想象一下,你同时用两种方法教导两个学生解数学题。一个学生(SFT)只是死记硬背你做过的每一道例题,连你的笔迹都想模仿。另一个学生(RL)呢,你只告诉他答案是对是错,让他自己琢磨规律。考试的时候,遇到没讲过的题,谁更可能答对?
答案似乎是明摆着的:那个自己琢磨的学生,更"聪明",更能举一反三。
这不仅仅是比喻。在训练当下最火的视觉语言模型(VLM)时,工程师们也遇到了同样的困惑。把模型扔进"题海"里,用标准答案进行监督微调(SFT),它在熟悉题目上能考满分,但题目稍微换个花样,立马抓瞎。可如果用强化学习(RL),模型不直接看答案,只根据结果反馈自己摸索,它的泛化能力,也就是应对新问题的本事,反而更强。
为什么?RL身上到底藏着什么灵丹妙药?
最近读到一篇有意思的论文,它从一个全新的角度------数据本身,给出了一个让人信服的答案。论文的观点很直接:RL之所以强,不是因为它算法多高明,而是因为它"挑食",尤其爱吃那些难度适中的"中等题"。
RL的"挑食"本能
怎么理解RL的"挑食"?论文里做了个有趣的分类。对于任何一个问题,让模型自己生成8个答案,然后根据答案的正确情况,把问题分成三类:
- 容易题: 8个答案全对。
- 困难题: 8个答案全错。
- 中等难度题: 答案有对有错,模棱两可。
你看,RL训练时,对于容易题和困难题,模型怎么答结果都一样,缺乏改进的"动力"。只有面对那些有对有错的中等题,模型才会感到"困惑",进而产生强烈的"求知欲",从错误中学习,向着正确答案调整。它的注意力,就这么自然而然地被那些"拧巴"的数据给吸引过去了。
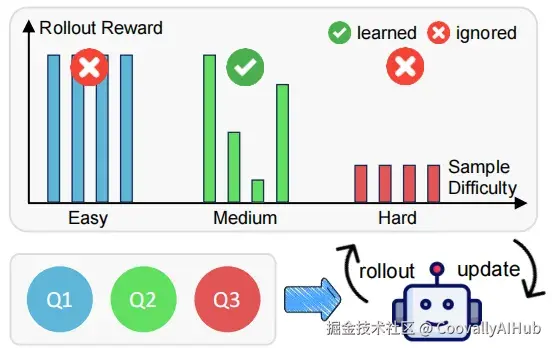
与之相反,SFT可不管这些。它像个勤勤恳恳但不知变通的老实人,对所有题目一视同仁,硬背答案。尤其是那些"困难题",虽然数量不多,但对模型的影响却大得惊人。
困难的"坏学生"效应
为了验证这个想法,研究人员做了个实验:分别用"容易题"、"中等题"和"困难题"去微调模型,然后看看它们在没见过的题目上表现如何。
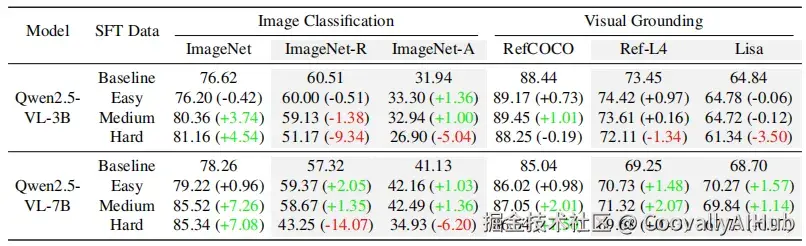
结果有点出乎意料。专攻"困难题"的模型,在熟悉的数据集上表现最好,但一遇到新题型,成绩就一落千丈。比如一个7B参数的模型,用困难题练完后,在熟悉的数据上准确率提升了7%,但在一个风格迥异的测试集上,直接暴跌14%!而那些用"中等题"训练的模型,表现则稳健得多,新旧考试都能hold住。
这个实验揭示了一个残酷的事实:SFT泛化能力差,很可能就是被一小撮"害群之马"------那些极端困难的样本------给拖累了。
说起来,这背后的道理其实很朴素。想象一下,一个学生如果天天只刷偏题、怪题,他的思维方式会被训练得越来越窄,自然无法适应正常的考试。而一个学生如果主要精力都花在那些"跳一跳够得着"的中等题上,他反而能建立起更稳固、更通用的知识框架。
既然知道了病因,那药方不就来了吗?
论文提出的方法,名字有点绕,但思路极其简单粗暴,我叫它"纯净版SFT"(DC-SFT)。核心就一句话:在SFT之前,先把那些"困难题"给扔掉!
