TL;DR
- 场景:长上下文昂贵?把文本渲染成图像,用视觉 token 压缩 7--20×再解码。
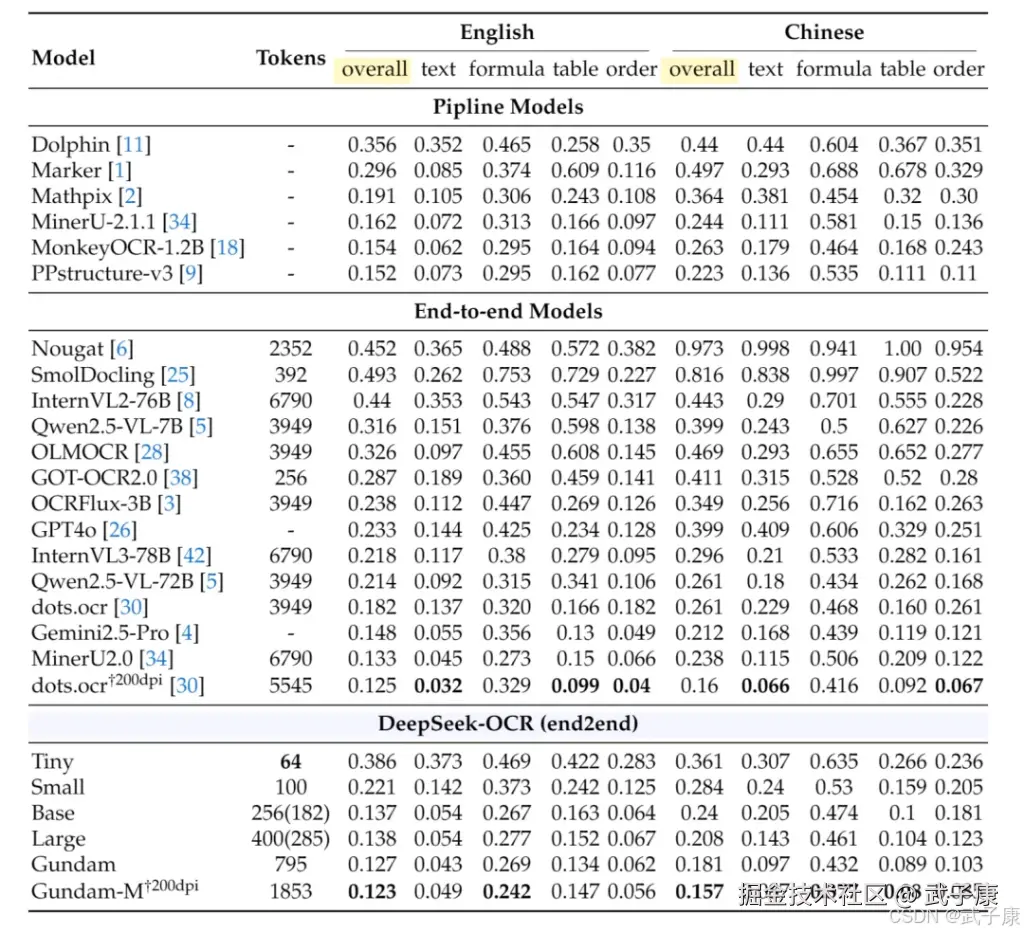
- 结论:当文本:视觉 token < 10:1时,OCR 精度约 97%;到 20:1 仍有 ~60%,用于极端长上下文/回放可用。
- 产出:一张架构速查图、多分辨率/vision-token 一览表、Prompt 与开关清单( / <|grounding|> / Tiny/Base/Gundam)。DeepSeek-OCR 论文
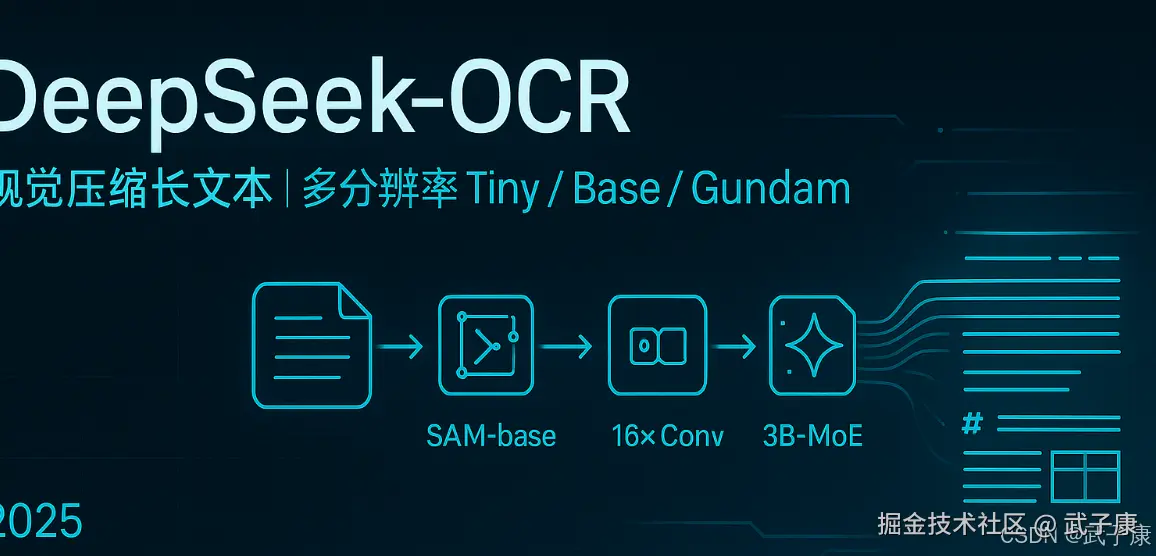
DeepSeek-OCR 基本原理与模型结构
原理90秒
- 把线性的文本序列映射到二维像素 → 由视觉编码器产出远少于文本 token 的vision token。
- 用 DeepEncoder 控制激活内存与token 数;MoE 解码器把 latent 反投影回文本。
- 结论:token 降至 1/7--1/20 的同时,低压缩区间保持高精度。
核心思想:视觉作为文本压缩器
DeepSeek-OCR的核心创新在于提出"上下文光学压缩"这一理念。简单来说,就是利用视觉模式来高效编码文本信息:将长文本渲染成图像,由模型"阅读"该图像来重构文本。这听起来有悖常规------毕竟传统观点里,图像输入文本会引入额外噪声和开销。然而DeepSeek团队发现,对于超长文本,视觉表示反而更划算 。
原因在于:图像天然包含文字的空间布局和形状信息,能够以更少的编码单元承载大量字符。例如,一整页2000字的文本可能需要数千个字词token表示,但渲染成清晰图片后,用视觉patch表示可能只需几百个token。这相当于把线性的文本序列"打包"进二维像素阵列中,用图像压缩的方式存储。有点类似人类快速浏览书页:大脑形成页面视觉记忆,再从中提取文字,而非逐字阅读。
DeepSeek-OCR正是基于此逆向思维,探索视觉-文本压缩范式的可行性。通过特殊设计的模型结构,它成功证明了视觉token可以比文本token更高效地存储长文本上下文。
模型总体架构
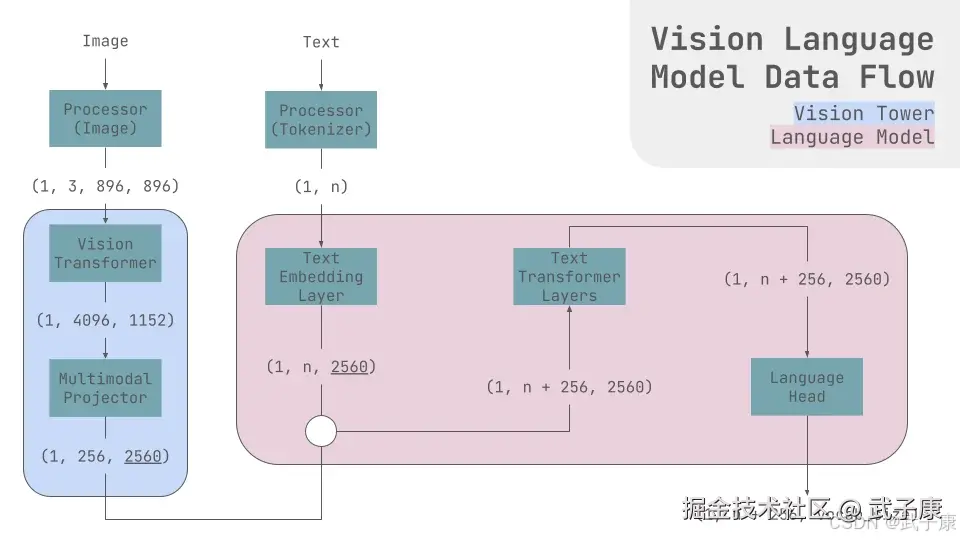
DeepSeek-OCR采用 "双阶段"Vision-Language Transformer架构,包括一个视觉编码器(命名为DeepEncoder)和一个文本解码器(DeepSeek-3B-MoE)。架构示意为:
图像(文档页面) → DeepEncoder 编码 → 压缩后的视觉token序列 → MoE解码器 解码 → 文本输出。
其中,DeepEncoder负责将输入图像转换为高度压缩的中间表示(视觉token序列),DeepSeek-3B-MoE解码器则从这些token中重建原始文本 。这一架构本质上是一个视觉到文本的Transformer:类似NLP中的编解码模型,但把文本的编码部分换成了图像编码。
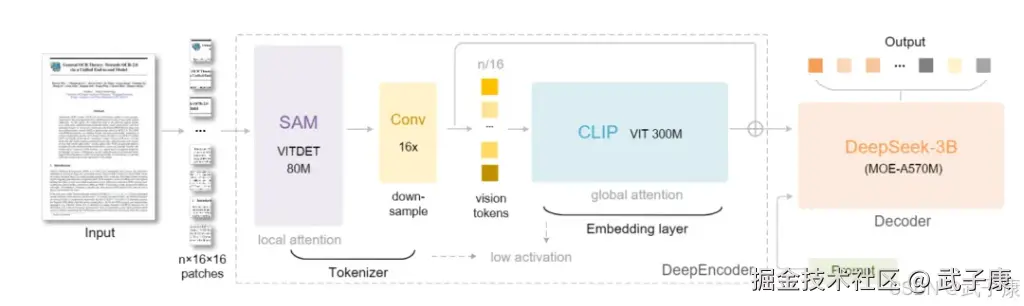
视觉编码器DeepEncoder采用的是ViT变体架构,但做了关键改进以实现极高的压缩率。具体来说,DeepEncoder内部集成了两大模块。
SAM-base局部感知模块
(局部窗口注意,约0.8亿参数) 这里的SAM指一个Vision Transformer的本地版(非Segment-Anything,这里的SAM likely指一种本地Self-Attention Model)。它在不降低原始分辨率的情况下,对图像进行局部特征提取。比如对1024×1024的输入图像划分成小网格块,在每个局部块内应用自注意力。这样即便初始产生了大量patch token(如4096个),由于限制注意力范围,计算和显存开销仍可控。这个阶段让模型获取细粒度细节(如字符形状)。
16×卷积压缩模块
紧接局部提取之后,DeepEncoder增加了一个卷积层,用16倍下采样对token序列进行剧烈压缩。例如,前述4096个局部token经过卷积压缩,只剩下256个token。这一步相当于提炼信息、丢弃冗余,把视觉token数量大幅缩减(压缩率16:1),为后续全局建模扫清障碍。
CLIP-large全局理解模块
(全局稠密注意力,约3亿参数) -- 压缩后的少量token再输入一个全局自注意力Transformer(架构类似OpenAI的CLIP视觉Transformer)。由于此时token数已大幅减少(仅原来的1/16),因此可以在可接受的计算量下施以全局自注意力。这一模块提供宏观上下文理解,整合页面的版面布局、段落结构等信息。它确保即使经过压缩,模型仍能"看懂"整页,而不仅是局部碎片。
暂时小结
经过上述三步串联,DeepEncoder能从高分辨率图像提取出信息密度极高的少量视觉token。这些token浓缩了页面的全部关键信息,为后续文本重建打下基础。
