一 信息一览
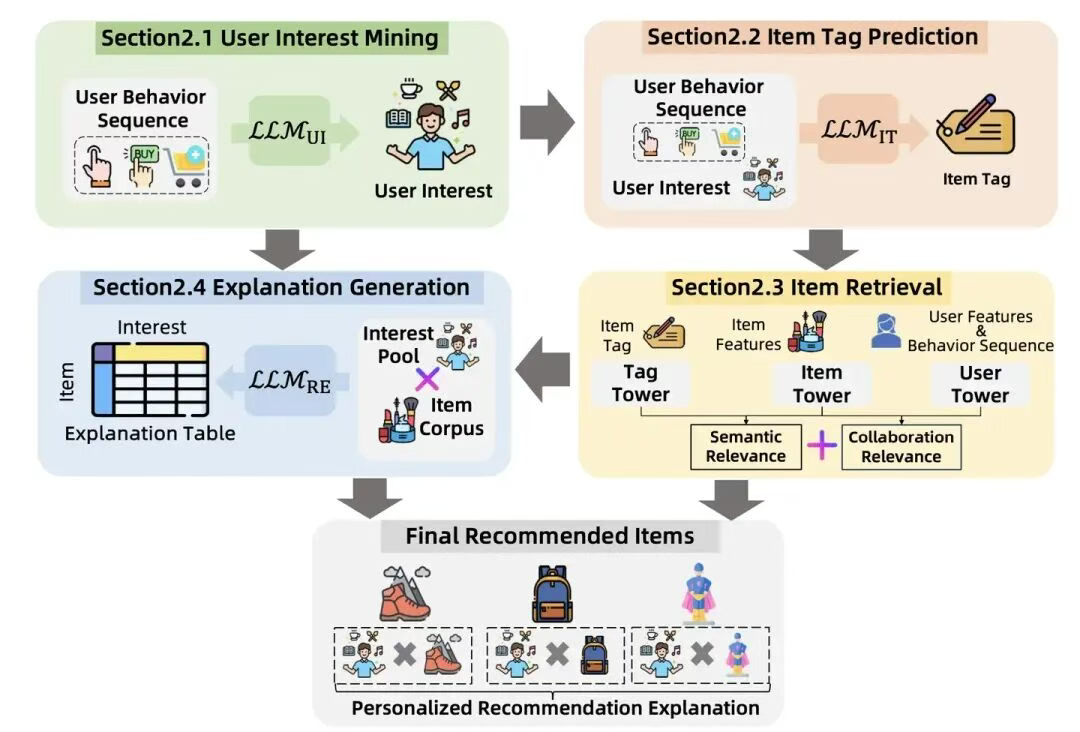
- 用户兴趣挖掘模块挖掘用户兴趣供商品标签预测模块和推荐归因模块使用。
- 标签预测模块生成商品标签供
- 召回层使用召回层利用了商品标签包含的语义相关性信息
- 丰富了召回的多样性带来效果提升
- 推荐归因模块离线生成用户兴趣x物品的推荐原因,最后跟推荐结果一起展示给用户
二 应用效果
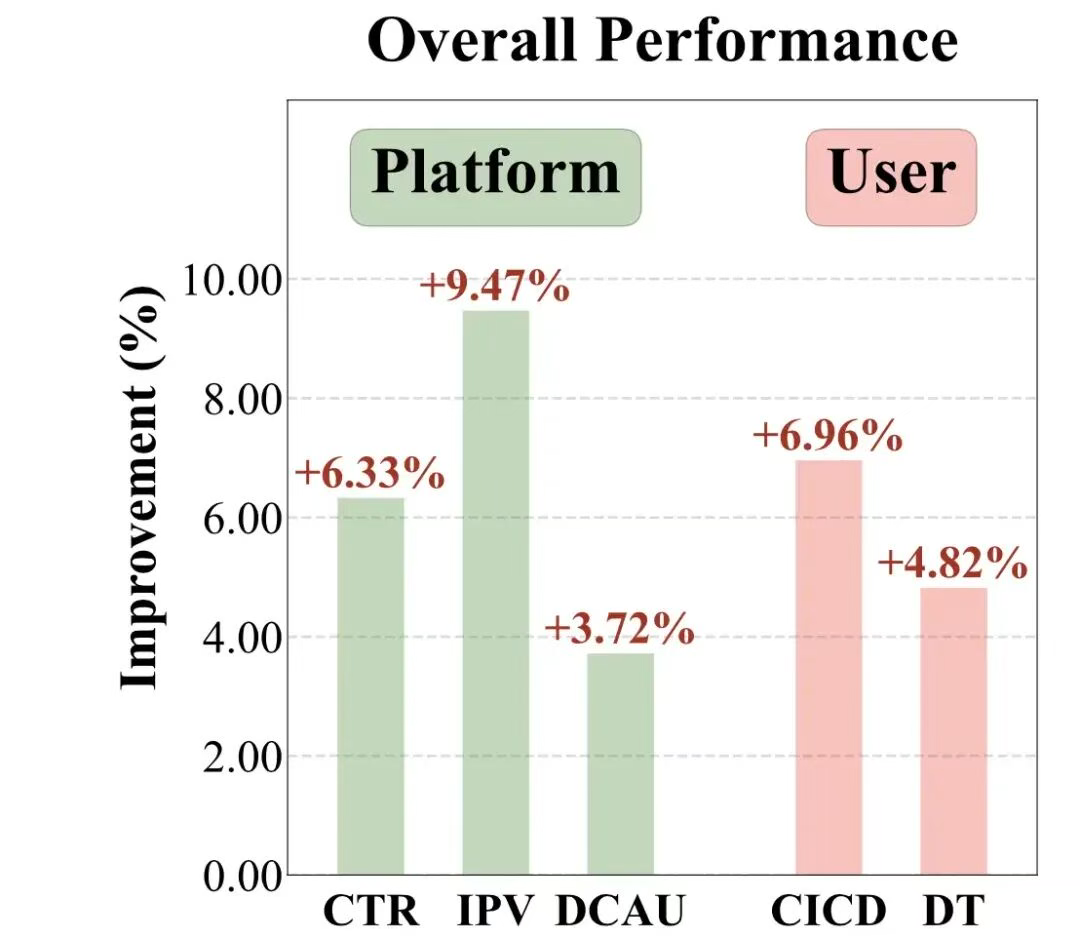
阿里基于LLM对于推荐系统召回阶段的应用,还是先看效果,CTR、IPV等核心指标有超过5%的提升:
三 模型架构
下面再看模型:
