在 Django 框架的**MVT(模型 - 视图 - 模板)**架构中,视图(View)和 URL 路由是连接用户请求与业务逻辑的核心环节。视图负责处理 HTTP 请求、与模型交互获取数据并返回响应,而 URL 路由则像 "导航地图",将用户的请求精准映射到对应的视图函数。本文将从基础概念出发,详细讲解 Django 视图的核心职责与 URL 路由的配置方法,帮助你搭建起 Web 应用的 "请求处理通道"。
一、Django 视图基础:连接请求与响应的核心
1.1 什么是视图?
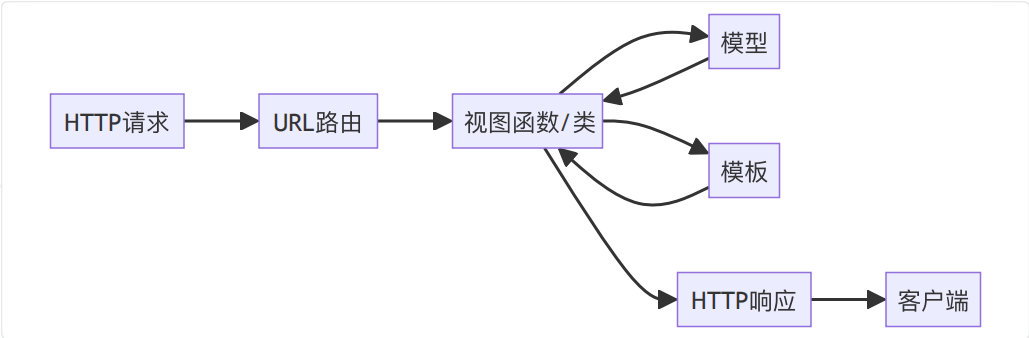
视图是 Django 中处理 Web 请求并返回响应的函数或类,它相当于 MVT 架构中的 "桥梁"------ 一边接收用户的 HTTP 请求,一边与模型(Model)交互获取数据,再将数据传递给模板(Template)渲染,最终返回 HTML 页面或 JSON 等响应结果。
在实际开发中,视图函数通常定义在应用目录下的views.py文件中,其核心特征是:
- 第一个参数必须是
request:代表 HTTP 请求对象,包含请求方法、参数、头信息等所有请求相关数据。 - 必须返回
HttpResponse或其子类实例:如JsonResponse、FileResponse等,用于向客户端返回响应内容。
1.2 视图的核心职责
Django 视图的工作流程可概括为四步,每一步都对应 Web 开发的关键环节:
- 接收 HTTP 请求:获取客户端发送的请求数据(如请求方法、参数、头部信息等);
- 与模型交互:通过 Django ORM 从数据库中查询或修改数据(如获取文章列表、更新用户信息);
- 传递数据到模板:将查询到的数据注入模板文件,准备页面渲染;
- 返回 HTTP 响应:将渲染后的 HTML 页面或 JSON 数据等返回给客户端。
举个最简单的视图例子:返回一句 "Hello, Django!" 的响应,代码如下:
python
# myapp/views.py
from django.http import HttpResponse
def hello(request):
# 接收请求,直接返回文本响应
return HttpResponse('Hello, Django!')1.3 视图与模型、模板的交互逻辑
视图并非孤立存在,而是与模型、模板紧密协作,形成完整的业务闭环:
-
视图 ↔ 模型 :视图通过 Django ORM 调用模型的方法(如
get()、filter())获取数据,无需直接操作数据库。例如,从Article模型中获取指定 ID 的文章:pythonfrom django.shortcuts import get_object_or_404 from .models import Article def article_detail(request, pk): # 若文章不存在,自动返回404错误 article = get_object_or_404(Article, pk=pk) # 将数据传递给模板 return render(request, 'article_detail.html', {'article': article}) -
视图 ↔ 模板 :通过
render()函数(后续会详细讲解)将上下文数据传递给模板,模板使用 Django 模板语法(如{``{ article.title }})渲染动态内容,最终生成 HTML 页面返回给用户。
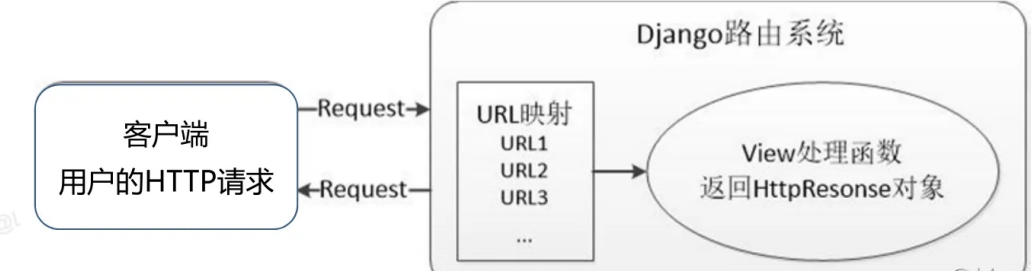
二、URL 路由配置:给请求 "指路"
当用户在浏览器中输入 URL(如http://127.0.0.1:8000/article/1/)时,Django 如何知道该调用哪个视图函数?答案就是URL 路由配置 ------ 通过urls.py文件中的urlpatterns列表,建立 URL 路径与视图函数的映射关系。
2.1 URL 路由基础:配置文件与核心语法
Django 的 URL 路由配置主要集中在两个层面:
- 项目级 URL 配置 :位于项目根目录的
urls.py,负责全局路由管理,通常通过include()函数引入应用级的 URL 配置。 - 应用级 URL 配置 :位于每个应用目录下的
urls.py,负责该应用内的路由映射,让代码结构更清晰(尤其适合大型项目)。
核心配置语法
URL 路由的核心是path()函数(或re_path(),用于正则表达式),其语法格式为:
python
path(route, view, kwargs=None, name=None)route:URL 路径规则,如'article/<int:pk>/',用于匹配用户请求的路径。view:对应的视图函数或类视图,如views.article_detail。kwargs:传递给视图的额外关键字参数(可选)。name:给 URL 命名(可选),用于反向解析 URL(后续重点讲解)。
示例:基础 URL 配置
以 "博客应用" 为例,项目级与应用级 URL 配置如下:
-
项目级
