在 RAG 智能问答系统的搭建系列中,我们已逐步攻克数据处理、向量存储、检索优化等关键环节。但当系统需要对接结构化数据库,让非技术用户通过日常语言获取数据时,单纯的文本检索已无法满足需求。此时,Text2SQL 技术与工作流的结合,成为打通 "自然语言→数据库查询→结果反馈" 全链路的核心方案。本文将带您完整实现一套基于 RAG 的数据库智能查询系统,让用户无需掌握 SQL 语法,也能轻松从数据库中提取所需信息。
一、Text2SQL:让自然语言成为数据库 "钥匙"
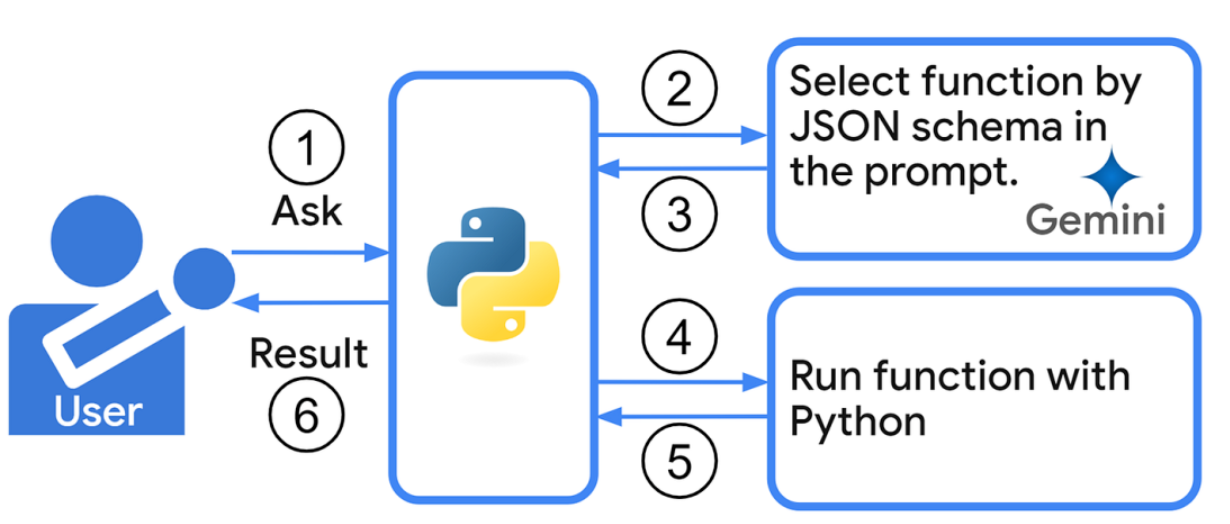
在传统数据库使用场景中,用户必须熟悉 SQL 语法才能编写查询语句 ------ 这对企业中的业务人员、教育场景下的师生等非技术群体来说,无疑是一道高门槛。而 Text2SQL 技术的出现,恰好解决了这一痛点:它能将用户输入的自然语言(如 "获取所有 2022 年入学学生的基本信息"),自动转换为可执行的 SQL 语句,让 "用聊天查数据" 成为可能。
1.1 Text2SQL 的核心能力
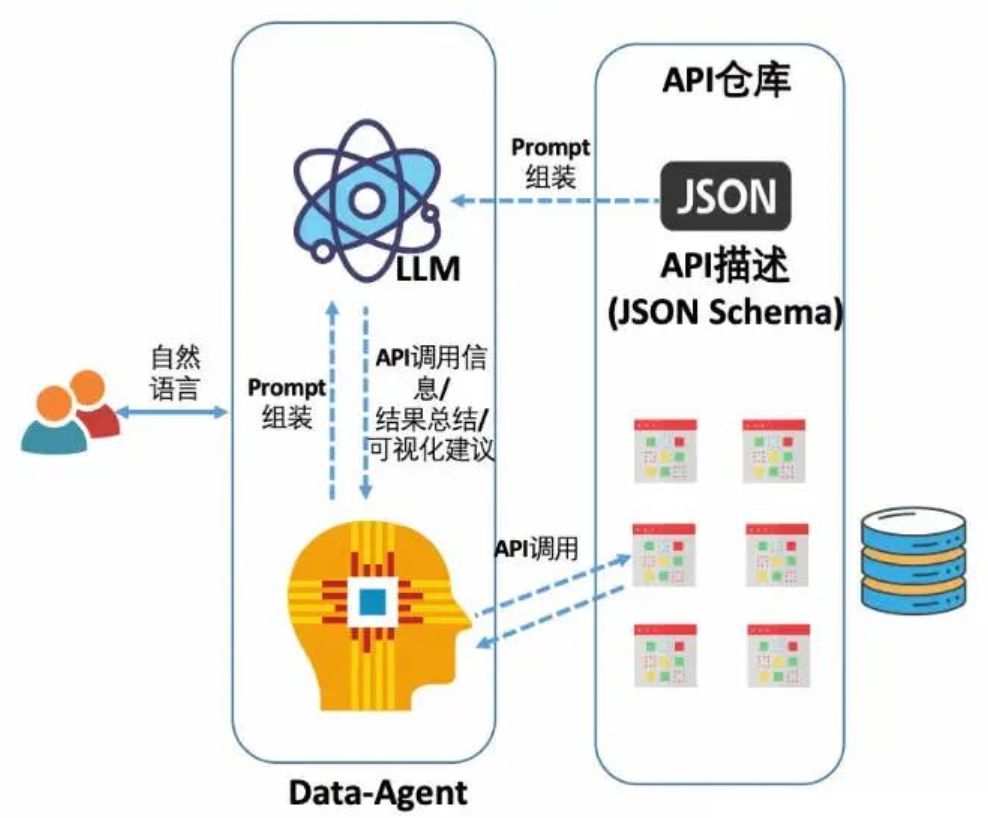
一套成熟的 Text2SQL 系统,需要具备四大核心功能,才能确保转换的准确性和实用性:
- 自然语言理解(NLU):通过分词、词性标注、命名实体识别等 NLP 技术,精准解析用户提问的意图。例如,当用户问 "计算机专业学生的高等数学成绩" 时,系统需识别出 "计算机专业" 是筛选条件、"高等数学" 是目标科目、"成绩" 是查询字段。
- 语义解析:将理解后的自然语言,映射为数据库可识别的结构信息。这一步需要明确查询涉及的表名(如 "student" 表、"score" 表)、列名(如 "major""subject""score")、筛选条件(如 "major = ' 计算机科学 '"),甚至多表关联关系(如通过 "student_id" 关联学生表与成绩表)。