基本结构如下图所示,基本的架子是一个三塔模型,右边的用户塔和物品塔没有什么可多讲的,典型的双塔结构;左边的Tag塔是RecGPT独有的,简单来说,RecGPT通过理解商品和用户信息把大模型的能力浓缩进了Tag塔,这也是召回效果增量的全部来源。
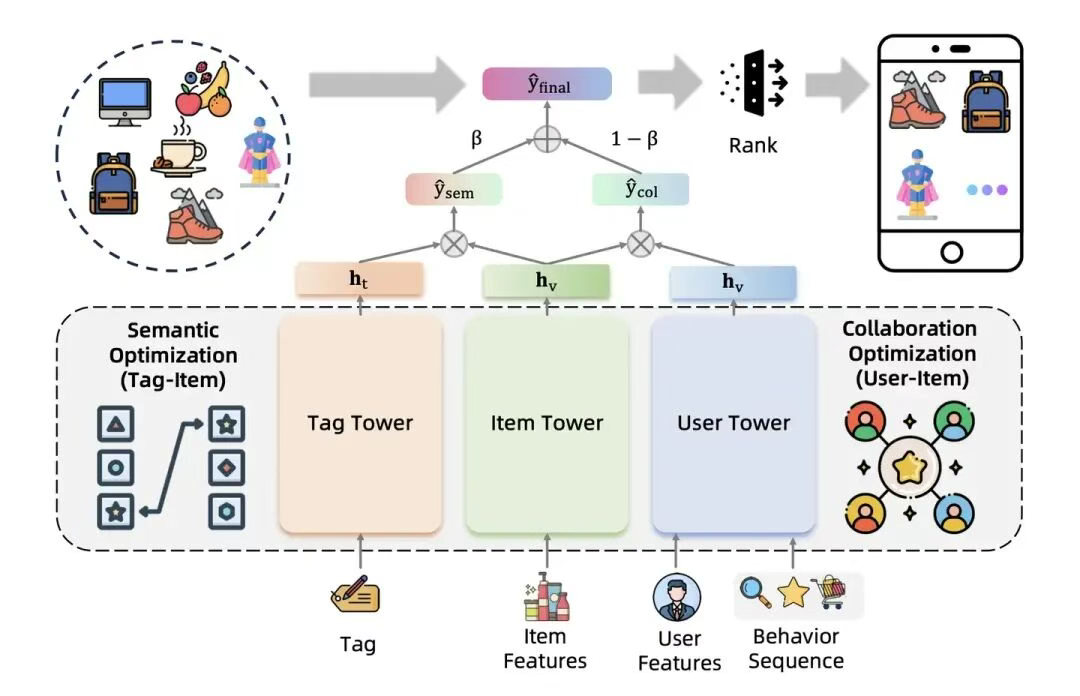
最终的召回得分是user-item双塔和tag-item双塔的加权,宏观上来说,user-item双塔得分学习的是传统推荐系统里用户行为之间的协同过滤相关性;而tag-item双塔得分学习的是用户兴趣意图和物品内容信息的语义 相关性。
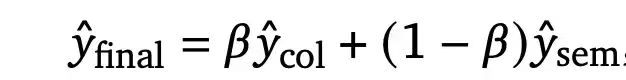
重点创新点:
- tag-item得分是怎么得出来的?
