文章目录
-
- [1. 配置大语言模型LLM](#1. 配置大语言模型LLM)
-
- [1.1 本地Ollama部署LLM------免费敞开用](#1.1 本地Ollama部署LLM——免费敞开用)
- [1.2 商用AI大模型平台](#1.2 商用AI大模型平台)
- [2. 代码实战QuickStart](#2. 代码实战QuickStart)
-
- [2.1 环境准备](#2.1 环境准备)
- [2.2 LangChain QuickStart](#2.2 LangChain QuickStart)
- [2.3 LangGraph QuickStart](#2.3 LangGraph QuickStart)
- [2.4 LangSmith QuickStart](#2.4 LangSmith QuickStart)
- [2.5 LangFuse QuickStart](#2.5 LangFuse QuickStart)
1. 配置大语言模型LLM
-
考虑到目前的个人计算机都是CPU为主的机器,如果你是和笔者一样囊中羞涩却又执着于AI Agent,本地部署Ollama加载一个小模型是经济实惠的选择,并不影响你对大模型的掌握和学习,毕竟学习的目的重在通过一片落叶而看到整个秋天,而不是没有见过汪洋,就以为江河最大;
-
如果你腰缠万贯,那么确实可以尝试第二种的直接引用商用AI平台大模型,毕竟钞能力无敌。
1.1 本地Ollama部署LLM------免费敞开用
-
Ollama简介;
Ollama is the easiest way to get up and running with large language models such as gpt-oss, Gemma 3, DeepSeek-R1, Qwen3 and more.
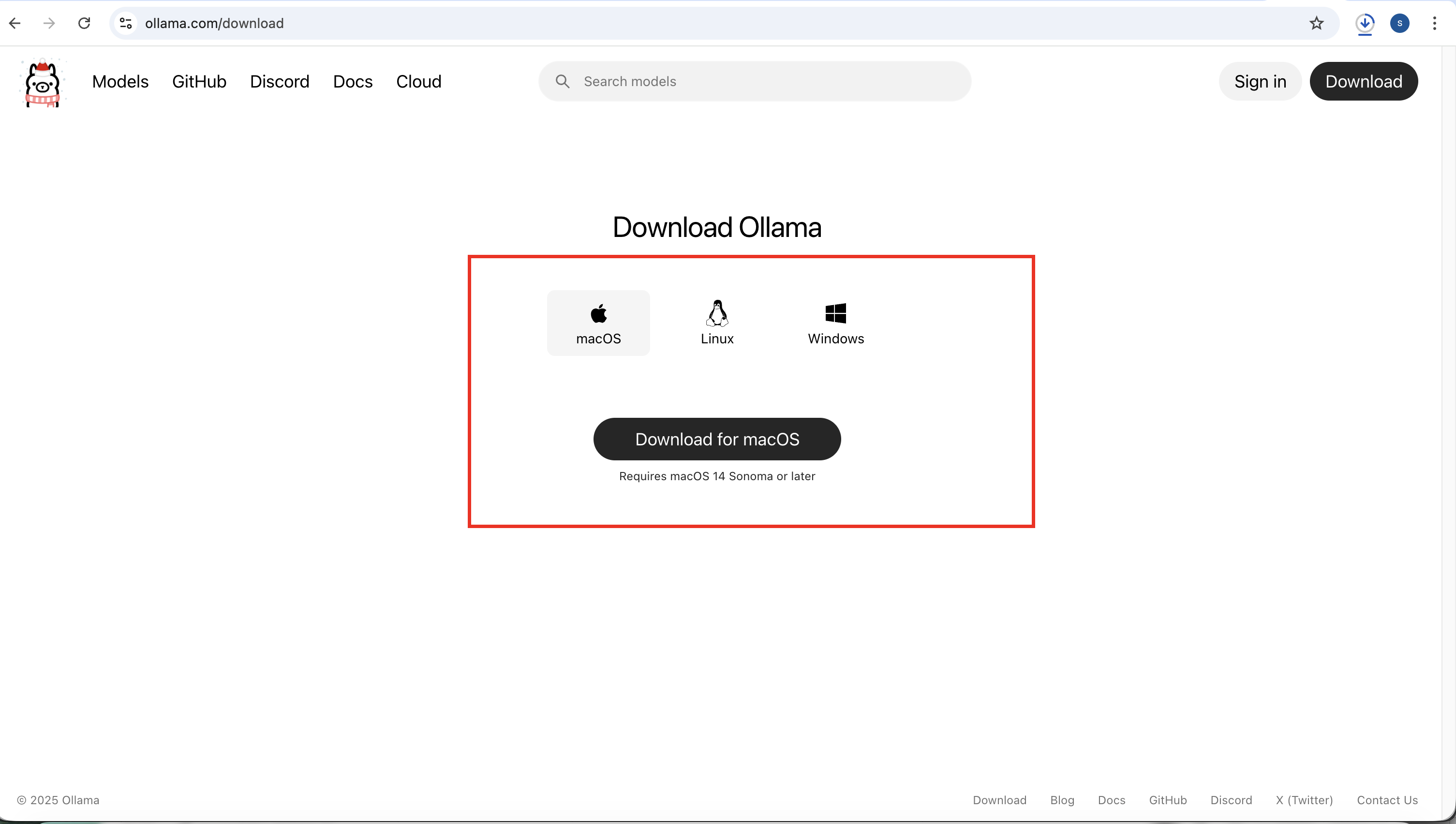
图1.1 Ollama下载页面
-
安装好以后打开你的Ollama软件,一只可爱的小羊驼的icon;默认本地Ollama启动的端口是http://localhost:11434/,启动后可以在浏览器打开该网站,会返回内容
Ollama is running,表示已经安装且启动成功; -