- SQL 生成:根据语义解析结果,生成语法正确的 SQL 语句。既支持简单的 SELECT 查询(如 "获取所有学生姓名"),也能处理包含 JOIN、WHERE、GROUP BY 等复杂操作的语句(如 "统计各专业学生的平均年龄")。
- 查询执行与结果返回:将生成的 SQL 语句发送至数据库执行,并将返回的结构化结果(如表格数据)整理为自然语言反馈给用户,让用户无需查看原始数据,就能直接理解查询结果。
1.2 Text2SQL 的典型应用场景
Text2SQL 并非单一场景的技术,而是能广泛适配各类需要数据库查询的场景:
- 商业智能(BI):企业中的运营、销售等业务人员,无需依赖数据分析师,可直接通过自然语言查询销售数据、用户增长趋势,快速生成业务报表。
- 数据探索:数据分析师在初步探索数据时,无需反复编写 SQL 语句,通过自然语言快速验证数据猜想,例如 "查看不同学期高等数学成绩的分布情况"。
- 客户支持:客服人员在接待用户咨询时,可通过自然语言查询数据库中的订单状态、用户会员信息,无需切换多个系统,提升响应效率。
- 教育场景:教师可查询学生的各科成绩、班级平均分,学生也能自主查询个人选课信息,简化教务数据的获取流程。
1.3 Text2SQL 面临的技术挑战
尽管 Text2SQL 优势显著,但在实际落地中仍需应对三大核心挑战:
- 自然语言歧义:同一表述可能存在多种含义。例如 "2022 年之后入学的学生",既可能指 "2022 年及以后",也可能指 "2022 年之后(不含 2022 年)",系统需结合上下文精准判断用户意图。
- 数据库模式理解:系统需完全掌握数据库的结构,包括表名、列名、字段类型、表间关联关系(如外键)。若无法识别 "student_id" 是关联 "student" 表与 "score" 表的关键字段,将无法生成正确的多表查询语句。
- 复杂查询处理:对于嵌套查询(如 "查询平均成绩高于 85 分的专业")、多表连接(如同时关联学生表、成绩表、课程表)等复杂场景,需要更精细的语义解析逻辑,才能确保生成的 SQL 语句逻辑正确。