item embedding的生成方式没有什么特别的,就是把item相关的属性转换成embedding,再用一个DNN学习item的emb表达,很经典DLRM的方式。
那么这里的tag是什么呢?tag其实是RecGPT利用大模型的能力学习出来的用户感兴趣的商品标签的集合。所以tag塔的输入是一组商品标签。这组商品标签是大模型通过语义相关性分析出来的用户可能感兴趣的商品标签。而tag塔的输出就是这一组商品标签embedding化后的mean pooling。
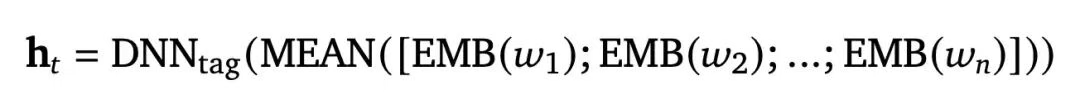
- 用户感兴趣的商品标签是怎么生成的?
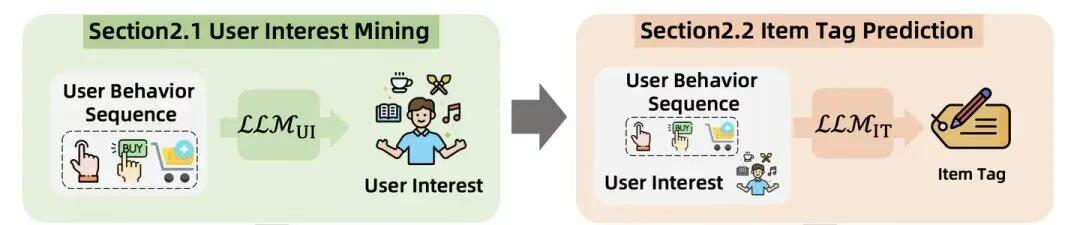
分为两步,第一步是利用用户兴趣挖掘模块LLM_UI来挖掘用户兴趣,然后再把用户兴趣输入另外一个大模型模块------商品标签预测模块LLM_IT来生成商品标签。下面就让我看看这两个模块分别是如何工作的:
1)LLM用户兴趣挖掘模块
用户兴趣挖掘模块是这样一个大模型任务,它会利用LLM的能力把用户的属性和行为历史抽象成用户的兴趣点。它的prompt把这个任务描绘的很清晰。

任务的输入是用户的一些属性信息和用户的行为历史,输出是用户的兴趣集合(文本形式)。当然,这里面肯定是要把兴趣相关的标签体系,任务的具体要求(Mandatory Requirement)作为prompt的一部分输入进去,这样才能生成结构化的兴趣集合。
文中给出了一个例子如下,大家可以有个直观认知。作为落地方案,这个兴趣集合其实直接采用电商平台的商品分类体系,广告平台的定向分类体系就很合适,而且易于跟现有平台融合。

2) LLM商品标签预估模块
接下来的商品标签预估模块是要进一步把用户兴趣细化,变成更细粒度的,更适合推荐系统召回层使用的商品标签。定义该任务的prompt也不难理解,具体的形式如下:

可以看到,标签预估模块其实不仅把刚刚生成的用户兴趣作为输入,而且还把原始的用户属性和用户行为输入进去了。
为什么要这么做?直接把用户兴趣模块去掉,让大模型基于用户属性和原始行为信息推测商品标签不好吗?为什么要加一步呢?
