Deepseek这项工作终于填补了长期以来只能纯文本输入的空白!
摘要
给出了几个重要信息
- 这是一篇探究视觉二维映射(optical 2D mapping)实现长上下文压缩的可行性的文章。
- 这个模型不怕高分辨率的输入。
- 当视觉图像压缩比很高的情况下,识别的精度依然很高。
- 模型推理速度快,单张 A100-40G 显卡搭载的 DeepSeek-OCR 每日可生成 20 万页以上的数据。
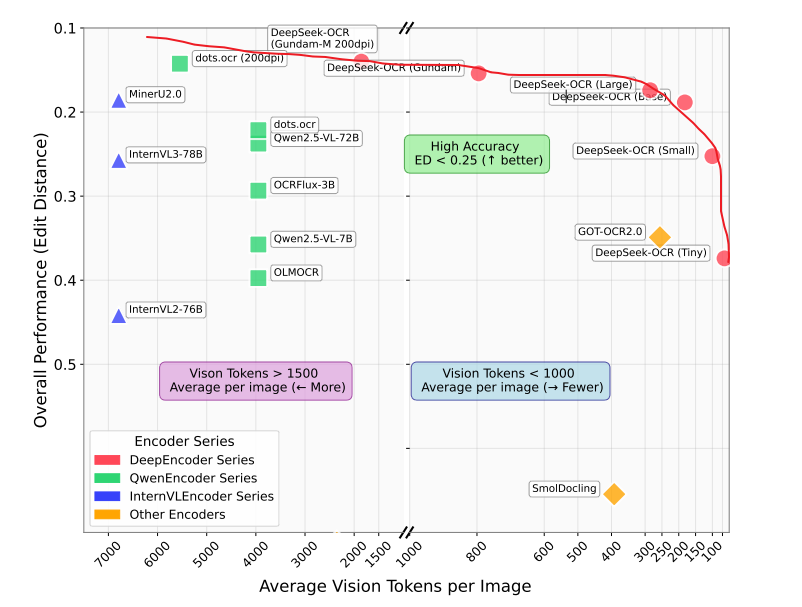
下图其他模型的在基准测试中对比,出手就是王炸,deepseek-ocr系列包揽了整个外围,类似机器学习的AUC图像,面积越大,模型性能越好。这个模型在各个token量级下的表现都是显著高于其他模型的。牛逼就完了。
简介
由于LLM存在天然的计算量的劣势:计算量随着序列长度呈现二次幂级的增长,学习过transformer的基本都该知道,向量在经过编码后,会形成qkv向量,然后两两之间进行计算,形成一个注意力矩阵,稍微具体点来说就是qkv 向量交互 :q(查询)与k^T(键的转置)先做点积计算 "注意力分数",再通过softmax得到权重,最终与v(值)做点积得到注意力输出。所以计算复杂度是n方。
为了规避这个问题,deepseek团队探究了一种用图像代替文本的思路:利用视觉令牌(vision
tokens)代替传统的令牌(token),本质上是一种信息的压缩。这里我们回顾一下token在大模型中的定义,我们可以这样理解:语言中的各个独立的信息都是存在于token当中的,它们彼此之间又有联系,从而可以升维成一个个词向量并交互计算。
在大语言模型(LLM)中,Token(标记)是模型处理自然语言的最小语义单元。它可以是一个字符、一个单词的片段(如子词)、完整的单词,甚至是标点符号或特殊符号。Token 的核心作用是将人类语言转化为模型能够理解的离散数字序列,从而支持后续的语义分析、生成等任务。
现在由于词向量两两之间计算注意力分数的范式效率太低了,我们将原先的文本输入 转化成图像输入,利用视觉token效率会不会更高呢?deepseek团队进行了一系列的实验:
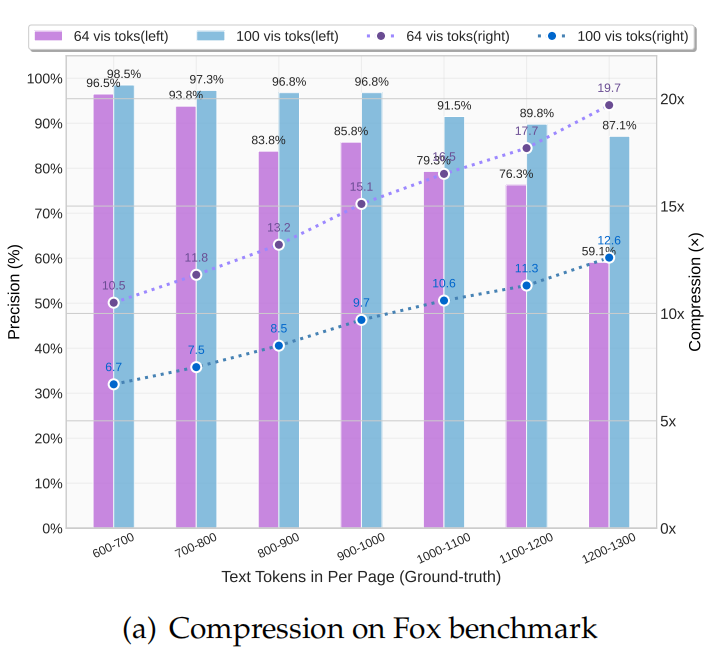
Fox基准测试【参考文献:Focus Anywhere for Fine-grained Multi-page Document Understanding 】中,我们的方法在