建议选一个小一点的模型,此处不是越大越好,因为个人计算机算力有限(当然如果你跟老黄关系很好,他送了你几块性能贼强的GPU显卡,就当我没说!),以
qwen3:4b为例,选择好以后进行对话,如果首次选择模型的话会进入下载模型的环节,下载需要点时间,可以去喝一杯咖啡等着,等模型会回复你的问题后则代表模型已经本地下载完成,恭喜你解锁了本地的LLM,如图1.2,开始免费畅饮吧;
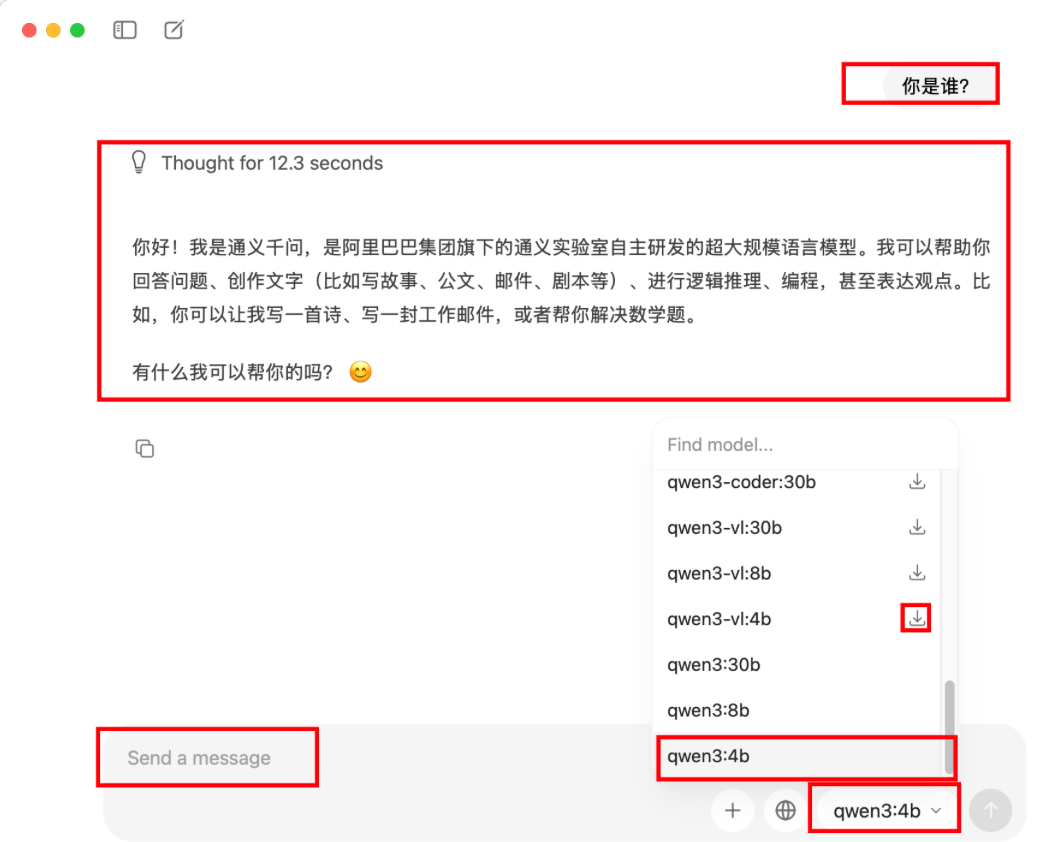
图1.2 Ollama主界面
- 对Ollama内部的模型稍微注意点,区别就是模型名字带
cloud或带个小云朵icon的模型是外部模型,本质和商用AI平台的模型类似,并且用cloud模型会要求你登录注册,此处就不展开细说了,用带下载按钮的小模型即可,如图1.3。
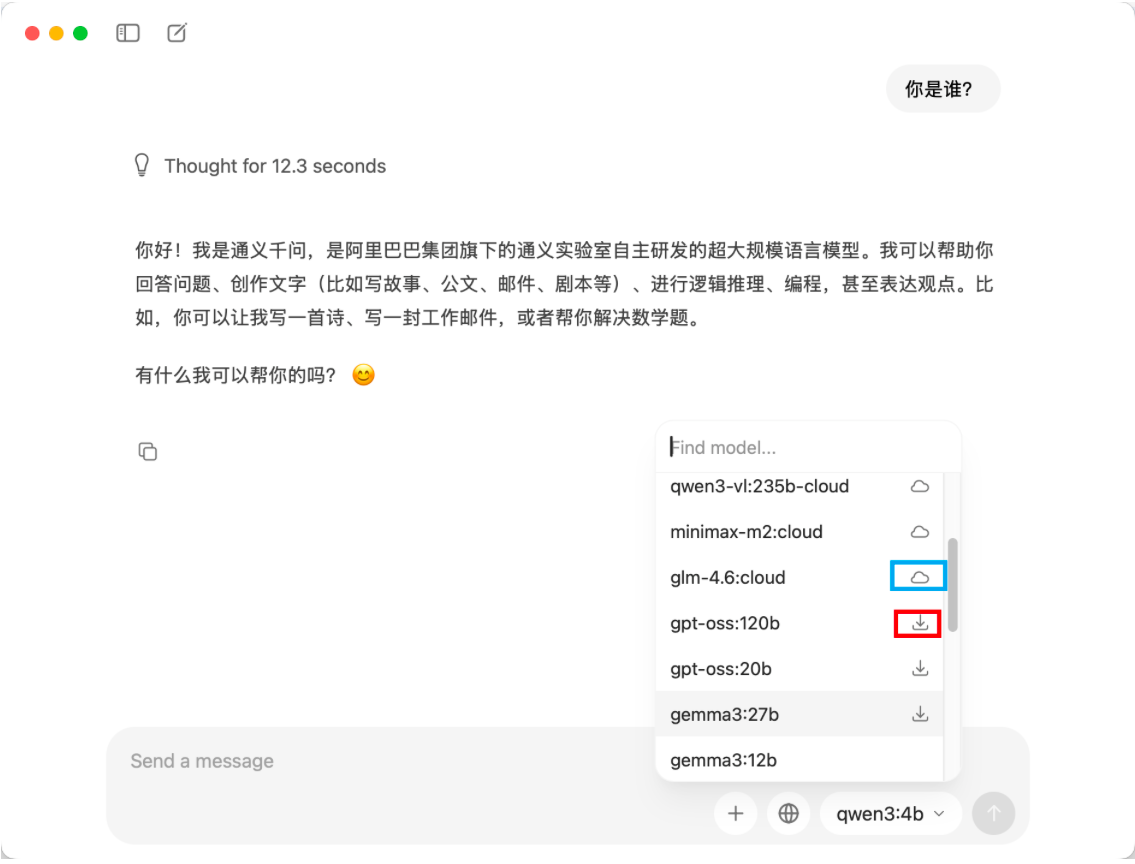
图1.3 Ollama内的本地模型和云端(外部)模型
1.2 商用AI大模型平台
- 以硅基流动平台为例,先注册好账号,设置API Key,官网和具体操作参考如下;
- 使用步骤总结;
- 注册或登录平台账号;
- 找到说明文档获取调用模型的通用
url链接; - 注册调用商用大模型的
API key,如图1.4;
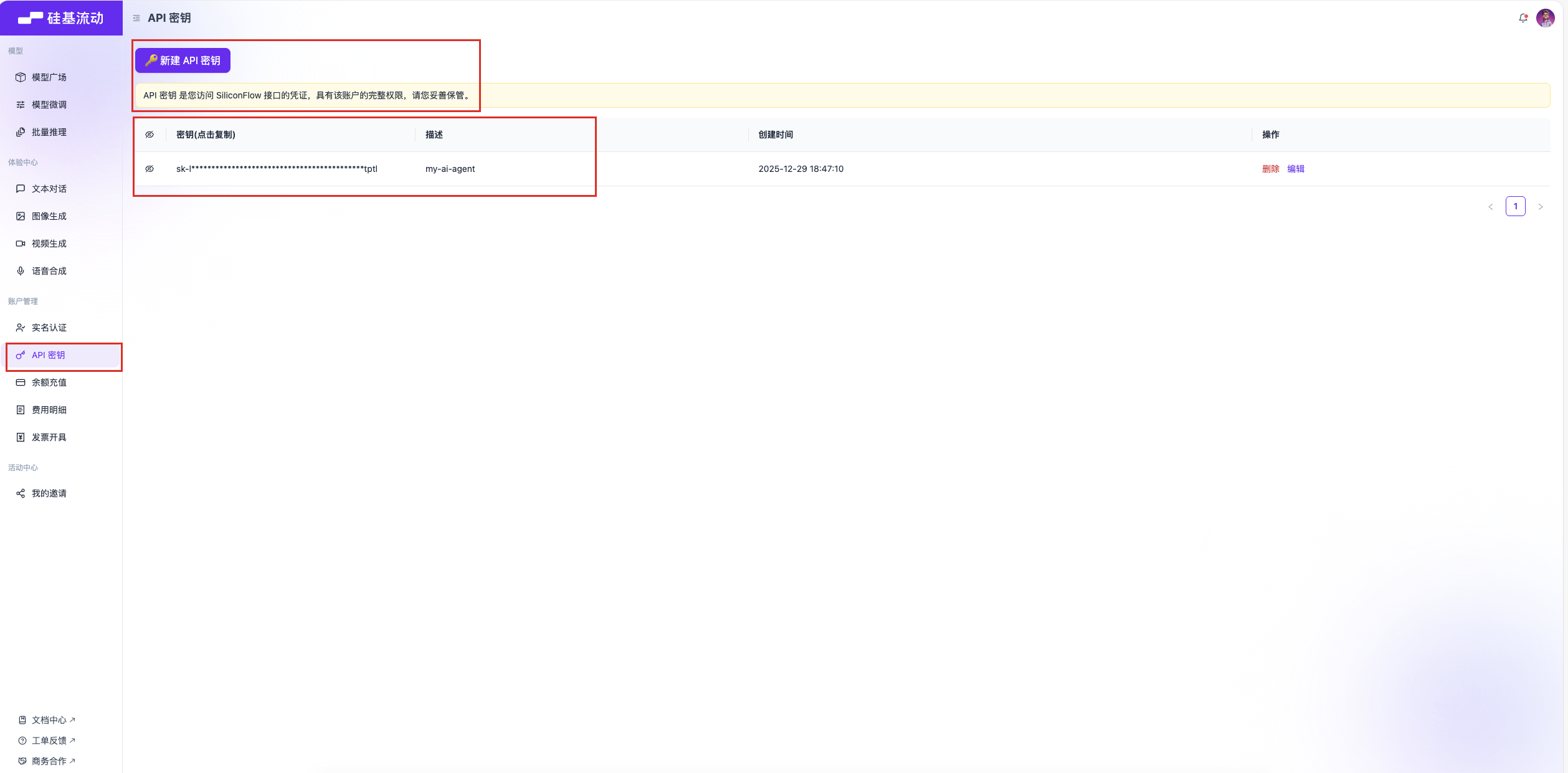
图1.4 获取硅基流动API Key
- 瞅一眼模型的收费算法,选择适合自己的模型,不太建议以上来就上贵的,如果是企业试验阶段,反而建议选最便宜的先尝试,看看模型的边界和企业内部应用的痛点在哪里,再咨询官网或尝试是否可以通过升级模型来解决。如果反了,就会形成
由奢入简难的尴尬处境。
- 除了硅基流动,国内还有像阿里云的百炼平台、Deepseek平台版等等,都是商用AI大模型平台的代表,使用方式步骤都差不多,硬要说差别的话只是有人单独做了自家的模型商用平台,有人做了资源整合的模型平台,对于使用者来说,那肯定是谁便宜又安全可靠用谁,比如白嫖硅基流动的免费在线小模型,如图1.5。
-
首次调用参考:首次调用通义千问API
-
Deepseek平台版:https://platform.deepseek.com/usage
-
Deepseek平台说明文档:https://api-docs.deepseek.com/
-
......
