文章目录
- [【1】 发现问题与解决问题](#【1】 发现问题与解决问题)
-
- [1. 面临的问题](#1. 面临的问题)
- [2. 本文的贡献](#2. 本文的贡献)
- 【2】本文的模型架构
-
- [1. 视觉前端 (Visual Frontend)](#1. 视觉前端 (Visual Frontend))
- [2. 学生模型入口 (Conv1)](#2. 学生模型入口 (Conv1))
- [3. 完整学生模型 (Student VSR model)](#3. 完整学生模型 (Student VSR model))
- 【3】损失函数详解
-
- [1. 总损失函数](#1. 总损失函数)
- [2. 转录的 CTC 损失 (Hard Label)](#2. 转录的 CTC 损失 (Hard Label))
- [3. 蒸馏损失 (Distillation Loss / Soft Label)](#3. 蒸馏损失 (Distillation Loss / Soft Label))
- [4. 补充知识:如何衡量两个概率矩阵的差异](#4. 补充知识:如何衡量两个概率矩阵的差异)
- 【4】相关工作与理论背景
-
- [1. 监督唇语识别 (Supervised Lip Reading)](#1. 监督唇语识别 (Supervised Lip Reading))
- [2. 知识蒸馏的两种流派 (Knowledge Distillation)](#2. 知识蒸馏的两种流派 (Knowledge Distillation))
- [3. 跨模态蒸馏 (Cross-modal Distillation)](#3. 跨模态蒸馏 (Cross-modal Distillation))
- 【5】数据集与清洗策略
-
- [1. 数据集的困境](#1. 数据集的困境)
- [2. VoxCeleb2 的"大浪淘沙"](#2. VoxCeleb2 的“大浪淘沙”)
- 【6】实验设置与实验结果
-
- [1. 实验设置](#1. 实验设置)
- [2. 实验结果分析 (WER)](#2. 实验结果分析 (WER))
原文标题 :ASR is all you need: Cross-modal distillation for lip reading
发表年份 :2020
核心思想:利用强大的 ASR(语音识别)模型作为教师,通过跨模态蒸馏,利用无标签数据训练 VSR(视觉语音识别/唇读)模型。
【1】 发现问题与解决问题
1. 面临的问题
训练一个鲁棒的视觉语音识别(VSR)模型通常依赖于海量且精准的人工标注数据(视频+精准字幕)。然而,获取这些"完美数据"成本极高,现有的公开数据集规模太小,限制了模型性能的上限。
2. 本文的贡献
作者提出了一种利用无标签视频数据的训练策略:
- 跨模态知识蒸馏 :使用一个在海量纯音频语料库上训练好的 ASR 模型(教师) ,来指导 VSR 模型(学生) 的学习。
- 摆脱人工标注:直接使用 ASR 教师模型生成的预测结果作为监督信号,消除了对专业字幕和强制对齐(Forced Alignment)的依赖。
- 双重监督信号 :
- 硬标签 (Hard Label) :利用 ASR 生成的标签结果计算 CTC 损失,让学生模仿教师的预测结果。
- 软标签 (Soft Label) :利用 ASR 输出的概率矩阵计算 蒸馏损失(KL 散度),让学生模仿教师的概率分布。