- 文本压缩比为 9-10 倍时,OCR 解码精度可达 96% 以上;
- 压缩比为 10-12 倍时,精度约为 90%;
- 压缩比为 20 倍时,精度约为 60%(若考虑输出与真值之间的格式差异,实际准确率会更高)
模型创新点:
1、新型架构 DeepEncoder,该架构即便在处理高分辨率输入时,仍能保持较低的激活内存与极少的视觉令牌数量 。
2、基于 DeepEncoder 与 DeepSeek3B-MoE开发了 DeepSeek-OCR 端到端softa模型。模型具有解析图表、化学公式、简单几何图形及自然图像的能力。
方法论
模型架构
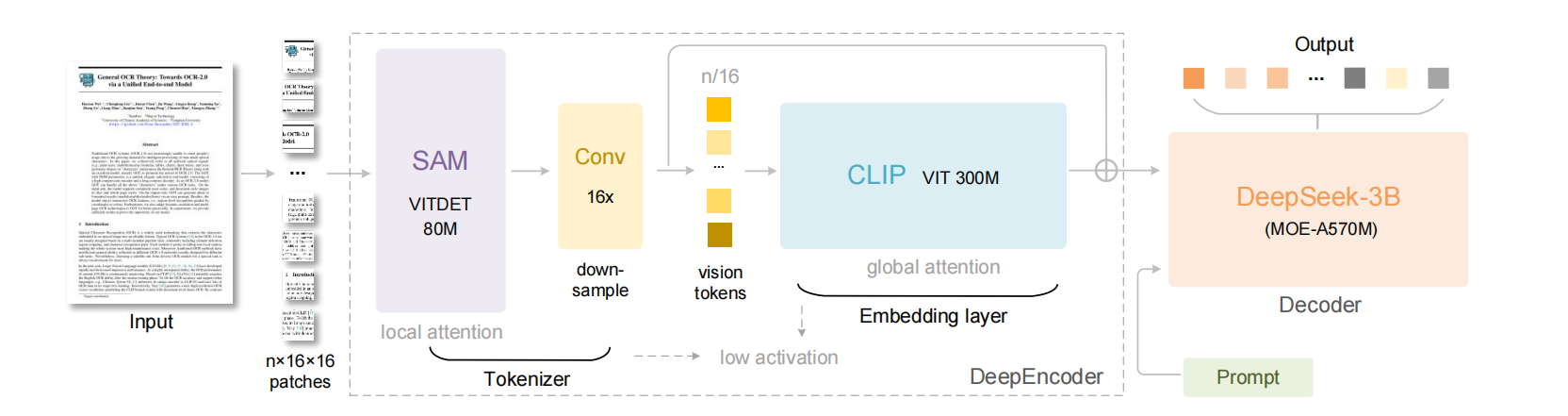
DeepEncoder 这里面有我们视觉领域的老朋友:SAM(https://segment-anything.com/)/CLIP(https://blog.csdn.net/weixin_47228643/article/details/136690837),中间的Conv 16x是链接SAM和CLIP的令牌压缩器,它实现了下采样,简化了大量计算。
DeepSeek-OCR 采用统一的端到端视觉语言模型(VLMs)架构,由编码器和解码器构成。其中,编码器(即 DeepEncoder,深度编码器)负责提取图像特征,并对视觉表征进行令牌化与压缩;解码器则用于根据图像令牌和提示词生成所需结果。
参数数量
DeepEncoder 的参数规模约为 3.8 亿,主要由 8000 万参数的 SAM-base 与 3 亿参数的 CLIP-large串联构成;
解码器采用 30 亿参数的 MoE(混合专家模型)架构,激活参数为 5.7 亿。"激活参数",特指 MoE 架构中实际参与计算的专家层参数,准确匹配该架构 "动态激活部分专家" 的核心特性。
模型特性需求
- 能够处理高分辨率(图像);
- 高分辨率下激活内存(activation)低;
- 视觉令牌(vision tokens)数量少;
- 支持多分辨率输入;
- 参数规模适中。
因此,deepseek团队自行设计了一款新型视觉编码器,命名为 DeepEncoder。
模型分析
DeepEncoder
DeepEncoder看起来只是对现有工作的缝合,但也是一种效率化的选择,论文中这样写的:To benefit from the pretraining gains of previous works, we use SAM-base (patch-size 16) and CLIP-large as the main architectures for the two components respectively. 看吧,我们不是非要缝合的,而是为了更高效率!
