提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- [1. 自然语言处理概述](#1. 自然语言处理概述)
-
- [1.1 基于同义词词典的方法](#1.1 基于同义词词典的方法)
- [1.2 基于计数的方法](#1.2 基于计数的方法)
- [1.3 基于推理的方法](#1.3 基于推理的方法)
- [2. 词嵌入层](#2. 词嵌入层)
-
- [2.1 什么是词嵌入](#2.1 什么是词嵌入)
- [2.2 API使用](#2.2 API使用)
- [2.3 词嵌入应用和NLP模型](#2.3 词嵌入应用和NLP模型)
- [3. 循环网络层](#3. 循环网络层)
-
- [3.1 RNN层介绍](#3.1 RNN层介绍)
- [3.2 API使用](#3.2 API使用)
- [4. 案例:古诗生成](#4. 案例:古诗生成)
-
- [4.1 数据预处理](#4.1 数据预处理)
- [4.2 创建数据集](#4.2 创建数据集)
- [4.3 创建模型](#4.3 创建模型)
- [4.4 模型训练](#4.4 模型训练)
- [4.5 生成新诗](#4.5 生成新诗)
- [5. 扩展](#5. 扩展)
- 总结
前言
两个领域:一个计算机视觉,图像识别,CNN,Transformer,卷积神经网络
还有一个就是自然语言处理了,循环神经网络,RNN,Transformer
1. 自然语言处理概述
们平日使用的语言,如汉语或英语,称为自然语言。自然语言处理(Natural Language Processing,NLP)的目标就是让计算机理解人类语言,进而完成对我们有帮助的事情。
说到计算机可以理解的语言,我们可能会想到编程语言或者标记语言等。这些语言的语法定义可以唯一性地解释代码含义,计算机也能根据确定的规则分析代码。编程语言是一种机械的、缺乏活力的语言。换句话说,它是一种"硬语言"。而汉语或英语等自然语言是"软语言",其含义和形式会灵活变化,并且会不断出现新的词语或新的含义。要让计算机去理解自然语言,使用常规方法是无法办到的。
1.1 基于同义词词典的方法
具有相同(同义词)或类似(近义词)含义的单词,可以归到同一个类别中;而根据单词"整体-部分"或者"上位-下位"关系,可以构建出层级的树状图。
这样,就可以构成一个庞大的"单词网络",用它就可以教会计算机单词之间的关系,从而计算出单词的"相似度"。
主要缺点:
需要人工逐个定义单词之间的相关性,非常费时费力;
新词不断出现,语言不断变化,词典维护成本极高;
在表现力上也有限制。
1.2 基于计数的方法
大量的文本数据,构成了 语料库(corpus)。
我们的目的,就是从语料库中,自动且高效地提取出语言的"本质"。最简单的做法,就是统计"词频"。
分词:对词进行统计,首先需要对文本内容进行切分,找出一个个基本单元;
词关联ID:给单词标上一个 ID,构建单词和ID的关联字典(称为"词表");
词向量化:用一个固定长度的向量来表示单词,也称为词的"分布式表示"。
对每一个词,可以统计它周围出现了什么单词、出现了多少次(称为"上下文");把这些词频统计出来,就构成了一个向量;这个向量就可以表示当前的词了,称为"词向量"(word vector)。这样,所有词对应的向量,汇总起来就是一个矩阵,被称为 共现矩阵(co-occurrence matrix)。
主要缺点:
对所有词进行向量化表示的计算复杂度极高。
1.3 基于推理的方法
除了基于计数的方法,还可以使用推理的方法把词用向量表示出来。