urls.py(根目录):引入博客应用的 URL 配置python# project/urls.py from django.contrib import admin from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), # Django自带的admin后台路由 path('blog/', include('blog.urls')), # 将/blog/路径映射到blog应用的urls ] -
应用级
urls.py(blog 目录):配置博客相关路由python# blog/urls.py from django.urls import path from . import views urlpatterns = [ path('', views.blog_home, name='blog_home'), # 博客首页:/blog/ path('article/<int:pk>/', views.article_detail, name='article_detail'), # 文章详情:/blog/article/1/ path('category/<slug:slug>/', views.category_articles, name='category_articles'), # 分类文章:/blog/category/tech/ ]
2.2 Django 处理请求的完整流程
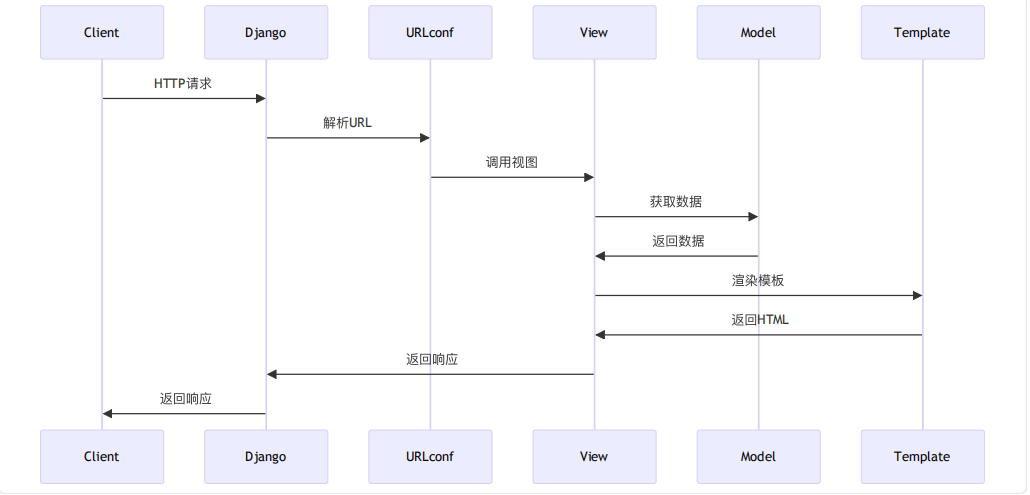
当用户发送 HTTP 请求(如访问http://127.0.0.1:8000/blog/article/1/)时,Django 的处理流程可分为 5 步,清晰展现了 URL 路由与视图的协作逻辑:
- 接收 HTTP 请求:Django 服务器监听端口(默认 8000),接收用户的请求(包含 URL、请求方法、参数等)。
- 解析 URL :提取 URL 中的路径部分(如
/blog/article/1/),忽略域名(如http://127.0.0.1:8000)、查询参数(如?page=2)和锚点(如#comments)。 - 匹配 URL 模式 :从项目级
urlpatterns开始匹配,/blog/触发include('blog.urls'),进而在 blog 应用的urlpatterns中匹配article/<int:pk>/。 - 调用视图函数 :匹配成功后,调用对应的
views.article_detail视图,并将路径中的参数(如pk=1)传递给视图。 - 返回响应 :视图处理请求(如查询文章数据、渲染模板),生成
HttpResponse对象,返回给客户端,最终在浏览器中显示页面。
2.3 高级 URL 配置技巧
基础配置满足简单场景,而 Django 提供的高级功能可应对复杂 URL 需求,如动态参数、正则表达式、反向解析等。
技巧 1:路径转换器 ------ 获取 URL 中的动态参数
当需要从 URL 中提取动态数据(如文章 ID、分类别名)时,Django 提供了路径转换器,无需手动解析字符串,直接将参数传递给视图。
Django 内置的 5 种路径转换器如下表所示:
| 转换器 | 描述 | 示例 | 匹配 URL 示例 |
|---|---|---|---|
str |
匹配除斜杠(/)外的任意字符(默认) | path('article/<str:slug>/', ...) |
/article/django-url-guide/ |
int |
匹配非负整数(用于 ID、页码等) | path('article/<int:pk>/', ...) |
/article/123/ |
slug |
匹配 slug 字符串(字母、数字、下划线、连字符,URL 友好) | path('category/<slug:slug>/', ...) |
/category/tech-news/ |
uuid |
匹配 UUID 格式字符串(用于唯一标识,如文件 ID) | path('file/<uuid:id>/', ...) |
/file/550e8400-e29b-41d4-a716-446655440000/ |
path |
匹配包含斜杠的完整路径(用于文件路径等) | path('file/<path:path>/', ...) |
/file/docs/django.pdf/ |
示例 :通过int:pk获取文章 ID,在视图中查询对应文章:
python
# blog/views.py
def article_detail(request, pk):
# pk是从URL中提取的整数参数(文章ID)
article = get_object_or_404(Article, pk=pk) # 不存在则返回404
return render(request, 'article_detail.html', {'article': article})技巧 2:正则表达式 ------ 复杂 URL 模式匹配
当路径规则需要更灵活的匹配(如按年月筛选文章归档)时,可使用re_path()函数,通过正则表达式定义 URL 模式。