由于输入CLIP已经不是图像,而是上一流程得到的tokens,CLIP的patch embedding layer就不需要了,因为已得到了类似的经过patch embedding layer层的tokens了。
Ok,我们看下官方的开源代码具体怎么实现的,在DeepEncoder模块中,使用了两大模型
class DeepseekOCRForCausalLM(nn.Module, SupportsMultiModal, SupportsPP):
...
self.sam_model = build_sam_vit_b()
self.vision_model = build_clip_l()
...
def _build_sam(
encoder_embed_dim,
encoder_depth,
encoder_num_heads,
encoder_global_attn_indexes,
checkpoint=None,
):
prompt_embed_dim = 256
image_size = 1024
vit_patch_size = 16
image_embedding_size = image_size // vit_patch_size
image_encoder=ImageEncoderViT(
depth=encoder_depth,
embed_dim=encoder_embed_dim,
img_size=image_size,
mlp_ratio=4,
norm_layer=partial(torch.nn.LayerNorm, eps=1e-6),
num_heads=encoder_num_heads,
patch_size=vit_patch_size,
qkv_bias=True,
use_rel_pos=True,
global_attn_indexes=encoder_global_attn_indexes,
window_size=14,
out_chans=prompt_embed_dim,
)在ImageEncoderViT中,使用了论文中提到的conv下采样
class ImageEncoderViT(nn.Module):
...