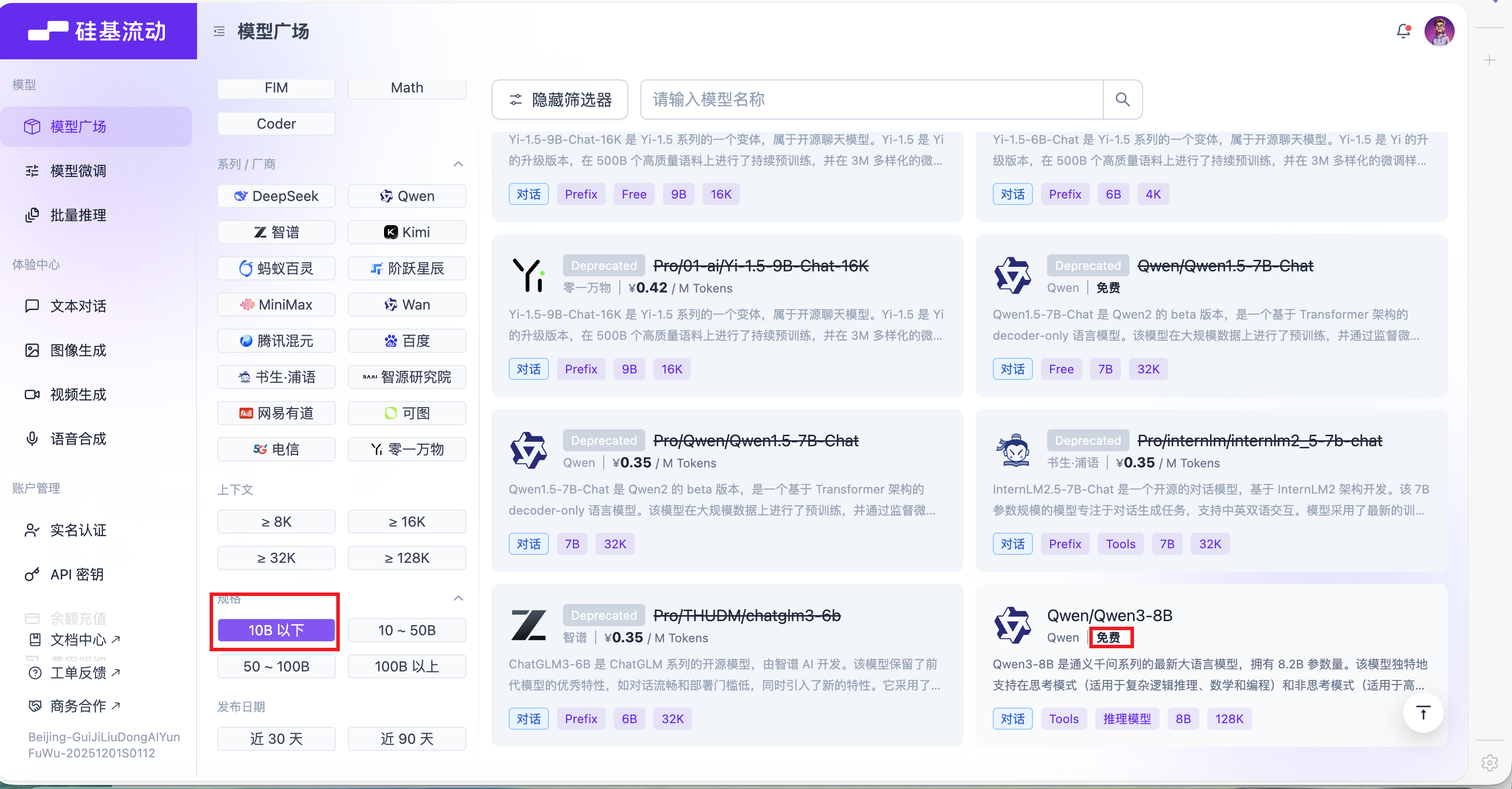
图1.5 硅基流动免费模型
2. 代码实战QuickStart
到了这一步,先恭喜你已经有了自己的LLM(大模型)了,已经迈出了重要的一步。
2.1 环境准备
可以参考笔者之前的文章快速构建AI Agent本地开发环境------Anaconda和uv ,此处就不展开了。
2.2 LangChain QuickStart
简单介绍下LangChain:
- 官网:https://www.langchain.com/
- Github:https://github.com/langchain-ai/langchain
- 官方文档:https://docs.langchain.com/oss/python/langchain/overview
LangChain官方:LangChain is an open source framework with a pre-built agent architecture and integrations for any model or tool --- so you can build agents that adapt as fast as the ecosystem evolves.
翻译翻译就是:
- LangChain是一个开源的标准化框架,旨在简化基于大型语言模型(LLM)的应用程序开发流程;
- 通过提供模块化的组件和工具,将LLM与其他数据源、工具和计算资源无缝连接,使开发者能够更高效地构建复杂AI应用。
发展历程:
- 自2022年10月首次发布以来,LangChain已迅速成为GitHub上增长最快的开源项目之一;
- 2024年1月,LangChain发布首个稳定版本0.1.0;
- 2025年9月,LangChain正式发布v1.0版本,标志着这个曾经被开发者戏称为"玩具框架"的工具包,终于完成了向生产级解决方案的关键一跃建议采用v1.0版本开始,因为v1.0是大改版,和之前的版本就像Python3和Python2的区别,Hadoop2.0和Hadoop1.0的区别,与其说改版,不亚于说重构,所以聪明的你还不直接站在巨人的肩膀上直接v1.0。
- ......
LangChain的核心功能模块包括:
- 模型(Models):提供统一接口调用各种LLM,如Qwen系列,Deepseek系列,OpenAI的GPT系列、Anthropic的Claude系列、Google的Gemini系列,以及Hugging Face的开源模型;
- 提示(Prompts):优化模型输入,提升生成结果的质量,包括PromptTemplate、ChatPromptTemplate和FewShotPromptTemplate等;
- 链(Chains):封装多个组件的调用序列,创建复杂的工作流程,如SimpleSequentialChain等;
- 代理(Agents):允许模型自主调用外部工具和组件,实现多步骤任务处理,如AutoGPT和BabyAGI;
- 记忆(Memory):存储和检索对话数据,支持上下文感知的应用,如多轮对话系统;
- 索引(Indexes):组织和检索文档数据,支持RAG(检索增强生成)等应用场景。
- ......
接下来到了又到了大家最喜欢的手搓AI Agent环节。
- 在构建好了本地开发环境后,可以用uv快速初始化你的第一个AI Agent项目,然后用Pycharm加载你的项目,结果如下图2.1;
shell
╰─$ uv init my-ai-agent
图2.1 在Pycharm里面加载初始化的Agent项目
也可以用tree命名查看下当前初始化项目的目录文件分布;
shell
╰─$ tree
.
