目录
[1.1. 红外图像和可见光图像的区别](#1.1. 红外图像和可见光图像的区别)
[1.2. 红外可见光融合(IVIF)的目的](#1.2. 红外可见光融合(IVIF)的目的)
[1.3. 应用领域](#1.3. 应用领域)
[1.4. 技术方法](#1.4. 技术方法)
[2.1. 空间域](#2.1. 空间域)
[2.2. 变换域](#2.2. 变换域)
[2.3. 小结](#2.3. 小结)
[3.1. 基于自编码器](#3.1. 基于自编码器)
[3.1.1. 单一尺度方法](#3.1.1. 单一尺度方法)
[3.1.2. 多尺度方法](#3.1.2. 多尺度方法)
[3.1.3. 小结](#3.1.3. 小结)
[3.2. 基于卷积神经网络](#3.2. 基于卷积神经网络)
[3.2.1. 显著性方法](#3.2.1. 显著性方法)
[3.2.2. 结构优化方法](#3.2.2. 结构优化方法)
[3.2.3. 统一多任务框架方法](#3.2.3. 统一多任务框架方法)
[3.2.3. 全局依赖自适应方法](#3.2.3. 全局依赖自适应方法)
[3.2.4. 特殊任务融合方法](#3.2.4. 特殊任务融合方法)
[3.2.5. 小结](#3.2.5. 小结)
[3.3. 基于生成对抗网络](#3.3. 基于生成对抗网络)
[3.3.1. 基础对抗生成方法](#3.3.1. 基础对抗生成方法)
[3.3.2. 注意力与显著性增强对抗方法](#3.3.2. 注意力与显著性增强对抗方法)
[3.3.3. 多尺度与循环一致性对抗方法](#3.3.3. 多尺度与循环一致性对抗方法)
[3.3.4. 混合结构对抗方法](#3.3.4. 混合结构对抗方法)
[3.3.5. 小结](#3.3.5. 小结)
一、问题引出
1.1. 红外图像和可见光图像的区别
可见光图像:
- 提供目标形态视觉细节信息(纹理)
- 容易受到极端天气等因素影响而丢失关键信息
- 光照强度低以及烟雾遮挡等情况下,图像所提供信息的可靠性不足
红外图像:
- 捕捉目标的热辐射信息
- 有效抵抗极端条件干扰
- 通常分辨率较低,对于纹理丰富的区域存在严重失真
1.2. 红外可见光融合(IVIF)的目的
红外图像对热源目标敏感,而可见光图像对纹理细节敏感,通过结合红外和可见光图像中的重要内容,生成信息更加丰富的融合图像。实现多 模态图像信息的互补与增强。
1.3. 应用领域
目标检测、目标跟踪、军事侦察、无人驾驶等。
1.4. 技术方法
可分为传统方法 和深度学习方法。
二、传统方法
2.1. 空间域
原理:在图像的原始空间进行融合操作
2.2. 变换域
原理:通过将图像转换到变换域,在变换域中进行操作后转回到空间域。
分类:
- 基于多尺度变换的方法
- 基于稀疏表示的方法
- 基于子空间的方法
- 基于显著性的方法
- 基于变分模型的方法
2.3. 小结
- 传统图像融合方法表现良好,但其本身依赖先验知识,很难识别未知结果。
- 追求更优性能会增大方法复杂性。
三、深度学习方法
本文分析了具有代表性的三类:基于自编码器(auto-encoder , AE )的方法、基于卷积神经网络(convolutional neural network , CNN) 的方法以及基于生成对抗网络(generative adversarial network, GAN )的方法。
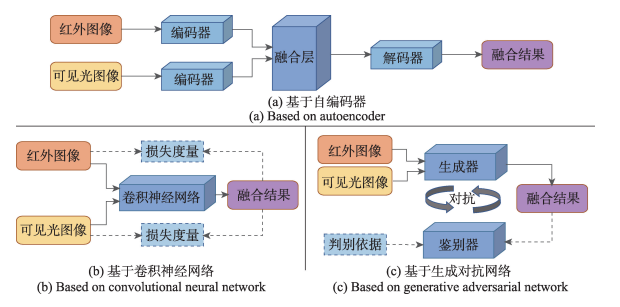
3.1. 基于自编码器
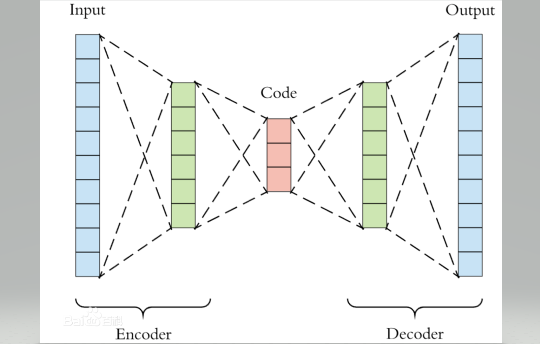
