开源16小时就登顶HuggingFace Trending全球第一!
前不久,小编刚刚介绍了PaddleOCR开源最强OCR生态,不靠参数靠实力,56K+ Star见证实力(附开源地址),然而就在17日,百度又放出大招,最新开源的PaddleOCR-VL,以仅0.9B的参数量,在权威评测OmniDocBench V1.5中拿下92.56分,登顶全球第一。
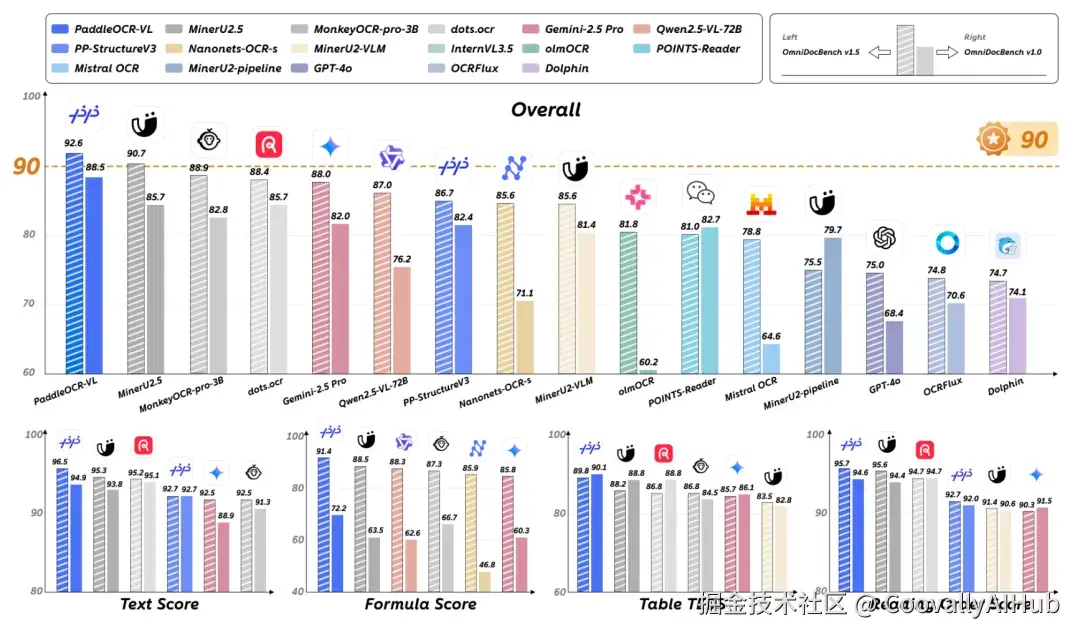
更惊人的是,它在文本、公式、表格、阅读顺序四大核心任务中全部刷新SOTA,成为当前唯一实现"四项全能"的OCR模型。
登顶全球榜单,四项能力全面领先
OmniDocBench V1.5由清华、阿里达摩院、上海AI实验室等联合推动,是当前最具挑战性的文档解析评测集,包含1355页PDF,涵盖9种文档类型和4种布局。
PaddleOCR-VL的92.56分综合成绩,超越了GPT-4o、Gemini-2.5 Pro等参数量数十倍甚至数百倍的大模型,同时也击败了dots.ocr、MinerU等OCR领域的垂直模型。
更让人印象深刻的是它的四项核心能力全面领先:
- 文本识别
编辑距离仅0.035,支持109种语言,包括手写、竖排、艺术字等复杂场景。在包含17,148个文本块的专项测试集上全面领先。