二、工作流:让 Text2SQL 流程更可控、可维护
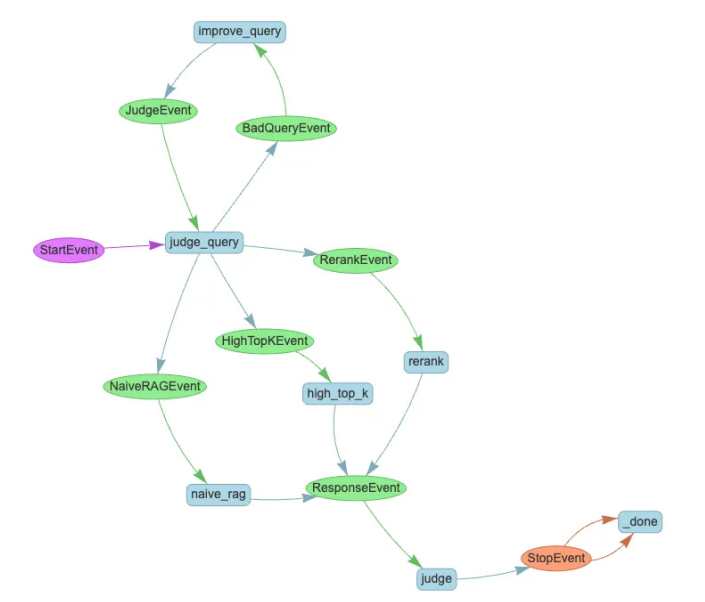
当 Text2SQL 与 RAG 结合,需要处理 "检索表信息→生成 SQL→执行查询→反馈结果" 等多步骤操作时,单纯的线性代码会导致逻辑混乱、难以调试。而工作流通过 "事件驱动 + 步骤拆分" 的方式,能将复杂流程拆解为清晰的模块,让整个系统更易维护、更易扩展。
2.1 工作流的核心逻辑
工作流本质是一种 "事件触发步骤、步骤生成事件" 的循环机制:将整个系统拆分为多个独立的 "步骤"(如 "检索表信息""生成 SQL""执行查询"),每个步骤由特定 "事件" 触发(如 "用户发起查询" 触发 "检索表信息" 步骤),步骤执行完成后,再生成新的事件触发下一个步骤。
以数据库 RAG 查询为例,一个典型的工作流流程如下:
- StartEvent(启动事件):用户输入自然语言查询(如 "获取所有学生的基本信息"),触发工作流启动;
- 检索表信息步骤:系统从向量数据库中检索与查询相关的表结构信息(如 "student" 表的字段、注释),生成 "TableRetrieveEvent(表检索完成事件)";
- 生成 SQL 步骤:接收 "TableRetrieveEvent",结合用户查询与表信息,生成 SQL 语句,生成 "TextToSQLEvent(SQL 生成完成事件)";
- 执行查询与生成响应步骤:接收 "TextToSQLEvent",执行 SQL 语句并将结果整理为自然语言,生成 "StopEvent(结束事件)",将结果反馈给用户。
这种流程设计的优势在于:每个步骤独立可调试,若 "生成 SQL" 步骤出现错误,只需修改该模块,无需改动其他步骤;同时,可灵活添加新步骤(如 "SQL 语法检查" 步骤),扩展系统功能。
2.2 为什么选择工作流?