推测主要有两点原因:用户兴趣模块起到了一个兴趣泛化的作用,利用这一步把用户的兴趣先提炼出来,让标签预测模块预测时能够在相对大,但是有针对性的兴趣范围内进行细粒度的标签预测。利用了大模型CoT(思维链)的思考方式,把问题拆解的更清晰,让大模型通过多步任务的出更稳定和合理的标签预测结果。
另外一个思考方向是能不能只把用户兴趣作为输入,舍弃原始的用户行为序列。这样做肯定是不行的,因为我们期望的输出是相比用户兴趣更细粒度的商品标签,必须有更丰富的原始信息输入,才能做到标签的细化。总而言之,通过标签预测模块,我们可以得到用户喜欢的一批商品标签,下面是一个具体的例子。可以看到,标签预估模块生成的tag相比用户interest,粒度更细,更接近商品描述本身,这更有利于推荐系统更精准的找到相关商品。在生成标签列表之后,就可以通过tag-item-user三塔模型进行商品召回了。
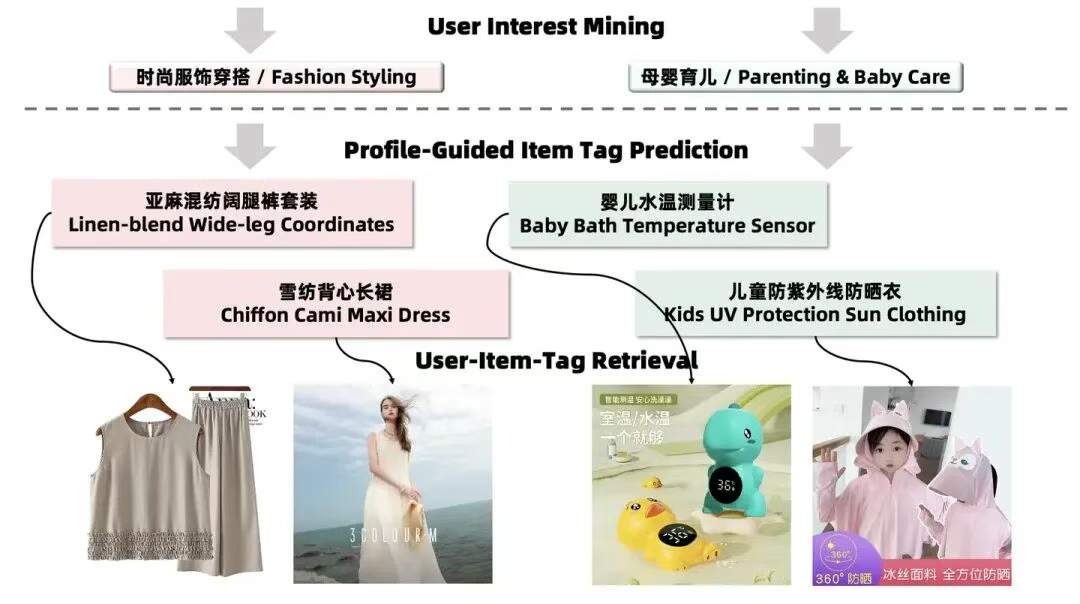
四 其他trick
1. RecGPT的行为序列压缩技巧
RecGPT显然是一个更有工业风,与成熟的推荐系统架构融合的更好的方案。这种工业风主要体现在细节的处理上,比如序列数据的压缩。
