文章目录
-
- 一、序章:性能优化的导火索
- [二、JVM 的"战场":GC 的真实面貌](#二、JVM 的“战场”:GC 的真实面貌)
-
- [JVM 堆结构示意图](#JVM 堆结构示意图)
- 三、故事的起点:一次看似"正确"的优化
- [四、G1 的"反击":内卷的开始](#四、G1 的“反击”:内卷的开始)
-
- [🔍 为什么会这样?](#🔍 为什么会这样?)
- [五、分析日志:GC 成为瓶颈的那一刻](#五、分析日志:GC 成为瓶颈的那一刻)
- 六、第二次优化:与内存模型"正面交锋"
-
- [🧩 问题点:](#🧩 问题点:)
- [🎯 三层次优化策略:](#🎯 三层次优化策略:)
-
- [1. 对象池化](#1. 对象池化)
- [2. 减少临时集合创建](#2. 减少临时集合创建)
- [3. 收集器切换与参数优化](#3. 收集器切换与参数优化)
- [七、内卷的终局:从 GC 调优到内存治理](#七、内卷的终局:从 GC 调优到内存治理)
- [八、经验总结:五条 JVM 调优"军规"](#八、经验总结:五条 JVM 调优“军规”)
- [九、后记:JVM 的"内卷"其实是一种进化](#九、后记:JVM 的“内卷”其实是一种进化)
- 十、结语:优化的尽头,是理解
博主介绍:全网粉丝10w+、CSDN合伙人、华为云特邀云享专家,阿里云专家博主、星级博主,51cto明日之星,热爱技术和分享、专注于Java技术领域
🍅文末获取源码联系🍅
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
🧠 "GC 不是问题,问题是当我们以为调优能救命时,GC 已经开始反抗。"------来自一次真实的线上事故复盘
一、序章:性能优化的导火索
项目上线三个月后,我们发现系统响应时间逐渐变慢。
最初只是个别接口的延迟,后来几乎所有请求的 P99 响应时间 都飙升到 2 秒以上。
监控图上,CPU 占用高企、Full GC 次数暴增,堆内存像心电图一样上下波动。
业务方一句话:"是不是 JVM 又在搞事情?"
而我知道,这背后不是一句"调大堆"就能解决的。
⚡ 我们决定------动手优化。
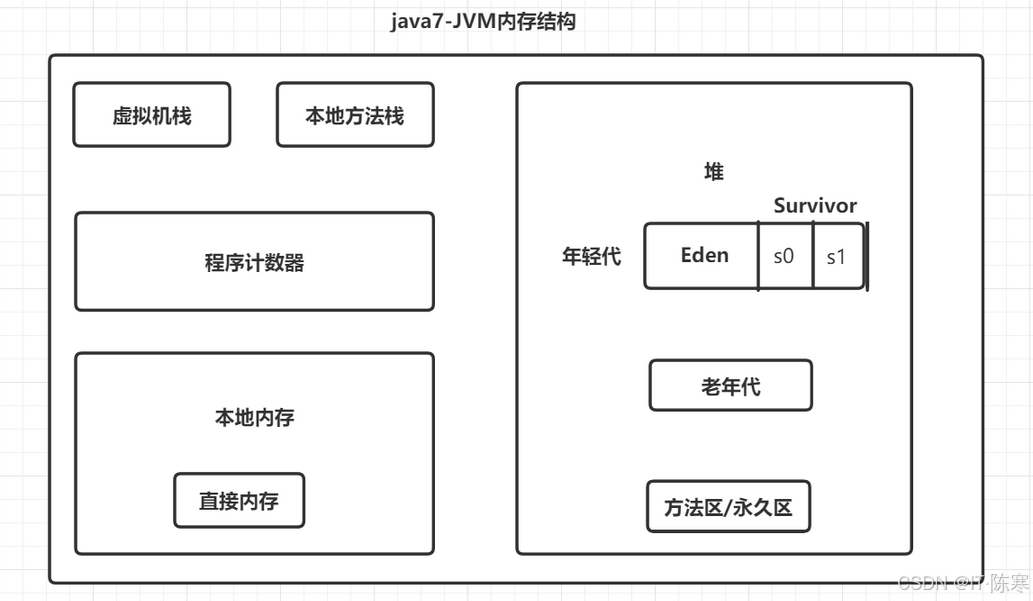
二、JVM 的"战场":GC 的真实面貌
JVM 的 GC 机制并不是"定时打扫卫生",而是一个分代、分阶段、分策略的 多线程调度系统。
JVM 堆结构示意图
+--------------------+
| 新生代 Young | -> 频繁创建与销毁对象的战场
| +----+---+---+ |
| |Eden|S0 |S1 | |
+--------------------+
| 老年代 Old | -> 存放长寿命对象
+--------------------+
| 元空间 Meta | -> 存放类元数据
+--------------------+每一次 GC,其实都是 JVM 对内存压力的一次自我修正。
然而,当我们人为干预"优化"时,JVM 也会用它的方式------反击。
三、故事的起点:一次看似"正确"的优化
系统采用 Spring Boot + MySQL + K8s 架构。
我们最初定位到某个 JSON 解析逻辑在每次请求中会创建大量临时对象(约 2 万个)。
于是,我们的第一步优化是"看似合理"的:
bash
-Xms2g -Xmx6g
-XX:+UseG1GC
-XX:MaxGCPauseMillis=200
-XX:+ParallelRefProcEnabled上线后,GC 次数显著下降。
但一周后,响应时间再次暴涨,甚至比之前更严重。
四、G1 的"反击":内卷的开始
在监控系统中,我们注意到 G1 GC 日志中频繁出现:
GC pause (G1 Evacuation Pause) (mixed)平均停顿时间 > 500ms,而堆内存并未打满。
问题不是 GC 太多,而是 G1 自己卷起来了。
🔍 为什么会这样?
