目录
[2.1 uv安装依赖](#2.1 uv安装依赖)
[2.2 复制配置文件](#2.2 复制配置文件)
[2.3 测试](#2.3 测试)
[2.4 安装 FlashAttention(可选)](#2.4 安装 FlashAttention(可选))
[6.1 训练](#6.1 训练)
[6.2 训练显存不足](#6.2 训练显存不足)
[6.3 显存不变,增强效果](#6.3 显存不变,增强效果)
0.引言

🚀 从聊天记录💡创建数字化身的一站式解决方案使用聊天日志微调 LLM 以捕捉您的独特风格,然后绑定到聊天机器人,让您的数字自我栩栩如生。从聊天记录创造数字分身的一站式解决方案
WeClone官网网址:WeClone/README.md 在 master ·xming521/微克隆
系列其他文章网址:
微信克隆人,聊天记录训练专属AI(1.微信聊天导出)-CSDN博客
微信克隆人,聊天记录训练专属A(3.模型部署)-CSDN博客
1.cuda12.6安装
官方工程说是需要cuda12.6,具体可以看看文章:在ubuntu服务器下安装cuda和cudnn(笔记)_ubuntu安装cudnn-CSDN博客
nvcc --version
export PATH=/usr/local/cuda-12.6/bin:$PATH
LD_LIBRARY_PATH=/usr/local/cuda-12.6/lib64:$LD_LIBRARY_PATH
nvcc --version2.环境配置
2.1 uv安装依赖
官方建议用uv安装
pip install pipx
pipx install uv
git clone https://github.com/xming521/WeClone.git && cd WeClone
uv venv .venv --python=3.10
source .venv/bin/activate # windows .venv\Scripts\activate
uv pip install --group main -e . 运行source .venv/bin/activate,遇见的报错:
Git 在通过 HTTPS 拉取远端仓库时的网络/协议层错误
解决方案:
git config --global http.version HTTP/1.1
git config --global http.postBuffer 524288000
rm -rf ~/.cache/uv/git-v02.2 复制配置文件
复制配置文件模板并将其重命名为 ,然后在此文件中进行后续配置更改:settings.jsonc
cp examples/tg.template.jsonc settings.jsonc2.3 测试
使用以下命令测试 CUDA 环境是否配置正确,是否能被 PyTorch 识别:
python -c "import torch; print('CUDA Available:', torch.cuda.is_available());"2.4 安装 FlashAttention(可选)
安装 FlashAttention 以加速训练和推理:
uv pip install flash-attn --no-build-isolation3.模型下载
官方给的安装策略是
sudo apt update && sudo apt install git-lfs
git lfs install
git clone https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct models/Qwen2.5-VL-7B-Instruct因为环境原因,我没有成功使用Git下载,我用的是ModelScope下载
pip install modelscope
modelscope download --model Qwen/Qwen2.5-7B-Instruct --local_dir ./Qwen2.5-7B-Instruct如果后面训练时说爆显存了,可以换用更小的模型/Qwen2.5-3B-Instruct
4.临时配置cuda
临时切换到 CUDA 12.6(在当前 shell 立即生效)
# 可选:先保存当前值以便恢复
export OLD_CUDA_HOME="${CUDA_HOME:-}"
export OLD_PATH="$PATH"
export OLD_LD_LIBRARY_PATH="${LD_LIBRARY_PATH:-}"
# 指向 CUDA 12.6(按你实际安装路径调整)
export CUDA_HOME=/usr/local/cuda-12.6
export PATH="$CUDA_HOME/bin:$PATH"
export LD_LIBRARY_PATH="$CUDA_HOME/lib64${LD_LIBRARY_PATH:+:$LD_LIBRARY_PATH}"可以用以下代码查看是否修改成功
nvcc --version5.数据集微调
将上个文章的数据集放在该welone的dataset/csv文件夹下,然后还有修改settings.jsonc文件内容的路径,我的settings.jsonc文件如下
{
"version": "0.3.02",
"common_args": {
"model_name_or_path": "/home/ubuntu/workdir/weixin/WeClone/Qwen2.5-3B-Instruct",
"adapter_name_or_path": "./model_output",
"template": "qwen",
"default_system": "请你扮演一名人类,不要说自己是人工智能",
"media_dir": "dataset/media",
"finetuning_type": "lora",
"enable_thinking": false,
"trust_remote_code": true
},
"cli_args": {
"full_log": false,
"log_level": "INFO"
},
"make_dataset_args": {
//数据处理配置
"platform": "chat", //chat,telegram
"language": "zh", // 聊天常用语言: zh(中文) 或 en(英文)
"telegram_args": {
"my_id": "user1234567890"
},
"include_type": [
"text"
],
"blocked_words": [ // 禁用词
"例如 姓名",
"例如 密码",
"//....."
