训练一个顶级的实时目标检测模型,要花多少钱?
这个问题,放在几年前,答案可能是"天价"。你得准备海量的数据,堆上成百上千张显卡,跑上几周甚至几个月。到了今天,虽然技术成熟了不少,但一些顶会论文里的模型,依然像娇贵的兰花------它们在特定的、昂贵且不公开的"温室"(超大规模的预训练数据集)里长大,旁人想复现?门都没有。
最近读到一篇新论文,讲的正是这个痛点。一群来自佐治亚理工学院和北京交通大学的 researchers,直接上手"拆解"了这个问题。他们提出了一个叫 Le-DETR 的新模型,读完之后,我觉得最有意思的不是它刷新的几个精度指标,而是他们做事的思路:在大家拼命往模型里塞东西的时候,他们选择做减法,而且减在了最关键的地方------预训练成本。
为什么这篇论文值得关注?
实时目标检测领域正在经历一场「路线之争」:YOLO 系列一路卷到了 v13,而 Transformer 阵营的 RT-DETR 系列也在奋起直追。但 RT-DETR 家族有一个被社区长期忽视的「隐痛」------预训练成本极高。
具体来说,RT-DETRv2 的骨干网络需要先在 400 万张未公开的过滤图像 上做知识蒸馏预训练,再在 ImageNet-1K 的 100 万张图像上微调,总计用到约 500 万张图像。而且那 400 万张图像根本不开源,这直接导致了两个严重问题:
- 无法公平复现: 想从头训一个 RT-DETR?骨干网络的预训练权重是「黑箱」
- 创新被锁死: 社区被迫只能用 PP-HGNetv2 或 PResNet 这两个骨干,想换新架构?没门
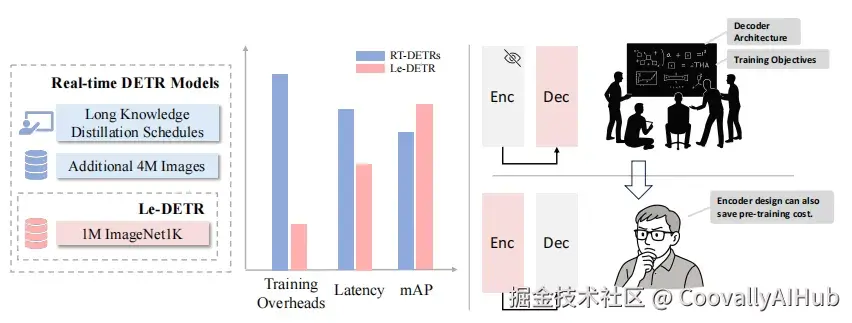
如图2所示,RT-DETRv2 的骨干网络需要先在 400 万张未公开的过滤图像 上做知识蒸馏预训练,再在 ImageNet-1K 的 100 万张图像上微调,总计用到约 500 万张图像。而且那 400 万张图像根本不开源,这直接导致了两个严重问题:
作者做了一个关键消融实验来证明这个问题有多严重:把 RT-DETRv2-L 的知识蒸馏和额外训练图像去掉后,mAP 从 53.4 直接掉到 51.6(↓1.8)。也就是说,RT-DETR 有相当一部分性能是靠「堆预训练数据」撑起来的。
Le-DETR 的核心主张很直接:这 400 万张额外图像根本不是必需的,那只是对次优架构设计的「补偿」。通过更好的架构设计,仅用 ImageNet-1K(100 万张图像)就能达到甚至超越 SOTA。
而且值得注意的是,以往的 D-FINE、DEIM 等工作主要集中在解码器架构和训练目标的改进上,Le-DETR 反其道而行,把重心放在了编码器设计上------这是一个被低估的方向。
核心方法:三板斧打天下
Le-DETR 的整体架构遵循标准的实时 DETR 范式:骨干网络 → 编码器 → 解码器。但在骨干和编码器两个关键环节做了深度重新设计。
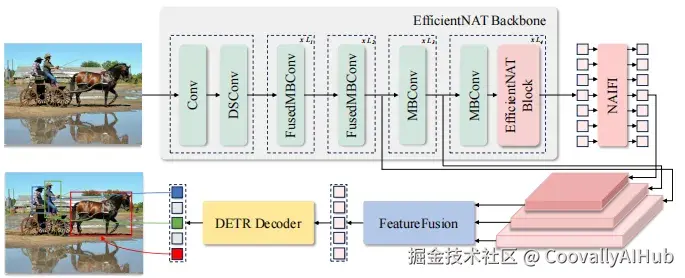
- EfficientNAT 骨干网络:卷积 + 局部注意力的混合设计
作者从 EfficientViT 出发,提出了全新的 EfficientNAT 骨干。核心设计思路是**「前三阶段用高效卷积提速,最后一阶段用局部注意力提质」:**
四阶段架构:
- Stem 层: 深度可分离卷积(DSConv),将输入图像映射到特征空间
- Stage 1-2: Fused MBConv(融合移动卷积),保证浅层高效处理
- Stage 3: 标准 MBConv(移动卷积),特征图逐渐缩小、通道逐渐增多
- Stage 4: EfficientNAT Block = Neighborhood Attention + MBConv FFN
每个阶段的第一个 block 负责下采样:空间分辨率减半,通道数翻倍。
关键创新在 Neighborhood Attention(邻域注意力)。 与标准 self-attention 对所有位置计算注意力不同,NA 只关注每个 query 周围的局部邻域(kernel size = k)。给定输入 X ∈ R^{n×d},对第 i 个 token,其注意力权重只在 k 个最近邻上计算:
text
NA_k(i) = softmax(A_k_i / √d) · V_k_i
其中 A_k_i 是 query_i 与其 k 个最近邻 key 的点积加上相对位置偏置。这将注意力计算从 O(n²) 降低到 O(n·k),同时能更好地保留局部空间结构信息。
- 骨干缩放策略:不同尺度需要不同的分配模式
这是论文中一个非常有实践价值的发现。作者系统研究了三种 block 分配策略:

最终选定的配置:
- EfficientNAT-M: block 数 = (1, 1, 2, 2),通道维度 = (32, 64, 128, 256, 512)
- EfficientNAT-L: block 数 = (1, 1, 4, 4),采用均衡分配 P_A
- EfficientNAT-X: block 数 = (2, 7, 15, 2),采用前重分配 P_C
在 ImageNet-1K 上的验证也支持这一结论:P_C-2 配置(2, 7, 15, 2)达到了 82.9% Top-1 准确率,在 X 尺度上全面碾压 P_A 和 P_B 的各种变体。
这告诉我们一个重要经验:模型缩放不是简单地等比放大所有层,不同规模有不同的最优分配模式。
- NAIFI 编码器:用局部注意力替换全局注意力
在编码器部分,作者提出了 NAIFI(Neighborhood Attention-based Improved Feature Inference)模块,用 Neighborhood Attention 替换了 RT-DETR 原有的 AIFI(基于全局自注意力的特征推理)。
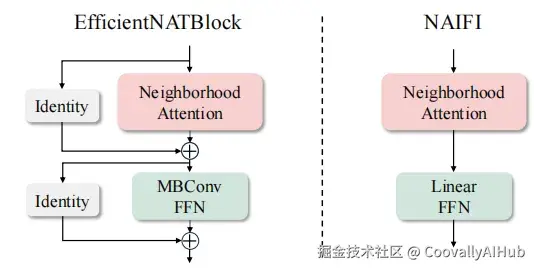
NAIFI 是一个单层的邻域注意力 Transformer,使用较小的 kernel size(论文中为 63)来优化特征表示。其结构比原始 AIFI 更简洁:Neighborhood Attention → Linear → FFN。
效果立竿见影:
- mAP:54.1 → 54.3(+0.2)
- 延迟:5.18ms → 5.01ms(快了 3.3%)
精度提升的同时还加速了,这说明对于实时检测任务,编码器其实不需要全局注意力,局部注意力就够了------而且更好。
此外,解码器部分使用了 Flash Attention 加速自注意力推理,并沿用了 DINO 框架中训练时每层都加 prediction head、推理时减少层数的策略。