├── README.md
├── main.py
├── pyproject.toml
└── uv.lock为了让项目树(通常说的脚手架)看起来更顺眼一些,可以加一些文件夹,建一些文件,改造后的项目树如下图2.2;
图2.2 更改后的项目树
shell
╰─$ tree
my-ai-agent # 项目名
├── README.md # 项目介绍
├── agents # 写Agent的文件夹
│ ├── langchain # langchain的快速实现文件夹
│ │ └── first_agent.py # langchain的快速实现具体代码
│ └── langgraph # langgraph的快速实现文件夹
│ │ └── first_agent.py # langgraph的快速实现具体代码
├── config.py # 配置文件,和环境变量文件.env联动
├── main.py # uv初始化项目自带main,一般用不上,留资做个纪念吧
├── overview.py # 用来在控制台打印引用的模型,一些环境变量看看是否正确引用了
├── pyproject.toml # 当前项目依赖的包
├── tools # 存储工具的文件夹
│ └── weather_tool.py # 自定一个天气的工具
└── uv.lock # uv引用包的具体描述- 配置环境变量,此处以本地的Ollama模型为例,环境变量文件
.env写入内容如下,恭喜你不用一分钱先白嫖好内部模型和外部模型;
shell
# ============================================================================
# MODEL CONFIGURATION
# ============================================================================
# Default model for all agents
# Examples: "anthropic:claude-haiku-4-5", "openai:gpt-4o-mini", "openai:gpt-4o"
# Can be overridden per-agent in factory functions
# 恭喜你不用一分钱先白嫖好内部模型和外部模型
LOCAL_MODEL="ollama:qwen3:4b" # 自己本地的Ollama模型
EXTERNAL_MODEL="openai:Qwen/Qwen3-8B" # 白嫖的硅基流动在线外部模型,这里注意下,如果初始化模型用init_chat_model(),他会根据"openai: "自己主动去Mapping 下面的配置项OPENAI_API_KEY和OPENAI_BASE_URL,非常丝滑
# If using OpenAI with siliconf
OPENAI_API_KEY="sk-XXX" # 需要自己注册硅基流动网站并且获取key,配置的前缀"OPEN_"会被初始化模型用init_chat_model()根据模型的"openai: "自动引用
OPENAI_BASE_URL="https://api.siliconflow.cn/v1" # 硅基流动在线网址,配置的前缀"OPEN_"会被初始化模型用init_chat_model()根据模型的"openai: "自动引用- 编写
config.py文件,该文件的作用是更好的引用环境变量,注音用到的包要先uv add XXX上,不要用pip,恶习改掉,pip是全局生效,uv是当前项目生效,而且可以配合uv sync等命名,uv add完可以查看项目的pyproject.toml文件变化;
shell
╰─$ uv add dotenv config.py文件内容如下
python
"""
Workshop-wide configuration for the AI Engineering Lifecycle workshop.
All default settings can be customized via environment variables in .env file.
This makes it easy to adapt the workshop for different:
- Model providers (OpenAI, Anthropic, Azure, etc.)
- Model versions (GPT-4, Claude Sonnet, etc.)
- Performance profiles (fast models vs. high-quality models)
"""
import os
from pathlib import Path
from dotenv import load_dotenv
load_dotenv() # 加载环境变量文件.env
# ============================================================================
# MODEL CONFIGURATION
# ============================================================================
# Primary model used by all agents throughout the workshop
# Set WORKSHOP_MODEL in .env to change the model for all sections
# Examples:
# - "anthropic:claude-haiku-4-5" (fast, cost-effective)
# - "anthropic:claude-sonnet-4" (balanced)
# - "openai:gpt-4o-mini" (fast, OpenAI)
# - "openai:gpt-4o" (high-quality, OpenAI)
# DEFAULT_MODEL = os.getenv("LOCAL_MODEL", "anthropic:claude-haiku-4-5") # 获取默认模型为环境变量中的本地Ollama模型模型
DEFAULT_MODEL = os.getenv("EXTERNAL_MODEL", "anthropic:claude-haiku-4-5") # 获取默认模型为环境变量中的外部硅基流动免费模型- 编写
overview.py,该文件为可选,主要用来在控制台打印一些变量,供编程者查看,代码和运行的输出如下;
python
from dotenv import load_dotenv
from config import DEFAULT_MODEL
load_dotenv()
if __name__ == '__main__':
print(f"Using model: {DEFAULT_MODEL}")
shell
Using model: openai:Qwen/Qwen3-8B
Process finished with exit code 0- 编写一个自定义的工具类,正常的业务项目工具类是带业务逻辑的,或者直接引用MCP服务器客户端调工具,此处仅为了说明LLM具有调用工具的能力问题,自定义一个工具类,tools文件夹下
weather_tool.py的内容如下;
python
def get_weather(city: str) -> str:
"""Get weather for a given city."""
return f"总是晴天,因为有你热情如火~ {city}!"- 编写第一个langchain agent,记得先把需要的包
uv add XXX上;
shell
╰─$ uv add langchain-openai
╰─$ uv add langchain-ollama
╰─$ uv add langchainlangchain/first_agent.py文件内容如下;
python
from langchain.agents import create_agent
from langchain.chat_models import init_chat_model
from dotenv import load_dotenv
from config import DEFAULT_MODEL
from tools import weather_tool
load_dotenv()
# Initialize the model
llm = init_chat_model(DEFAULT_MODEL)
# Create agent with database tools
db_tools = [weather_tool.get_weather]
# create_agent
agent = create_agent(
model=llm,
tools=db_tools,
system_prompt="You are a helpful assistant.",
)
if __name__ == '__main__':
# 试着调用工具查天气
result = agent.invoke(
{"messages": [{"role": "user", "content": "上海天气?"}]}
)
for message in result["messages"]:
message.pretty_print()运行结果如下,恭喜你得到了你的第一个基于langchain框架的agent;
shell
================================ Human Message =================================
上海天气?
================================== Ai Message ==================================
Tool Calls:
get_weather (019b69d93d08bba04caa8dde2b3084ad)
Call ID: 019b69d93d08bba04caa8dde2b3084ad
Args:
city: 上海
================================= Tool Message =================================
Name: get_weather
总是晴天,因为有你热情如火~ 上海!