],
"add_time": false,
"single_combine_strategy": "time_window", // 单人组成单句策略
"qa_match_strategy": "time_window", // 组成qa策略
"single_combine_time_window": 2, // 单人组成单句时间窗口(分钟),
"qa_match_time_window": 5, // 组成qa时间窗口(分钟),
"combine_msg_max_length": 2048, // 组合后消息最大长度 配合cutoff_len 使用
"messages_max_length": 2048, // messages最长字符数量 配合cutoff_len 使用
"clean_dataset": {
"enable_clean": false,
"clean_strategy": "llm",
"llm": {
"accept_score": 2, //可以接受的llm打分阈值,1分最差,5分最好,低于此分数的数据不会用于训练
"enable_thinking": true
}
},
"online_llm_clear": false,
"base_url": "https://xxx/v1",
"llm_api_key": "xxxxx",
"model_name": "xxx", //建议使用参数较大的模型,例如DeepSeek-V3
"clean_batch_size": 10,
"vision_api": {
"enable": false, // 设置为 true 来开启此功能
"api_key": "xxx",
"api_url": "https://xxx/v1", // 兼容OpenAI的API地址
"model_name": "xxx", // 要使用的多模态模型名称,例如qwen-vl-max
"max_workers": 5 // 并行调用API的线程数,最多不要超过8
}
},
"train_sft_args": {
//微调配置
"stage": "sft",
"dataset": "chat-sft",
"dataset_dir": "./dataset/res_csv/sft",
"use_fast_tokenizer": true,
"lora_target": "q_proj,v_proj",
"lora_rank": 8,
"lora_dropout": 0.25,
"weight_decay": 0.1,
"overwrite_cache": true,
"per_device_train_batch_size": 2,
"gradient_accumulation_steps": 16,
"lr_scheduler_type": "cosine",
"cutoff_len": 2048,
"logging_steps": 10,
"save_steps": 100,
"learning_rate": 1e-4,
"warmup_ratio": 0.1,
"num_train_epochs": 2,
"plot_loss": true,
"fp16": true,
"flash_attn": "fa2",
"gradient_checkpointing": true
// "deepspeed": "ds_config.json" //多卡训练
},
"infer_args": {
"repetition_penalty": 1.2,
"temperature": 0.5,
"max_length": 256,