结果呢?这个简单到有点"不讲武德"的方法,效果却好得出奇。
- 超越RL: 只用"中等题"训练的"纯净版SFT",其泛化能力已经能和RL并驾齐驱,甚至在某些指标上反超。这说明RL的"聪明",很大程度上就是源于它对数据的"筛选",而不是算法本身有什么魔法。
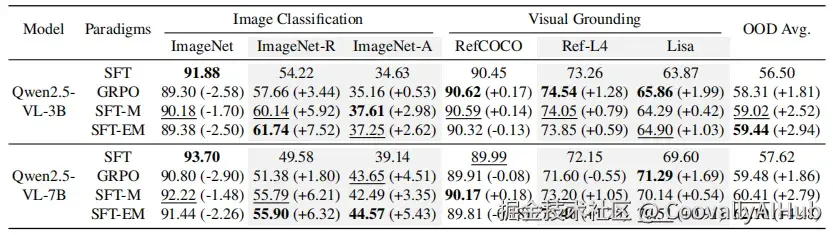
- 效果更佳: 如果把"容易题"和"中等题"一起用来训练,效果最好。这就像是给学生打好了扎实的基础知识(容易题),又让他练习了适量的拓展题(中等题),自然无往不利。
- 稳定高效: RL训练起来像个任性的艺术家,情绪不稳定,动不动就"掉分"。
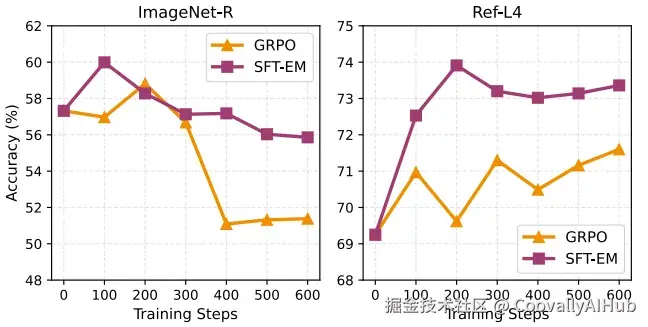
而"纯净版SFT"稳如老狗,训练速度还快了3到5倍。这简直就是既想马儿跑,又想马儿不吃草的完美解决方案。
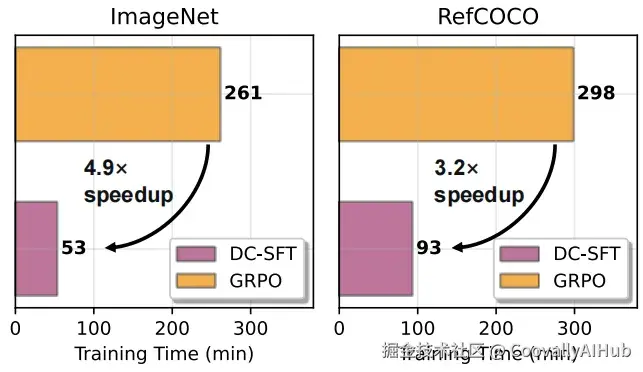
为什么扔掉"困难题"效果这么好?
这可能是很多人心里的疑问。论文也做了个漂亮的分析。
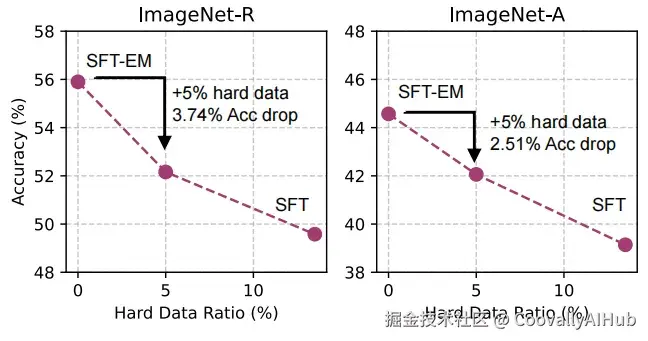
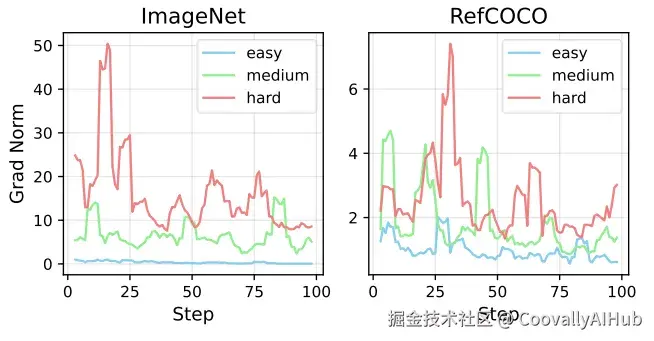
他们发现,哪怕只加入5%的困难题,模型的泛化能力就会明显下滑。这就像一碗白米饭里掉进几颗老鼠屎,坏了一整锅。原因在于,困难题在训练时会产生巨大的"梯度"------你可以理解为它对模型的"冲击力"特别强,总是能把模型的参数往奇怪的方向拽。模型为了迎合这些怪题,反而学不到普适的规律。
不只是泛化,推理能力也更强
更有趣的是,这个方法的好处不仅体现在普通的视觉任务上。在更复杂的数学推理测试中,"纯净版SFT"同样吊打了标准SFT和RL,拿下了多个测试集的最高分。
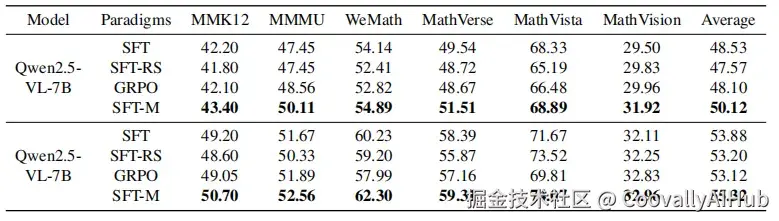
这暗示着,剔除"噪声"数据,让模型专注于高质量的"中等题",或许是通往更强推理能力的捷径。
总结
读完这篇论文,我最大的感受是:有时候,我们追求算法的复杂性,却忽略了最根本的数据问题。RL的崛起,或许不是因为它的算法更贴近生物学习机制,而仅仅是因为它恰好实现了一种更智能的数据过滤。
当然,硬币有两面。这篇论文的实验主要集中在一个特定系列的模型上(Qwen2.5-VL),且大多是参数高效的微调。它是否适用于更大规模的模型、更广泛的场景,还需要更多验证。但它无疑给我们提了个醒:给模型喂数据,不是越多越好,更不是越难越好。如何构建一份难度适中、结构合理的"营养餐",可能是未来提升模型能力更关键、更高效的途径。
毕竟,聪明不只是一种天赋,更是一种"挑食"的习惯。