检测准确度。
(1)图片检测操作
1.点击打开图片按钮,选择需要检测的图片,或者点击打开文件夹按钮,选择需要批量检测图片所在的文件夹,操作演示如下:
2.点击目标下拉框后,可以选定指定目标的结果信息进行显示。
3. 点击保存按钮,会对图片检测结果进行保存,存储路径为:save_data目录下。
4.点击表格中的指定行,界面会显示该行表格所写的信息内容。
注:右侧目标位置默认显示置信度最大一个目标位置,可用下拉框进行信息切换。所有检测结果均在表格中显示。
点击保存按钮,会对图片的检测结果进行保存,共会保存3种类型结果,分别是:检测分割结果标识图片、分割的Mask图片以及原图分割后的图片。存储在save_data目录下,保存结果如下:

(2)视频检测操作
1.点击打开视频图标,打开选择需要检测的视频,就会自动显示检测结果。再次点击该按钮,会关闭视频。
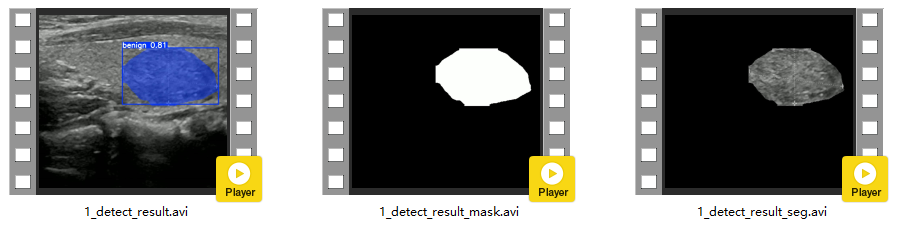
2.点击保存按钮,会对视频检测结果进行保存,同样会保存3种类型结果,分别是:检测分割结果标识视频、分割Mask视频以及原视频分割后的视频,存储路径为:save_data目录下。
视频检测保存结果如下:
(3)摄像头检测演示
1.点击打开摄像头按钮,可以打开摄像头,可以实时进行检测,再次点击该按钮,可关闭摄像头;
2.点击保存按钮,可以进行摄像头实时图像的检测结果保存。
