RLHF 是一种特殊的强化学习,它使用与经典强化学习相同的数学框架,但核心却截然不同。
让我们先从"奖励"的区别说起。
在普通的强化学习中:智能体与环境交互。每一步,它都会执行一个动作 a_t,获得一个奖励 r_t,并更新其策略以最大化预期的未来奖励。奖励信号内置于环境中,例如,游戏得分、机器人与目标的距离,或明确的成功/失败衡量标准。
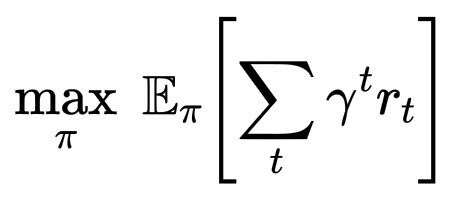
\max_\pi \; \mathbb{E}_\pi\left\\sum_t \\gamma\^t r_t\\right
在基于人类反馈的强化学习 (RLHF) 中:没有自然的奖励函数,模型不会玩游戏或赢得积分。相反,人类会提供偏好反馈。假设给定两个响应:响应 A 和 响应 B。人类会标记哪个响应感觉更好:更有帮助、更无害或更诚实。
通过这些比较,一个奖励模型 R_\phi(x, y) 被训练来预测人类的偏好。然后,大模型的"策略",也就是模型生成响应的方式会被优化,以最大化这个学习到的奖励函数,而不是外部的奖励函数。
微调仍然使用强化学习算法,通常是 PPO(近端策略优化,需要奖励模型,代价比较高)或是 DRPO(直接策略优化,快速经济的方案), 来更新模型的权重。PPO优化目标为:
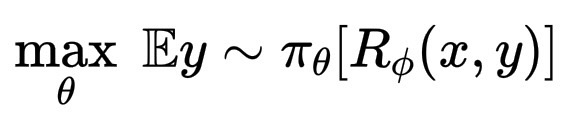
\max_\theta \; \mathbb{E}{y \sim \pi_\theta}R_\\phi(x, y)
但在这里,R_\phi 代表的是人类的价值观,而不是世界上的客观数字。