在 RAG 数据库查询系统中,工作流相比传统的有向无环图(DAG)框架,更能应对复杂场景的需求:
- 避免逻辑嵌套混乱:DAG 需将循环、分支逻辑编码在图形边缘,导致流程难以理解;而工作流通过事件与步骤的对应关系,让循环(如 "SQL 语法错误时重新生成 SQL")、分支(如 "简单查询直接执行,复杂查询先优化")逻辑更清晰。
- 简化数据传递:DAG 中节点间的数据传递需要处理可选值、默认值等复杂逻辑;而工作流通过事件携带数据(如 "TableRetrieveEvent" 携带表信息字符串),数据传递更直观、不易出错。
- 更贴合 AI 应用开发习惯:对于包含 RAG、LLM 调用的复杂 AI 应用,开发人员更习惯按 "步骤拆分" 的思路编写代码,工作流的设计更符合这一习惯,降低开发门槛。
三、实战:从零实现 RAG+Text2SQL 数据库查询系统
接下来,我们将通过代码实战,搭建一套完整的 "自然语言→数据库查询" 系统。系统将基于 Python 实现,核心依赖 llama_index(处理 RAG 与工作流)、SQLAlchemy(数据库连接)、Milvus(向量存储表结构信息)。
3.1 环境准备与依赖安装
首先,安装所需依赖库,确保系统能正常连接数据库、处理向量存储与工作流:
python
# 基础依赖:llama_index 核心库、工作流工具、SQLAlchemy(数据库连接)
pip install llama-index-core llama-index-utils-workflow sqlalchemy
# 向量存储依赖:Milvus(存储表结构信息)
pip install llama-index-vector-stores-milvus pymilvus
# 数据库连接依赖:MySQL 驱动、加密库(解决 MySQL 8.0+ 认证问题)
pip install pymysql cryptography
# LLM 依赖:根据实际使用的模型安装(如 deepseek 等)
pip install deepseek-ai3.2 核心模块实现
系统分为 5 个核心模块,分别负责数据库连接、向量存储表信息、工作流调度、Text2SQL 生成、前端交互,各模块职责清晰、可独立复用。
模块 1:数据库 RAG 基础类(database_rag.py)
该类负责连接数据库、加载表结构信息、创建向量索引,为后续检索表信息提供支持:
python
from llama_index.core import SQLDatabase, StorageContext
from llama_index.core.objects import SQLTableSchema, SQLTableNodeMapping, ObjectIndex
from sqlalchemy import create_engine
from llama_index.vector_stores.milvus import MilvusVectorStore
import re
from .config import RagConfig # 配置类:存储数据库连接字符串、Milvus 地址等
class DatabaseRAG:
def __init__(self, **kwargs):
# 1. 连接数据库:从配置中获取连接字符串
self.engine = create_engine(RagConfig.db_connection_string)
self.sql_database = SQLDatabase(self.engine)
async def load_data(self):
# 2. 加载数据库表结构:获取所有表名,提取表描述与字段信息
tables = self.sql_database.get_usable_table_names()
table_schema_objs = []
for table in tables:
# 获取单表信息(包含字段、注释)
table_info = self.sql_database.get_single_table_info(table)
# 提取表描述(若不存在,用表名作为描述)
match = re.search(r"with comment: \((.*?)\)", table_info)
table_desc = match.group(1) if match else f"{table} table"
# 创建表结构对象(用于后续向量存储)
table_schema_objs.append(
SQLTableSchema(table_name=table, context_str=table_desc)
)
return table_schema_objs
async def create_index(self, collection_name="database"):
# 3. 创建向量索引:将表结构信息存储到 Milvus
# 加载表结构数据
table_data = await self.load_data()
# 建立表与节点的映射关系
table_node_mapping = SQLTableNodeMapping(sql_database=self.sql_database)
# 初始化 Milvus 向量存储
vector_store = MilvusVectorStore(
uri=RagConfig.milvus_uri,
collection_name=collection_name,
dim=RagConfig.embedding_model_dim, # 嵌入模型维度(如 768)
overwrite=True
)
# 创建存储上下文
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# 生成向量索引(用于后续检索表信息)
index = ObjectIndex.from_objects(
objects=table_data,
object_mapping=table_node_mapping,
storage_context=storage_context
)
return index模块 2:Text2SQL 工作流类(text_to_sql_workflow.py)
该类继承自工作流与 DatabaseRAG,实现 "检索表信息→生成 SQL→执行查询→反馈结果" 的全流程:
python
from llama_index.core.indices.struct_store.sql_retriever import SQLRetriever
from llama_index.core.workflow import Workflow, Context, StartEvent, Event, step, StopEvent