【2】本文的模型架构
总体架构:
- 教师模型 (Teacher) :一个已经训练好的 Jasper 10x5 声学模型。它是在 Librispeech(大型纯音频数据集)上预训练的,参数冻结不更新。
- 学生模型 (Student) :基于 Jasper 声学模型架构。本质上,它是一个 全卷积网络 (FCN) + CTC 的组合。与基于 Attention 的 Seq2Seq 模型(如 Transformer)不同,该模型不依赖解码器逐个 Token 自回归生成,而是并行输出每一帧的概率矩阵,最后通过 CTC 算法解码。
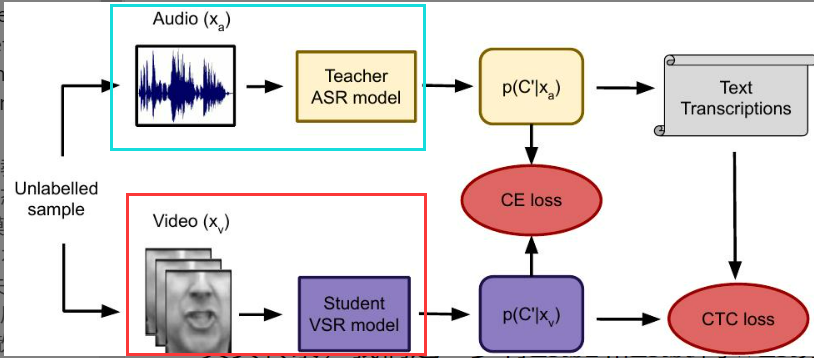
1. 视觉前端 (Visual Frontend)
在进入主干网络之前,首先需要提取视频帧的特征。
- 输入 :原始视频帧序列。维度: ( B , T , H , W , 1 ) (B, T, H, W, 1) (B,T,H,W,1) ------ 其中 1 代表单通道灰度图。
- 处理 :时空残差网络 (Spatio-temporal Residual CNN)。这是一个 3D 卷积网络,能够同时捕捉嘴唇的运动(时间维度)和形状(空间维度)。
- 输出 :视觉特征序列。维度: ( B , T , D f e a t ) (B, T, D_{feat}) (B,T,Dfeat) ------ D f e a t D_{feat} Dfeat 为特征向量维度(通常为 512 或 1024)。
思考:维度变换原理------为什么 H, W 消失了?
这是通过 全局平均池化 (Global Average Pooling, GAP) 实现的。无论输入的空间分辨率如何,网络末端会将特征图在空间维度上压缩为一个点:
( B , T , C , H s m a l l , W s m a l l ) → G A P ( B , T , C , 1 , 1 ) → S q u e e z e ( B , T , D f e a t ) (B, T, C, H_{small}, W_{small}) \xrightarrow{GAP} (B, T, C, 1, 1) \xrightarrow{Squeeze} (B, T, D_{feat}) (B,T,C,Hsmall,Wsmall)GAP (B,T,C,1,1)Squeeze (B,T,Dfeat)
2. 学生模型入口 (Conv1)
这是本文为了将视觉特征适配到声学模型架构(Jasper)所做的最关键修改。
- 输入 :视觉特征 ( B , T , D f e a t ) (B, T, D_{feat}) (B,T,Dfeat)
- 层级 :Conv1 (转置卷积)
- 参数:Kernel = 11, Stride = 0.5, Output Channels = 256
- 原理解析 :
- Stride=0.5 (上采样) :这在数学上等同于 2倍上采样。由于视频帧率(通常 25fps)远低于音频特征的采样频率,为了对齐时间粒度,模型通过转置卷积将时间维度拉长了。
- 输出 :上采样后的特征序列。
- 维度变化 : T → 2 T T \rightarrow 2T T→2T
- 输出维度 : ( B , 2 T , 256 ) (B, 2T, 256) (B,2T,256) ------ 注意:这里的 256 既是特征维度,也是 1D 卷积的输出通道数。