原理:自编码器是一种无监督学习的神经网络,用于将输入数据压缩成一种低维表示(编码),再从中重建原始输入(解码)。这是一种类似有损压缩的方法,网络会提取输入内容的关键特征,然后基于关键特征对其进行重建。仅能识别类似的数据。
| 部分 | 功能 | 示例操作 |
|---|---|---|
| 编码器 (Encoder) | 将输入压缩为低维特征 | 卷积层 / 全连接层 |
| 潜在表示 (Latent Space) | 压缩后的"语义"表示 | z 含有主要特征信息 |
| 解码器 (Decoder) | 从 z 重建输入 | 反卷积 / 上采样 |
| 损失函数 (Loss) | 衡量重建误差 | MSE, BCE 等 |
3.1.1. 单一尺度方法
29. 引入密集连接块,编码器中每一层的输出都用来构建特征图。但是手动设计策略使得性能受限。
30. 在中间层采用卷积代替手动融合规则,但是增加了模型复杂性和训练难度。
自编码器手动设计融合策略,这一点体现在哪?
自编码器本质上仅负责对输入的编码和解码(压缩和重建),因此不会主动融合多源特征。
相比之下,例如Yolo会自动学习每个通道、每个尺度的融合权重,不需要人工指定。
例如:
python
# 人为定义融合策略
E_ir = Encoder(ir)
E_vis = Encoder(vis)
# 手动指定融合方式
F = 0.5 * E_ir + 0.5 * E_vis
output = Decoder(F)
E_ir = Encoder(ir)
E_vis = Encoder(vis)
# 网络自动学融合权重
F = AttentionFusion(E_ir, E_vis)
output = Decoder(F)31.双分支在多个层次之间建立特征传输和交互,每个解码器不仅接收自己分支的特征,还接收来自另一分支或不同层次的融合特征。
32.基于31类似架构,将多模态特征分类为独有和共同两种分别融合。
以上方法,不能有效地提取多尺度特征。
为什么说无法提取多尺度特征?
单支路传统自编码器过度依赖前一阶段的输入,没有特征融合,仅能学到单一尺度特征。
双支路融合自编码器的每个支路内部仍然是但尺度卷积流,即便有交叉融合也都是都是人工或固定的融合策略。无法提取多尺度特征。
3.1.2. 多尺度方法
33,34,35,36.设计多尺度编码器,通过下采样获得不同层特征,并通过注意力机制弥补普通卷积感受野小的不足,能够提升特征表达能力。
37.针对上述直接采用下采样会造成特征丢失的问题,采用了Res2Net缓解丢失问题。
ResNet和Res2Net有什么区别?
两者共同遵循:
只是:
ResNet 的 F(x)是一个卷积堆叠。
Res2Net 的 F(x)内部又被拆成多个更小的卷积组 F1,F2,............
这里重点区分堆叠和卷积组的区别:
概念 关键词 核心区别 卷积堆叠(stacked convolution) 深度方向堆叠(层叠顺序) 多个卷积层顺序串联,层与层之间有非线性(ReLU、BN) 分组卷积(group convolution) 通道方向分组(并行计算) 一个卷积层内部把通道分成几组,各组独立卷积、互不通信 加之两者的区别:
对比项 ResNet Res2Net 主要目的 加深网络而不退化 单块内建多尺度特征表达 特征提取方式 多层堆叠卷积(跨层) 分组卷积 + 层内连接(块内) 感受野增长 随层数增加 同层内部已包含多感受野 空间细节 多次下采样可能丢失 不下采样即可多尺度 信息流动 单路径 组内递进式流动 多尺度特征 隐式 显式、多尺度可控
ResNet和Yolo都有shortcut,区别在哪?