(4)检测结果保存
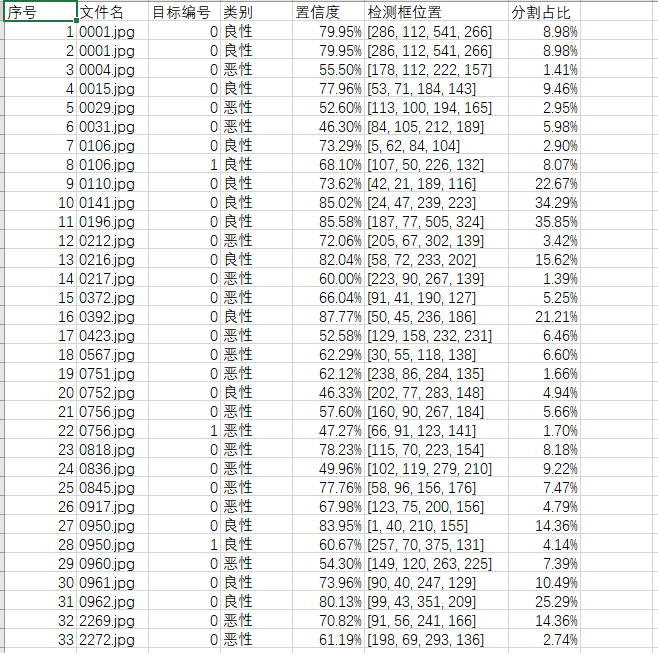
点击保存按钮后,会将当前选择的图片【含批量图片】、视频或者摄像头的分割结果进行保存。结果会存储在save_data目录下,保存内容如下:

图片文件保存的csv文件内容如下,包括图片路径、目标在图片中的编号、目标类别、置信度、目标坐标位置,分割面积占比。
注:其中坐标位置是代表检测框的左上角与右下角两个点的x、y坐标。
二、YOLO11简介
YOLO11源码地址:https://github.com/ultralytics/ultralytics
Ultralytics YOLO11是一款前沿的、最先进的模型,它在之前YOLO版本成功的基础上进行了构建,并引入了新功能和改进,以进一步提升性能和灵活性。YOLO11设计快速、准确且易于使用,使其成为各种物体检测和跟踪、实例分割、图像分类以及姿态估计任务的绝佳选择。

YOLO11的网络结构:

YOLO11创新点如下:
YOLO 11主要改进包括:
增强的特征提取:YOLO 11采用了改进的骨干和颈部架构,增强了特征提取功能,以实现更精确的目标检测。
优化的效率和速度:优化的架构设计和优化的训练管道提供更快的处理速度,同时保持准确性和性能之间的平衡。
更高的精度,更少的参数:YOLO11m在COCO数据集上实现了更高的平均精度(mAP),参数比YOLOv8m少22%,使其在不影响精度的情况下提高了计算效率。