我们希望在已知上下文的前提下,"推测"当前位置的词是什么。
利用神经网络,接收上下文信息作为输入,通过模型计算,输出各个单词可能得出现概率;从而就可以根据上下文,预测该出现的单词了。
2. 词嵌入层
2.1 什么是词嵌入
自然语言是由文字构成的,而语言的含义是由单词构成的。即单词是含义的最小单位。因此为了让计算机理解自然语言,首先要让它理解单词含义。
词向量是用于表示单词意义的向量,也可以看作词的特征向量。将词映射到向量的技术称为 词嵌入(Word Embedding)。
比如 你这个词,用一系列的数据表示


将词转换为词向量时:
首先需要对文本进行分词,再根据需要进行清洗和标准化。----》比如一些助词标点符号啥的干掉
构建词表(Vocabulary),每个词对应一个索引。
使用词嵌入矩阵将词索引转换为词向量。
反正就是找到每一个单词的特征向量的表达
2.2 API使用
可使用torch.nn.Embedding来初始化词嵌入矩阵:
java
torch.nn.Embedding(num_embeddings, embedding_dim)
# num_embeddings:所有词的数量
# embedding_dim:词向量的维度这个词嵌入矩阵的话,就是传入一个词的id,就会返回这个词的意思表达了,返回向量

例:
先安装jieba库用于分词:pip install jieba。
这个是中文分词库
java
import torch
import torch.nn as nn
import jieba
java
text = "自然语言是由文字构成的,而语言的含义是由单词构成的。即单词是含义的最小单位。因此为了让计算机理解自然语言,首先要让它理解单词含义。"
java
#1. 分词,lcut精确模式分词,不会按照字拆开,而是按照--》词分开
original_words = jieba.lcut(text)
print(original_words)
但是还含有句号这些没用的东西
java
#自定义一组停用词
stopwords = {"的","是","而","由",",","。"}
java
#2.过滤停用词,构建词表(idToWord)
words = [word for word in original_words if word not in stopwords]
print(words)
java
#3.构建词表,,set可以去重
id2word = list(set(words))
print(id2word)
再来一个单词找id
java
#4.构建字典,保存word到索引号的映射(word2id)
word2id = dict()
for id,word in enumerate(id2word):
word2id[word] = id
print(word2id)
最后就是使用词嵌入矩阵把索引转换为词向量了
java
#5.构建一个词嵌入层
embed = nn.Embedding(num_embeddings=len(id2word), embedding_dim=5)词嵌入矩阵的num_embeddings是词的个数---》词嵌入矩阵行的个数
embedding_dim就是词嵌入矩阵列的个数---》每个向量的长度
java
#5.构建一个词嵌入层
embed = nn.Embedding(num_embeddings=len(id2word), embedding_dim=5)
这样的话,输入一个索引,就会得到一个向量
java
#6. 前向传播,传入单词索引号,得到词向量
