1.读取数据类Dataset
Dataset将数据和label进行组织编号0 1 2 3......,使得可以根据编号读取数据;需获取每一个数据及其label以及数据总数 ,要实现 len() 方法和 getitem() 方法。
len() 方法返回数据集的样本数量;getitem() 方法根据给定的索引返回对应的数据样本;
通过继承Dataset类class MyData(Dataset),实现__len__和__getitem__方法,可以自定义自己的数据集类以适应不同的数据源和格式
python
class MyData(Dataset):
#root:根目录 label:标签(ants/bees)
def __init__(self,root_dir,label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path=os.path.join(self.root_dir,self.label_dir)
#os.listdir()获取指定目录下的所有条目
self.img_path=os.listdir(self.path)
def __getitem__(self,idx):
img_name=self.img_path[idx]
img_item_name=os.path.join(self.root_dir,self.label_dir,img_name)
img=Image.open(img_item_name)
label=self.label_dir
return img,label
def __len__(self):
return len(self.img_path)2.TensorBoard使用
(1)add_scalar方法:通常用于记录训练过程中的各种指标,如损失值、准确率等。它将这些数值与对应的步数关联起来,以便后续进行可视化分析
python
def add_scalar(
self,
tag,
scalar_value,
global_step=None,
walltime=None,
new_style=False,
double_precision=False,
):
<font style="color:rgb(163, 21, 21);background-color:rgba(0, 0, 0, 0.1);">tag</font>: 字符串类型,用于标识数据的标签或名称,通常用于在可视化时区分不同的数据曲线<font style="color:rgb(163, 21, 21);background-color:rgba(0, 0, 0, 0.1);">scalar_value</font>: 要记录的标量值,通常是数字<font style="color:rgb(163, 21, 21);background-color:rgba(0, 0, 0, 0.1);">global_step</font>: 可选参数,表示训练的步数或迭代次数,用于x轴的刻度
(2)利用TensorBoard绘制y=x图像
python
from torch.utils.tensorboard import SummaryWriter
#保存的目录路径
writer=SummaryWriter("logs")
#y=x
for i in range(100):
writer.add_scalar("y=x",i,i)
writer.close()(3)启动命令
在终端中输入如下命令
python
tensorboard --logdir=logs #logs是上面指定在writer = SummaryWriter("logs")中指定的文件夹名,日志文件存储在此文件中(4)add_image方法:将图像数据添加到TensorBoard日志中
python
def add_image(
self, tag, img_tensor, global_step=None, walltime=None, dataformats="CHW"
):
- tag:图像的标识符,用于在TensorBoard中区分不同的图像
- img_tensor:图像数据,支持torch.Tensor、numpy.ndarray或字符串/blobname格式
- global_step:记录的全局步数,用于时间轴上的定位
- walltime:可选的时间戳,默认使用当前时间
- dataformats:图像数据格式,如CHW(通道-高度-宽度)、HWC等
(5)add_image使用
python
import numpy as np
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
writer=SummaryWriter("logs")
image_path="dataset/train/ants/0013035.jpg"
img_PIL=Image.open(image_path)
#利用numpy将PIL格式转换为numpy数组
img_array=np.array(img_PIL)
print(type(img_array))
print(img_array.shape)
#HWC表示Height(高度)× Width(宽度)× Channels(通道数)
writer.add_image("test",img_array,2,dataformats='HWC')
writer.close()3.Transforms学习
用于对图像进行预处理和数据增强操作,如调整图像大小、中心裁剪、随机裁剪、随机水平翻转、归一化、将 PIL 图像转换为 Tensor 等等
(1)ToTensor()使用:PyTorch的torchvision模块中的一个转换类,它的主要作用是将PIL图像或NumPy数组转换为PyTorch张量
python
#1.创建具体的工具
tensor_trans=transforms.ToTensor()
#2.转换
tensor_img=tensor_trans(img)
writer.add_image("Tensor_img",tensor_img)(2)Normalize: 对图像进行归一化,对每个通道进行归一化
