前言
使用 python 第三方库 requests 进行网页爬取时,如何正确地获取网页编码是十分重要的。
原因是:不同的网页可能有不同的编码格式,如果没有正确获取编码,可能会对后续内容提取造成一定的麻烦。
典型例子如:爬虫代码得到的编码与网页实际编码不一致,导致中文乱码问题。
常见网页编码有:utf-8、gbk、gb2312、iso-8859-1等。
常见三种网页编码获取方法分别为:手动浏览器查看、requests 自带编码获取方法、使用chardet 第三方编码识别模块。
当然,这三种方法都是建立在网页请求成功状态之下的,如果网页本身存在反爬机制,数据是通过渲染加载的,需要通过抓包等方式获取,那么大多数情况也就不存在查看网页编码一说了。
以下将根据示例,详细展示这三种方法的具体使用、优缺点对比等。
一、手动浏览器查看---多用以辅助验证
编写爬虫代码前,查看网页编码最直接了当的方法,就是手动通过浏览器去查看,具体有以下两种方式:
一是:目标网页【右键】-选择【检查】-在 html 中找到【charset】值,该值就是目标网页的编码。
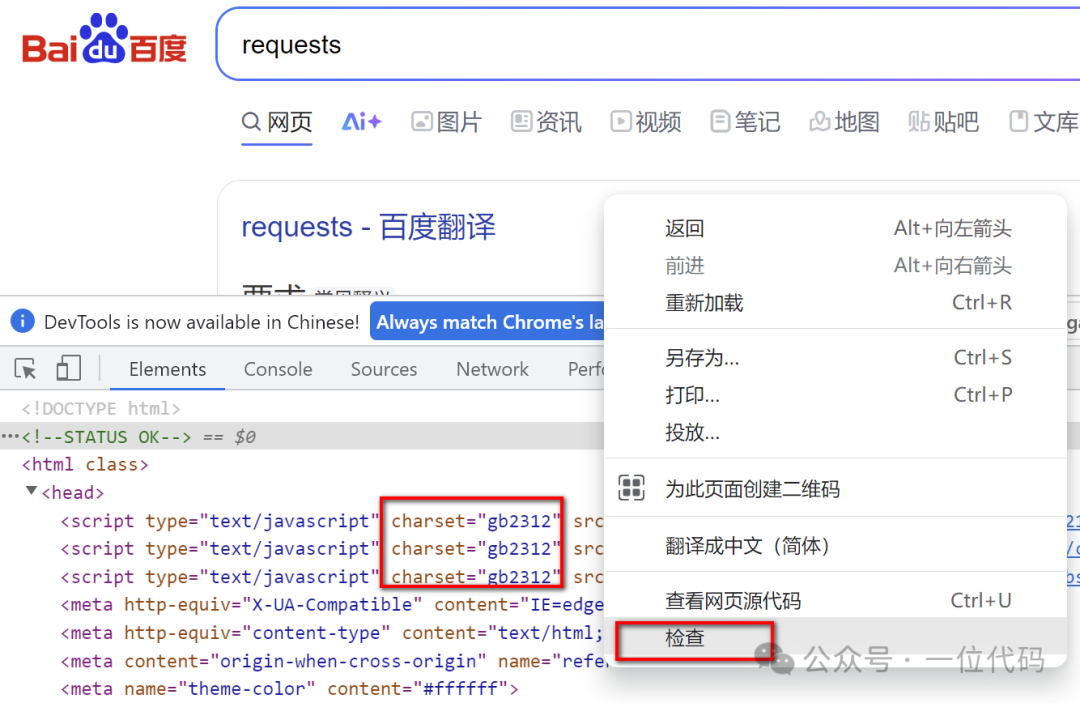
二是:目标网页【右键】-选择【查看网页源代码】- 在 html 中找到【charset】值,该值就是目标网页的编码。
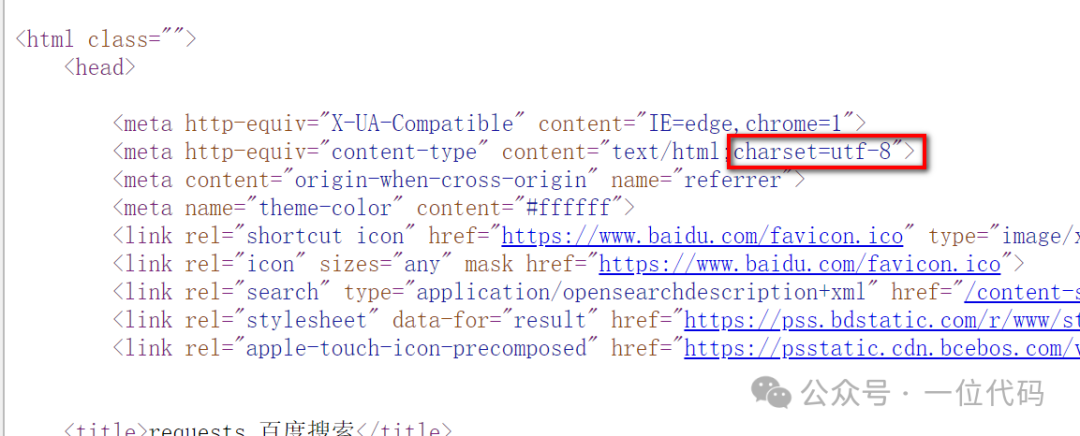
总结:以上方法多用以辅助验证、前期准备。因为在编写爬虫代码时,一般不会把编码写成一个固定值,这样会导致代码灵活性不高,后续网页编码一旦改变将可能会导致一些问题出现。
二、requests 自带编码获取方法---优先使用
requests 自带的三种可供获取网页编码的属性方法中,最准确、实用的为 :
response.apparent_encoding这三种方法详细对比,如下图:

用法示例1:response.headers
python
import requests
url1 = 'https://dydytt.net/index.htm'
url2 = 'https://baijiahao.baidu.com/s?id=1842989128859063643&wfr=spider&for=pc'
response1 = requests.get(url1)
response2 = requests.get(url2)
headers1 = response1.headers
headers2 = response2.headers
print('url1返回headers中不包含charset字段:\n',headers1)
print('url2返回headers中包含charset字段:\n',headers2)结果如下图:

结果分析:不是所有的网页响应头中都包含 charset 字段的,如上例中 url1 响应头中就不包含 charset 字段。
用法示例2:response.encoding
python
import requests
url1 = 'https://dydytt.net/index.htm'
url2 = 'https://baijiahao.baidu.com/s?id=1842989128859063643&wfr=spider&for=pc'
response1 = requests.get(url1)
response2 = requests.get(url2)
encode1 = response1.encoding
encode2 = response2.encoding
print('url1返回headers中不包含charset字段:\n',encode1)
print('url2返回headers中包含charset字段:\n',encode2)结果如下图:

结果分析:response.encoding,是基于响应头中的 charset 字段来提取的网页编码,若响应头不包含 charset ,则返回默认编码 ISO-8859-1,如上例中的 url1 。
用法示例3:response.apparent_encoding
python
import requests
url1 = 'https://dydytt.net/index.htm'
url2 = 'https://baijiahao.baidu.com/s?id=1842989128859063643&wfr=spider&for=pc'
response1 = requests.get(url1)
response2 = requests.get(url2)
encode1 = response1.apparent_encoding
encode2 = response2.apparent_encoding
print('url1使用apparent_encoding属性获取到的网页编码:\n',encode1)
print('url2使用apparent_encoding属性获取到的网页编码:\n',encode2)结果如下图:

结果分析:response.apparent_encoding 获取的编码是最准确的。如 url1:
(1)通过浏览器查看方式,可以看到 url1 的实际编码为 gb2312;
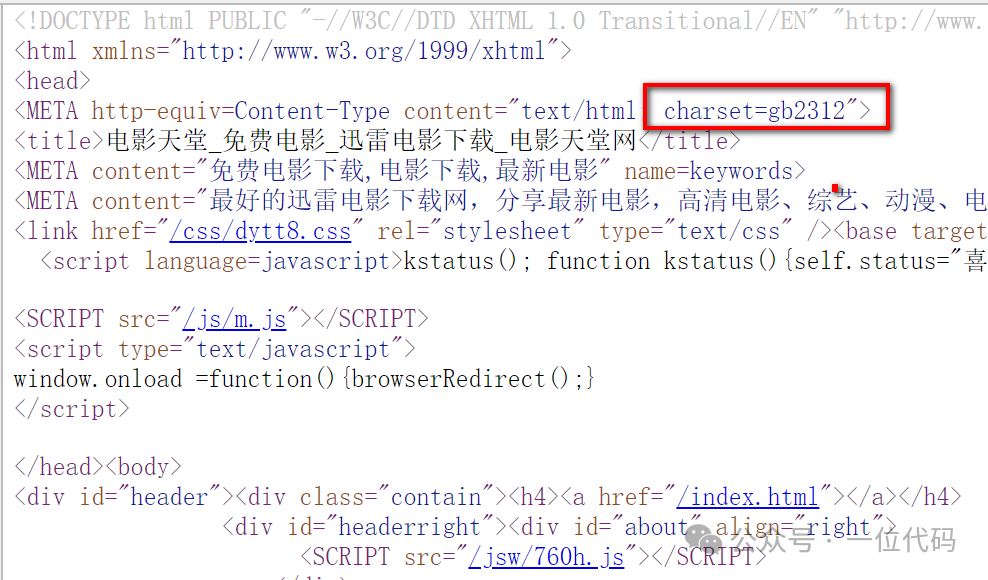
(2)使用 response.headers ,url1 响应头中不包括 charset 字段,则无法获取网页编码;
(3)使用 response.encoding,因 url1 响应头中不包括 charset 字段,返回默认编码 ISO-8859-1,与 url1 实际编码 gb2312 不一致;
(4)使用 response.apparent_encoding ,获取的 url1 编码与实际编码一致,均为 gb2312。
三、chardet 第三方编码识别模块---可作了解
除上面两种基本方法外,还可以通过引入第三方模块 chardet 来查看网页编码。
一般来说,上面两种方法结合使用,已经可以满足绝大多数需求,使用 chardet 来查看网页编码,可作了解。
使用前,需要先安装 chardet ,安装命令为:
pip install chardet具体运用代码如下:
python
import requests
import chardet
url1 = 'https://dydytt.net/index.htm'
url2 = 'https://baijiahao.baidu.com/s?id=1842989128859063643&wfr=spider&for=pc'
response1 = requests.get(url1)
response2 = requests.get(url2)
encode1 = chardet.detect(response1.content)
encode2 = chardet.detect(response2.content)
print('url1网页编码为:\n',encode1)
print('url2网页编码为:\n',encode2)结果如下图

结果分析:从结果来看,该方法对网页的编码判断还是比较准确的。这里有一个注意的点是,chardet.detect() 方法接受一个字节序列作为输入,所以上面代码中输入的是 response.content 的返回值。
总结
以上就是如何正确获取网页编码的三种常见方法,在代码中建议优先选择 requests 自带的 response.apparent_encoding,更为精准。