for id ,word in enumerate(id2word):
# 不能直接传入id,因为深度学习中使用的都是张量
word_vec = embed(torch.tensor(id))
print(f"{id:>2}:{word:8}\t{word_vec.detach().numpy()}")
很显然这些矩阵就是词嵌入矩阵的参数,这些值一开始都是随机生成的--》没有什么含义
后面不断训练,就会变成真正能够表达含义的矩阵,具体是什么含义---》结合场景
2.3 词嵌入应用和NLP模型
应用--》搜索,翻译,生成文本
java
nn.Embedding.from_pretrained(embeddings=)这个from_pretrained就是使用别人已经训练好的词嵌入矩阵---》这个就是参数embeddings(必传)--》比如谷歌的word2vec-->但是后面还是要训练的
----》词生词
Seq2Seq----》句子生句子---》RNN--->编码器,解码器+Attention---->生成transformer---》大模型
3. 循环网络层
3.1 RNN层介绍
文本是连续的,具有序列特性。如果其序列被重排可能就会失去原有的意义。比如"狗咬人"这段文本具有序列关系,如果文字的序列颠倒可能就会表达不同的意思。
目前我们接触的神经网络都是前馈型神经网络。前馈(feedforward)是指网络的传播方向是单向的。具体地说,将输入信号传给下一层,下一层接收到信号后传给下下一层,然后再传给下下下一层...像这样,信号仅在一个方向上传播。虽然前馈网络结构简单、易于理解,并且可以应用于许多任务中。不过,这种网络存在一个大问题,就是不能很好地处理时间序列数据。更确切地说,单纯的前馈网络无法充分学习时序数据的性质。于是,循环神经网络(Recurrent Neural Network,RNN)应运而生。
意思就是我们传入的数据必须是连在一起的,有意义的,不像以前,传入的数据可以任意分开---》CNN神经网络就处理不了
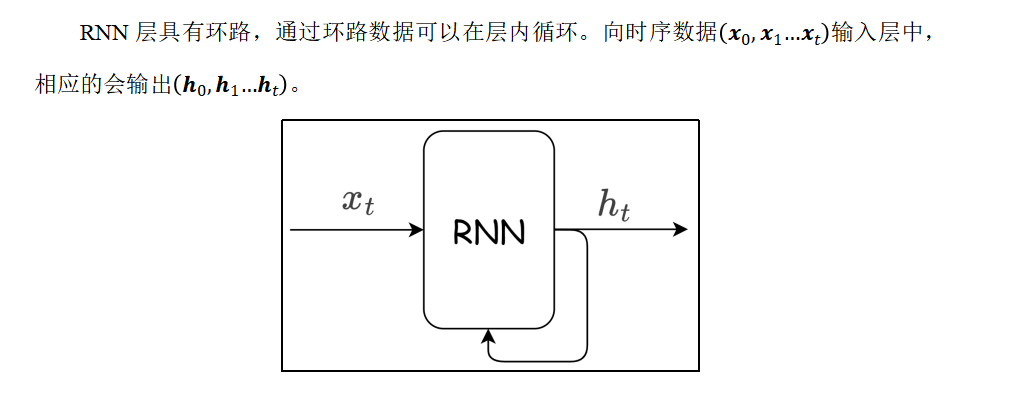
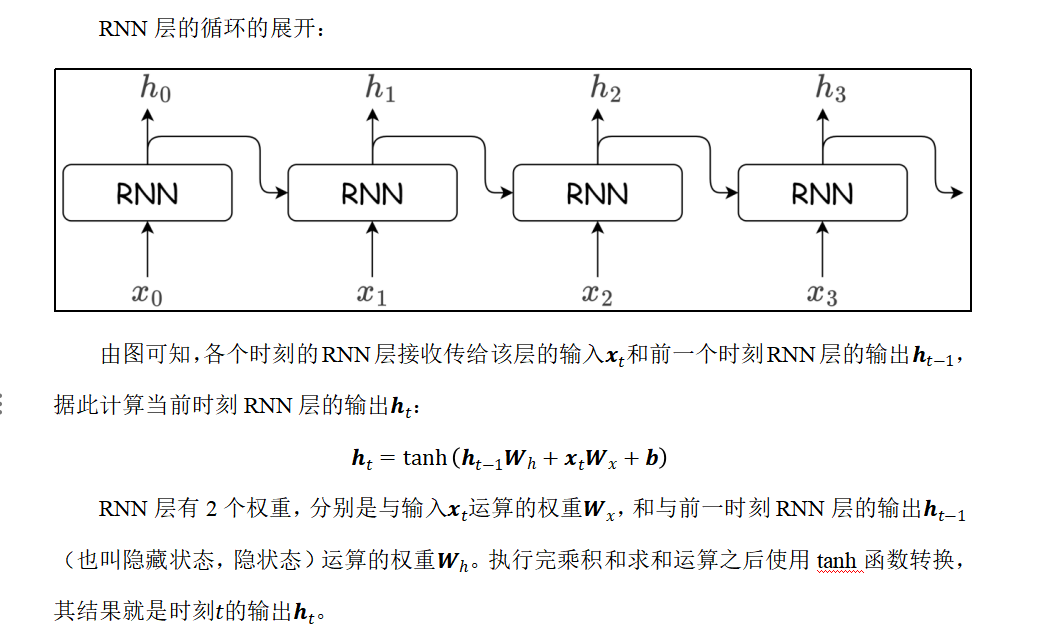
意思就是x0的输入,就有两个输出,一个h0给下一层,还有一个环路,和x1一起作为x1的输入
3.2 API使用
可使用torch.nn.RNN来初始化RNN层:
java
rnn = torch.nn.RNN(input_size, hidden_size, num_layers)
# input_size:输入数据的特征数量,,就是x
# hidden_size:隐藏状态的特征数量,就是h
# num_layers:隐藏层的层数,如果设置多个层,前一个隐藏层的输出作为下一个隐藏层的输入多层 RNN 中,只有第一层的输入维度是用户指定的 input_size,而从第二层开始,输入维度会自动 "继承" 上一层的 hidden_size,而非用户指定的 input_size。
调用时需要传入2个参数:
java
output, hn = rnn(input, hx)
# input:输入数据[seq_len序列长度, batch_size批量大小, input_size],input_size是词向量维度
# hx:初始隐状态[num_layers, batch_size, hidden_size],因为初始的时候没有h来输入
# output:输出数据[seq_len, batch_size, hidden_size]
# hn:隐状态[num_layers, batch_size, hidden_size]input(输入数据)
维度:seq_len, batch_size, input_size