python
trans_norm=transforms.Normalize([3,5,8],[3,2,1])
img_norm=trans_norm(img_tensor)
writer.add_image("Normalize",img_norm,2)(3)Resize()使用:可以处理 PIL 图像对象,也可以处理张量类型的数据
python
trans_resize=transforms.Resize((800,800))
img_resize=trans_resize(img)
img_resize=trans_totensor(img_resize)
writer.add_image("Resize",img_resize,2)(4)Compose()使用: 组合多个图像转换(transform)操作,通过 Compose,可以创建一个转换流程,这个流程可以按顺序执行多个图像处理操作,这些操作可以包括缩放、裁剪、归一化等,其需要的参数是一个列表,其元素类型是transforms类型。
python
trans_resize = transforms.Resize(512)
trans_totensor = transforms.ToTensor()
trans_compose = transforms.Compose([trans_resize,trans_totensor])
img_resize_2 = trans_compose(img)4.Torchvision数据集使用
(1)DataSet使用
python
#将数据集中的每张图片转换为tensor类型
dataset_transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
torch_set=torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=dataset_transform,download=True)
test_set=torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=dataset_transform,download=True)
<font style="color:rgb(163, 21, 21);background-color:rgba(0, 0, 0, 0.1);">root="./dataset"</font>: 指定数据集存储的根目录为当前路径下的"dataset"文件夹<font style="color:rgb(163, 21, 21);background-color:rgba(0, 0, 0, 0.1);">train=True</font>: 表示加载的是训练集(CIFAR-10中有50000张训练图像)<font style="color:rgb(163, 21, 21);background-color:rgba(0, 0, 0, 0.1);">transform=dataset_transform</font>: 对数据应用的预处理/变换操作<font style="color:rgb(163, 21, 21);background-color:rgba(0, 0, 0, 0.1);">download=True</font>: 如果数据集不存在于指定目录,则自动下载
(2)Dataloader使用: PyTorch 提供的数据加载器,用于批量加载数据集。
python
#transform参数指定了数据转换方式
test_data=torchvision.datasets.CIFAR10(root="./dataset",train="False",transform=torchvision.transforms.ToTensor())
test_loader=DataLoader(dataset=test_data,batch_size=4,shuffle=True,num_workers=0,drop_last=False)
img,target=test_data[0]
print(img.shape)
print(target)
for data in test_loader:
imgs,targets=data
print(imgs.shape)
print(targets)
<font style="color:rgb(163, 21, 21);background-color:rgba(0, 0, 0, 0.1);">dataset=test_data</font>:指定要加载的数据集<font style="color:rgb(163, 21, 21);background-color:rgba(0, 0, 0, 0.1);">batch_size=4</font>:每个批次包含4个样本<font style="color:rgb(163, 21, 21);background-color:rgba(0, 0, 0, 0.1);">shuffle=True</font>:在每个epoch开始时打乱数据顺序<font style="color:rgb(163, 21, 21);background-color:rgba(0, 0, 0, 0.1);">drop_last=False</font>:如果最后一批数据小于batch_size,仍然保留
5.神经网络基本骨架nn.Moduel使用
对于定义的模型都需要集成Moduel类,实现__init__和forward函数
python
class Module(nn.Module):
def __init__(self) :
super().__init__()
def forward(self,input):
output=input+1
return output
module=Module()
x=torch.tensor(1.0)
output=module(x)