跨环境的适应性:YOLO 11可以部署在各种环境中,包括边缘设备、云平台和支持NVIDIA GPU的系统。
广泛的支持任务:YOLO 11支持各种计算机视觉任务,如对象检测、实例分割、图像分类、姿态估计和面向对象检测(OBB)。
三、模型训练、评估与推理
本文主要基于YOLO11n模型进行模型训练,训练完成后对模型在验证集上的表现进行全面的性能评估及对比分析。总体流程包括:数据集准备、模型训练、模型评估。
1. 数据集准备与训练
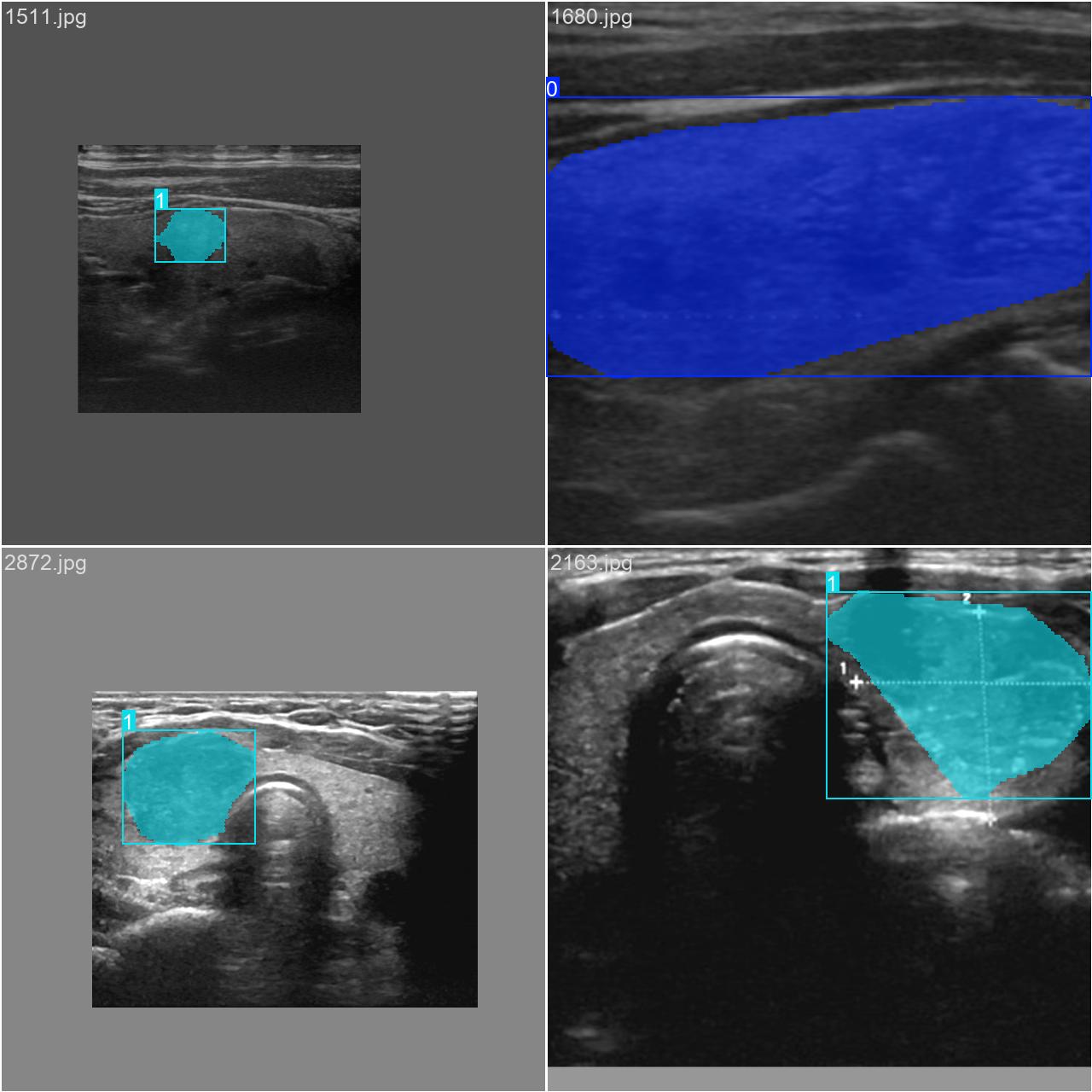
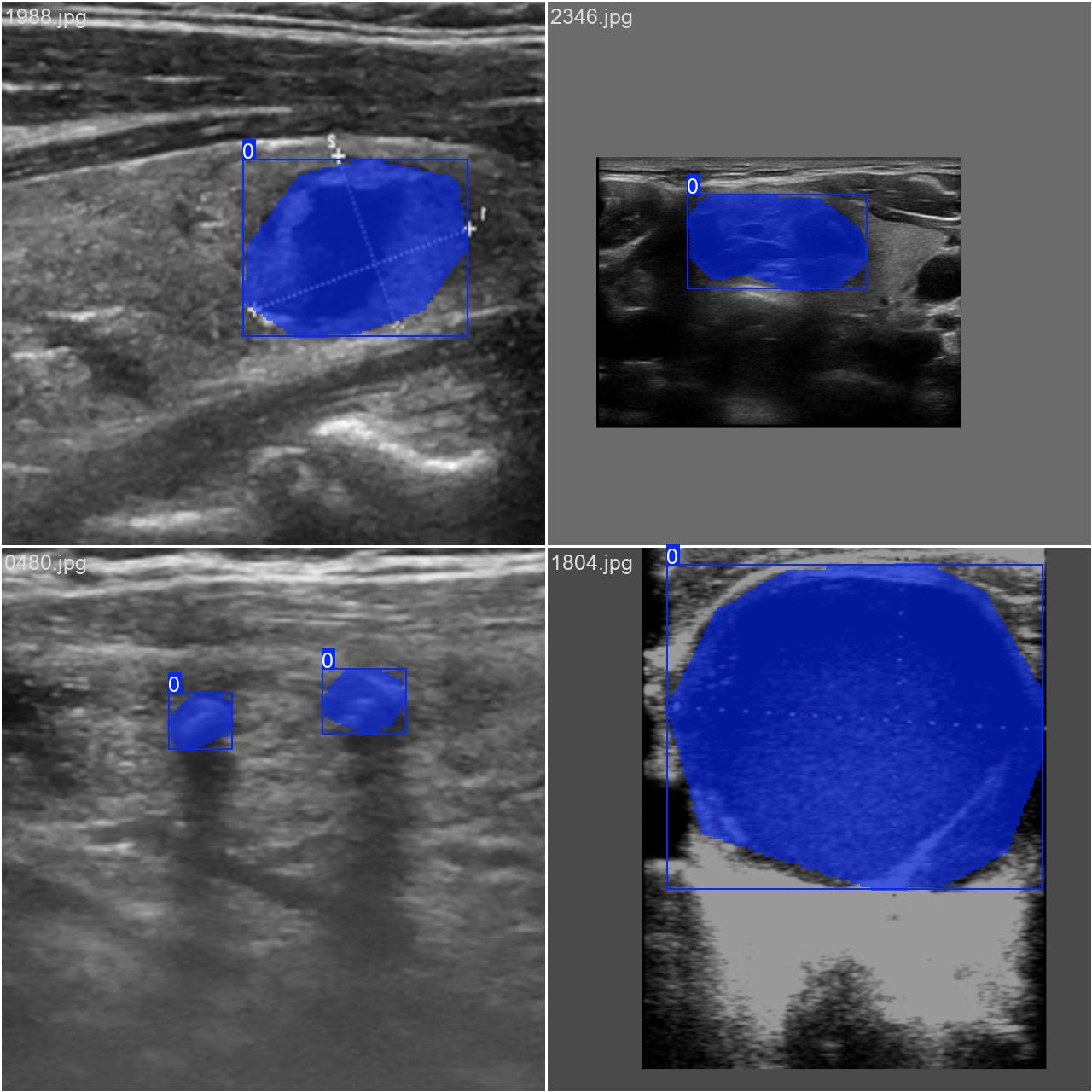
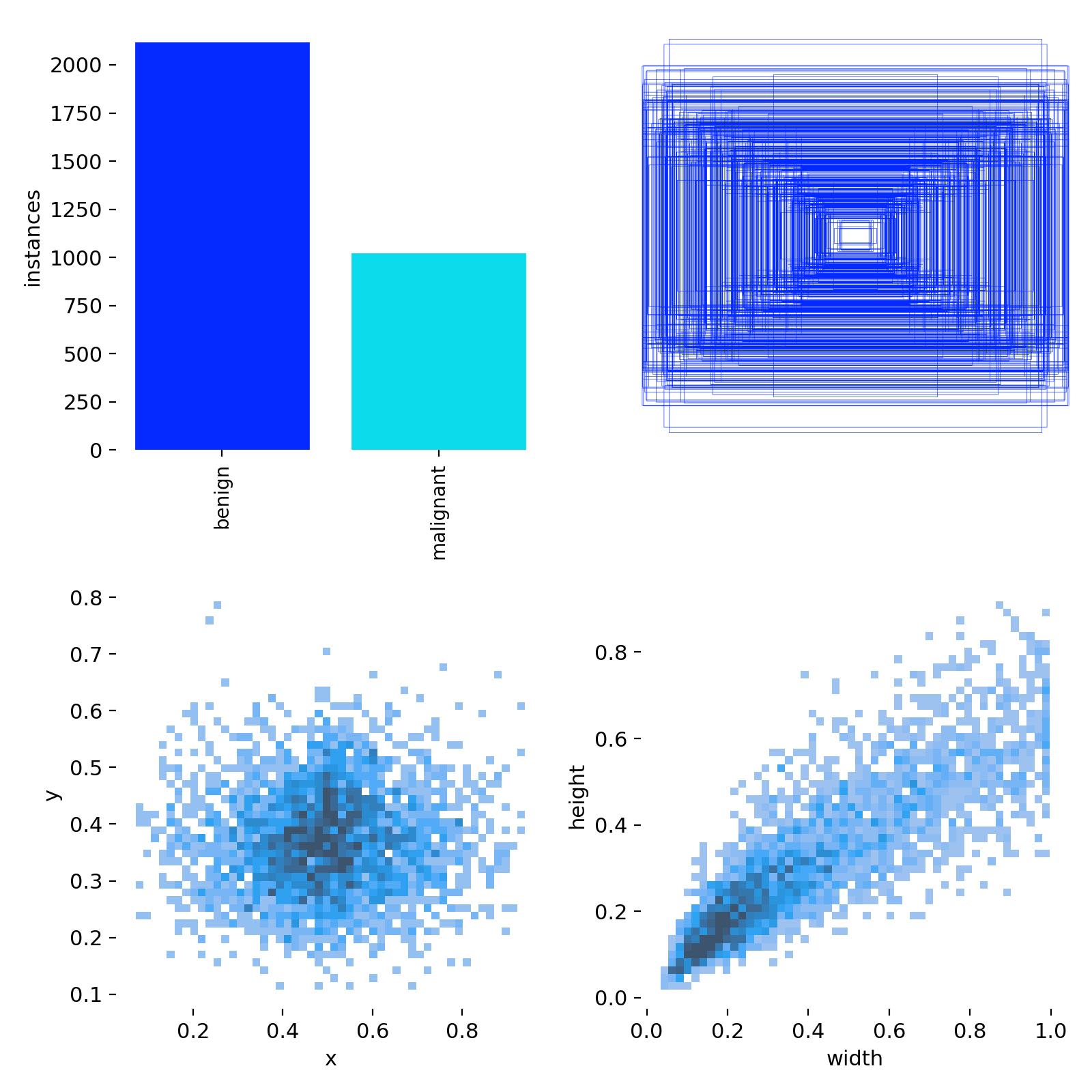
通过网络上搜集关于超声图像的甲状腺结节图片,并使用Labelme标注工具对每张图片中的分割结果及类别进行标注。一共包含3493张图片,其中训练集包含2879张图片,验证集包含614张图片,部分图像及标注如下图所示。

数据集的各类别具体分布如下所示:
图片数据的存放格式如下,在项目目录中新建datasets目录,同时将检测的图片分为训练集、验证集放入Data目录下。

同时我们需要新建一个data.yaml文件,用于存储训练数据的路径及模型需要进行检测的类别。YOLOv8在进行模型训练时,会读取该文件的信息,用于进行模型的训练与验证。data.yaml的具体内容如下:
python
train: E:\MyCVProgram\3SegProgram\ThyroidnodulesSeg_v11\datasets\Data\train
val: E:\MyCVProgram\3SegProgram\ThyroidnodulesSeg_v11\datasets\Data\val
nc: 2
names: ['benign', 'malignant']注:train与val后面表示需要训练图片的路径,建议直接写自己文件的绝对路径。
数据准备完成后,通过调用train.py文件进行模型训练,epochs参数用于调整训练的轮数,batch参数用于调整训练的批次大小【根据内存大小调整,最小为1】,代码如下:
python
#coding:utf-8
from ultralytics import YOLO
import matplotlib
matplotlib.use('TkAgg')
if __name__ == '__main__':
# 训练模型配置文件路径
yolo_yaml_path = 'ultralytics/cfg/models/11/yolo11-seg.yaml'
# 数据集配置文件路径
data_yaml_path = 'datasets\Data\data.yaml'
# 官方预训练模型路径
pre_model_path = "yolo11n-seg.pt"
# 加载配置文件和预训练模型
model = YOLO(yolo_yaml_path).load(pre_model_path)
# 模型训练
results = model.train(data=data_yaml_path,
epochs=80, # 训练轮数
batch=4, # batch大小
optimizer='SGD') # 优化器3. 训练结果评估
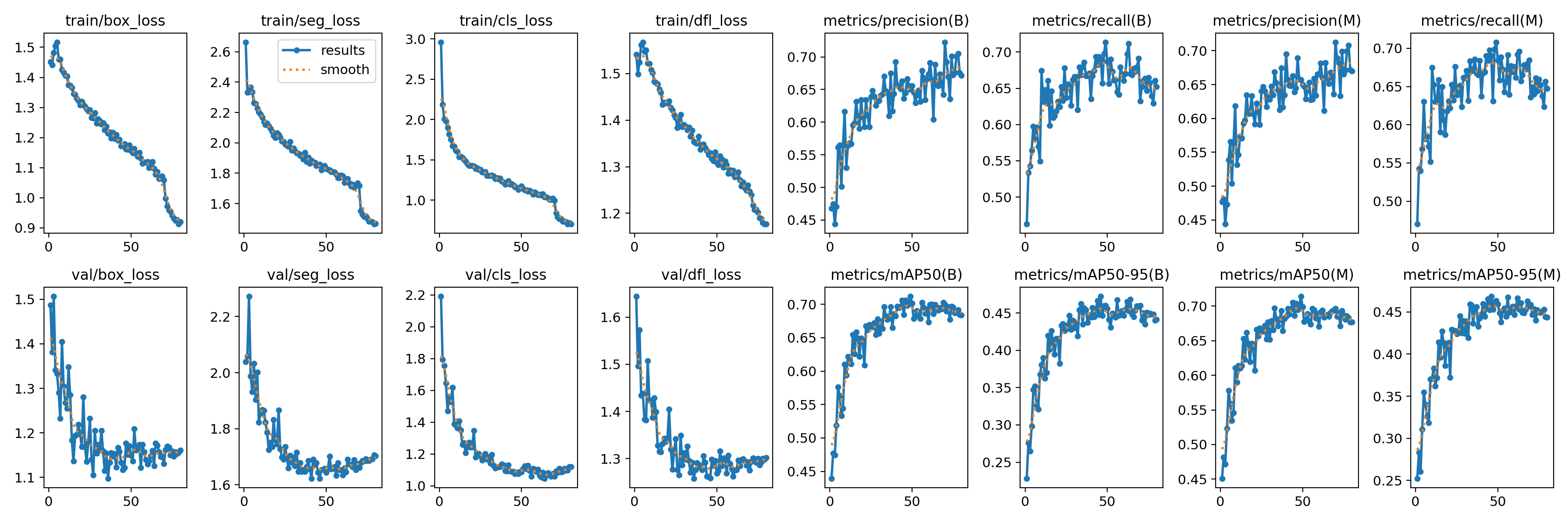
在深度学习中,我们通常用损失函数下降的曲线来观察模型训练的情况。YOLOv8在训练时主要包含三个方面的损失:定位损失(box_loss)、分类损失(cls_loss)、动态特征损失(dfl_loss)以及分割损失(seg_loss),在训练结束后,可以在runs/目录下找到训练过程及结果文件,如下所示:
各损失函数作用说明:
定位损失box_loss:预测框与标定框之间的误差(GIoU),越小定位得越准;
分类损失cls_loss:计算锚框与对应的标定分类是否正确,越小分类得越准;