seq_len:输入序列的长度(时间步数)L。例如,一句话有 5 个单词,seq_len=5。
batch_size:批量处理的样本数量N。例如,一次输入 32 句话,batch_size=32。
input_size:每个时间步输入的特征维度(如词向量维度)m。例如,每个单词用 128 维向量表示,input_size=128。
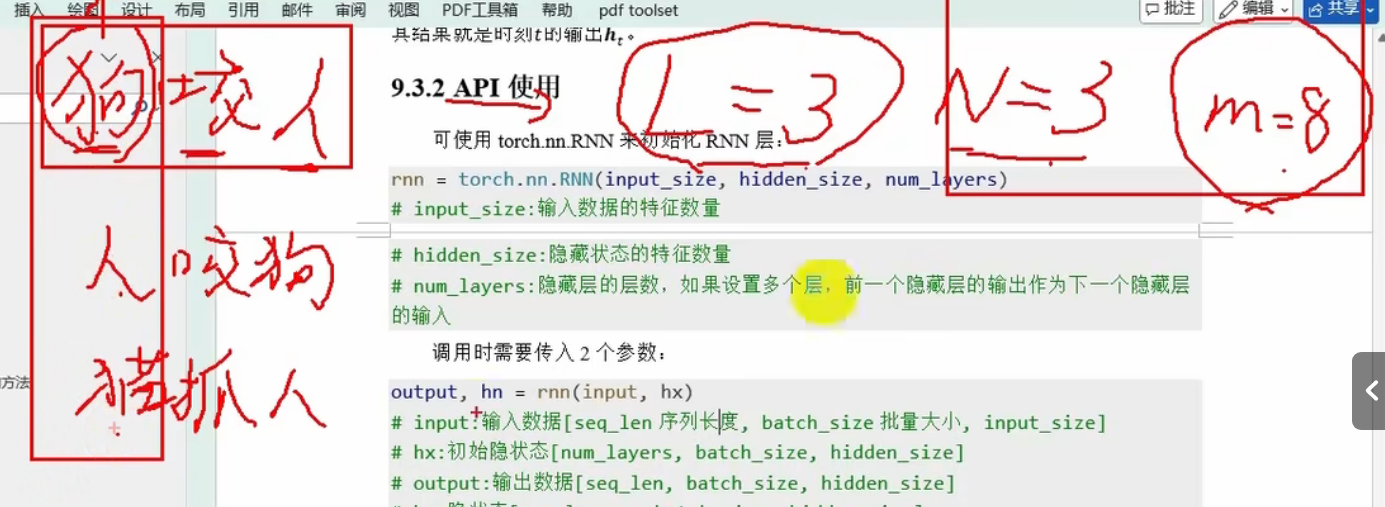
狗咬人:这个文本序列输入数据---》seq_len=3,有三个词,那么第一个时间步传入的x就是狗,第二个时间步传入的x就是咬,而且还要结合上一个时间步狗的输出结果一起处理
batch_size=3:三句话,狗咬人,人咬狗,猫爪人
seq_len*input_size:一个序列,一个句子的表达,横向
batch_size*input_size:第一个时间步,第一个词(狗,人,猫),的特征向量,纵向
hx(初始隐藏状态)
维度:num_layers, batch_size, hidden_size
num_layers:RNN 的层数(堆叠的 RNN 层数量)。例如,num_layers=2 表示两层 RNN 堆叠。
batch_size:与输入数据的批量大小一致。
hidden_size:隐藏状态的维度(内部记忆的维度)。
后边的x就是前面h的输入
output(输出数据)
维度:seq_len, batch_size, hidden_size
含义:包含 RNN 在每个时间步的输出。具体来说,outputt 是第 t 个时间步(对应输入序列的第 t 个元素)经过 RNN 计算后得到的输出,其值等于该时间步的隐藏状态(对于单层 RNN 而言)。
注意:若 RNN 是多层(num_layers > 1),output 仅包含最后一层在每个时间步的输出。
hn(最终隐藏状态)
维度:num_layers, batch_size, hidden_size
含义:包含 RNN 在最后一个时间步的隐藏状态,且按层划分。例如,hni 表示第 i 层 RNN 在最后一个时间步的隐藏状态。
java
import torch
import torch.nn as nn
java
#定义RNN层,input_size表示输入词向量的维度是8---》词的特征是8,,hidden_size表示隐藏状态特征数量,,num_layers表示2层的RNN
rnn = nn.RNN(input_size=8,hidden_size=16,num_layers=2)
java
#定义输入数据和初始隐状态,第一个1表示序列的长度---》一个字一个字生成推测
# 3是批量大小---》给几个词传进来,每次传三个词进来
# 8是inputsize,必须和RNN的input_size一样
input = torch.randn(1,3,8)
# 2表示两个RNN,就是num_layers,3是批量大小,,16是hidden_size
hx = torch.randn(2,3,16)
print(input)
print(hx)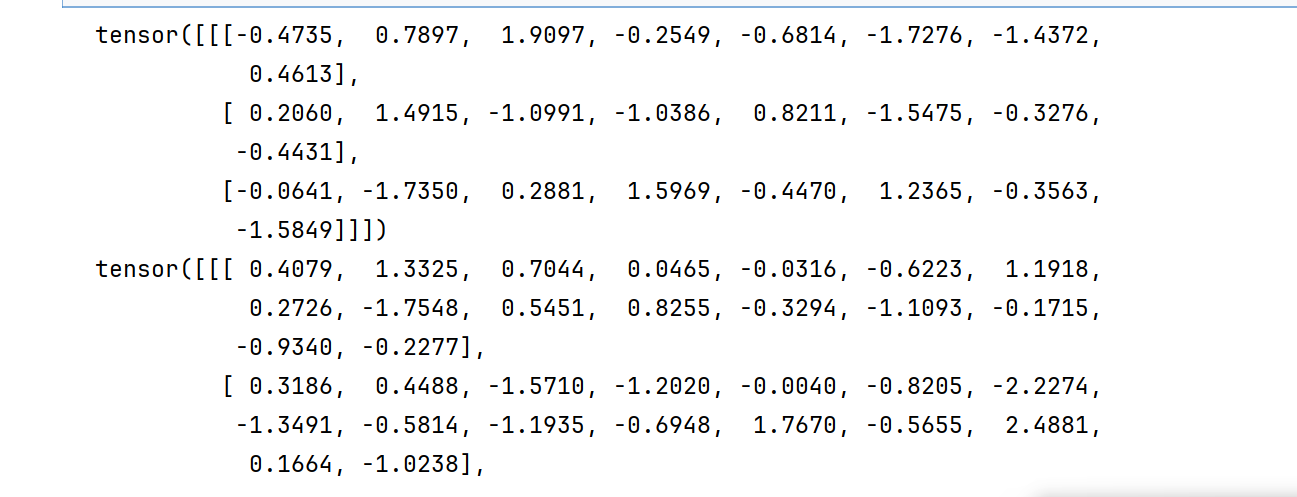
java
#前向传播,得到输出和隐状态
output,hn =rnn(input,hx)
print(output)
print(hn)
print(output.shape)
print(hn.shape)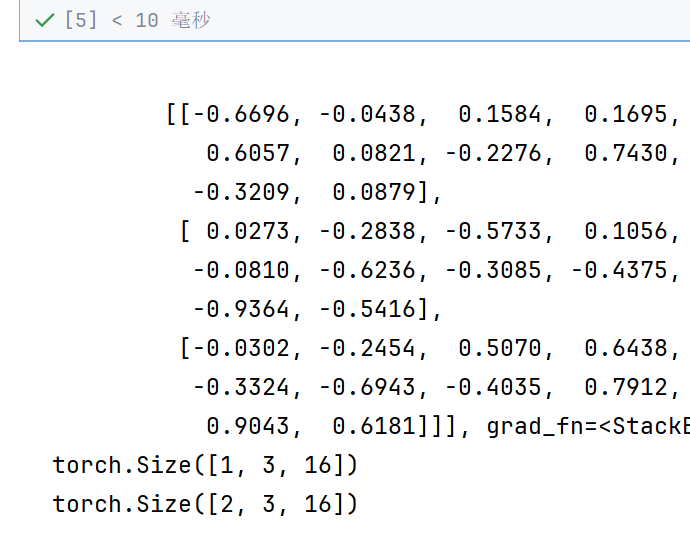