print(output)当调用一个 nn.Module 的实例时,例如 module(x),PyTorch 会自动触发该实例的 forward 方法。这是因为 nn.Module 类在 Python 中被视为一个可调用对象,这是通过在 nn.Module 类中实现特殊方法__call__()来实现的。
call 方法在 nn.Module 中被定义为调用 forward 方法的包装器,像函数一样调用一个 nn.Module 实例时,实际上是在执行 forward 方法,并将传入的参数(在这个例子中是 x)作为输入传递给 forward 方法
6.卷积层的使用
python
dataset=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),
download=True)
dataloader=DataLoader(dataset,batch_size=64)
class Module(nn.Module):
def __init__(self):
super(Module,self).__init__()
#创建二维卷积层
self.conv1=Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)
def forward(self,x):
x=self.conv1(x)
return x
module=Module()
writer=SummaryWriter("./logs")
step=0
for data in dataloader:
imgs,targets=data
output=module(imgs)
print(imgs.shape)
print(output.shape)
#torch。Size([64,3,32,32])
writer.add_images("input",imgs,step)
#torch.Size([64,6,30,30])
#卷积之后图像的形状 torch.Size([64, 6, 30, 30])是6个通道的 而add_images只能接收3通道的输入
output=torch.reshape(output,(-1,3,30,30))
writer.add_images("output",output,step)
step+=17.最大池化层
保留输入的特征,同时减少数据量 加快训练速度
python
input=torch.tensor([
[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]
])
input=torch.reshape(input,(-1,1,5,5))
print(input.shape)
class Module(nn.Module):
def __init__(self):
super(Module,self).__init__()
#ceil_mode=True:当输入尺寸不能被池化窗口整除时,使用向上取整的方式计算输出尺寸
self.maxpool1=MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self,input):
output=self.maxpool1(input)
return output8.非线性激活层
引入非线性的特性,使得神经网络具有更强的表达能力和适应能力
(1)ReLU:当输入大于0时,输出等于输入,当输入小于等于0时,输出为0
python
input=torch.tensor([
[1,-0.5],
[-1,3]
])
input=torch.reshape(input,(-1,1,2,2))
print(input.shape)
class Module(nn.Module):
def __init__(self):
super(Module,self).__init__()
self.relu=ReLU()
def forward(self,input):
output=self.relu(input)
return output(2)Sigmod:用于隐层神经单元输出,取值范围为(0,1),它可以将一个实数映射到(0,1)的区间,可以用来做二分类。在特征相差比较复杂或者相差不是特别大的时候效果比较好。
9.线性层及其他层
Linear:
output=input×weightT+bias
<font style="color:#DF2A3F;">input</font>:输入数据(形状<font style="color:#000000;">[batch_size, input_dim]</font>)<font style="color:#DF2A3F;">weight</font>:权重矩阵(形状<font style="color:#000000;">[output_dim, input_dim]</font>)<font style="color:#DF2A3F;">bias</font>:偏置向量(形状<font style="color:#000000;">[output_dim]</font>)
python
import torch
import torch.nn as nn
# 定义一个线性层:输入100维,输出64维
linear_layer = nn.Linear(100, 64)
# 随机生成输入数据(batch_size=5, 输入维度=100)
input_data = torch.randn(5, 100)
# 前向传播
output = linear_layer(input_data)
print("输出形状:", output.shape) # 输出: torch.Size([5, 64])10.flatten层
将输入张量扁平化(flatten)的函数,它将输入张量沿着指定的维度范围进行扁平化处理,并返回一个一维张量作为结果
python
t = torch.tensor([[[1, 2],
[3, 4]],
[[5, 6],
[7, 8]]])
torch.flatten(t)11.Sequential的使用
以按照添加的顺序依次执行包含的各个模块,torch.nn.Sequential提供了一种简单的方式来构建神经网络模型,代码十分简洁。