项目 出现背景 主要目的 ResNet (2015) 深层网络训练困难(梯度消失、退化问题) 通过恒等映射让梯度顺利传递,便于训练超深网络 YOLO Shortcut / Route (Darknet, CSP 结构) 特征复用与融合不足,浅层细节丢失 通过跨层连接实现多尺度特征融合与信息补充
角度 ResNet Shortcut YOLO Shortcut 核心思想 恒等残差连接 跨层特征复用 出发点 训练优化(防退化) 表征增强(多尺度) 操作形式 Add Add / Concat 维度要求 输入输出一致 可变通道,灵活连接 最终效果 让网络更深 让特征更丰富
38.设计了轻量级自监督融合框架,在自监督机制下实现图像共有与独有特征的分解与组合,无需复杂损失函数即可生成高质量融合结果,有效提升了融合性能与模型效率。
以上为理想情况下的多尺度方法,现实中受因素影响融合性能会出现下降。
39.针对红外与可见光图像存在未对准(偏移)问题,提出了配准融合架构(RFVIF),在网络中引入特征动态对准模块自适应调整红外与可见光特征对齐,有效抑制未配准源图像导致的伪影问题。
40.提出了低光增强融合方法(DIVFusion),通过场景照明解纠缠网络去除低光退化,并利用对比度增强网络在极弱光环境下提升图像视觉感知质量;但其结果中主要目标区域不够突出。
41.构建了统一融合框架,通过学习多个融合任务间的相关性,增强模型的泛化能力与任务适应性,实现了跨任务融合性能提升。
42.将对比学习(contrastive learning)引入融合框架,利用正负样本约束机制优化特征分布,进一步提升融合结果的判别性与一致性。
43.设计了知识蒸馏(knowledge distillation)融合框架,通过高分辨率分支结果引导低分辨率融合分支,实现了多分辨率间的信息传递与结果优化。
3.1.3. 小结
自编码器的方法通过多方面的探索, 大大提升了融合 图像的性能。 但自编码器的方法通常都需要大批量的数据进行训练,模型训练较为困难。另外目前还存在其他问题需要进一步研究。
3.2. 基于卷积神经网络
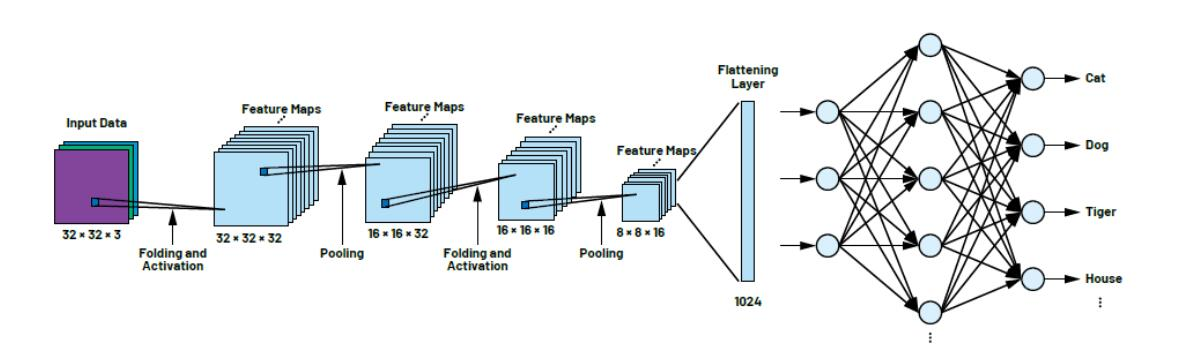
原理:前向传播中通过多次卷积运算,提取特征纹理,直到变成向量后输入全连接层进行学期,反向更新优化神经网络内部参数,做到自我学习和调整。
3.2.1. 显著性方法
45.定义 IVIF 所需信息为红外显著目标与可见光纹理细节,提出 STDFusionNet(CNN模型),利用显著目标掩膜标注红外关键区域,并通过特定损失函数引导融合过程。
47,48,49.提出显著性引导融合架构,利用显著性掩码赋予重要区域更高权重,引导网络重点保留关键信息。但此类方法依赖显著性检测精度,外部掩膜或双任务训练均存在优化困难。
掩膜和掩码什么区别?