示例:匹配 "/blog/article/2025/08/" 格式的 URL,筛选 2025 年 8 月的文章:
python
# blog/urls.py
from django.urls import re_path
urlpatterns = [
# 正则表达式匹配:年(4位数字)+ 月(2位数字)
re_path(r'^article/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/$',
views.article_archive,
name='article_archive'),
]-
(?P<year>[0-9]{4}):命名分组,将匹配的 4 位数字作为year参数传递给视图。 -
视图中接收参数并筛选数据:
python# blog/views.py def article_archive(request, year, month): # 筛选指定年月的文章(created_at是文章的创建时间字段) articles = Article.objects.filter(created_at__year=year, created_at__month=month) return render(request, 'article_archive.html', {'articles': articles, 'year': year, 'month': month})
技巧 3:反向解析 ------ 避免硬编码 URL
在开发中,若直接在模板或视图中写死 URL(如/blog/article/1/),后续修改 URL 规则时需全局替换,效率极低。Django 的反向解析 功能通过 URL 的name属性动态生成 URL,彻底解决硬编码问题。
反向解析的核心工具是:
- 视图中:
reverse()函数。 - 模板中:
{% url %}模板标签。
示例 1:视图中使用reverse(
python
# blog/views.py
from django.urls import reverse
from django.shortcuts import redirect
def redirect_to_article(request):
# 动态生成name为'article_detail'的URL,参数pk=1
article_url = reverse('article_detail', args=[1]) # 生成结果:/blog/article/1/
return redirect(article_url) # 重定向到该URL示例 2:模板中使用{% url %}
html
<!-- templates/article_list.html -->
<!-- 遍历文章列表,动态生成每个文章的详情页链接 -->
<ul>
{% for article in articles %}
<li>
<a href="{% url 'article_detail' article.pk %}">{{ article.title }}</a>
</li>
{% endfor %}
</ul>技巧 4:命名空间 ------ 解决多应用 URL 重名问题
当项目包含多个应用时,若不同应用的 URL 使用相同的name(如两个应用都有name='index'的 URL),反向解析会无法区分。Django 的命名空间(namespace) 功能可给每个应用的 URL 添加 "前缀",避免冲突。
命名空间的配置步骤如下:
-
项目级
urls.py中添加namespace:python# project/urls.py urlpatterns = [ path('blog/', include(('blog.urls', 'blog'), namespace='blog')), # 命名空间为'blog' path('shop/', include(('shop.urls', 'shop'), namespace='shop')), # 命名空间为'shop' ] -
应用级
urls.py中定义app_name(Django 2.0 + 要求):python# blog/urls.py app_name = 'blog' # 应用级命名空间 urlpatterns = [ path('', views.blog_home, name='index'), # 命名为'blog:index' ] -
反向解析时指定命名空间 :
- 视图中:
reverse('blog:index') - 模板中:
{% url 'blog:index' %}
- 视图中:
三、小结
本文从视图的核心职责出发,详细讲解了 Django URL 路由的基础配置、请求处理流程及高级技巧(路径转换器、正则表达式、反向解析、命名空间)。这些知识点是 Django Web 开发的 "地基"------ 视图负责 "处理业务",URL 路由负责 "精准导航",二者结合才能构建起稳定、灵活的请求处理系统。
在下一篇博客中,我们将深入讲解视图的进阶用法,包括错误视图、异步视图、快捷函数(如render()、redirect())和视图装饰器,帮助你进一步提升视图开发效率。