================================== Ai Message ==================================
上海的天气总是晴朗,因为有你热情如火~ ☀️ 上海!到这里,恭喜你已经有一个可以哄你开心的查天气的AI Agent了,关于AI Agent很重要的可观测性和可监控性配置,参考本文的LangSmith QuickStart这一章节,效果如下图2.3,接下来更多LangChain的应用等着你来解锁,如各种神奇的中间件,结构化输出,MCP等等,此处由于篇幅问题,笔者有机会将在后续文章更新。
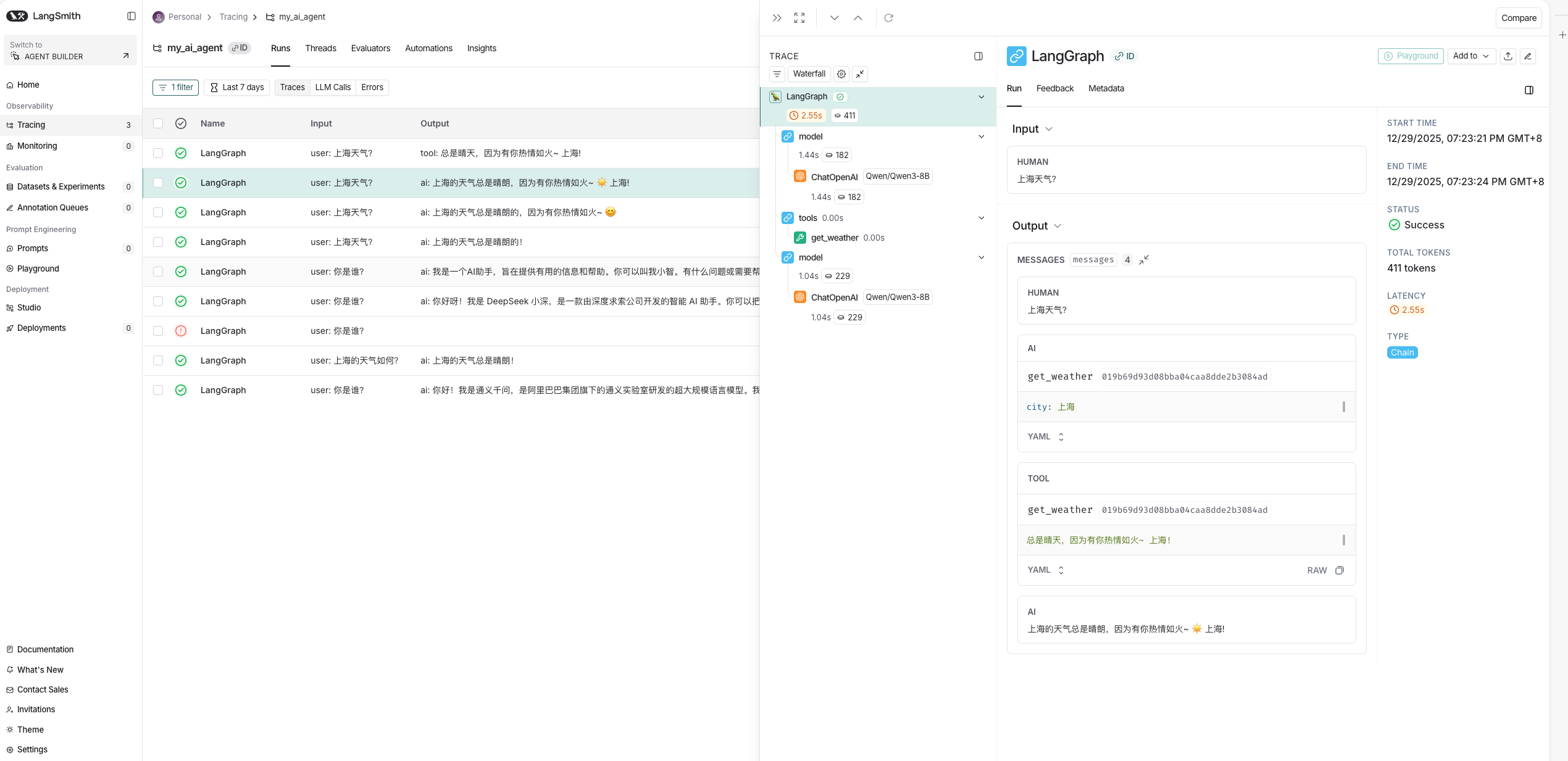
图2.3 LangChain在LangSmith的可观测性
2.3 LangGraph QuickStart
LangGraph同样是LangChain生态的一员,相比于LangChain的相对的线性执行任务,LangGraph支持将执行的任务抽象成一个由节点(Node)、边(Edge)、状态(State)构成的有向循环图(DCG,Directed Cyclic Graph),不仅赋予了极大的灵活性,也能轻松的应对单一和多智能体的复杂AI应用场景,要注意的是,LangChain和LangGraph并非相互替代的关系,而是互补共生的关系,LangChain提供了基础组件,LangGraph侧重更高级的编排架构,所以开发者应该灵活选择或组合使用,但是笔者个人建议如果能用LangChain实现的功能,会建议可以优先使用LangChain实现,学习步骤也建议优先学习LangChain,LangGraph的抽象架构图如图2.4。
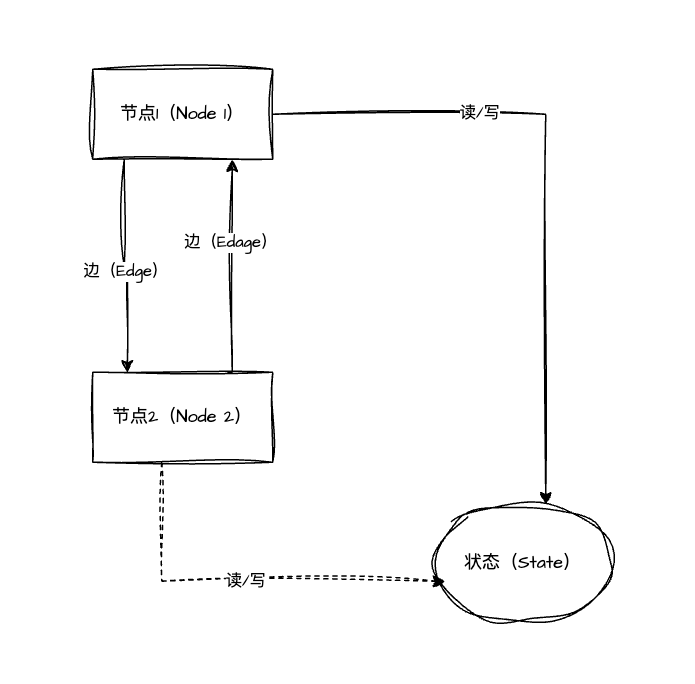
图2.4 LangGraph抽象架构
LangGraph 有三个最核心的概念,分别是:状态(State)、节点(Node)和 边(Edge),对这几个概念的具体理解如下:
- State:状态,其中记录了智能体运行过程中的所有信息,涵盖输入数据、中间计算结果和最终输出,为智能体的持续运行提供上下文。状态内的参数可以在多个节点间保存和流转,是节点间通信的核心机制;
- Node:节点,它是构成 LangGraph 的基本单元。每个 Node 可实现特定功能,例如数据处理、逻辑判断或调用外部 API,常见的节点有大模型调用节点,工具调用节点,自定义函数节点,子图节点等;
- Edge :边,定义了节点之间的连接和数据流向,决定了整个AI Agent应用的工作流执行顺序和逻辑。支持普通边,条件边,入口点,条件入口点。
更多详细介绍,可参考LangGraph的官方文档。
接下来到了又到了大家最喜欢的通过LangGraph手搓AI Agent环节,同样的哄你开心的查天气的AI Agent,笔者用LangGraph实现一遍。
- 只需要在原项目的基础上,先
uv add langgraph;
shell
╰─$ uv add langgraph- 接下来在langgraph文件夹下添加文件
first_agent.py,内容如下;
python
from tools import weather_tool
from langchain.chat_models import init_chat_model
from langgraph.prebuilt import ToolNode # 导入ToolNode 用于封装工具节点
from config import DEFAULT_MODEL
from langgraph.graph import END,START,MessagesState,StateGraph
# 定义工具节点
tools=[weather_tool.get_weather]
tool_node=ToolNode(tools)
# 初始化模型节点并绑定工具
model = init_chat_model(DEFAULT_MODEL).bind_tools(tools)
# 定义agent执行函数call_model,也就是需要模型做什么
def call_model(state):
message=state['messages']
response=model.invoke(message)
return {"messages":[response]}
# 定义状态结构体,为了简单,就用LangGraph自带的MessageState
workflow=StateGraph(MessagesState)
workflow.add_node("agent",call_model)
workflow.add_node("tools",tool_node)
workflow.add_edge(START,"agent")
workflow.add_edge("agent","tools")
workflow.add_edge("tools",END)
graph=workflow.compile()
if __name__ == '__main__':
result=graph.invoke({"messages":[{"role":"user","content":"上海天气?"}]})
for message in result["messages"]:
message.pretty_print()输出结果如下;
shell
================================ Human Message =================================
上海天气?
================================== Ai Message ==================================
Tool Calls:
get_weather (019b69f9d009ef87176c1c4bcdeaa3c8)
Call ID: 019b69f9d009ef87176c1c4bcdeaa3c8
Args:
city: 上海
================================= Tool Message =================================
Name: get_weather
总是晴天,因为有你热情如火~ 上海!