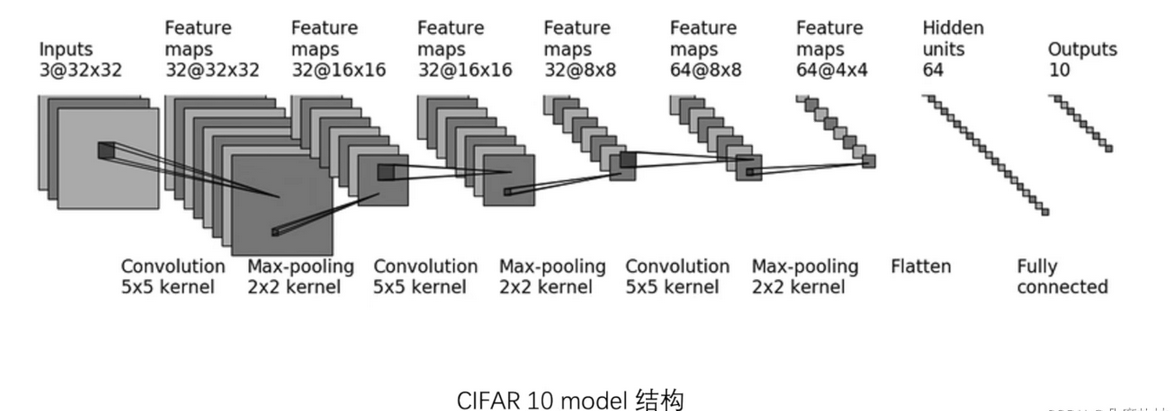
python
class Module(nn.Module):
def __init__(self):
super(Module,self).__init__()
#Sequential使用
self.model1=Sequential(
Conv2d(3,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,32,5,padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x=self.model1(x)
return x
module=Module()
print(module)
#网络结构检测
input=torch.ones((64,3,32,32))
output=module(input)
print(output.shape)12.损失函数
损失函数(Loss Function)用于衡量模型的预测输出与实际标签之间的差异或者误差,损失越小越好,根据loss调整参数(反向传播),更新输出,减小损失
python
inputs=torch.tensor([1,2,3],dtype=torch.float32)
targets=torch.tensor([1,2,5],dtype=torch.float32)
inputs=torch.reshape(inputs,(1,1,1,3))
targets=torch.reshape(targets,(1,1,1,3))
#平均绝对误差
loss=L1Loss(reduction="sum")
result=loss(inputs,targets)
#均方误差
loss_mse=MSELoss()
result_mse=loss_mse(inputs,targets)
print(result,result_mse)分类问题常用损失:CrossEntropyLoss交叉熵损失函数
python
dataset=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),
download=True)
dataloader=DataLoader(dataset=dataset,batch_size=64)
class Module(nn.Module):
def __init__(self):
super(Module,self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
#使用交叉熵损失函数
loss=nn.CrossEntropyLoss()
module=Module()
for data in dataloader:
imgs,targets=data
outputs=module(imgs)
result_loss=loss(outputs,targets)
#执行反向传播,计算损失相对于模型参数的梯度,这些梯度将用于后续的参数更新
result_loss.backward()
print(result_loss)反向传播:在张量上进行操作时,PyTorch 会自动跟踪操作并构建计算图,可以使用 .backward() 方法(反向传播)计算梯度,然后通过 .grad 属性获取梯度值
13.优化器使用
在深度学习中,optimizer.zero_grad()是一个非常重要的操作,它的含义是将模型参数的梯度清零。
在训练神经网络时,通常采用反向传播算法来计算损失函数关于模型参数的梯度,并利用优化器来更新模型参数以最小化损失函数。在每次反向传播计算梯度后,梯度信息会被累积在对应的参数张量(tensor)中。如果不清零梯度,在下一次计算梯度时,这些梯度将会被新计算的梯度累加,导致梯度信息错误。
python
#创建一个计算交叉损失熵函数
loss=nn.CrossEntropyLoss()
module=Module()
#创建一个随机梯度下降(SGD)优化器
optim=torch.optim.SGD(module.parameters(),lr=0.01)
for epoch in range(20):
running_loss=0.0
for data in dataloader:
imgs,targets=data
outputs=module(imgs)
result_loss=loss(outputs,targets)
#将模型中所有参数(parameters)的梯度清零。
optim.zero_grad()
#反向传播
result_loss.backward()
#optim.step()是优化器对象的一个方法,用于根据计算得到的梯度更新模型的参数
optim.step()
running_loss=running_loss+result_loss
print(running_loss)14.网络模型使用
(1)模型下载、添加、修改
python
#vgg16网络模型下载
vgg16_false=torchvision.models.vgg16(pretrained=False)
vgg16_true=torchvision.models.vgg16(pretrained=True)
#现有网络模型添加
vgg16_true.classifier.add_module("add_linear",nn.Linear(1000,10))
#现有网络模型修改
vgg16_false.classifier[6]=nn.Linear(4096,10)
print(vgg16_false)(2)模型保存
python
vgg16=torchvision.models.vgg16(weights=None)
#保存方式1,模型结构+模型参数
torch.save(vgg16,"vgg16_method1.pth")
#保存方式2(推荐),模型参数
torch.save(vgg16.state_dict(),"vgg16_method2.pth")(3)模型加载