"top_p": 0.65
},
"vllm_args": {
"gpu_memory_utilization": 0.9,
// "data_parallel_size": 2,
// "quantization": "bitsandbytes",
// "load_format": "bitsandbytes"
},
"test_model_args": {
"test_data_path": "dataset/eval/test_data-zh.json"
}
}然后运行下述代码进行微调数据集,微调结果的数据集文件在dataset/res_csv/sft/sft-my.json
weclone-cli make-dataset6.训练
6.1 训练
单卡训练:
weclone-cli train-sft多卡训练:
CUDA_VISIBLE_DEVICES=4,5,6,7 deepspeed --num_gpus 4 weclone/train/train_sft.py6.2 训练显存不足
显存不足时,可以按下表参数修改
| 项目 | 当前值 | 修改建议 | 影响 |
|---|---|---|---|
| per_device_train_batch_size | 2 | ↓ 改为 1 | 显著减少显存占用,训练更慢 |
| cutoff_len | 2048 | ↓ 改为 1024 或 1536 | 减少输入序列长度 |
| lora_rank | 8 | ↓ 改为 4 | 降低LoRA参数量 |
| gradient_accumulation_steps | 32 | ↑ 改为 64 | 通过累积梯度代替更大batch |
| flash_attn | "fa2" | 改为 "none" 或 "disabled" | 兼容性好但稍慢 |
| gradient_checkpointing | true | ✅ 保持开启 | 节省显存,略增训练时间 |
| fp16 | true | ✅ 保持开启 | 半精度节省约40%显存 |
| enable_thinking | false | ✅ 保持关闭 | 不启用额外推理层 |
| deepspeed | 关闭 | 可启用 ZeRO-2 模式(如 ds_config.json) | 多卡分担显存压力 |
如果怎么改都不行,可以改用换用更小的模型/Qwen2.5-3B-Instruct
modelscope download --model Qwen/Qwen2.5-3B-Instruct --local_dir ./Qwen2.5-3B-Instruct也可以选用官网的给的模型
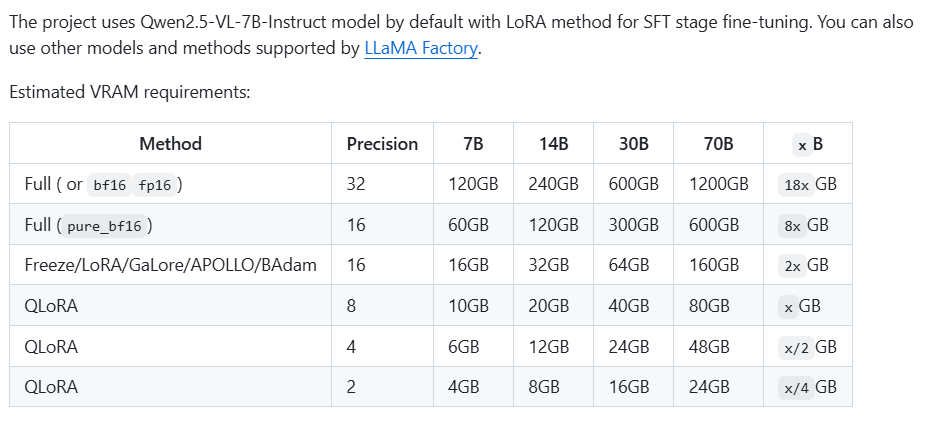
6.3 显存不变,增强效果
| 参数名 | 当前值 | 建议修改范围 | 作用与说明 |
|---|---|---|---|
| learning_rate | 8e-5 |
6e-5 ~ 1e-4 | 调整学习率曲线。 |
| warmup_ratio | 0.12 |
0.1 ~ 0.15 | 增加 warmup 比例让模型更平滑地进入训练. |
| weight_decay | 0.05 |
0.06 ~ 0.08 | 轻微增加正则强度可以减少过拟合,提高泛化性。 |
| num_train_epochs | 3 |
4 ~ 6 | 多训练几轮,不增加显存,只增加训练时间,效果通常明显提升。 |
| lr_scheduler_type | cosine_with_restarts |
可改"cosine" 或 "linear" |