Process finished with exit code 0- 同样可以再LangSmith上查看到该LangGraph的可观测性,如图2.5。
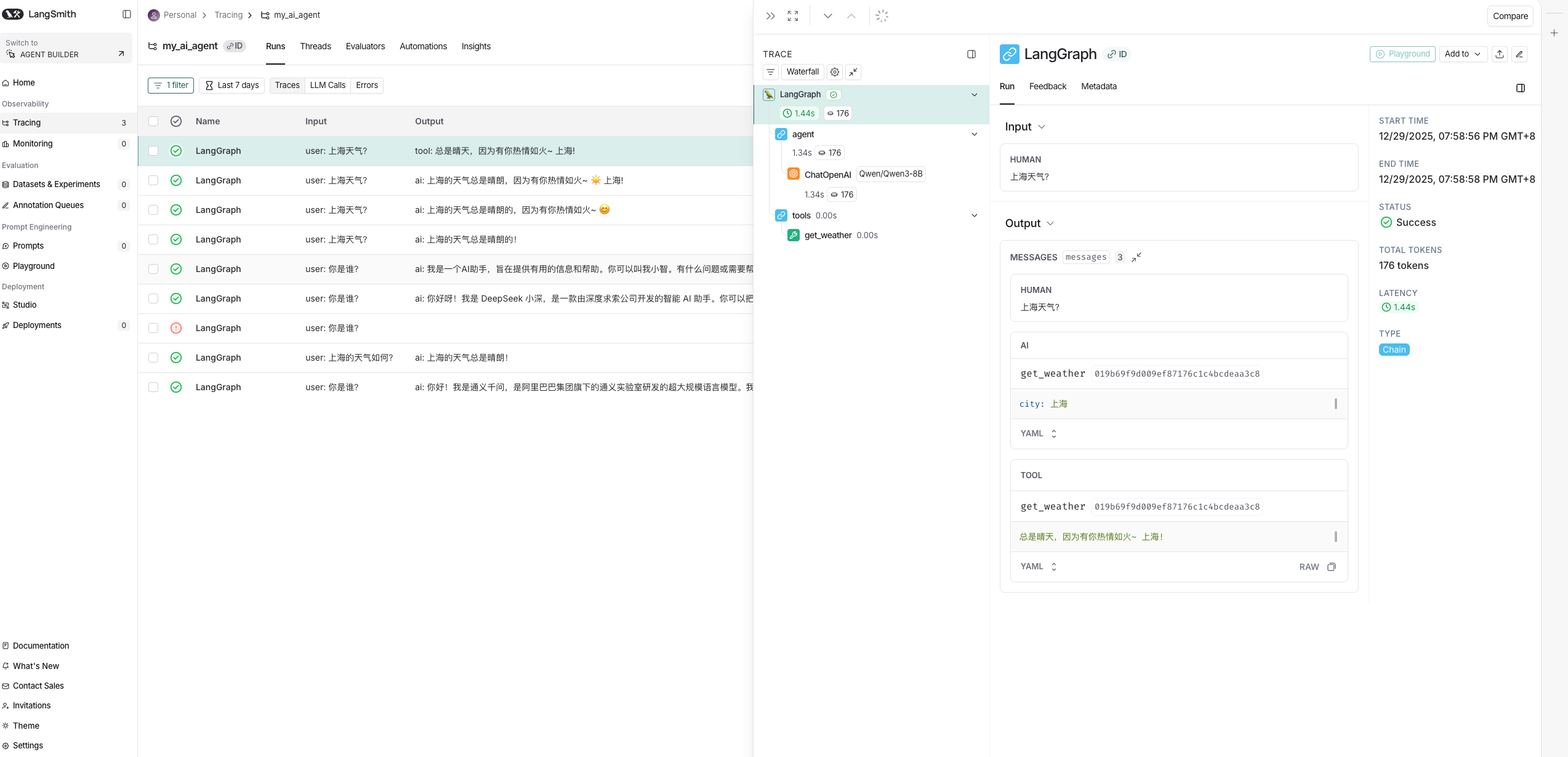
图2.5 LangGraph的可观测性
到这里,恭喜你用LangGraph复现了一个可以哄你开心的查天气的AI Agent了,接下来更多LangGraph的应用等着你来解锁,如人机环路协作,设计模式等等,此处由于篇幅问题,笔者有机会将在后续文章更新。
2.4 LangSmith QuickStart
简单介绍下LangSmith,其也是LangChain生态的框架,主要解决AI Agent开发和部署上的可观测性以及Debug,如果读者玩过埋点(Event-Tracking)的话,就非常好理解这玩意了,其实就是内嵌的一套埋点系统,把关键的事件和数据都追踪下来,再给一个Web端的平台呈现,供开发者使用,LangSmith集成LangChain和LangGraph非常丝滑,真正的做到了有手就行,缺点就是这个玩意国内网络访问受限,你需要用到"科学上网"的方式,比如穿墙术;第二就是LangSmith企业版收费,这样也是开源社区营业的老规矩了,开发的框架你随便用,到了企业的Server端,嘿嘿,他要收网了(We need your money!),但是也不必过于灰心,此时此景,总有将开源进行到底的活雷锋,因此平替也就诞生了,如支持本地部署的开源产品LangFuse和Aegra等。
- LangSmith官方文档:https://docs.langchain.com/langsmith/home
LangSmith provides tools for developing, debugging, and deploying LLM applications. It helps you trace requests, evaluate outputs, test prompts, and manage deployments in one place. LangSmith is framework agnostic, so you can use it with or without LangChain's open-source libraries
langchainandlanggraph. Prototype locally, then move to production with integrated monitoring and evaluation to build more reliable AI systems.
接下来又到了大家最喜欢的手搓LangSmith可观测性环节;
-
用科学上网的方式,比如穿墙术去注册一个LangSmith账号,然后登录;
- 官方注册网站:https://smith.langchain.com/
-
登录后看到LangSmith的主界面如图2.6;
图2.6 LangSmith主界面
- 从右下角的
settings进入,去创建属于你的独一无二的LangSmith的API Keys,如图2.7;
图2.7 LangSmith创建API Keys
- 还记得你的项目
my-ai-agent的.env文件吗,没错,将你的API Keys添加到到这里,参考如下;
shell
# ============================================================================
# LANGSMITH CONFIGURATION
# ============================================================================
# Optional for LangSmith tracing and experiment tracking
LANGSMITH_TRACING="true" # 表示打开在LangSmith上的可观测性,一定需要
LANGSMITH_PROJECT="my_ai_agent" # 给你可观测性的项目起个名字