L序列大小为1,N批次大小为3---》那么输出就不会变---》变的只是输出维度
输出维度由输入维度的8变成了16
输出的隐状态,输出的是两层的隐状态---》所以是23 16
最后一层的隐状态就是output

java
input = torch.randn(3,3,8)
hx = torch.randn(2,3,16)
print(input)
print(hx)
java
output,hn =rnn(input,hx)
print(output)
print(hn)
print(output.shape)
print(hn.shape)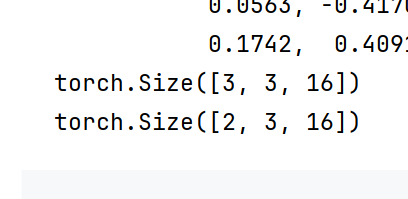
输出形状就变成了3316了
隐藏层还是2316,因为只有两层,与时间步无关
所以隐藏层hn的输出的是最后一个时间步,它的最后一个层,(空间上最后一层)
output输出的是最后所有时间步的最后一个层,时间上最后一步,所以它的最后一步与hn的最后一层是相同的值
4. 案例:古诗生成
生成一个词,生成一个序列,文本分类,文本翻译---》词嵌入
构建神经网络
4.1 数据预处理

起始给一个字---》生成古诗
数据在.txt文件中,每行为一首诗。
首先将每个字作为一个词构建词表。并将原文转换为索引序列。

古诗中每个字都当做一个词
java
import torch
from torch import nn,optim
from torch.utils.data import DataLoader,Dataset
#正则化---》针对字符串
import re
#1. 数据预处理
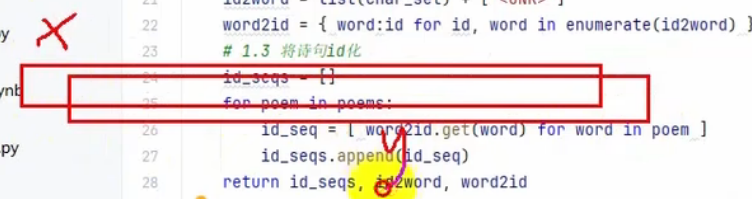
def preprocess_poems(file_path):
#定义字的集合(去重),保存诗id化之后的列表
char_set = set()
poems = []
#1.1 读取文件,保存
with open(file_path,'r',encoding='utf-8') as f:
for line in f:
#数据清洗,去掉标点和两侧空白,sub(r"[,。?!;:]","",line)表示把这些标点符号替换为空字符,strip表示去除空白
line = re.sub(r"[,。?!;:]","",line).strip()
#按字分割并去重,保存到set,list(line)把line变成一个字一个字的列表
char_set.update(list(line))
poems.append(list(line))
#1.2 构建词表
id2word = list(char_set) + ["<UNK>"]
word2id = {word:id for id,word in enumerate(id2word) }
#1.3 将诗句id化
id_seqs = []
for poem in poems:
id_seq = [word2id.get(word) for word in poem]
id_seqs.append(id_seq)
# id_seqs表示诗句中每行每个字的id,是一个二维列表
return id_seqs,id2word,word2id
id_seqs , id2word,word2id = preprocess_poems('./data/poems.txt')
print(len(id_seqs))
print(len(id2word))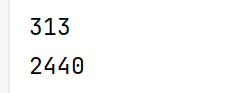