动态特征损失(dfl_loss):DFLLoss是一种用于回归预测框与目标框之间距离的损失函数。在计算损失时,目标框需要缩放到特征图尺度,即除以相应的stride,并与预测的边界框计算Ciou Loss,同时与预测的anchors中心点到各边的距离计算回归DFLLoss。这个过程是YOLOv8训练流程中的一部分,通过计算DFLLoss可以更准确地调整预测框的位置,提高目标检测的准确性。
分割损失(seg_loss):预测的分割结果与标定分割之前的误差,越小分割的越准确;
本文训练结果如下:
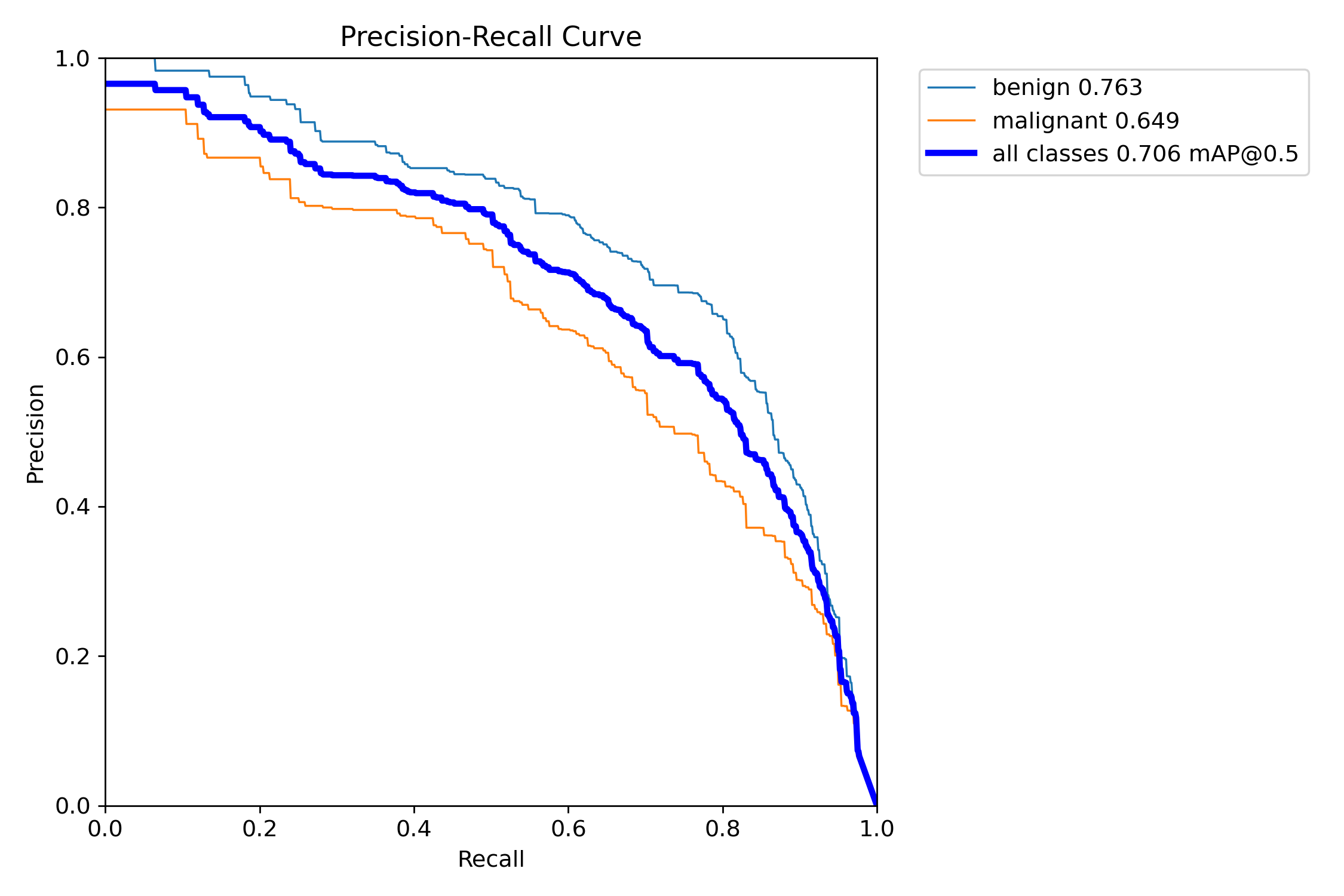
我们通常用PR曲线来体现精确率和召回率的关系,本文训练结果的PR曲线如下。mAP表示Precision和Recall作为两轴作图后围成的面积,m表示平均,@后面的数表示判定iou为正负样本的阈值。mAP@.5:表示阈值大于0.5的平均mAP。
定位结果的PR曲线如下:
分割结果的PR曲线如下:
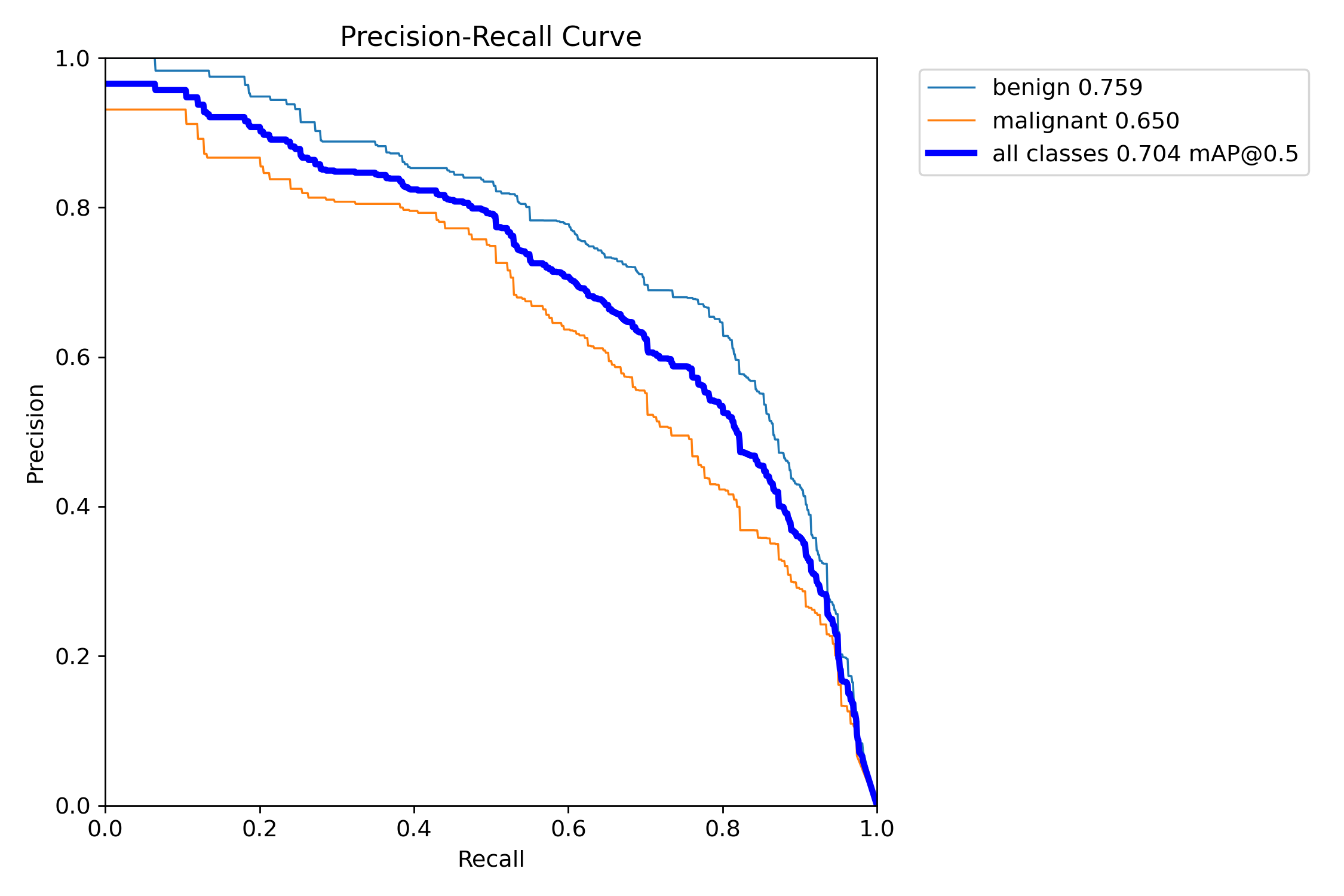
从上面图片曲线结果可以看到:定位的平均精度为0.706,分割的平均精度为0.704,结果还是不错的。
模型在验证集上的性能评估结果如下:

4. 模型推理
模型训练完成后,我们可以得到一个最佳的训练结果模型best.pt文件,在runs/trian/weights目录下。我们可以使用该文件进行后续的推理检测。
图片检测代码如下:
python
# 所需加载的模型目录
path = 'models/best.pt'