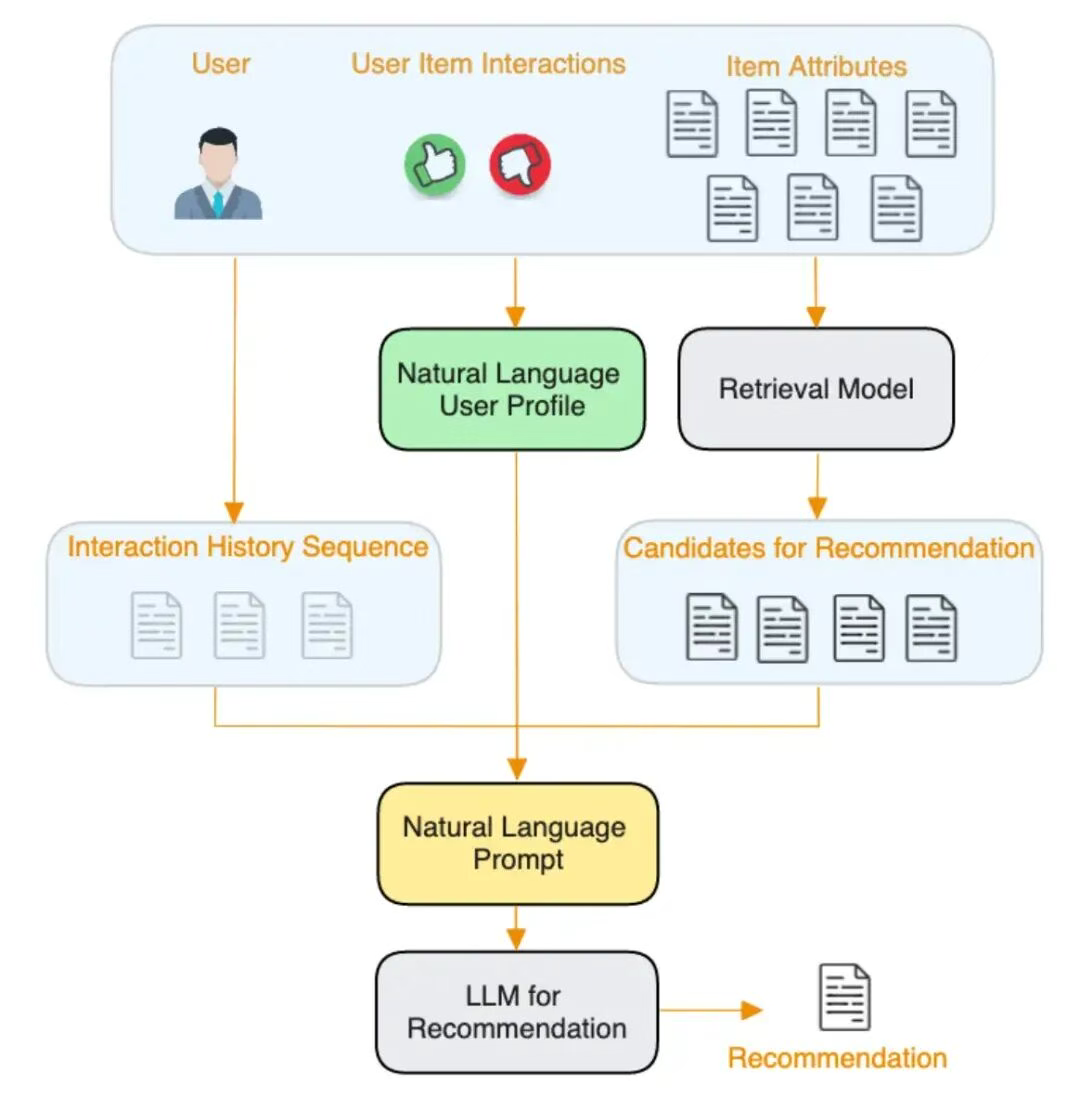
对于用户行为序列,如果我们不加处理的输入LLM,会存在一些问题,比如信息密度过低,序列长度超出LLM限制等。所以RecGPT方案采取了一系列的序列压缩方案:
a. 只采用有明确兴趣指向的行为,比如购买,添加购物车,喜欢,搜索等。对于弱兴趣意图的行为比如点击、阅读评论等则不加入行为序列;
b. 商品信息压缩: 只把关键的能代表商品信息,比如名称、类别、品牌等作为商品信息;
c. 对用户行为进行时间上和item级别的压缩:比如把固定时间段内的重复行为合并,把经常同时出现的item聚合在一起汇总行为序列等。最终的行为序列是下面的表达,是几个物品item1,item2,在不同时间段time1,tme2上的行为序列汇总,这样大幅压缩了原始序列的体积,同时保留了关键的item相关性和时间相关性的信息。

2. 微调
但到这里,我们还要回答两个关键的问题。
RecGPT是直接使用DeepSeek这类开源的大模型呢?还是经过了一些fine tunning的训练过程?LLM各模块的评估是如何完成的?