self.net_2 = nn.Conv2d(256, 512, kernel_size=3, stride=2, padding=1, bias=False)
self.net_3 = nn.Conv2d(512, 1024, kernel_size=3, stride=2, padding=1, bias=False)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.patch_embed(x)
if self.pos_embed is not None:
# x = x + self.pos_embed
x = x + get_abs_pos(self.pos_embed, x.size(1))
for blk in self.blocks:
x = blk(x)
neck_output = self.neck(x.permute(0, 3, 1, 2))
conv2_output = self.net_2(neck_output)
# print(f"conv2_output shape: {conv2_output.shape}")
conv3_output = self.net_3(conv2_output)
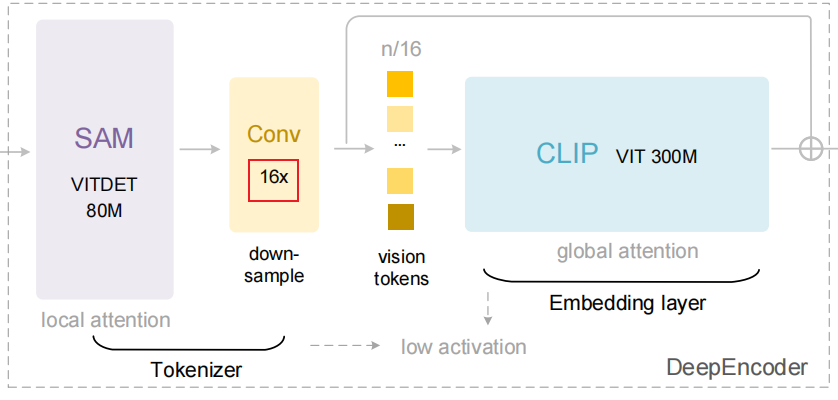
return conv3_output 假设输入一张高分辨率的图像,深度编码器(DeepEncoder)会将其分割1024/16×1024/16=4096 个补丁令牌(patch tokens),4096 个令牌经过压缩模块处理后,令牌数量变为 4096÷16=256 个,从而使整体激活内存处于可控范围。
在代码中,具体则是_build_sam中的image_encoder负责将其做第一步的切分,得到4096 个令牌,可以理解为使用vit模型的思想,将一张高分辨率的图像1024*1024的图像分块化,得到一张图像的4096个block,
def _build_sam(
encoder_embed_dim,
encoder_depth,
encoder_num_heads,
encoder_global_attn_indexes,
checkpoint=None,
):
prompt_embed_dim = 256
image_size = 1024
vit_patch_size = 16
image_embedding_size = image_size // vit_patch_size
image_encoder=ImageEncoderViT(
depth=encoder_depth,
embed_dim=encoder_embed_dim,
img_size=image_size,
mlp_ratio=4,
norm_layer=partial(torch.nn.LayerNorm, eps=1e-6),
num_heads=encoder_num_heads,
patch_size=vit_patch_size,
qkv_bias=True,
use_rel_pos=True,
global_attn_indexes=encoder_global_attn_indexes,
window_size=14,
out_chans=prompt_embed_dim,
)而两个连续的conv(stride=2,每次采样,block数量下降4倍,两次就是16倍),则对这个block化的图像继续压缩,实现信息的压缩,论文写的比较玄乎,其实代码就这样,祛魅了属于是
self.net_2 = nn.Conv2d(256, 512, kernel_size=3, stride=2, padding=1, bias=False)
self.net_3 = nn.Conv2d(512, 1024, kernel_size=3, stride=2, padding=1, bias=False)
neck_output = self.neck(x.permute(0, 3, 1, 2))
conv2_output = self.net_2(neck_output)
# print(f"conv2_output shape: {conv2_output.shape}")
conv3_output = self.net_3(conv2_output)多分辨率支持
假设我们有一张包含 1000 个光学字符的图像,且希望测试解码该图像需要多少个视觉令牌(vision tokens)。这就要求模型支持可变数量的视觉令牌,也就是说,DeepEncoder(深度编码器)需要支持多种分辨率,在训练阶段,输入图像的分辨率都是不固定的,团队通过位置编码的动态插值(dynamic interpolation of positional encodings)满足了前文提及的需求,并设计了多种分辨率模式(resolution modes)用于模型同步训练,以实现单个 DeepSeek-OCR 模型支持多种分辨率的能力。如图 4 所示,