4.2 创建数据集
java
#2. 构建自定义数据集
# L=24,我们定义一个连续的24个字为x,然后这个24个字往后挪一位作为y输出
# 探讨每一个x与每一个y之间的关系
java
#2. 构建自定义数据集
# L=24,我们定义一个连续的24个字为x,然后这个24个字往后挪一位作为y输出
# 探讨每一个x与每一个y之间的关系
class PoetryDataset(Dataset):
# 传入原诗的id列表,以及序列化长度
def __init__(self,id_seqs,seq_len):
self.seq_len = seq_len
self.data = [] #保存数据元组,(x,y)的列表
#遍历所有诗
for id_seq in id_seqs:
#遍历当前诗的所有字(id)
for i in range(0,len(id_seq)-self.seq_len):
self.data.append( (id_seq[i:i+self.seq_len],id_seq[i+1:i+1+self.seq_len]) ) #(x,y)
# 返回数据集长度
def __len__(self):
return len(self.data)
# 通过索引id返回元素值
def __getitem__(self, idx):
x= torch.LongTensor(self.data[idx][0])
y= torch.LongTensor(self.data[idx][1])
return x,y
dataset = PoetryDataset(id_seqs,24)
print(len(dataset))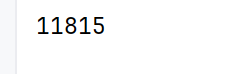
4.3 创建模型
词嵌入层→RNN→全连接层。
词嵌入层生成特征值向量
RNN:提取本质规律
全连接层:输出
----》输出词表(2400多个词)中每个词的输出概率
java
#3. 创建模型RNNLM
class PoetryRNN(nn.Module):
#初始化,vocab_size词表大小,embedding_dim输出词向量维度----》嵌入层参数
# RNN输入维度,就是词向量输出维度,hidden_size:隐状态维度,num_layers:层数
def __init__(self,vocab_size,embedding_dim,hidden_size,num_layers=1):
super().__init__()
#词嵌入层
self.embed = nn.Embedding(vocab_size,embedding_dim)
#RNN层,batch_first=True表示把批次N放在第一维度,L序列长度放在第二层
self.rnn = nn.RNN(embedding_dim,hidden_size,num_layers,batch_first=True)
#输出层--全连接,最后输出是词表中每个词出现概率,所以是vocab_size
self.linear = nn.Linear(hidden_size,vocab_size)
#前向传播
def forward(self,input,hx=None): #hx是初始隐状态
embed = self.embed(input)
output,hn = self.rnn(embed,hx)
output = self.linear(output)
return output,hn