关于问题一,文中比较了两个未经fine tuning的大模型DeepSeek-R1和阿里的Qwen3,和经过fine tuning的模型Qwen3-SFT和TBStars-SFT的效果。采用的测试集是人工生成的测试用例。在用户兴趣生成任务上,几个模型的表现如下:

在商品标签预测任务上,几个模型的表现如下:

可以看到,DeepSeek-R1在两个任务上均展现出了很高的通过率。这也给中小团队一些启发,如果没有资源和精力进行fine tuning,其实用开源的DeepSeek-R1就是非常好的选择。对于阿里这样的一线团队来说,他们除了采用阿里千问的大模型Qwen3作为基座模型,还使用了专门用于电商业务的TBStars模型进行fine tuning,该模型仅有3.5B参数,也达到了不错的效果,是线上部署比较节约资源的工程方案。
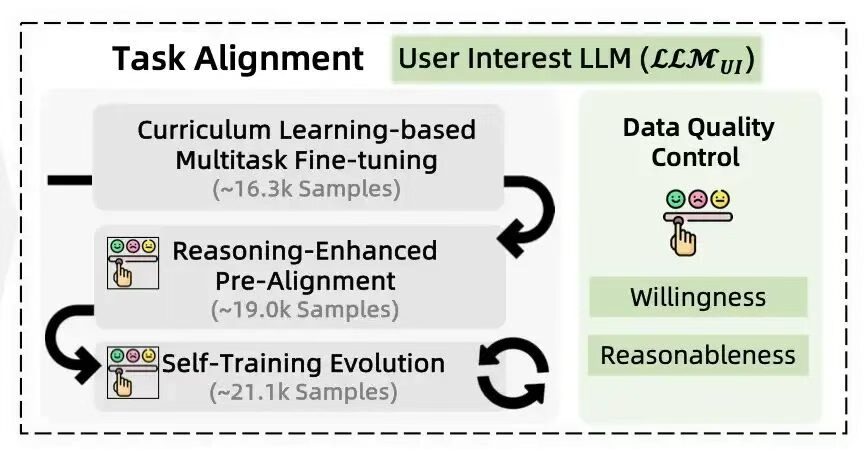
关于fine tuning的过程,用户兴趣、标签预测、推荐归因这三个任务基本都采用了三步走的策略:多任务微调。利用16个预先准备好的微调训练集,总共16.3k个训练样本进行模型微调。让模型更适合处理电商类的任务。比如这些训练集中包括商品关键信息提取,用户画像分析,推荐归因等。推理增强预对齐。利用DeepSeek R1生成针对任务的高质量训练集,并经过人工精选和整理,形成预对齐训练集。经过这一步训练,模型会显著增强完成特定任务的能力。自训练进化。建立了模型自生成样本 -> Human-LLM协同评估 -> 模型持续学习 的闭环。模型能够持续进化提升效果。这里面的关键是Human-LLM协同评估,等会我们再细讲。
下面这个图概括了整个的fine tuning的过程。三个任务的不同之处在于Data Quality Control的区别,不同的任务会用不同的标准来评估模型结果。用户兴趣模块是Willingness和Reasonableness,标签预测是Relevance Consistency Specificity Validity,推荐归因是Relevance Factuality Clarity Safety。
3. 效果评估
其实评估大模型在特定任务上的效果一直比较困难。因为人工生成大量测试集是一个非常昂贵的过程。LLM as a judge的思路是利用少量的人工测试集,教会LLM自己进行效果评估 。
如下图所示,RecGPT是把三个任务的通过样本(Approved Judge Samples)以及拒绝样本(Rejected Judge Samples)先保存到Judge Data Buffer,然后再通过数据再平衡,简单来说就是把量比较少的样本类别进行增强,把量比较大的样本类别进行降采样,形成一个比较平衡的样本集合,供LLM进行微调,微调成一个LLM Judge。