3. 完整学生模型 (Student VSR model)
(下图参照论文 Table 2)
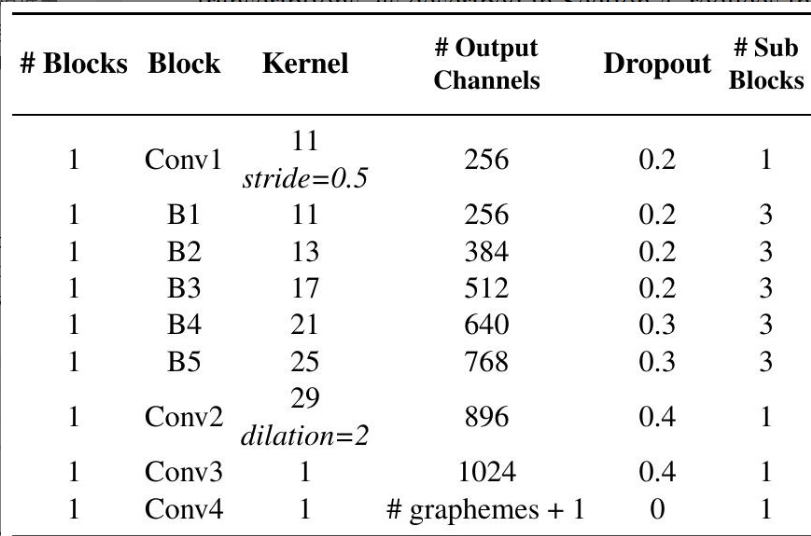
关键参数解释:
- 【1】Kernel (卷积核大小) :文中所有卷积核均为 1D 卷积核 (例如 11, 13, 17, 29)。这意味着卷积操作仅在时间维度上滑动,同时聚合所有通道的信息。
- 【2】Stride (步长) :
Stride=0.5:仅在第一层 Conv1 使用,作用是时间上采样 ( T → 2 T T \rightarrow 2T T→2T)。- 其余层级通常默认为
Stride=1(配合 Padding),保持时间维度不变。
- 【3】Dilation (膨胀系数) :
- 文中 Conv2 使用了
Dilation=2。 - 直观理解 :想象一个标准的卷积核(Kernel=3),采样点是紧挨着的
[x, x, x](覆盖长度 3)。 - 膨胀卷积 :将采样点"撑开",中间留出空隙
[x, o, x, o, x]。在参数量不变的情况下,将感受野扩大到了 5,有助于捕捉长距离的上下文依赖。
- 文中 Conv2 使用了
- 【4】Padding (填充策略):除 Conv1 外,网络中的 1D 卷积层通常配合 Padding 操作,以保证输入输出的时间长度一致。
- 最终输出维度 : ( B , 2 T , VocabSize + 1 ) (B, 2T, \text{VocabSize}+1) (B,2T,VocabSize+1)。这里的
+1代表 CTC 需要的 Blank(空白符)。这样的输出即可与音频教师模型的预测结果进行对齐。
【3】损失函数详解
本文的训练目标是将教师网络(ASR)的知识迁移给学生网络(VSR)。总损失函数由两部分组成:
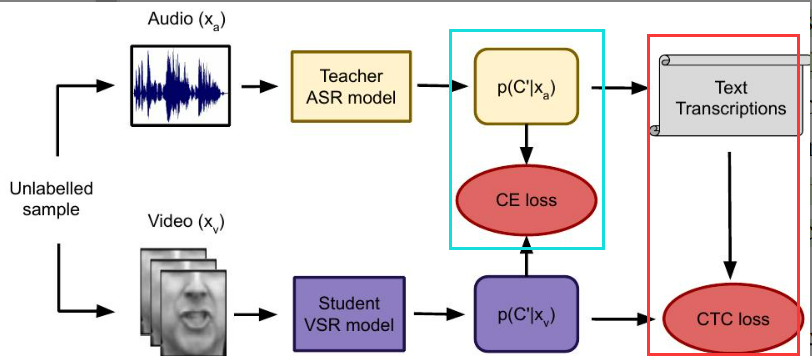
1. 总损失函数
L ( x a , x v , y ∗ ) = λ C T C L C T C ( x v , y ∗ ) + λ K D L K D ( x a , x v ) \mathcal{L}(x_a, x_v, y^*) = \lambda_{CTC} \mathcal{L}{CTC}(x_v, y^*) + \lambda{KD} \mathcal{L}_{KD}(x_a, x_v) L(xa,xv,y∗)=λCTCLCTC(xv,y∗)+λKDLKD(xa,xv)
- x a x_a xa 为音频输入, x v x_v xv 为视频输入, y ∗ y^* y∗ 为(伪)标签序列。
- λ \lambda λ 为平衡系数。根据作者经验,设置 λ C T C = 0.1 \lambda_{CTC} = 0.1 λCTC=0.1 且 λ K D = 10 \lambda_{KD} = 10 λKD=10。
- 理解:这是"硬标签"与"软标签"的双重监督------既要学生学会由教师预测出的文本标签(CTC 损失),又要学生模仿教师在每一帧对他所预测字符的自信程度(蒸馏损失)。
2. 转录的 CTC 损失 (Hard Label)
这部分利用教师模型生成的标签结果作为目标,让学生模型学习"预测什么字"。