# 需要检测的图片地址
img_path = "TestFiles/0001.jpg"
# 加载预训练模型
# conf 0.25 object confidence threshold for detection
# iou 0.7 intersection over union (IoU) threshold for NMS
model = YOLO(path, task='segment')
# 检测图片
results = model(img_path)
print(results)
res = results[0].plot()
# res = cv2.resize(res,dsize=None,fx=0.5,fy=0.5,interpolation=cv2.INTER_LINEAR)
cv2.imshow("YOLOv8 Detection", res)
cv2.waitKey(0)执行上述代码后,会将执行的结果直接标注在图片上,结果如下:
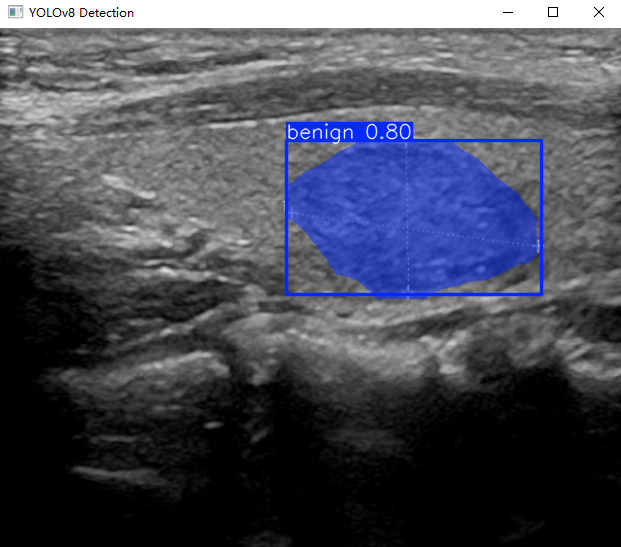
四、可视化系统制作
基于上述训练出的目标检测模型,为了给此检测系统提供一个用户友好的操作平台,使用户能够便捷、高效地进行检测任务。博主基于Pyqt5开发了一个可视化的系统界面,通过图形用户界面(GUI),用户可以轻松地在图片、视频和摄像头实时检测之间切换,无需掌握复杂的编程技能即可操作系统。【系统详细展示见第一部分内容】