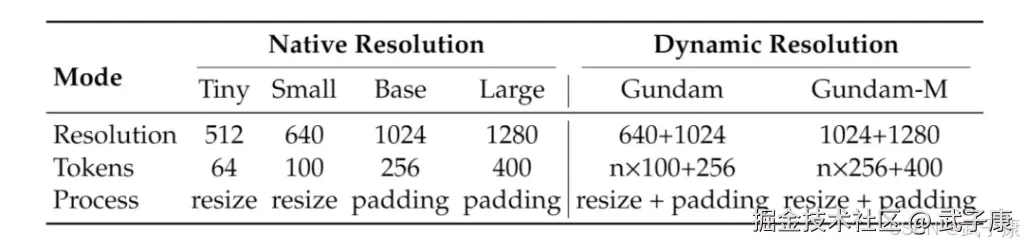
值得一提的是,DeepEncoder支持多种分辨率/压缩模式,以适应不同应用需求。从"Tiny"(输入512×512像素,输出仅64个token)到"Base"(1024×1024,256 token)再到"Gundam"模式(对超大页面动态分块,输出接近800 token)------同一模型可以灵活调整"压缩强度"。这意味着对于文字稀疏的小页面,可以使用极强的压缩以提升速度;而对于特别复杂的大版面,则可以选择适当降低压缩、分块处理以保留细节。这种多分辨率设计在业界尚属首次,为视觉模型处理各种尺寸文档提供了便利。
开发者在推理时只需设置相应参数(如base_size和crop_mode等),即可切换模式,非常实用。
DeepSeek-3B
文本解码器DeepSeek-3B-MoE则是一个Mixture-of-Experts(混合专家)Transformer解码器, 具备约3亿有效参数(3B模型,但每步激活≈5.7亿参数)。它的架构类似一个小型的大语言模型(类似GPT),但引入Mixture-of-Experts技术将模型分为64个专家网络,每个token只激活其中6个专家参与计算。
这样既在参数规模上扩展了模型容量,又控制了推理开销(每步只用一小部分专家)。DeepSeek-3B-MoE的职责是将来自DeepEncoder的压缩视觉token翻译回自然语言。由于其在训练中见过海量的文档数据,它不仅能输出纯文本,还可以在需要时输出结构标记(例如检测坐标、表格结构等)。
值得注意的是,DeepSeek解码器并非直接采用现有的大模型,而是DeepSeek团队自研/定制的语言模型。此前DeepSeek已开源了通用LLM模型(如DeepSeek-R1、DeepSeek-V3系列),有推测认为OCR解码器是在这些模型基础上微调/改造而来,以便更好地适配视觉输入。事实上,HuggingFace模型标签中的"deepseek_vl_v2"也暗示此模型是DeepSeek第二代Vision-Language模型框架的一部分。
输入输出与Tokenization
在使用DeepSeek-OCR时,输入通常是一张图片(例如文档扫描页),模型会将其编码为一串内部视觉token,并由解码器生成相应的文字。为了让模型知道何时接收图像,DeepSeek-OCR约定了特殊的输入格式:在文本Prompt中使用特殊标记占位,然后传入实际图像张量。