DeepEncoder(深度编码器)主要支持两种核心输入模式:原生分辨率模式(native resolution)与动态分辨率模式(dynamic resolution),每种模式下均包含多个子模式(sub-modes)。
原生分辨率支持四种子模式:Tiny、Small、Base 和 Large,对应的分辨率及令牌数量分别为 512×512(64 个)、640×640(100 个)、1024×1024(256 个)和 1280×1280(400 个)。
由于 Tiny 模式和 Small 模式的分辨率相对较小,为避免浪费视觉令牌(vision tokens),图像通过直接调整原始尺寸的方式进行处理;对于 Base 模式和 Large 模式,为保留原始图像的宽高比,需将图像填充(padding)至对应尺寸。填充后,有效视觉令牌的数量会少于实际视觉令牌数量,其计算公式如下
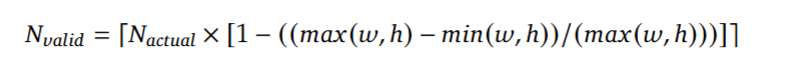
其中,w 和 h 分别表示原始输入图像的宽度(width)和高度(height)
动态分辨率(对应Gundam模式 ) 可由两种原生分辨率组合构成(所以你会看到||这个符号)。支持动态分辨率主要出于应用层面的考量,尤其针对超高分辨率输入(如报纸图像)。分块(tiling)本质是一种二次窗口注意力机制,能进一步有效降低激活内存(activation memory)。值得注意的是,由于我们采用的原生分辨率本身相对较大,动态分辨率模式下图像不会过度分割,动态分辨率模式下图像不会过度分割 ------ 分块数量控制在 2 到 9 个之间。例如图4的第三个情况,一个页面就被分成了6小块,每小块都应用base模式。
Gundam模式可由 n 个 640×640 的分块(局部视图,local views)和一个 1024×1024 的全局视图(global view)组成(如图4第三情况所示),其分块方法(tiling method)沿用 InternVL2.0的设计

DeepEncoder 在 Gundam 模式下输出的视觉令牌(vision token)数量计算公式为:n×100+256,其中 n 代表分块数量。对于宽和高均小于 640 的图像,n 设为 0,即 Gundam 模式会降级为 Base 模式。当然,如果页面分辨率很大,也可以降级成Large模式,此时数量计算公式为:n×256+400
具体在代码中如何实现的?目前开源的代码,好像并没有对应的详细代码,只能找到一段被注释掉的代码,它的核心功能是从候选分辨率列表中,为输入图像选择 "最佳适配分辨率",适配原则是在保证图像完整(不拉伸变形)的前提下,最大化 "有效分辨率利用率" 并最小化 "分辨率浪费",通常用于图像裁剪。
遍历self.candidate_resolutions,这是类中预定义的 "候选分辨率列表"(格式为 (宽 1, 高 1), (宽 2, 高 2), ...),代码会逐个评估每个候选分辨率的适配性,这里候选分辨率是由原生分辨率组合而来的
def select_best_resolution(self, image_size):
# used for cropping
original_width, original_height = image_size
best_fit = None
max_effective_resolution = 0
min_wasted_resolution = float("inf")
for width, height in self.candidate_resolutions:
scale = min(width / original_width, height / original_height)
downscaled_width, downscaled_height = int(
original_width * scale), int(original_height * scale)
effective_resolution = min(downscaled_width * downscaled_height,
original_width * original_height)
wasted_resolution = (width * height) - effective_resolution
if effective_resolution > max_effective_resolution or (
effective_resolution == max_effective_resolution
and wasted_resolution < min_wasted_resolution):
max_effective_resolution = effective_resolution
min_wasted_resolution = wasted_resolution
best_fit = (width, height)
return best_fit开源代码中相应使用的地方(最后一行)也注掉了..
class DeepseekOCRProcessor(ProcessorMixin):
...