python
#加载模型方式1
model=torch.load("vgg16_method1.pth")
print(model)
#加载模型方式2
#创建一个未预训练的VGG16模型,weights=None表示不加载预训练权重
vgg16=torchvision.models.vgg16(weights=None)
vgg16.load_state_dict(torch.load("vgg16_method2.pth"))
print(vgg16)15.完整网络模型训练与测试套路
python
import torch.optim
import torchvision.datasets
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from model import *
from nn_optim import epoch
#使用GPU进行训练
device=torch.device("cuda")
train_data=torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=torchvision.transforms.ToTensor(),
download=True)
test_data=torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=torchvision.transforms.ToTensor(),
download=True)
#length长度
train_data_size=len(train_data)
test_data_size=len(test_data)
print("训练数据长度为{}".format(train_data_size))
print("测试数据长度为{}".format(test_data_size))
train_dataloader=DataLoader(train_data,batch_size=64)
test_dataloader=DataLoader(test_data,batch_size=64)
#创建网络模型
module=Module()
module=module.to(device)
#损失函数
loss_fn=nn.CrossEntropyLoss()
loss_fn=loss_fn.to(device)
#优化器
learning_rate=1e-2
optimizer=torch.optim.SGD(module.parameters(),lr=learning_rate)
#设置训练网络的一些参数
#记录训练次数
total_train_step=0
#记录测试次数
total_test_step=0
#训练轮数
epoch=10
#添加tensorboard
writer=SummaryWriter("./logs_train")
for i in range(epoch):
print("--------第{}轮训练开始----------".format(i+1))
#训练步骤
for data in train_dataloader:
imgs,targets=data
imgs=imgs.to(device)
targets=targets.to(device)
outputs=module(imgs)
loss=loss_fn(outputs,targets)
#优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step=total_train_step+1
if total_train_step%100==0:
print("训练次数:{},loss:{}".format(total_train_step,loss))
writer.add_scalar("train_loss",loss,total_train_step)
#测试步骤
total_test_loss=0
total_accuracy=0
with torch.no_grad():
for data in test_dataloader:
imgs,targets=data
imgs = imgs.to(device)
targets = targets.to(device)
outputs=module(imgs)
loss=loss_fn(outputs,targets)
total_test_loss=total_test_loss+loss
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy=total_accuracy+accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step=total_test_step+1
#保存网络模型
torch.save(module,"moduel_{}.pth".format(i))
print("模型已保存")
writer.close()在推理或评估模型时使用
torch.no_grad(),表明当前计算不需要反向传播使用之后,强制后边的内容不进行计算图的构建,with 语句是 Python 中的一个语法结构,用于包裹代码块的执行,并确保在代码块执行完毕后,能够自动执行一些清理工作。
model.train()开启训练模式,模型会跟踪所有层的梯度,以便在优化器进行梯度下降时更新模型的权重。
model.eval():开启评估模式,在评估模式下,模型不会跟踪梯度,这有助于减少内存消耗并提高计算效率。
16.使用GPU进行训练
(1)对于网络模型,数据,以及损失函数,都要调用cuda()
(2)(推荐)xx=xx.to(device)
python
device=torch.device("cuda")
#模型
module=module.to(device)
#损失函数
loss_fn=loss_fn.to(device)
#数据
imgs=imgs.to(device)
targets=targets.to(device)