from .database_rag import DatabaseRAG
from .prompts import TEXT_TO_SQL_PROMPT, RESPONSE_SYNTHESIS_PROMPT # 预定义提示模板
from .llms import deepseek_llm # 自定义 LLM 加载函数
from .utils import parse_response_to_sql # 自定义 SQL 解析函数
# 自定义事件:表检索完成事件(携带查询与表信息)
class TableRetrieveEvent(Event):
query: str
table_content_str: str
# 自定义事件:SQL 生成完成事件(携带查询与 SQL)
class TextToSQLEvent(Event):
query: str
sql: str
class TextToSQLWorkflow(Workflow, DatabaseRAG):
def __init__(self, **kwargs):
# 初始化工作流与数据库 RAG
Workflow.__init__(self, **kwargs)
DatabaseRAG.__init__(self, **kwargs)
@step
async def retrieve_tables(self, ctx: Context, ev: StartEvent) -> TableRetrieveEvent:
"""步骤 1:检索与用户查询相关的表信息"""
# 加载 Milvus 中的表结构索引
index = await self.create_index(collection_name="database")
# 检索前 20 个最相关的表结构(避免遗漏关键信息)
retriever = index.as_retriever(similarity_top_k=20)
table_schema_objs = retriever.retrieve(ev.query)
# 整理表信息为字符串(便于 LLM 理解)
table_content_str = "\n\n".join([node.text for node in table_schema_objs])
return TableRetrieveEvent(query=ev.query, table_content_str=table_content_str)
@step
async def generate_sql(self, ctx: Context, ev: TableRetrieveEvent) -> TextToSQLEvent:
"""步骤 2:根据查询与表信息生成 SQL"""
# 格式化提示模板(注入用户查询与表信息)
prompt = TEXT_TO_SQL_PROMPT.format_messages(
query=ev.query,
table_context_str=ev.table_content_str
)
# 调用 LLM 生成 SQL
llm = deepseek_llm()
chat_response = llm.chat(prompt)
# 解析 LLM 响应,提取纯 SQL 语句(去除多余文本)
sql = parse_response_to_sql(chat_response)
return TextToSQLEvent(query=ev.query, sql=sql)
@step
async def generate_response(self, ctx: Context, ev: TextToSQLEvent) -> StopEvent:
"""步骤 3:执行 SQL 并生成自然语言响应"""
# 执行 SQL 查询(获取结构化结果)
sql_retriever = SQLRetriever(sql_database=self.sql_database)
query_result = sql_retriever.retrieve(ev.sql)
# 格式化响应模板(注入查询、SQL、结果)
response_prompt = RESPONSE_SYNTHESIS_PROMPT.format_messages(
query=ev.query,
sql=ev.sql,
context_str=query_result
)
# 返回结果(包含响应提示与原始 SQL,便于调试)
return StopEvent(result={"message": response_prompt, "sql": ev.sql})模块 3:提示模板配置(prompts.py)
预定义 Text2SQL 与响应合成的提示模板,引导 LLM 生成准确的 SQL 与自然语言响应:
python
from llama_index.core import PromptTemplate
from llama_index.core.prompts import PromptType
# Text2SQL 提示模板:限定 LLM 只使用指定表、生成正确语法的 MySQL 语句
TEXT_TO_SQL_PROMPT_STRING = """
给定一个输入问题,首先创建语法正确的 MySQL 查询来运行,然后查看查询结果并返回答案。
注意事项:
1. 只查询问题中需要的列,不要查询表中所有列;
2. 仅使用下面列出的表结构信息,不要使用其他表或列;
3. 若涉及多表查询,需通过外键(如 student_id)关联,确保表关系正确;
4. 生成的 SQL 语句需包含完整的表名、列名,避免语法错误。
你必须使用以下格式:
Question: {query}
SQLQuery: 要运行的 SQL 查询
SQLResult: (无需填写,仅为格式要求)
Answer: (无需填写,仅为格式要求)
可用表结构信息:
{table_context_str}
SQLQuery:
"""
TEXT_TO_SQL_PROMPT = PromptTemplate(
TEXT_TO_SQL_PROMPT_STRING,
prompt_type=PromptType.TEXT_TO_SQL
)
# 响应合成提示模板:将 SQL 结果整理为自然语言
RESPONSE_SYNTHESIS_PROMPT_STRING = """
根据用户问题、执行的 SQL 语句和查询结果,合成简洁易懂的自然语言回答。
要求:
1. 直接回答用户问题,不要包含 SQL 语句;
2. 若结果为表格数据,用清晰的列表或段落描述,避免展示原始数据;
3. 语言口语化,让非技术用户能快速理解。
用户问题:{query}
执行的 SQL:{sql}
查询结果:{context_str}
Response:
"""
RESPONSE_SYNTHESIS_PROMPT = PromptTemplate(RESPONSE_SYNTHESIS_PROMPT_STRING)模块 4:配置文件(config.py)
存储数据库连接、Milvus 地址、嵌入模型维度等配置,便于统一管理:
python
from pydantic import Field
from pydantic_settings import BaseSettings
import os
class RagConfig(BaseSettings):
# 数据库连接字符串(从环境变量读取,避免硬编码)
db_connection_string: str = Field(
default=os.getenv("DB_CONNECTION_STRING"),
description="MySQL 数据库连接字符串"
)
# Milvus 向量存储配置
milvus_uri: str = Field(default="http://localhost:19530", description="Milvus 服务地址")
embedding_model_dim: int = Field(default=768, description="嵌入模型维度(如 BGE 模型为 768)")
# 实例化配置(全局复用)
rag_config = RagConfig()模块 5:前端交互(chainlit_ui.py)
使用 Chainlit 搭建简单的 Web 界面,让用户通过可视化界面输入查询、查看结果:
python
import chainlit as cl
from llama_index.core import Settings
from .text_to_sql_workflow import TextToSQLWorkflow
from .llms import deepseek_llm
# 初始化 LLM(用于响应流式输出)
Settings.llm = deepseek_llm()
@cl.on_chat_start
async def start():
# 向用户发送欢迎消息
await cl.Message(content="欢迎使用数据库智能查询系统!请输入您的查询(如"获取所有学生的基本信息")").send()
@cl.on_message
async def main(message: cl.Message):
# 1. 创建 Text2SQL 工作流实例
workflow = TextToSQLWorkflow()
# 2. 运行工作流(传入用户查询)
result = await workflow.run(query=message.content)
# 3. 提取结果(SQL 语句与响应提示)
sql = result.get("sql")
response_prompt = result.get("message")
# 4. 向用户展示生成的 SQL(便于调试)
await cl.Message(content=f"生成的 SQL 语句:\n```sql\n{sql}\n```", author="系统").send()
# 5. 流式输出自然语言响应
msg = cl.Message(content="", author="系统")
response_gen = Settings.llm.stream_chat(response_prompt)
for token in response_gen:
await msg.stream_token(token.delta)
await msg.send()3.3 系统测试与常见问题解决
测试步骤
-
启动 Milvus 服务:确保 Milvus 向量数据库正常运行(本地或云端);
-
配置环境变量 :设置数据库连接字符串(避免硬编码):
# Windows set DB_CONNECTION_STRING=mysql+pymysql://root:root123@localhost:3306/student_db # Linux/Mac export DB_CONNECTION_STRING=mysql+pymysql://root:root123@localhost:3306/student_db -
启动前端界面 :
chainlit run rag/chainlit_ui.py -w -
输入查询测试:在 Web 界面输入 "获取所有计算机科学专业学生的姓名、年龄和入学年份",查看生成的 SQL 与响应结果。
常见问题解决
问题 1 :RuntimeError: 'cryptography' package is required for sha256_password or caching_sha2_password auth methods原因 :MySQL 8.0+ 默认使用 caching_sha2_password 认证方式,依赖 cryptography 库加密;解决 :安装 cryptography 库:
pip install cryptography。问题 2 :生成的 SQL 语句缺少表关联(如查询成绩时未关联 student 表与 score 表)原因 :LLM 未明确表间关联关系;解决:在提示模板的 "可用表结构信息" 中,补充表间关联说明(如 "score 表的 student_id 外键关联 student 表的 id 字段")。
问题 3 :检索不到相关表信息原因 :Milvus 中未正确创建表结构索引;解决 :检查
create_index方法,确保overwrite=True(覆盖旧索引),且嵌入模型维度与表结构向量维度一致。
四、总结与后续优化方向
本文实现的 RAG+Text2SQL 系统,已能满足基本的数据库自然语言查询需求,但在实际应用中,仍有多个优化方向可提升系统性能与用户体验:
- SQL 语法检查与纠错:添加 "SQL 语法验证" 步骤,使用 SQLAlchemy 的语法检查功能,若生成的 SQL 存在语法错误,自动触发重新生成;
- 多轮对话优化:支持上下文记忆,例如用户先问 "获取计算机专业学生",再问 "他们的高等数学成绩",系统能识别 "他们" 指代 "计算机专业学生",无需重复输入;
- 结果可视化:在前端界面中,将查询结果(如表格数据)转换为柱状图、折线图,更适合业务人员分析数据;
- 权限控制:针对企业场景,添加用户权限管理,限制不同用户可查询的表或字段(如客服只能查询用户订单信息,不能查询财务数据)。
通过 Text2SQL 与工作流的结合,我们成功将 RAG 智能问答系统的能力扩展到结构化数据库领域。这一方案不仅降低了数据库的使用门槛,也为后续构建更复杂的 AI 应用(如多模态数据库查询、智能报表生成)奠定了基础。