# self.candidate_resolutions = candidate_resolutions # placeholder no use而具体分辨率模式是在这里定义的,
# Tiny: base_size = 512, image_size = 512, crop_mode = False
# Small: base_size = 640, image_size = 640, crop_mode = False
# Base: base_size = 1024, image_size = 1024, crop_mode = False
# Large: base_size = 1280, image_size = 1280, crop_mode = False
# Gundam: base_size = 1024, image_size = 640, crop_mode = True根据分辨率模式,我们可以定义多组candidate_resolutions,给定一个随机的页面尺寸,可以利用select_best_resolution来获取最佳的分辨率模式,如果是需要使用Gundam,则进行二次分块。我是这样理解的。
MoE Decoder
deepseek团队还是这么喜欢MoE。。。解码器采用 DeepSeekMoE 模型,具体为 DeepSeek-3B-MoE(30 亿参数混合专家模型)。在推理阶段,该模型会从 64 个路由专家(层)中激活 6 个,并激活 2 个共享专家(层),激活参数规模约为 5.7 亿。
这款 30 亿参数的 DeepSeekMoE 模型非常适合领域聚焦型(对我们而言即 OCR 领域)视觉语言模型(VLM)研究 ------ 它既能具备 30 亿参数模型的表达能力,同时又拥有 5 亿参数小模型的推理效率。
解码器从深度编码器(DeepEncoder)压缩后的 latent 视觉令牌中重构原始文本表征,具体形式如下:
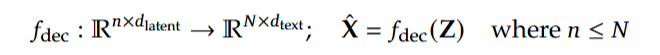
其中Z代表代表从深度编码器输出的压缩后 latent 视觉令牌,则是重构得到的文本表征,轻量语言模型可通过 OCR 式训练有效习得该映射能力
。
具体的MoE模型,其他专家已经有写,我就不赘述了,这里贴出一个链接参考https://blog.csdn.net/Python_cocola/article/details/145214265
数据
在数据的处理上,deepseek做足了工作。
Ocr1.0 data
文档数据是 DeepSeek-OCR 的核心优先级数据。团队从互联网上收集了 3000 万页(30M pages)多样性 PDF 数据,涵盖约 100 种语言,
- 中英文数据约 2500 万页(25M pages),
- 其他语言数据约 500 万页(5M pages)。
针对该数据,构建了两类真值标注(ground truth):粗粒度标注(coarse annotations)与细粒度标注(fine annotations)。粗粒度标注直接通过 fitz 库从完整数据集中提取得到,目的是教会模型识别视觉文本,尤其针对小语种文本;细粒度标注包含中英文各 200 万页数据,通过先进的版面模型和 OCR 模型进行标注,以构建检测与识别交织的数据。
在 DeepSeek-OCR 的训练过程中,我们通过不同的提示词(prompts)区分粗粒度标签与细粒度标签。细粒度标注图文对(image-text pairs)的真值标注(ground truth)可参考图 5。【真值标注(ground truth)格式化为 "版面与文本交织" 的形式,其中每段文本前均标注其在原始图像中的坐标及标签。所有坐标均被归一化到 1000 个区间(bins)内。】

团队还收集了 300 万条(3M)Word 文档数据,通过直接提取内容构建高质量的无版面信息图文对 ------ 这类数据主要对公式和 HTML 格式表格的处理有帮助。此外,我们还选取了部分开源数据作为补充数据。