Pyqt5详细介绍
关于Pyqt5的详细介绍可以参考之前的博客文章:《Python中的Pyqt5详细介绍:基本机构、部件、布局管理、信号与槽、跨平台》,地址:
系统制作
博主基于Pyqt5框架开发了此款甲状腺结节智能检测与分析系统,即文中第一部分的演示内容 ,能够很好的支持图片、视频及摄像头进行检测,同时支持检测结果的保存。
通过图形用户界面(GUI),用户可以轻松地在图片、视频和摄像头实时检测之间切换,无需掌握复杂的编程技能即可操作系统。这不仅提升了系统的可用性和用户体验,还使得检测过程更加直观透明,便于结果的实时观察和分析。此外,GUI还可以集成其他功能,如检测结果的保存与导出、检测参数的调整,从而为用户提供一个全面、综合的检测工作环境,促进智能检测技术的广泛应用。
关于该系统涉及到的完整源码、UI界面代码、数据集、训练代码、训练好的模型、测试图片视频等相关文件,均已打包上传,感兴趣的小伙伴可以通过下载链接自行获取。
【获取方式】
本文涉及到的完整全部程序文件:包括环境配置文档说明、python源码、数据集、训练代码、UI文件、测试图片视频 等(见下图),获取方式见文末:

注意:该代码基于Python3.9开发,运行界面的主程序为
MainProgram.py,其他测试脚本说明见上图。为确保程序顺利运行,请按照程序运行说明文档txt配置软件运行所需环境。