LANGSMITH_API_KEY="lsv2_pt_XXX" # 需要自己注册补全LangSmith的key,注册LangSmith账号获取key- 配置好以后再启动的项目,其他的什么都不用做了,就是如此丝滑,你就可以看到在LangSmith主界面的
Tracking菜单栏上该项目的可观测性了,可以清楚的看到你的AI Agent用的什么模型,是否调用了工具,总耗时多少,每一步的耗时多少,总Token(词元)消耗多少?每一步的Token(词元)消耗多少?每一步的输入,输出是什么等等;因此也就很清晰的就能知道哪一步需要优化耗时,哪一步需要优化Token等,具体如图2.8。
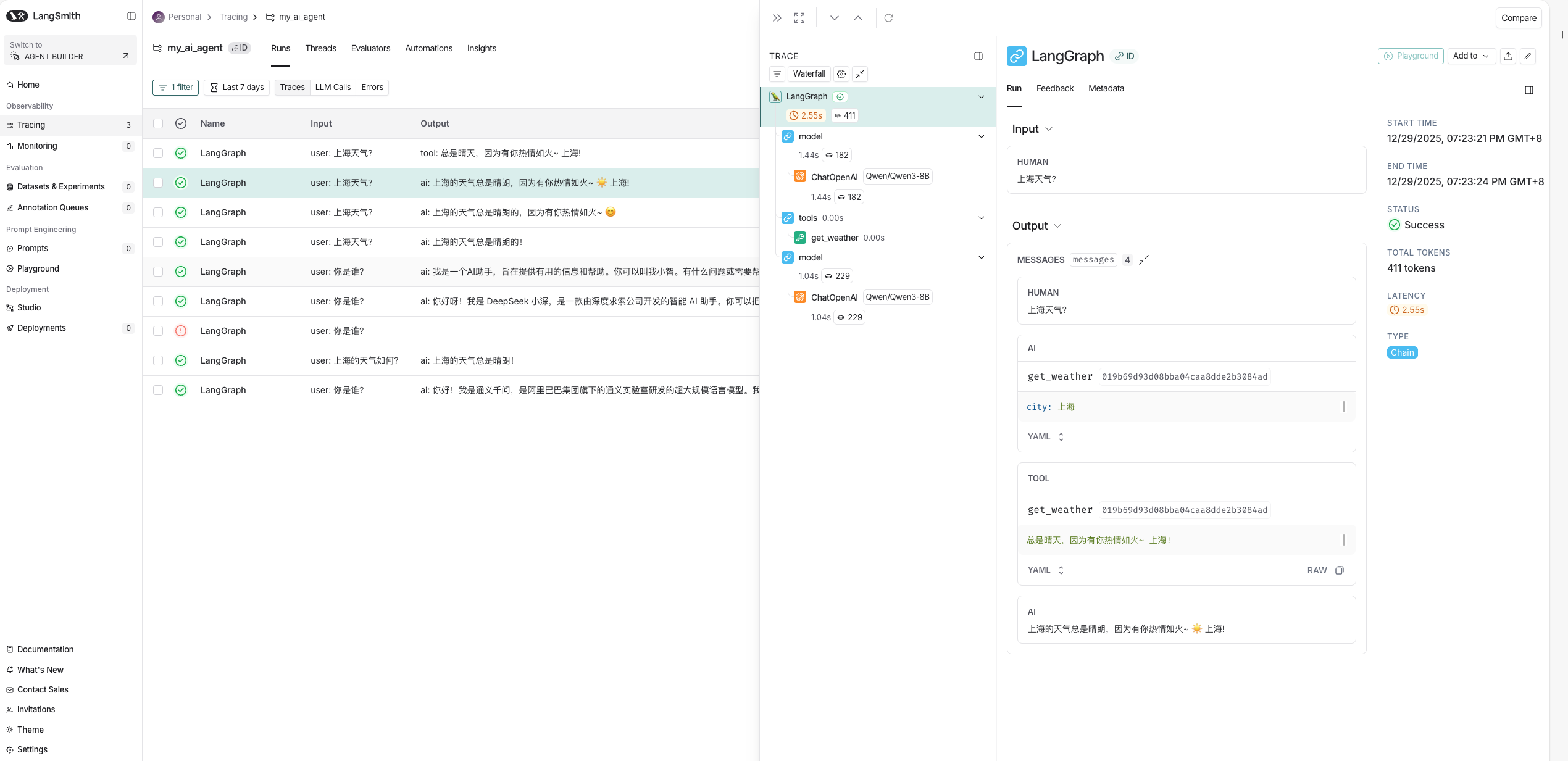
图2.8 LangSmith的Tracking明细
到这里,你就完成了你的AI Agent在LangSmith上的可观测性,但是需要注意的是LangSmith还是把观测的数据上传到了外网,学习可以,如果是企业真实应用,一定要得到企业法律和合规部门的允许;LangSmith本身支持自托管服务(自己部署在Docker或K8s上),但自托管LangSmith是为对安全性和可控性有高要求的大型客户设计的企业计划功能,通常需要联系销售团队获取许可证密钥(LangSmith needs your money)。
什么?不会科学上网?也没有许可证?行吧,那看在少侠你骨骼惊奇的份上,就在教你一招能在本地部署的LangFuse QuickStart,也就是LangSmith的平替产品。
2.5 LangFuse QuickStart
- 首先本地下载个orbstack,orbstack天然支持docker,后续将用docker来启动LangFuse;
- 然后有手就行的安装上,并打开,在orbstack的
settings上将docker的镜像站点改成国内的加速站点。如图2.9;
shell
{
"registry-mirrors" : [
"https:\/\/docker.domys.cc",
"https:\/\/hub.domys.cc",
"https:\/\/docker.m.daocloud.io",
"https:\/\/docker.xuanyuan.me",
"https:\/\/docker.1ms.run",
"https:\/\/docker.aityp.com\/"
],
"dns" : [
"8.8.8.8",
"1.1.1.1"
]
}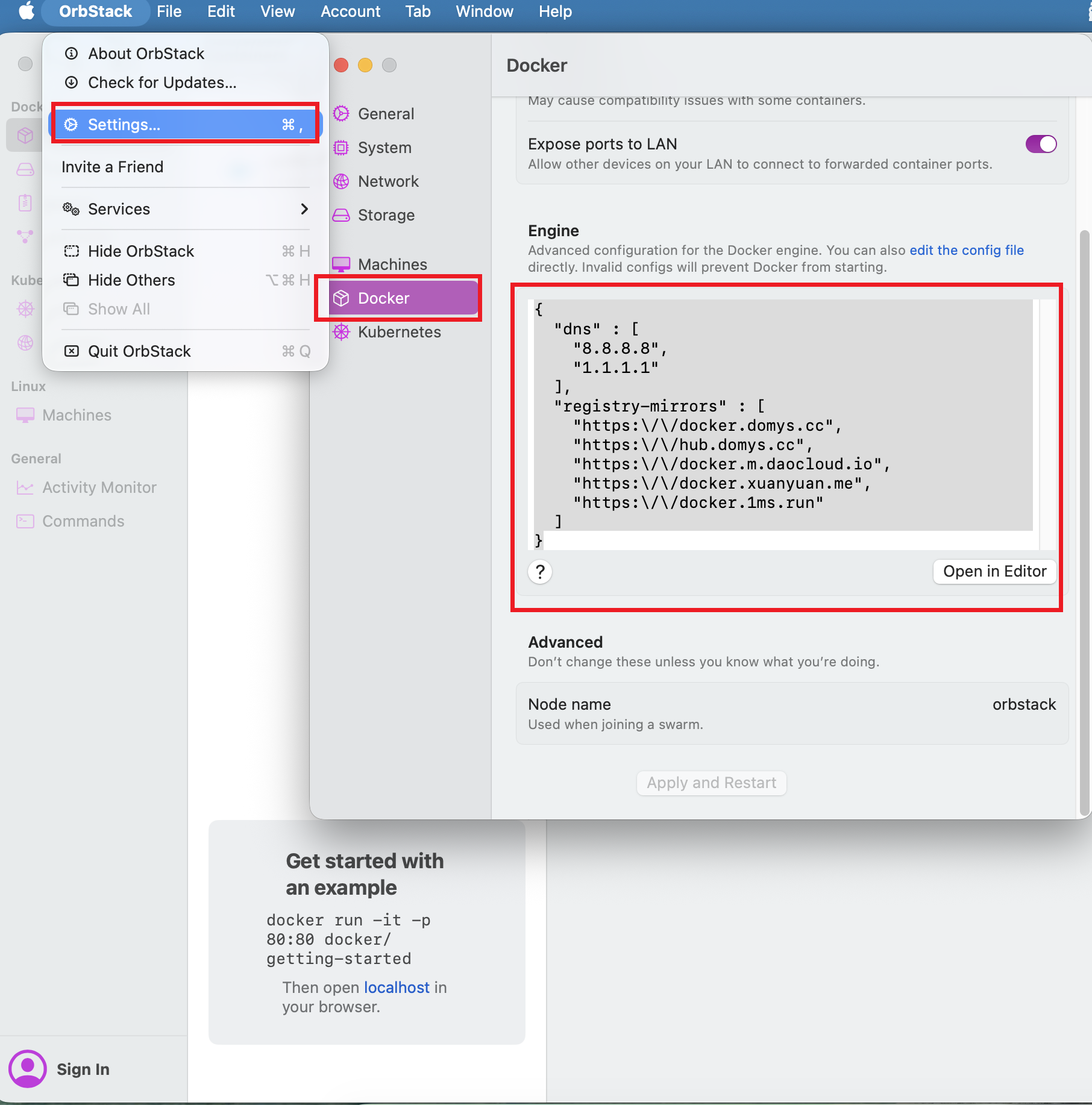
图2.9 修改orbstack的docker的加速站点
- 重启
orbstack软件,注意一定要quit后再重启,不是最小化隐藏; - github下载LangFuse代码,并用docker启动;
shell
git clone https://github.com/langfuse/langfuse.git
cd langfuse
# Get a copy of the latest Langfuse repository
git clone https://github.com/langfuse/langfuse.git
cd langfuse
# Run the langfuse docker compose
docker compose up
[+] Running 29/66
⠇ clickhouse [⠀⠀⣿⠀⠀⠀⠀⠀⠀] Pulling 31.8s
⠇ langfuse-worker [⣿⣿⣿⣿⣿⣄⣿⣿⠀⠀⠀⠀⠀⠀⠀] Pulling 31.8s
⠇ postgres [⣿⣿⣿⣿⣿⣿⣿⣿⣄⣿⣿⣿⣿⣿] 46.94MB / 110.9MB Pulling 31.8s
⠇ redis [⠀⠀⠀⠀⠀⠀⠀] Pulling 31.8s
⠇ langfuse-web [⣿⣿⣿⣿⣿⣿⣿⣿⡀⠀⠀⠀⠀⠀⠀⠀] Pulling- 需要点时间,等所有的镜像文件安装好,就可以启动了,默认是访问localhost:3000,如图2.10,然后类似在右下角的
settings->API Keys->Create new API keys获取得到LangFuse的API Keys;
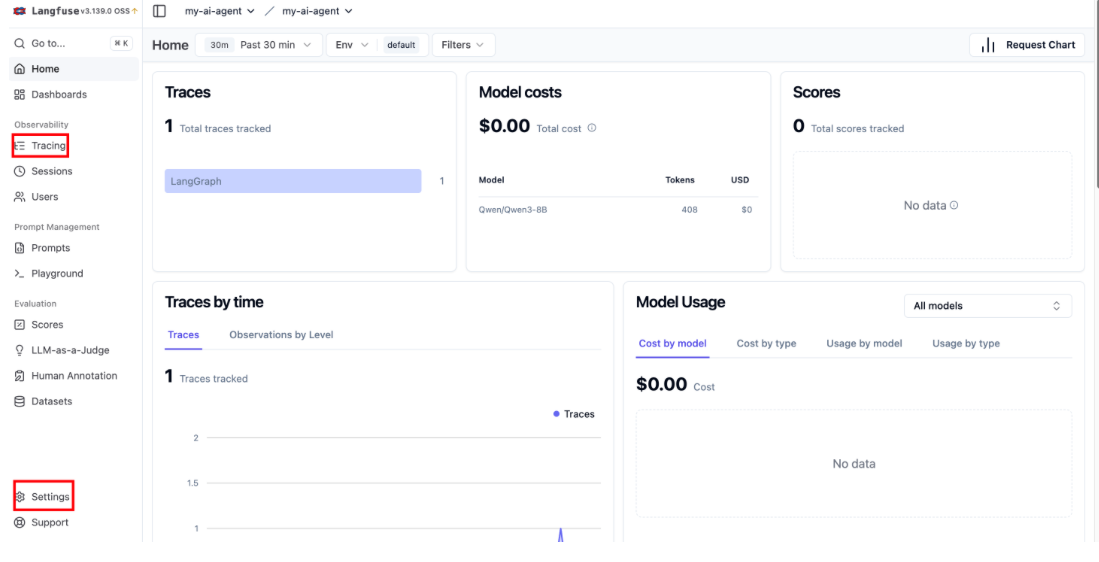
