春晚舞台上,机器人群体的整齐划一令人惊叹------但如果想让机器人真正理解并模仿人类的复杂动作,我们需要怎样的视觉技术?
当16台机器人在春晚舞台上旋转跳跃时,它们的每一个动作都经过工程师数月精心编排。然而,真正智能的机器人不应只会重复预设动作,而应能观察人类、理解姿态、即时模仿。这正是姿态估计技术试图解决的难题------让机器人拥有"看懂"人类动作的视觉智能。

本文将带你深入探索基于YOLO26-Pose的零样本姿态估计技术,揭秘如何让机器人在无需特定场景训练数据的情况下,实时理解并复现人类动作。
姿态估计技术解析:从看懂到理解
姿态估计作为计算机视觉的核心技术,通过检测图像或视频中人体/物体的关键点并构建骨架模型,实现对姿态和运动的量化分析。在机器人领域,这项技术正在开启全新应用场景:
- 模仿学习: 机器人通过观察人类操作,学习抓取物体、使用工具
- 人机协作: 实时理解工人意图,实现安全高效的人机协同作业
- 远程操控: 将操作者动作精确映射到远端机器人,完成危险环境作业
- 技能传授: 专家动作数字化,批量复制到多台机器人
然而,传统姿态估计方案面临一个根本性挑战:每个新场景都需要重新训练。当你把机器人从春晚舞台搬到工厂车间,光照、背景、视角全都变了,模型精度断崖式下降------这背后的代价是数千张标注图像和数周训练时间。
零样本姿态估计:突破数据依赖的桎梏
零样本姿态估计技术的核心突破在于:模型无需针对特定场景训练,就能在新环境中准确预测姿态关键点。
核心技术优势
- 预训练知识迁移
基于海量多样化数据训练的基础模型
学习到通用的视觉模式和结构关系,不依赖于特定场景特征
- 强大的泛化能力
适应未知环境的光照变化、背景干扰、遮挡挑战
处理未见过的物体类别和姿态变化,真正实现"举一反三"
- 可转移特征表示
复用已学习的底层特征提取能力
通过少量示例即可快速适应新任务,大幅降低数据依赖
这种技术突破意味着:春晚舞台上的机器人无需重新训练,就能适应工厂车间的复杂环境;演示给机器人的新动作,可以立即被理解并复现------这正是实现通用机器人智能的关键一步。
YOLO26-Pose架构解析:速度与精度的完美平衡
在众多姿态估计方案中,YOLO26-Pose凭借其独特的架构设计,成为机器人实时应用的理想选择。
- 主流方案对比
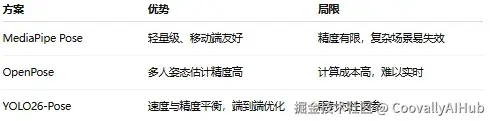
- YOLO26-Pose核心创新
-
多任务统一架构
YOLO26-Pose采用共享特征提取骨干网络,同时输出检测框和关键点坐标。这种设计大幅降低计算开销,使姿态估计成为目标检测的"副产品"------无需额外计算即可获得关键点信息。
-
实时推理性能
专为机器人实时控制优化,在Jetson等边缘设备上可达30+FPS。这意味着机器人能以每秒30帧的速度理解人类动作,实现流畅的实时响应。
-
零样本适应能力
通过大规模多样化数据预训练,模型学习到通用的姿态表示。即使面对训练集中从未出现过的新场景、新动作,仍能保持稳定可靠的姿态估计能力。
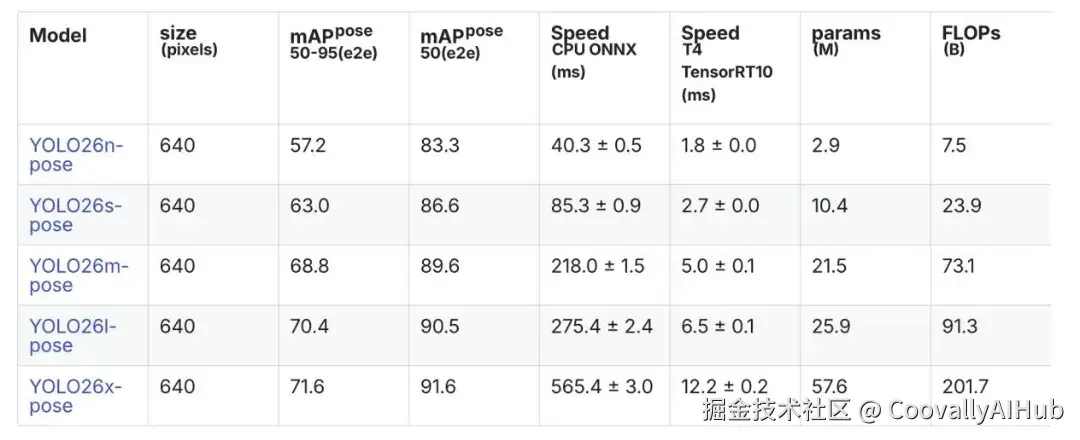
技术展望
- 多模态融合
结合深度信息、IMU数据,从2D姿态估计向3D空间理解演进,提升机器人对复杂环境的感知能力。
- 自监督学习
进一步减少对标注数据的依赖,让机器人在实际工作中持续学习、自我提升。
- 具身智能整合
将姿态估计与机器人运动规划深度融合,实现从"看懂动作"到"学会动作"的完整闭环。
结语
从春晚舞台上整齐划一的机器人表演,到工厂车间里灵活协作的智能助手,姿态估计技术正在重新定义人机交互的边界。零样本学习的突破,让机器人真正具备了理解人类动作的通用视觉能力------无需为每个新场景重新训练,无需为每个新动作采集数据。
正如春晚机器人展示的群体智能,未来的机器人也将通过姿态估计技术,学会观察、理解、模仿,最终与人类实现真正的协作共融。在这场机器人视觉革命中,掌握零样本姿态估计技术,就是掌握了通往通用机器人智能的钥匙。
技术思考:零样本学习正在重塑机器人视觉系统的开发范式,但需要注意其在新场景下的误差累积问题。建议在关键安全场景中保留人工复核机制,或采用Coovally平台提供的模型监控功能实时检测性能衰减。