不仅如此,就算因为一些变形或者光线不好的场景,PaddleOCR-VL也能轻松面对。
- 公式识别
CDM得分0.9453,LaTeX输出准确,在1,050个公式测试集上超越所有对比模型。在OmniDocBench V1.5的公式子任务中获得91.43分的最高分。

- 表格理解
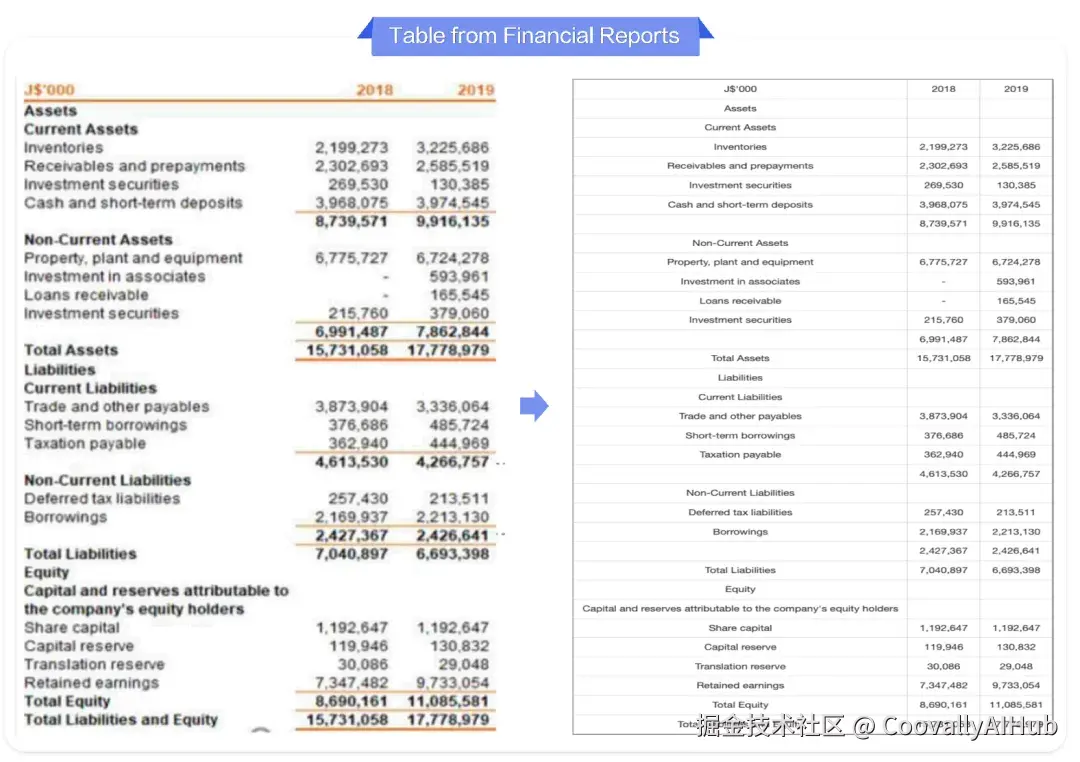
TEDS得分89.76,在512个表格测试集上取得0.9195的TEDS分数,能解析财报、统计报表中的合并单元格、嵌套表格等复杂结构。
- 阅读顺序
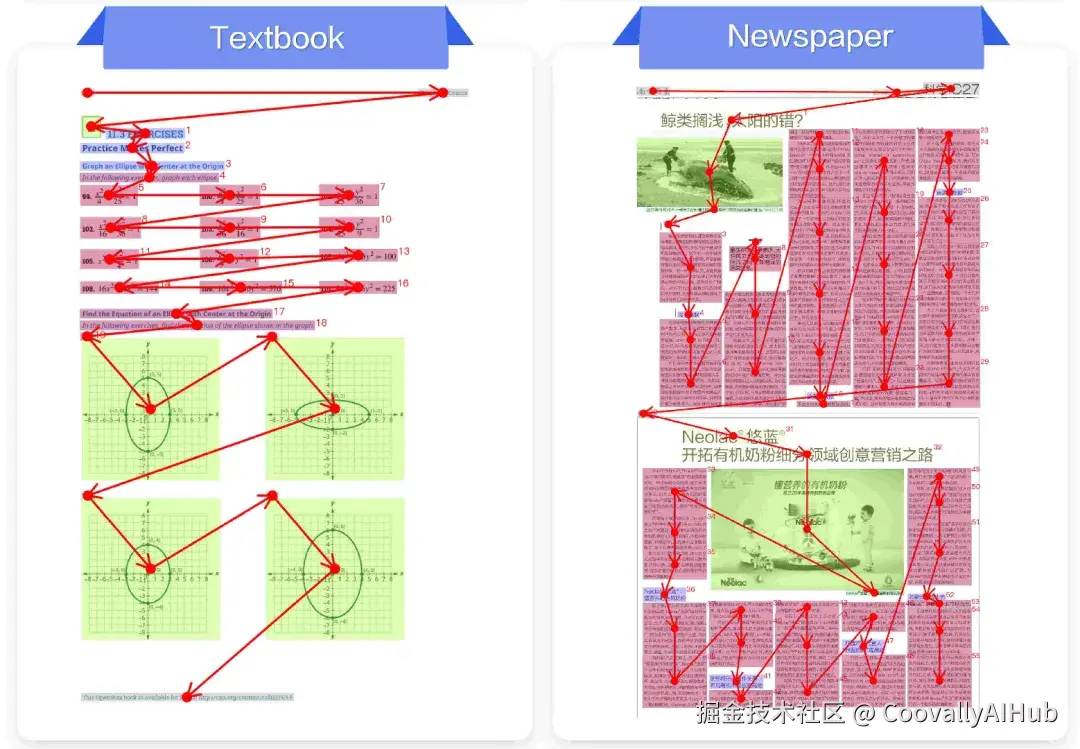
编辑距离0.043,是该榜单所有模型中的最优表现,能像人一样理解多栏、图文混排的阅读逻辑。
小模型大能量:架构创新打破传统局限
传统OCR系统采用逐行识别策略,面对多栏、嵌套、错行等复杂版面时往往力不从心。PaddleOCR-VL之所以能"像人一样理解结构",源于其创新的两阶段架构设计。
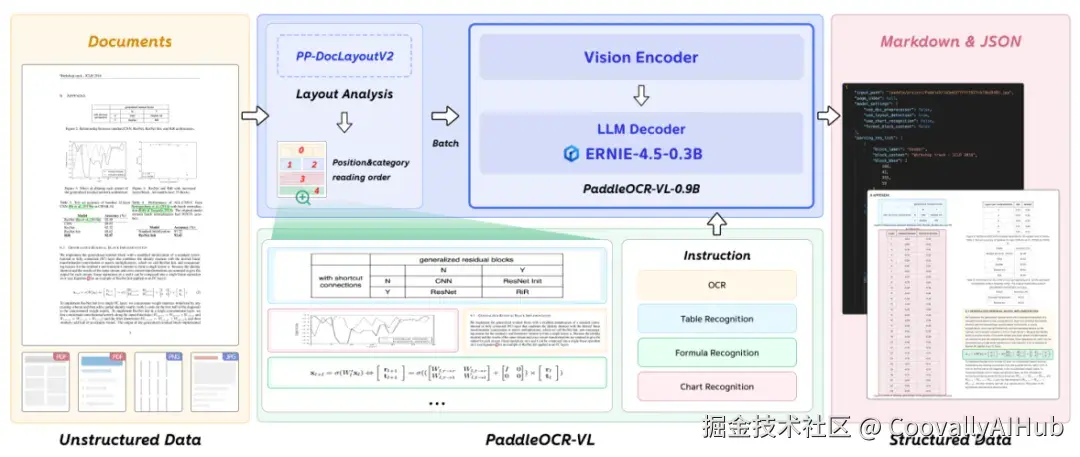
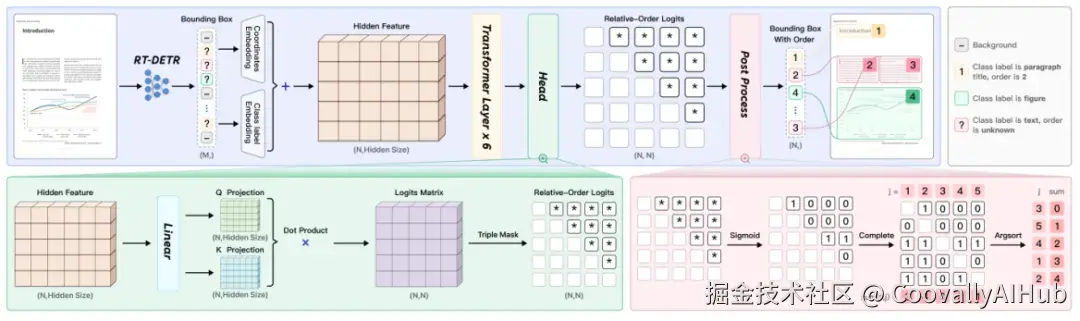
第一阶段由PP-DocLayoutV2模型负责文档版面分析,基于RT-DETR检测器与指针网络预测阅读顺序。这个轻量级视觉模型专门优化了复杂版面的处理能力。