例如,可以构造Prompt:"\n<|grounding|>请将这张图中的内容转成Markdown。",其中表示后附带的图像,<|grounding|>是模型特定的控制符号,用于指示任务(grounding在此表示OCR对齐任务)。模型读取到标记时,会由视觉编码器处理输入图像;之后解码器看到<|grounding|>指令,就会按要求生成结果格式。
在输出上,DeepSeek-OCR可以灵活地产生不同形式的结果:默认情况下可输出纯文字内容;若使用<|ref|>...<|/ref|>和<|det|>...<|/det|>等特殊token,则会输出文本片段及其在图像中的坐标框,实现文字检测+识别的双重结果。这种输出格式在需要版面还原或结构化提取时非常有用。而如果Prompt要求比如"转为Markdown"或"提取表格",模型则会根据训练中学到的知识输出相应的富文本标记(例如表格用|和---绘制,标题加#等)。所有这些都得益于模型在训练时混合了OCR任务和语言建模任务,使之具备图文协同和听从指令的能力。
在Tokenizer方面,DeepSeek-OCR应该使用了一个多语言SentencePiece/BPE词表,以覆盖百种语言字符和特殊标记。推理时需使用与模型对应的Tokenizer加载(HuggingFace提供的AutoTokenizer.from_pretrained会自动处理)。视觉部分的token由模型内部生成,不需要用户干预。
是否使用大语言模型进行协同?
虽然DeepSeek-OCR本质上自己就包含一个语言模型作为解码器,但一个有趣的问题是:它能否与外部的大语言模型协同工作?
从设计上看,DeepSeek-OCR已经集成视觉和语言于一体(即所谓Visual-Language模型),因此并不需要再额外对接GPT这类模型来完成OCR任务。然而,它的确可以作为其它LLM的"前端模块"使用:例如我们可以用DeepSeek-OCR将超长文档压缩成少量视觉token,然后把这些token对应的文本摘要交给另一个更大的LLM继续推理。这其实就是上下文光学压缩的应用场景之一。