p ( y ∣ x ) = ∑ π ∈ B − 1 ( y ) ∏ t = 1 T p ctc ( π t ∣ x ) p(y|x) = \sum_{\pi \in \mathcal{B}^{-1}(y)} \prod_{t=1}^{T} p_{\text{ctc}}(\pi_t | x) p(y∣x)=π∈B−1(y)∑t=1∏Tpctc(πt∣x)
- y y y 为目标输出序列, x x x 为输入序列, B − 1 ( y ) \mathcal{B}^{-1}(y) B−1(y) 为所有能通过 CTC 规则(去除重复和空白)映射到 y y y 的路径 π \pi π 的集合。
- 理解 :计算所有能通过"去重和去空"规则合并成目标文本 y y y 的路径概率之和。
3. 蒸馏损失 (Distillation Loss / Soft Label)
这部分利用教师模型输出的"概率分布"作为目标,最小化教师后验概率 p a p^a pa 和学生后验概率 p v p^v pv 之间的 KL 散度,让学生模型学习"教师的判断细节"。
L K D ( x a , x v ) = − ∑ t ∈ T ∑ c ∈ C ′ log p t a ( c ∣ x a ) p t v ( c ∣ x v ) \mathcal{L}{KD}(x_a, x_v) = - \sum{t \in T} \sum_{c \in C'} \log p_t^a(c|x_a) p_t^v(c|x_v) LKD(xa,xv)=−t∈T∑c∈C′∑logpta(c∣xa)ptv(c∣xv)
- C ′ C' C′ 为包含空白符的扩展字符集, p t a p_t^a pta 和 p t v p_t^v ptv 分别为教师和学生在 t t t 时刻对类别 c c c 的后验概率预测。
- 理解 :逐帧对齐------计算学生预测概率分布与教师预测概率分布之间的差异(通过 KL 散度/交叉熵衡量),并把每一帧、每一类的差异累加起来。
4. 补充知识:如何衡量两个概率矩阵的差异
为了计算蒸馏损失,我们需要衡量"学生预测的分布"与"教师预测的分布"到底有多像。数学上常用的两种方法如下:
(1)KL 散度的定义 (Kullback-Leibler Divergence)
KL 散度通常用来衡量两个概率分布之间的"距离"或差异。
D K L ( P ∣ ∣ Q ) = ∑ i P ( i ) log P ( i ) Q ( i ) D_{KL}(P || Q) = \sum_{i} P(i) \log \frac{P(i)}{Q(i)} DKL(P∣∣Q)=i∑P(i)logQ(i)P(i)
- P ( i ) P(i) P(i) :真实分布中第 i i i 个类别的概率。(文中对应教师模型 ASR 预测出为第 i i i 个类别的结果,即目标分布)
- Q ( i ) Q(i) Q(i) :预测分布中第 i i i 个类别的概率。(文中对应学生模型 VSR 预测出为第 i i i 个类别的结果,即拟合分布)
- log \log log :通常指自然对数(以 e e e 为底)。
(2)交叉熵损失的定义 (Cross-Entropy Loss)
这是深度学习中最常用的分类损失函数。
H ( P , Q ) = − ∑ i P ( i ) log Q ( i ) H(P, Q) = - \sum_{i} P(i) \log Q(i) H(P,Q)=−i∑P(i)logQ(i)