第二阶段由PaddleOCR-VL-0.9B进行细粒度识别,该模型采用LLaVA架构风格,融合NaViT动态分辨率视觉编码器与ERNIE-4.5-0.3B语言模型,在效率与精度上取得了双重突破。
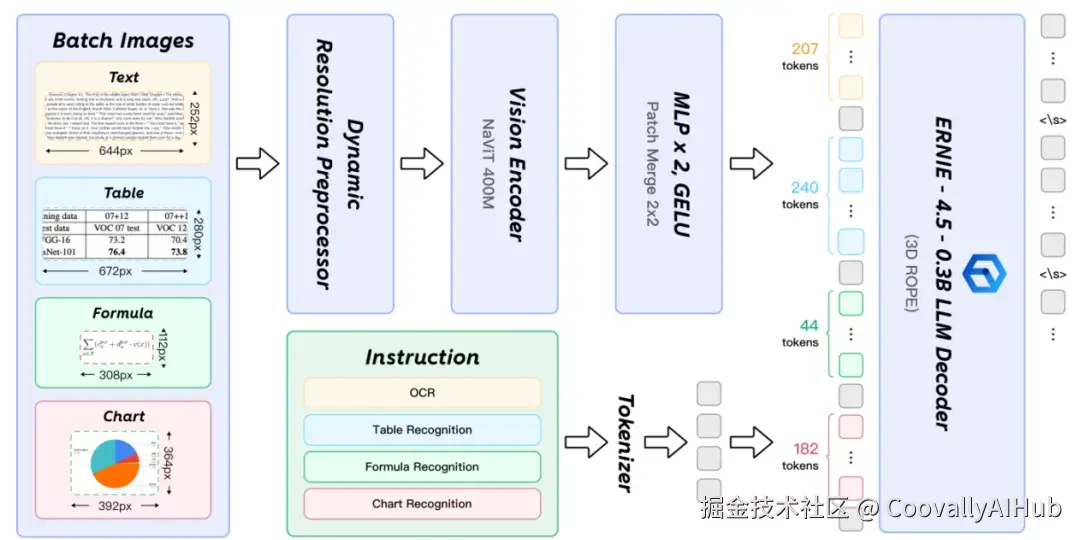
训练策略上,模型采用两阶段训练方法:首先在2900万图像-文本对上进行预训练对齐,然后在270万高质量样本上进行指令微调。训练数据涵盖文本、表格、公式、图表等多模态信息,结合自动标注与难例挖掘机制。
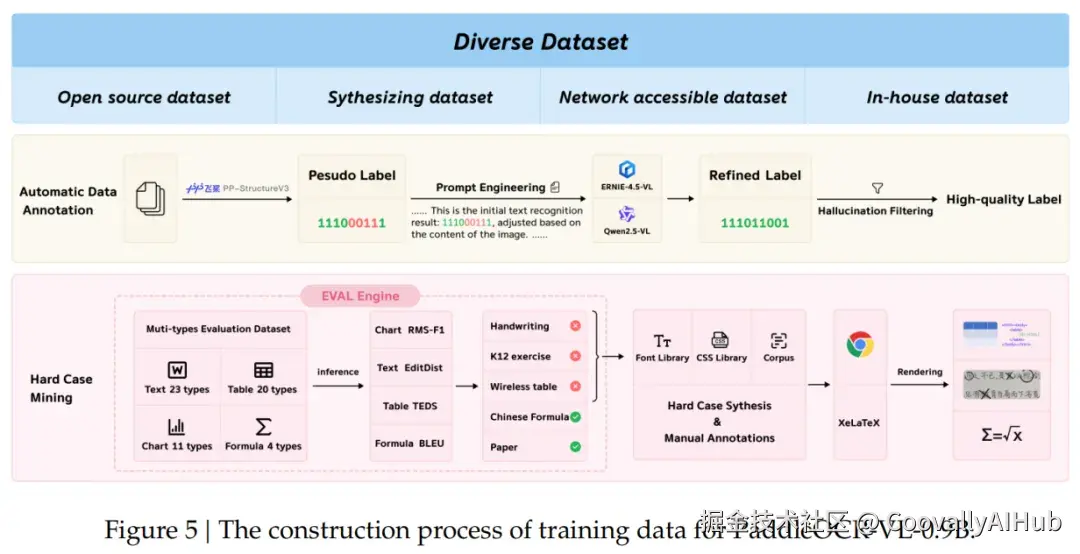
这种模块解耦的设计让模型在面对复杂版面任务时表现更稳定、更高效,在单张A100上推理速度达1881 token/s,同时保持较低的内存占用。
真实场景实测:多项评测验证强大性能
除了在OmniDocBench上的出色表现,PaddleOCR-VL在多个专项评测中都展示了强大的实用价值:
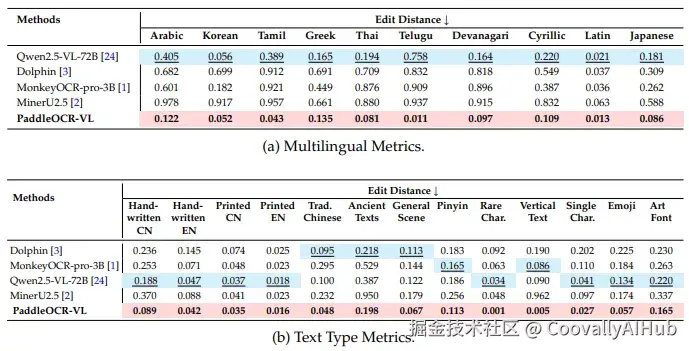
- 多语言文本识别: 在10.7万样本的内部测试集上,对阿拉伯文、韩文、泰文、希腊文等不同文字体系都保持了低编辑距离和高识别精度。