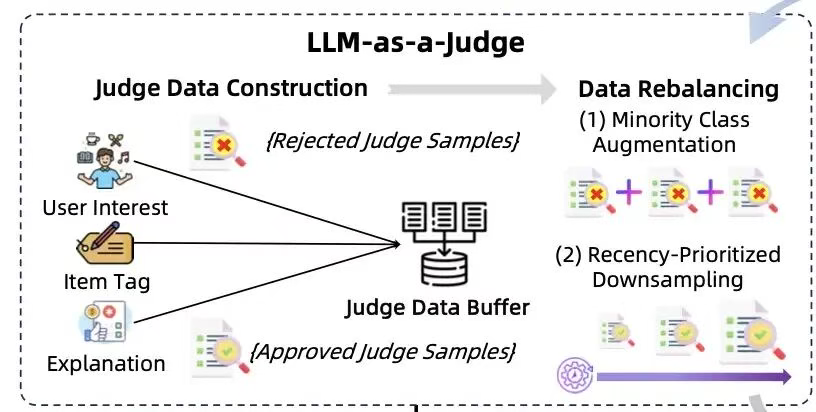
LLM Judge微调完成后,也不是一劳永逸的,还需要经过阶段性的人工检查。也就是说人会定期生成一些测试样本,不断测试LLM Judge的效果,再不断把LLM Judge分类错的例子教给它,不断优化LLM judge的效果。这样就形成了 人类监督LLM Judge,LLM Judge监督SFT-LLM的链条。这一链条大幅降低了人类参与的工作量。只需要用少量的人工样本测试LLM Judge即可
五 LLM的优势,归因
相比于推荐召回的改进工作,RecGPT更进一步用LLM给出了推荐原因。这样在产品界面中把推荐原因展现给用户,有可能进一步提升用户的购买兴趣。RecGPT的推荐归因prompt如下:

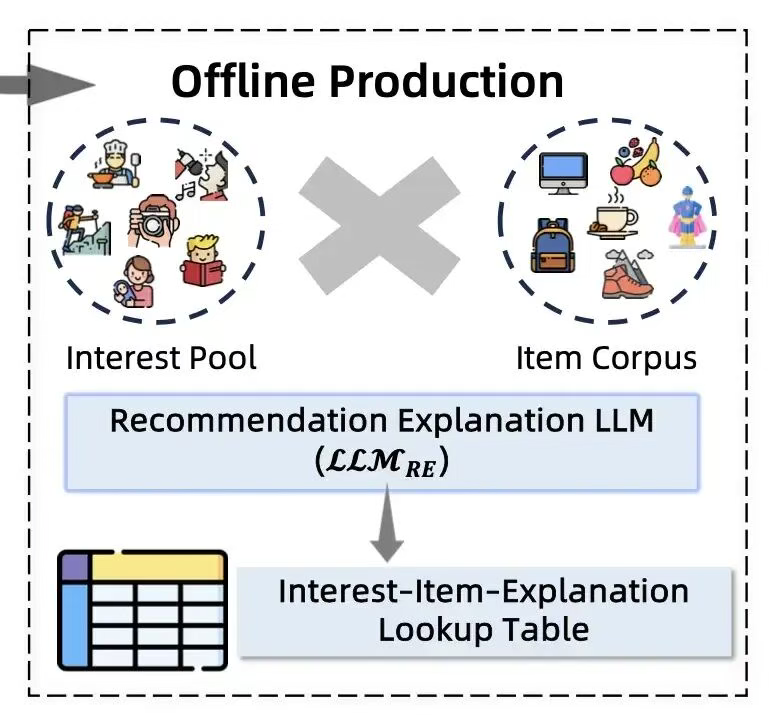
Prompt定义的输入主要是用户兴趣,当前时间和商品信息。所以归根结底,RecGPT没有采用特别复杂的Prompt,而是主要发掘用户兴趣和推荐商品的关联性。如果把用户的所有行为历史都输入进来,那势必会让推荐归因的结果五花八门,不太可控。而简单易于理解的归因也可以让用户不会感到意外。通过这个例子,我们也可以学习RecGPT给我们提供的非常好的prompt engineering的范例。Role,Input,Requirements,Output可以视为一个严谨的prompt设计的必要元素。另外Prompt中的Core Reasoning Steps是一个很好的利用LLM CoT能力的设计,把推荐归因生成分裂成了"上下文理解"和"解释生成"两步,增强了归因的稳定性。另外团队也给出了线上推理的建议。由于大模型线上实时做inference,无论从latency还是资源消耗的角度来说都是不可接受的。所以解释生成的过程是在离线预处理的。把用户兴趣x商品集合进行逐对离线分析,把推荐原因记录在lookup table,线上为用户推荐时就可以直接根据用户兴趣和推荐出的商品查询出推荐原因。这也是一个比较实用的工程技巧。
总结与思考:
之前的LLM,要么是玩具级别的,要么就是利用LLM的架构做模型大的创新,因为本人所在公司体量不大,LLM架构的模型根本玩不起,也很少做finetune,但是这个模型方法感觉实用性很强,存prompt也可以尝试,对于中小公司是一个可以参考模仿的!