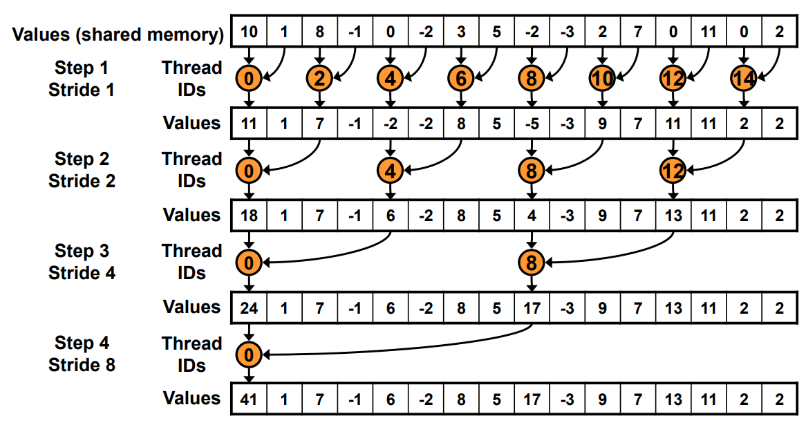
1. 归约思路
归约操作通过多轮并行阶段逐步聚合数据,实现并行化计算:
- 第一轮 :相邻两个元素两两相加
- 线程处理索引
(0,1),和写回索引0; - 线程处理索引
(2,3),和写回索引2; - 线程处理索引
(4,5),和写回索引4; - 结果:索引
0存3、索引2存7、索引4存11。
- 线程处理索引
- 第二轮 :聚合上一轮的部分结果
- 线程处理索引
(0,2),和写回索引0; - 索引
4保持不变; - 结果:索引
0存10(前四个数的和)、索引4存11。
- 线程处理索引
- 第三轮 :聚合最终结果
- 线程处理索引
(0,4),和写回索引0; - 最终结果:所有元素的和
21。
- 线程处理索引
__global__ void reduce_v0(float *g_idata, float *g_odata) {
__shared__ float sdata[BLOCK_SIZE];
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x * blockDim.x + threadIdx.x;
sdata[tid] = g_idata[i];
__syncthreads();
for (unsigned int s = 1; s < blockDim.x; s *= 2) {
if (tid % (2 * s) == 0) { // 相当于这里的tid = 2 * s
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}优化点:
(1)线程闲置问题
在归约的for循环阶段,每次迭代只有前一半线程参与计算,后一半线程闲置。以 256 线程的线程块为例:
- 第一次迭代:仅前 128 个线程执行
sdata[tid] += sdata[tid + s]; - 第二次迭代:仅 64 个线程参与;
- ......
- 最后一次迭代:仅有 1 个线程执行最终累加操作。
(2)线程束分歧问题
为避免数据竞争,代码中加入条件判断if (tid % (2 * s) == 0),这会导致线程束分化(warp divergence):
- 以第一次迭代(跨度
s = 1)为例,条件等价于tid % 2 == 0,只有偶数索引线程参与计算,奇数索引线程空转等待; - 同一 warp 中的线程因执行路径不同,性能严重受损。
(3)存储体冲突(bank conflict)
归约迭代中,多个线程会连续访问共享内存的相邻元素。对于 32 位数据类型(如float),第i个线程访问的sdata[i]所属 bank 编号为:
bank_id = (i * sizeof(float)) / 4 % 32 = i % 32在 CUDA 共享内存架构中,每个 bank 一个时钟周期仅能服务一个线程的访问请求。若不同线程同时访问同一 bank,会引发存储体冲突,降低内存访问效率。
2、优化思路
(1)解决线程束分化问题
代码中warpReduce函数通过无分支执行消除线程束分化:
- 函数内未使用任何条件判断(如
if语句),32 个线程(属于同一 warp)执行完全相同的指令序列:先执行cache[tid] + cache[tid + 32],再依次以步长 16、8、4、2、1 调用__shfl_down_sync进行累加。 - 同一 warp 内的线程遵循 SIMT(单指令多线程)模式,所有线程同步执行相同操作,不存在 "部分线程执行、部分线程空转" 的分支分化,避免了因指令路径不一致导致的性能损耗。
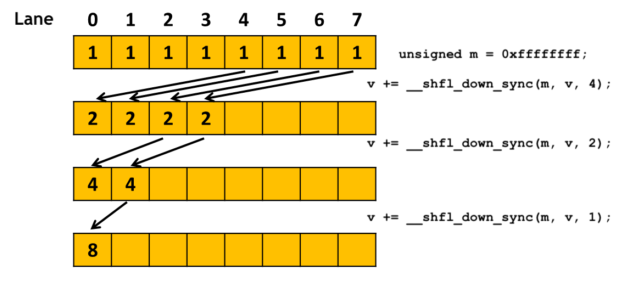
(2)解决线程闲置问题
通过全线程全程参与计算避免闲置:
- warp 内 32 个线程(
tid0~31)从始至终参与所有操作:- 第一步均执行
cache[tid] + cache[tid + 32]的累加; - 后续每步
__shfl_down_sync调用中,每个线程都负责从下方线程读取数据并更新自身值,直至最终收敛。
- 第一步均执行
(3)解决存储体冲突问题
通过寄存器级通信替代共享内存访问规避冲突:
-
传统归约依赖共享内存
cache进行数据交换,当多个线程访问相邻索引(如cache[tid]和cache[tid+1])时,易因共享内存 bank(共 32 个)的并发访问引发冲突(同一 bank 同一周期只能响应一个请求)。 -
此代码中,
__shfl_down_sync操作基于线程寄存器直接通信,数据交换在寄存器间完成,不涉及共享内存的读写。因此,完全避开了共享内存 bank 的竞争,从根本上消除了存储体冲突的性能损耗。#define FULL_MASK 0xffffffff
device void warpReduce(float *cache, unsigned int tid) {
int v = cache[tid] + cache[tid + 32];
v += __shfl_down_sync(FULL_MASK, v, 16);
v += __shfl_down_sync(FULL_MASK, v, 8);
v += __shfl_down_sync(FULL_MASK, v, 4);
v += __shfl_down_sync(FULL_MASK, v, 2);
v += __shfl_down_sync(FULL_MASK, v, 1);
cache[tid] = v;
}