在自然场景光学字符识别(OCR)任务中,模型主要支持中文和英文。图像数据来源于 LAION与 Wukong(数据集 / 模型),通过 PaddleOCR(OCR 模型)进行标注,其中中文和英文数据样本各 1000 万条(10M)。与文档 OCR 类似,自然场景 OCR 也可通过提示词(prompts)控制是否输出检测框(detection boxes)
Ocr2.0 data
参照 GOT-OCR2.0,我们将图表、化学公式及平面几何解析数据统称为 OCR 2.0 数据。针对图表数据,我们参照 OneChart 7,使用 Python 可视化库 pyecharts 与 matplotlib去渲染 1000 万张(10M)图像,主要包括常用的折线图、柱状图、饼图和复合图表。我们将图表解析定义为 "图像到 HTML 表格" 的转换任务,如图 6 (a) 所示。针对化学公式,我们以 PubChem(化合物数据库)中的 SMILES 格式(简化分子线性输入规范)为数据源,通过 RDKit(化学信息学工具包)将其渲染为图像,构建了 500 万组(5M)图文对。
针对平面几何图像,我们参照 Slow Perception的方法进行生成。具体而言,我们将感知标尺尺寸设为 4,对每条线段进行建模。为提升渲染数据的多样性,我们引入 "几何平移不变的数据增强"------ 同一平面几何图像在原始图像中进行平移时,其对应的真值标注(ground truth)为在坐标系中心位置绘制的同一标注。基于此,我们共构建了 100 万条(1M)平面几何解析数据,如图 6 (b) 所示。
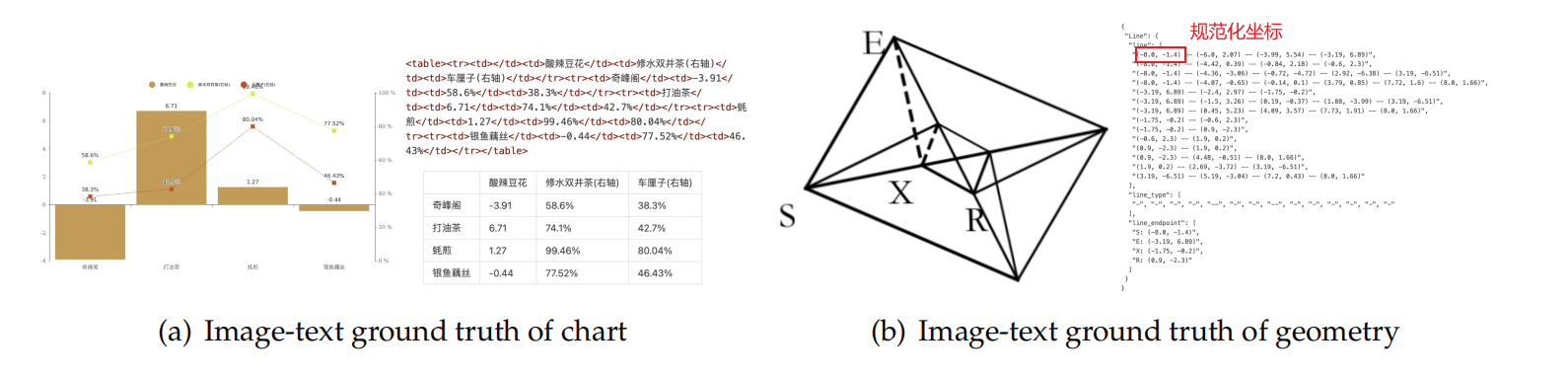
针对图表,我们未采用 OneChart的字典格式,而是采用 HTML 表格格式作为标注,此举可节省一定数量的令牌(tokens)。针对平面几何,我们将真值标注(ground truth)转换为字典格式,该字典包含 "线段""端点坐标""线段类型" 等键(keys),以提升可读性。每条线段均采用 Slow Perception的方式进行编码。
训练
这部分了解就好,一般人玩不起。训练流程十分"简洁",主要包含两个阶段:
- 独立训练 DeepEncoder(深度编码器)
- 训练 DeepSeek-OCR(OCR 模型)
需注意,Gundam-master 模式是通过在预训练好的 DeepSeek-OCR 模型上,使用 600 万条(6M)采样数据继续训练得到的。由于其训练方案与其他模式完全一致,此后不再赘述其详细说明。
训练 DeepEncoder(深度编码器)。在此阶段,使用前文提及的所有 OCR 1.0 和 OCR 2.0 数据,以及从 LAION数据集中采样得到的 1 亿条(100M)通用数据。所有数据均以 1280 的批次大小(batch size)训练 2 轮(epochs),使用 AdamW 23 优化器,搭配余弦退火调度器(cosine annealing scheduler)22,学习率(learning rate)设为 5×10⁻⁵。训练序列长度(sequence length)为 4096。
DeepEncoder 准备就绪后,我们使用 3.4 节提及的数据训练 DeepSeek-OCR,整个训练过程在 HAI-LLM平台上进行。整个模型采用流水线并行(PP),并分为 4 个部分,其中 DeepEncoder 占 2 个部分,解码器占 2 个部分。
对于 DeepEncoder,我们将 SAM与压缩器视为视觉令牌生成器,置于 PP0 中并冻结其参数;同时将 CLIP 部分视为输入嵌入层,置于 PP1 中,且该部分权重未冻结,用于训练。对于语言模型部分,由于 DeepSeek3B-MoE 包含 12 层,我们在 PP2 和 PP3 上各放置 6 层。训练使用 20 个节点(每个节点配备 8 张 A100-40G 显卡),数据并行(DP)度为 40,全局批次大小为 640。我们采用 AdamW 优化器,搭配基于步长的调度器,初始学习率设为 3×10⁻⁵。其中,纯文本数据的训练速度为每天 900 亿个令牌,多模态数据的训练速度为每天 700 亿个令牌。