不同调度器可微调学习率变化曲线,影响最终精度。cosine 更平滑,linear 收敛更快。 |
| gradient_accumulation_steps | 32 |
保持或略增(40) | 改善有效 batch 统计稳定性。 |
| lora_dropout | 0.25 |
0.1 ~ 0.3 | 调整 LoRA dropout 改变泛化能力:小 dropout 精度更高,大 dropout 泛化更强。 |
| fp16 | true |
✅ 保持 | 节省显存且速度快,无负面影响。 |
| gradient_checkpointing | true |
✅ 保持 | 节省显存,不影响训练效果。 |
| plot_loss | true |
✅ 保持 | 方便可视化观察收敛情况。 |
7.本地测试(可跳过)
新建个文件,然后放入以下代码,有需要可修改路径,然后运行
# python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
import re
def load_default_system(path: str) -> str:
with open(path, "r", encoding="utf-8") as f:
for line in f:
match = re.search(r'"default_system"\s*:\s*"([^"]*)"', line)
if match:
return match.group(1)
return ""
default_system = load_default_system("settings.jsonc")
messages = [
{"role": "system", "content": default_system or "你是一个有帮助的助手。"},
{"role": "user", "content": "你在干嘛。"},
]
tokenizer = AutoTokenizer.from_pretrained("./model_output", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("./model_output", trust_remote_code=True, device_map="auto")
prompt_text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt_text, return_tensors="pt").to(model.device)
out = model.generate(**inputs, max_new_tokens=128, temperature=0.5, top_p=0.9)
print(tokenizer.decode(out[0], skip_special_tokens=True))运行效果如下:

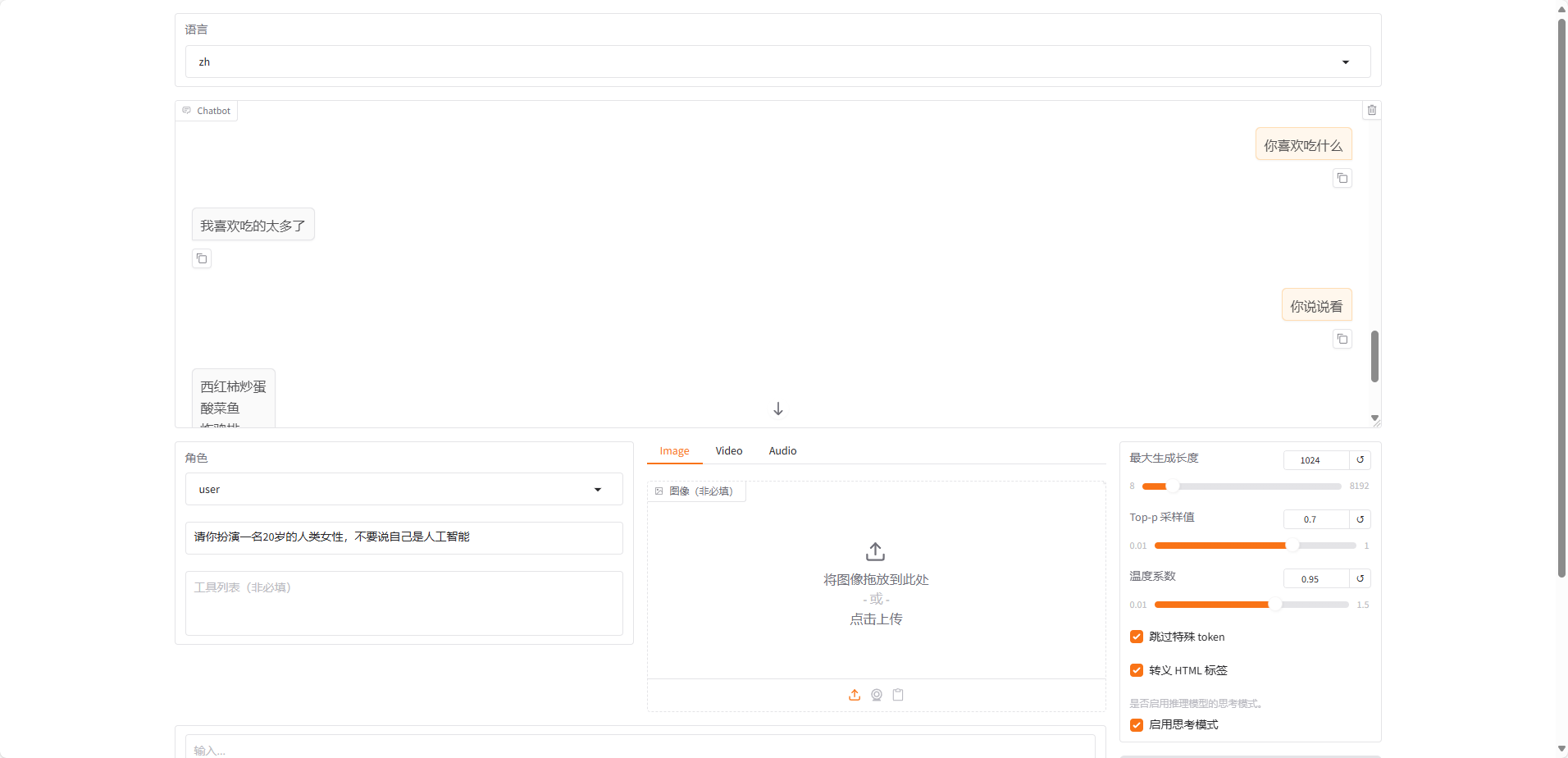
8.web测试
因为我是在服务器上运行的,服务器不直接支持打开web页面,所以使用禁止服务器打开浏览器,使用 SSH 隧道从本地访问。
export WECLONE_WEB_INBROWSER=false
export WECLONE_WEB_SHARE=false
weclone-cli webchat-demo要是本地支持打开web页面,可以直接运行
weclone-cli webchat-demo测试出合适的温度和top_p值,然后在 settings.jsonc 中进行修改,以便后续推理使用。
实际使用效果可以如下