变量定义同上, P ( i ) P(i) P(i) 为教师概率, Q ( i ) Q(i) Q(i) 为学生概率。
【4】相关工作与理论背景
1. 监督唇语识别 (Supervised Lip Reading)
目前的流派主要分为两类:
- CTC 方法:逐帧预测,利用 CTC 损失解决对齐问题(如 LipNet)。
- Seq2Seq 方法:基于 Attention 机制,自回归地逐个预测 Token。
2. 知识蒸馏的两种流派 (Knowledge Distillation)
在深度学习中,蒸馏主要有两种形式:
| 维度 (对比角度) | 方法 A: Logit 回归 | 方法 B: 概率交叉熵 (本文采用) |
|---|---|---|
| 输入数据 | z z z (Logits): Softmax 之前的原始分数 | p p p (Probabilities): 经 Softmax 归一化的概率 |
| 数学约束 | 无约束,数值范围 ( − ∞ , ∞ ) (-\infty, \infty) (−∞,∞) | 约束在 0 , 1 0, 1 0,1 之间,和为 1 |
| 损失函数 | MSE (均方误差) | KL 散度 或 Cross-Entropy |
| 信息侧重 | 侧重于绝对数值 和类间距离 | 侧重于概率分布 |
| 超参数 | 无需温度系数 | 通常需调节温度系数 T T T |
补充:关于温度系数 T T T
- 作用 :经过 Softmax 后,教师模型通常非常"自信"(如 99% 概率给正确类别)。引入 T > 1 T > 1 T>1 可以"软化"分布,让那些原本概率极小的错误类别(但可能与正确类别相似)的概率浮现出来。
- 暗知识 (Dark Knowledge):这种包含类别相似度的信息(例如:虽然是"哈士奇",但它像"狼"多过像"汽车")被称为"暗知识"。
3. 跨模态蒸馏 (Cross-modal Distillation)
本文的方法属于"用一种模态教另一种模态"。在此之前,Wei et al. 31 也做过类似工作,但两者有本质区别:
- Wei et al. 31 :目标是视听融合 (用视觉辅助音频),且训练教师模型依赖人工标签 (Ground Truth)。
- 本文 :目标是纯视觉唇读 ,且完全无监督(利用音频信号预测得到的文本作为标签)。
【5】数据集与清洗策略
1. 数据集的困境
- YT31k, LSVSR, MV-LRS: 质量高但在业界不公开,无法复现。
- Librispeech: 只有音频和标签,没法做视觉任务。
- VoxCeleb2 : 有音视频,数据量巨大(1M+ 样本),但没有标签。
- LRS2 / LRS3: 公开且带标签,但数据量较小(约 30h)。LRS2 来源于 BBC 节目,偏向新闻;LRS3 来源于 TED 演讲,偏向公共演讲。
2. VoxCeleb2 的"大浪淘沙"
由于 VoxCeleb2 包含大量非英语、噪音视频,作者设计了严格的清洗流程,将数据从 1M 筛选至 140k。
【1】基于规则的初筛(语言与置信度)
- 使用教师 ASR 进行转录。
- 保留标准 :转录结果中,"长度 > 4 的单词"必须有 90% 以上属于合法英语单词。这过滤掉了非英语和极度含糊的语音。
【2】基于一致性的精筛(双重校验)
- 引入另一个在 Librispeech 上训练的辅助 ASR 模型 (Wave2Letter)。