G1(Garbage First)采用"按收益回收"的策略,将堆划分为若干 Region(默认 2048 个)。
当堆扩大后:
- Region 数量倍增;
- 标记与整理的开销增加;
- JVM 花更多时间思考该"先收谁"。
🧩 我们给了它更大的操场,它反而花更多时间打扫卫生。
五、分析日志:GC 成为瓶颈的那一刻
开启详细 GC 日志:
bash
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintAdaptiveSizePolicy
-Xloggc:/var/log/gc.log部分日志如下:
[2025-10-18T14:21:07.765+0800][info][gc] GC pause (G1 Evacuation Pause) (mixed), 0.5433457 secs
[2025-10-18T14:21:08.309+0800][info][gc,heap] Heap: 6144M(6144M)->6012M(6144M)含义是:
- GC 释放了内存,但花了太久;
- 停顿时间超出设定的 200ms;
- 频繁的 "Evacuation Pause" 表示晋升/复制过多。
进一步通过 jstat -gcutil <pid> 5s 发现:
- Eden 区频繁清空;
- Survivor 区过小;
- 老年代 占比不断上升。
调大堆的结果反而是对象晋升代价更高。
六、第二次优化:与内存模型"正面交锋"
在堆转储(heap dump)分析后,我们确认了问题根源:
代码层面制造了"GC噪音"。
🧩 问题点:
- 高频创建短生命周期对象(
JSONObject,StringBuilder)。 - 使用
Stream + Lambda带来额外包装开销。 - Jackson 解析 JSON 产生大量中间节点对象。
🎯 三层次优化策略:
1. 对象池化
引入 Fastjson2 并复用 ObjectWriter、ObjectReader 实例,避免重复初始化。
2. 减少临时集合创建
将原有写法:
java
list.stream().map(x -> transform(x)).collect(Collectors.toList());改为:
java
List<Result> results = new ArrayList<>(list.size());
for (Item item : list) {
results.add(transform(item));
}3. 收集器切换与参数优化
我们尝试使用 ZGC 替代 G1:
bash
-XX:+UseZGC
-XX:+AlwaysPreTouch
-XX:SoftMaxHeapSize=4G
-XX:MaxHeapSize=6GZGC 的低延迟特性(平均停顿 <10ms)让系统性能提升约 48%,Full GC 基本消失。
七、内卷的终局:从 GC 调优到内存治理
复盘时我们发现,所谓"GC战争",其实是一次 认知偏差 的战争。
JVM 没有错,我们才是垃圾制造的源头。
| 问题类型 | 后果 | 典型原因 |
|---|---|---|
| 短生命周期对象过多 | GC 频繁 | JSON解析、集合操作 |
| 对象晋升过快 | 老年代膨胀 | Survivor 区过小 |
| 大对象分配频繁 | Full GC 激增 | Byte\[\]、String 拼接 |
| ThreadLocal 泄漏 | 内存无法回收 | 未调用 remove() |
GC 只是"打扫工",真正的优化在于------让房子别太乱。
八、经验总结:五条 JVM 调优"军规"
| 军规 | 内容 | 解释 |
|---|---|---|
| 1. 优先代码优化而非参数调优 | 减少对象创建、控制集合大小 | GC 是结果,问题常在源头 |
| 2. 堆不是越大越好 | 大堆会增加 Region 分析和停顿成本 | 延迟反而上升 |
| 3. 持续监控比一次调优更重要 | 开启 GC 日志、JFR、Prometheus | 量化问题而非猜测 |
| 4. 收集器要匹配场景 | CMS、G1、ZGC 各有边界 | 高并发推荐 G1/ZGC |
| 5. 关注对象生命周期 | 用 VisualVM / MAT 分析堆快照 | 看看谁"活得太久" |
九、后记:JVM 的"内卷"其实是一种进化
当我们抱怨 JVM 太复杂、GC 太难懂时,它其实在默默进化。
从 Serial → CMS → G1 → ZGC → Shenandoah,每一步都在追求 "更聪明的回收"。
而开发者也在与它的博弈中变得更"卷"------
不过这次,我们学会了让 JVM 做它擅长的事。
十、结语:优化的尽头,是理解
性能优化的最高境界,不是参数调到极限,而是理解系统。
当你知道哪些对象该活、哪些该死;
当你能读懂 GC 日志背后的故事;
当你不再害怕 "Full GC" 三个字的红线时------
你就不只是一个 Java 程序员,
而是一个懂 JVM 思维的工程师。
🧩 写在最后:
每一次 GC 日志的跳动,都是 JVM 在向你传递信号。
真正的性能优化,从来不在命令行参数,而在你的每一行代码之间。
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