model = PoetryRNN(vocab_size=len(id2word),embedding_dim=256,hidden_size=512,num_layers=2)4.4 模型训练

这个是损失函数预测值和目标值输入形状规定
Input: Shape :math:(C), :math:(N, C) or :math:(N, C, d_1, d_2, ..., d_K)
- Target: If containing class indices, shape :math:
(), :math:(N)or :math:(N, d_1, d_2, ..., d_K)with
第一个对应是(N, C)和(N)
表示类别概率,和对应实际类别,这个是可以直接计算的。(N)可以不用独热编码展开
N表示批次---》有多少个
C表示有多少个类别,特征
但是现在加了L
所以L维度要放在后面
java
#4. 模型训练--->不用测试集测试了
def train(model,dataset,lr,epoch_num,batch_size,device):
#4.1 初始化相关
model.train()
model.to(device)
#定义损失函数和优化器
loss = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(),lr=lr)
#4.2 迭代训练
for epoch in range(epoch_num):
train_loss =0
#定义数据加载器
dataloader = DataLoader(dataset,batch_size=batch_size,shuffle=True)
for batch_idx,(x,y) in enumerate(dataloader):
x,y = x.to(device),y.to(device)
#4.2.1前向传播
output,_ = model(x)
#4.2.2计算损失
# output:(N,L,C)...y:(N,L),,,这就是为什么前面要把N放在第一维度原因,不放的话,无法计算,然后就是为什么y有N呢,因为batch_size划分了小批次
#L表示词的数量,C表示词的特征维度,就是每个类,每个词的概率。参照原码,所以output(N,C,L)
# loss_value = loss(output,y)
loss_value = loss(output.transpose(1,2),y)
#4.2.3反向传播
loss_value.backward()
#4.2.4 更新参数
optimizer.step()
#4.2.5梯度清零
optimizer.zero_grad()
train_loss += loss_value.item()*x.shape[0]
#打印进度条
print(f"\rEpoch:{epoch+1:0>2}[{'=' * int ((batch_idx+1)/len(dataloader)*50) }]",end="")
#本轮训练结束
this_loss = train_loss/len(dataset)
print(f"train_loss:{this_loss:.4f}")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#超参数
lr = 1e-3
epoch_num = 20
batch_size = 32
train(model,dataset,lr,epoch_num,batch_size,device)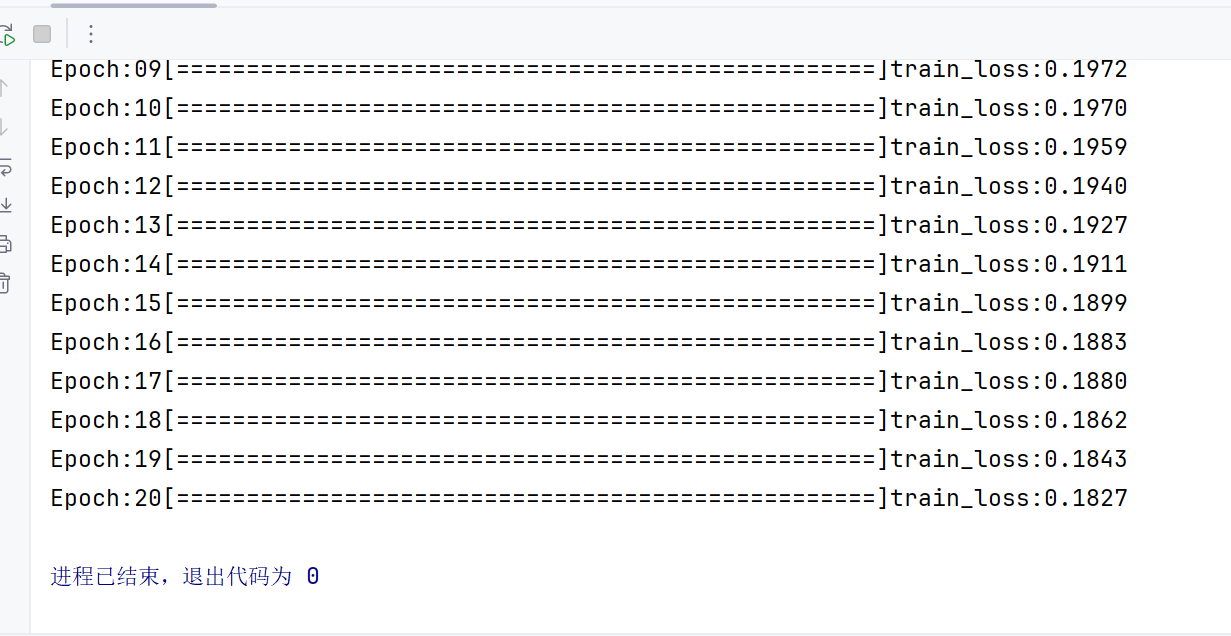