图2.10 LangFuse首页
- 同样在项目
my-ai-agent的.env文件上类似LangSmith添加上LangFuse的配置信息;
shell
# ============================================================================
# LANGFUSE CONFIGURATION
# ============================================================================
LANGFUSE_SECRET_KEY="sk-lf-XXX"
LANGFUSE_PUBLIC_KEY="pk-lf-XXX"
LANGFUSE_BASE_URL="http://localhost:3000"- 先在该项目下
uv add langfuse;
shell
╰─$ uv add langfuse - 在需要
agent.invoke或graph.invoke的脚本如first_agent.py添加以下import和config即可完成LangFuse的配置,已经用注释# LangFuse相关标记出;
python
from langchain.agents import create_agent
from langchain.chat_models import init_chat_model
from dotenv import load_dotenv
from config import DEFAULT_MODEL
from tools import weather_tool
from langfuse import get_client # LangFuse相关包
from langfuse.langchain import CallbackHandler # LangFuse相关包
load_dotenv()
# Initialize Langfuse client LangFuse相关
langfuse = get_client() # LangFuse相关
# Initialize Langfuse CallbackHandler for Langchain (tracing) LangFuse相关
langfuse_handler = CallbackHandler() # LangFuse相关
# Initialize the model
llm = init_chat_model(DEFAULT_MODEL)
# Create agent with database tools
db_tools = [weather_tool.get_weather]
agent = create_agent(
model=llm,
tools=db_tools,
system_prompt="You are a helpful assistant.",
)
if __name__ == '__main__':
# 试着调用工具查天气
result = agent.invoke(
{"messages": [{"role": "user", "content": "上海天气?"}]},
config={"callbacks": [langfuse_handler]} # LangFuse相关
)
for message in result["messages"]:
message.pretty_print()- 最后得到LangFuse的可观测性效果如图2.11,你会发现在样式上不能说和LangSmith很像,简直就是孪生兄弟,最重要的是LangFuse免费,也不需要会穿墙术,就问你香不香。
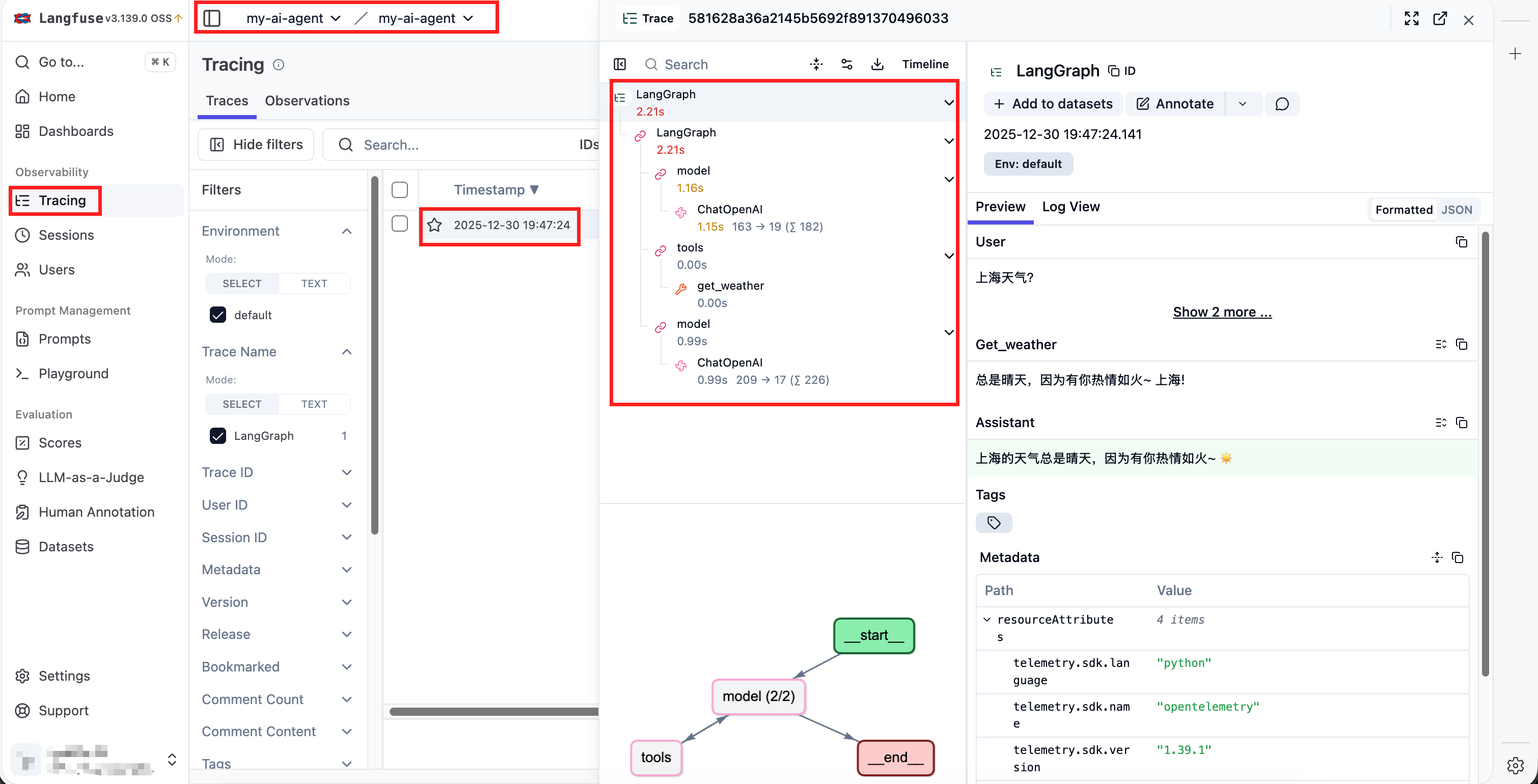
图2.11 LangFuse的可观测性效果
以上就是AI Agent开发实战的QuickStart,总结下来就是你不仅白嫖到了LLM,还学会了手搓第一个使用LangChain和LangGraph的AI Agent,并且还可以选择需要用穿墙术的LangSmith或白嫖的LangFuse完成对AI Agent的可观测性,看完还不学起来并邀请你的热爱AI的宝子一起来学?