因此可以说,DeepSeek-OCR不是简单调用某个现有LLM,而是自带一个定制的小型LLM(3B-MoE)专门用于OCR。当然,社区中也有人尝试将DeepSeek-OCR与其他模型结合,例如使用DeepSeek-OCR读取文档后,把结果传入Claude等问答模型以实现文档问答。这种模块化协同属于应用层集成,而非模型内部直接使用了别的LLM。
总而言之,DeepSeek-OCR通过精心设计的视觉编码器和Mixture-of-Experts解码器,实现了将文本转换为视觉表示并几乎无损地解码回文本的能力。这种架构在保证OCR高准确率的同时,大幅压缩了中间表示长度,为解决长上下文问题提供了新的思路。
可复现实验 MRE
之前的章节已经讲解过,这里略过。
- 环境:torch 2.6 + flash-attn 2.7.3 + transformers 4.46.3。
- 命令:HF/或 vLLM 推理;切 3 个模式(Tiny/Base/Gundam),打印输出与 token 统计。
- 提醒:skip_special_tokens=False + n-gram 处理器白名单 实用。
信息来源
- 36氪-文本已死,视觉当立,Karpathy狂赞DeepSeek新模型,终结分词器时代
- wallstreetcn-DeepSeek-OCR
- Getting DeepSeek-OCR working on an NVIDIA Spark via brute force using Claude Code
- The Innovations in DeepSeek OCR
- deepseek-ocr-is-here
- deepseek-ai/DeepSeek-OCR
- DeepSeek unveils multimodal AI model that uses visual perception to compress text input
其他系列
[Ollama 本地部署实战 | 3 分钟安装 & 多卡GPU部署 & 运行实战 【2025版】
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI-调查研究-108-具身智能 机器人模型训练全流程详解:从预训练到强化学习与人类反馈
💻 Java篇持续更新中(长期更新)
Java-154 深入浅出 MongoDB 用Java访问 MongoDB 数据库 从环境搭建到CRUD完整示例 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解