实验结果:全面碾压
- 主实验对比(COCO Val 2017)
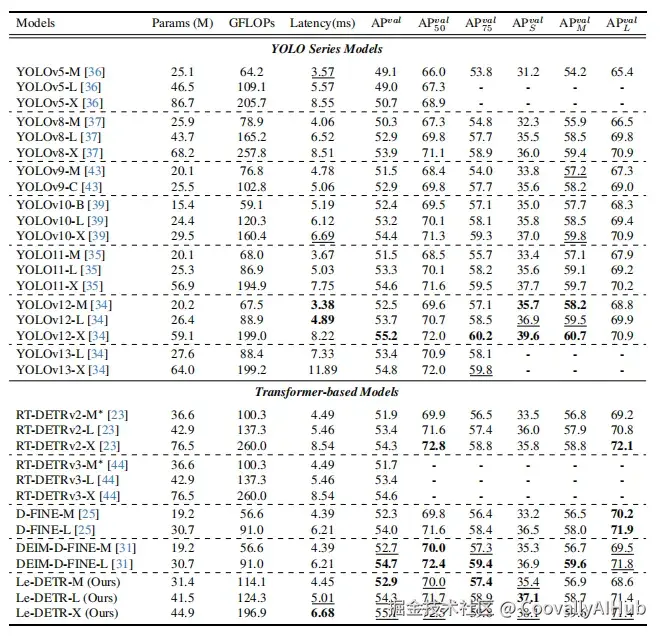
vs YOLO 系列:
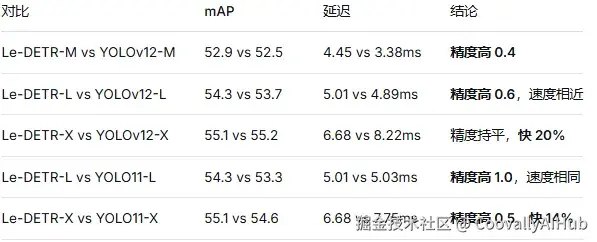
vs DETR 系列:
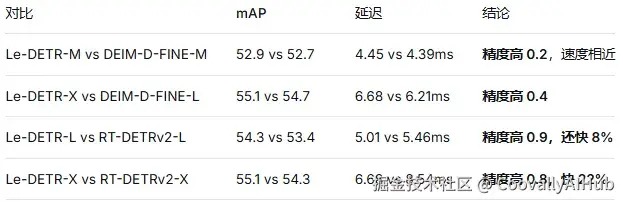
杀手级数据:在相同预训练条件下(都只用 ImageNet-1K),Le-DETR-L 比 RT-DETRv2-L 高出 2.7 mAP! 这直接说明了架构设计优势远大于数据量堆砌。
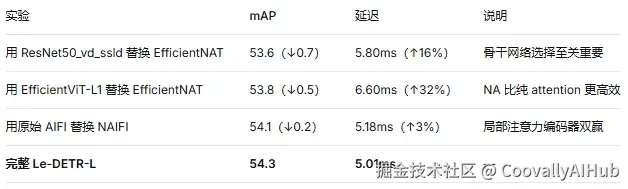
- 消融实验
组件消融(基于 Le-DETR-L):
解码器层数消融:
训练统一使用 6 层解码器,推理时可灵活裁剪:
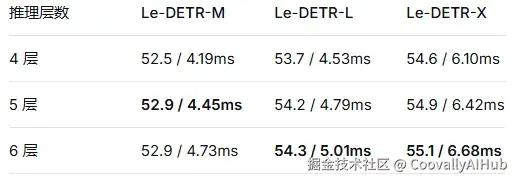
Le-DETR-M 用 5 层推理就能达到 6 层的精度,省了 0.26ms。这种「训多推少」的策略在实际部署中很实用。
技术启示
- 预训练数据量不是万能药
Le-DETR 证明了一个重要事实:如果模型架构本身设计不佳,堆数据只是治标不治本。RT-DETRv2 去掉 400 万额外图像后 mAP 掉 1.8,而 Le-DETR 用同样少的数据反而比原始 RT-DETRv2 高 0.9------好的架构可以从根本上减少对数据的依赖。
- 局部注意力是实时检测的最佳拍档
全局自注意力的 O(n²) 复杂度对实时推理是个大负担。Neighborhood Attention 既保留了注意力机制捕获空间关系的能力,又将计算量限制在可控范围。Le-DETR 的结果表明,对于目标检测这种天然具有空间局部性的任务,局部注意力甚至比全局注意力表现更好。
- 编码器设计被严重低估
过去两年 DETR 系列的改进几乎都集中在解码器和训练目标上(D-FINE 的 FDR/GO-LSD,DEIM 的 MAL 损失),Le-DETR 证明了在编码器端同样有巨大的优化空间,而且编码器的改进还能反向降低骨干预训练的成本。
- 模型缩放是一门学问
不同规模的模型需要不同的 block 分配策略(L 用均衡,X 用前重),这提醒我们在设计模型族时不能简单地线性缩放,每个尺度都值得单独实验验证。
局限性
作者诚实地指出了两点限制:
- 仍需 ImageNet-1K 预训练: 虽然比之前的 500 万张图像少了 80%,但 YOLO 系列完全不需要额外预训练(直接在 COCO 上从头训),DETR 系列在这方面仍有差距。作者期待未来出现真正零预训练的实时 DETR
- Neighborhood Attention 的部署兼容性: NA 目前在 ONNX 和 TensorRT 导出方面支持有限,可能影响边缘设备部署。不过社区对 NA 的 kernel 支持正在快速推进
论文信息
论文标题: Revisiting Real-Time Detection Transformer with Efficient Encoder Design
arXiv: 2602.21010
代码/权重: 即将开源
机构: SHI Labs @ Georgia Tech,北京交通大学