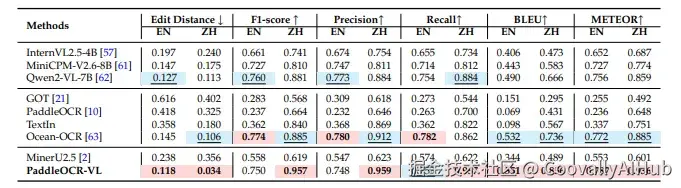
- 手写文字识别: 在Ocean-OCR手写评测集上,中英文手写识别均取得最佳成绩,中文编辑距离仅0.034,英文0.118。
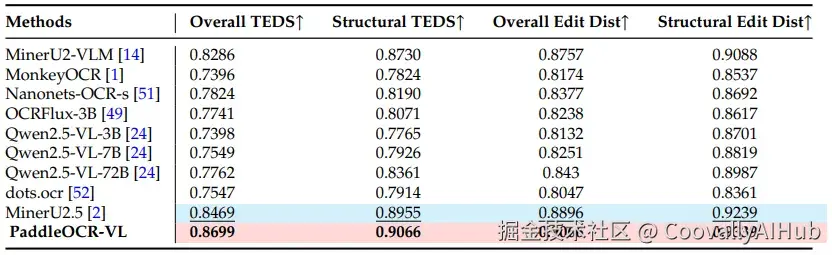
- 复杂表格解析: 在包含20种表格类型的内部测试集上,TEDS得分达0.8699,显著领先对比模型。能够准确处理带公式、合并单元格、水印等复杂表格。
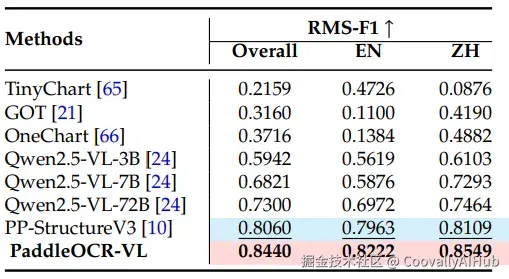
- 图表理解能力: 在1801个图表的内部测试集上,RMS-F1得分达0.8440,超越了一系列专用图表理解模型。
论文附录中展示了大量真实场景案例,从学术论文、研究报告到报纸杂志,PaddleOCR-VL都能准确解析其中的文本、表格、公式和图表,并输出结构化的Markdown格式。
OCR进入认知时代:从"识字"到"理解"
PaddleOCR-VL的突破,标志着OCR技术从传统的"识字"阶段,进入了真正的"理解"阶段。
在产业智能化浪潮中,OCR已成为各行业不可或缺的数字化基础设施。金融合同审核、学术文献处理、政务档案数字化、历史古籍保护等场景,都需要能够理解文档结构的智能工具。
PaddleOCR-VL的独特价值在于:
- 作为RAG系统的最佳搭档,它能提供高质量的结构化输入,显著提升知识检索与生成的可靠性;
- 在文档密集型行业中,它可以作为"智能文档助手"接入业务流程,实现自动化处理;
- 它的轻量化设计使其可以在消费级GPU上运行,在RTX 4090D上也能达到每秒1.03页的处理速度,大大降低了部署门槛。
百度通过PaddleOCR-VL证明:在垂直任务中,架构合理、任务聚焦的"小模型"同样可以超越参数量巨大的通用大模型,实现精度、速度、功耗的三赢。
PaddleOCR-VL不仅是OCR技术的突破,更是AI理解现实世界文档的关键一步。它把"读懂文档"的钥匙,从参数堆砌的大模型手中,交还给了真正理解场景的轻量化设计。
正如一位开发者在社交平台上所说:"这可能是目前最适合落地的文档解析模型------既强,又轻,还开源。"
随着PaddleOCR-VL的开源发布,我们有理由相信,AI理解复杂文档的能力将迅速普及到各行各业,推动整个社会向智能化时代迈进。
论文及项目地址
ruby
GitHub项目:https://github.com/PaddlePaddle/PaddleOCR
技术报告:https://arxiv.org/abs/2510.14528
在线Demo:https://aistudio.baidu.com/application/detail/98365