- 保留标准 :把教师模型的转录作为 Ground Truth,把辅助模型的转录作为预测结果,计算 WER 。只有当 WER < 28% 时才保留。
【6】实验设置与实验结果
1. 实验设置
- 训练环境与超参 :
- 硬件:4 张 11GB 显存的 GPU。
- 优化器:NovoGrad。
- Batch Size:单卡 64(总 256)。
- 损失权重 : λ C T C = 0.1 \lambda_{CTC} = 0.1 λCTC=0.1, λ K D = 10 \lambda_{KD} = 10 λKD=10(经验值)。
- 推理与解码 :
- 搜索策略 :使用宽度为 8192 的 束搜索 (Beam Search)。
- 语言模型 :引入一个在 Librispeech 文本语料上训练的 6-gram 语言模型 进行辅助打分,以提升预测文本的语法通顺度。
2. 实验结果分析 (WER)
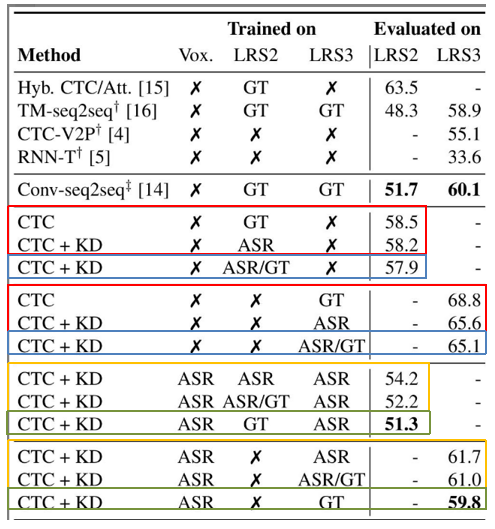
【1】无人工标注 vs 全监督(验证蒸馏有效性)
- 设定:(1)只使用LRS2/LRS3;(2)不使用任何人工标签,完全依赖 ASR 教师生成的伪标签(转录+后验概率)进行训练。
- 结果 :如红框所示
- 在 LRS2 上达到 58.2%(与使用真实标签的 58.5% 持平)。
- 在 LRS3 上达到 65.6%(优于使用真实标签的 68.8%)。
- 结论 :这证明了为了训练有效的唇读模型,昂贵的人工标注数据并不是必需的 。
【2】少量微调的效果(验证少样本能力)
- 设定:(1)只使用LRS2/LRS3;(2)在无监督训练后,仅使用 LRS2/LRS3 中极少量的"main/train-val"子集真实标签进行微调。
- 结果 :如蓝框所示。LRS2 的 WER 降至 57.9% ,LRS3 降至 65.1% 。
- 对比:仅在 LRS2 数据集上训练时,该结果优于之前的 SOTA 方法(15 Audio-Visual Speech Recognition with a Hybrid CTC/Attention Architecture 的 63.5%)。
【3】引入大规模无标签数据(VoxCeleb2 预训练)
- 设定:利用本文方法在海量无标签的 VoxCeleb2 上进行预训练。
- 结果 :如黄框所示。
- 纯无监督 :WER 进一步大幅下降至 54.2% (LRS2) 和 61.7% (LRS3) 。
- 少量微调 :若再配合少量真实标签微调 ,WER 降至 52.2% (LRS2) 和 61.0% (LRS3) 。
【4】最佳性能探索(预训练 + 全监督)
- 设定 :(1)在大规模无监督预训练(VoxCeleb2)之后,(2)使用目标数据集(LRS2/LRS3)的全部真实标签进行全监督微调。
- 结果 :如绿框所示。取得了全场最佳性能,LRS2 为 51.3% ,LRS3 为 59.8% 。
总结
本文揭示了一个高效的训练范式:
"海量异源数据的无监督预训练 (Pre-training) + 目标数据的全监督微调 (Fine-tuning)" 。
先在不同类型的大规模无标签数据集(如 VoxCeleb2)上让模型"见多识广"(学习通用特征),再在解决具体问题的同类型数据集(如 LRS2)上进行精细化训练,能达到模型性能的上限。