4.5 生成新诗
我们虽然按照24的长度训练模型,这个是我们训练集数据定死的,但是我们可以用1的长度来预测模型
java
#5.生成新诗(测试)
# start_token表示输入数据,line_num表示生成四句话,一句话有两个诗,中间有逗号,line_length表示每句话的长度
def generate_poem(model,id2word,word2id,start_token,line_num=4,line_length=7):
model.eval()
poem =[]#记录生成结果
current_rest_len = line_length
#5.1 先把start_tokenID化
start_id = word2id.get(start_token,word2id["<UNK>"])#word2id["<UNK>"如果找不到这个字,就取UNK的id
if start_id != word2id["<UNK>"]:
poem.append(start_token)
current_rest_len-=1
#5.2 定义输入数据----->应该是N*L的形式,N是批量数,L是序列长度--二维
input = torch.LongTensor( [[start_id]] ).to(device)
#5.3 迭代生成数据
with torch.no_grad():
# 按行生成诗句
for i in range(line_num):
#每行生成两句诗
for interpunction in [",","。\n"]:
while current_rest_len>0:
# 逐字生成诗句,output:N,L,C,,,,C就是每个词每个类对应概率,,,,1*1*2439---》还不是预测概率,因为没有进行softmax,也没有进行损失(自带softmax)
output, _ = model(input)
# 调用softmax,得到每个词的额分类概率,,,dim=-1 表示沿着最后一个维度进行 softmax 运算。
prob = torch.softmax(output[0, 0], dim=-1)
# 基于概率分布,得到下一个随机的id
# 这是 PyTorch 中用于多项式分布采样的函数。它根据输入的概率分布(prob),按照概率大小随机抽取指定数量的样本(索引),概率越高的元素被选中的可能性越大。
# prob:输入的概率分布张量(由之前的 torch.softmax 得到,满足沿指定维度元素和为 1)。
# num_samples=1:表示只抽取 1 个样本(即 1 个索引 id)。
next_id = torch.multinomial(prob, num_samples=1)
# 将id转换成word,放入列表
poem.append(id2word[next_id.item()])
# 更新input,长度减一
current_rest_len -= 1
input = next_id.unsqueeze(0) # 增加一个维度,因为必须input是二维数据
#本句生成结束,添加标点符号
poem.append(interpunction)
current_rest_len = line_length
return "".join(poem)
for i in range(10):
print(generate_poem(model,id2word,word2id,start_token="一",line_num=4,line_length=7))
5. 扩展