"掩码(mask) "和"掩膜(掩模) "其实是中文术语翻译中经常混用的两个词,它们在字面上接近,但在计算机视觉、图像处理、深度学习的语境里,确实有一些语义与使用习惯上的区别。
使用场合 正确表述 深度学习 / 特征融合 / 显著性引导 掩码(mask) 图像滤波 / 模板匹配 / 传统算法 掩膜 / 掩模(filter mask)
"掩码 ":指一种选择或权重图 ,用于控制信息流或区域关注,多出现在深度学习网络中。
"掩膜 ":指一种运算模板或滤波核 ,用于空间卷积或特征提取,多出现在传统图像处理。
以上方法,依赖显著性检测结果,可能无法充分考虑融合需求。
3.2.2. 结构优化方法
46.提出残差密集 CNN 网络(DenseFuse 改进),通过特征重用增强融合性能。
3.2.3. 统一多任务框架方法
50.Xu 等人提出 U2Fusion 统一融合框架,多任务间相互促进,提高多种融合任务的泛化能力。
51,52.构建了基于梯度与强度比例约束的快速统一融合网络,后续引入压缩/分解双网络结构,同时关注融合与分解阶段,提升信息完整性。
53.提出 MU-Fusion 框架,利用中间结果的协同监督实现多任务融合。
(统一模型提升泛化,但任务冲突导致学习难度增加。)
统一多任务,比较复杂,任务可能存在冲突和不一致,提升效率成为最大挑战。
3.2.3. 全局依赖自适应方法
54,55.将 Transformer 引入融合网络,增强全局上下文建模,实现全局+局部特征联合提取,显著提升融合性能;但模型参数量大、融合效率下降。
56.Liu 等人引入 神经架构搜索(NAS)范式,网络可自适应调整结构以高效提取不同模态特征,提升融合速度与自适应性。
3.2.4. 特殊任务融合方法
57,58,59.提出基于交叉模态配准的融合网络(CNN-based registration fusion),缓解错位引起的伪影。Xu 提出 RFNet,通过粗配准+细配准模块提升精度。后续改进版本引入 对比学习 提取共享特征,进一步提升配准与融合效果。
60.设计语义感知融合框架(SeAFusion),引入语义损失指导高层语义信息回流,提高融合图像在高层视觉任务中的表现。
61.构建双子网络(Twin Network),融合子网筛选显著特征,检测子网利用融合特征完成精准检测,探索融合与下游任务的联合优化。
62,63.结合元学习(meta-learning)设计跨分辨率融合模型。双向回归超分重构网络,解决红外与可见光分辨率差异导致的重建退化问题。
3.2.5. 小结
基于 CNN 的融合方法已从早期的显著性引导与结构复用阶段,逐步发展到多任务协同、全局建模与自动化架构优化阶段。该类方法在融合质量与模型可扩展性方面取得了显著进展,但仍面临网络结构复杂、训练代价较高以及融合策略可解释性不足等问题,为后续研究提供了新的改进方向。
3.3. 基于生成对抗网络
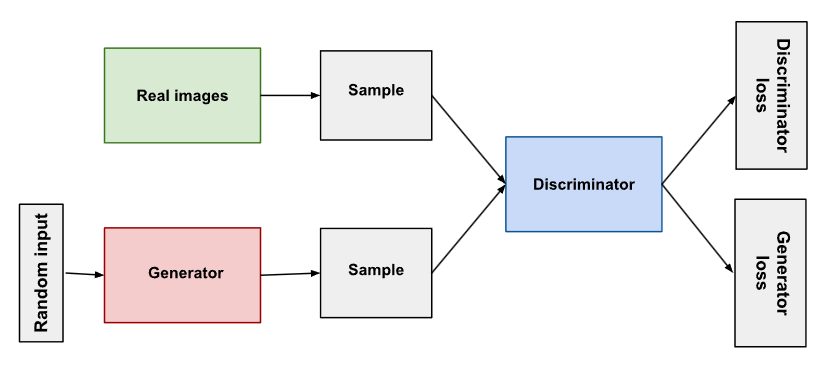
原理:生成对抗网络(Generative Adversarial Network, GAN)由两个相互竞争的子网络组成:生成器(Generator,G)与判别器(Discriminator,D)。其核心思想是通过对抗学习方式,使生成器逐渐学会从输入数据中生成逼真的样本,而判别器则学习区分真实样本与生成样本,从而形成一个动态博弈过程。
3.3.1. 基础对抗生成方法
64 提出了以生成对抗网络为核心的融合模型,通过对抗学习提升融合图像的自然性、对比度与细节保真度,使生成结果在视觉质量上更为逼真。
65 提出了在生成器与判别器之间加入特征级对抗约束的融合框架,通过特征空间对抗机制强化模态互补性,同时保留红外显著目标与可见光纹理结构。
3.3.2. 注意力与显著性增强对抗方法
66 提出了结合注意力机制的对抗融合方法,在生成器中加入空间注意力模块,使网络自适应地关注重要区域,提高关键目标的显著性与背景细节的清晰度。
3.3.3. 多尺度与循环一致性对抗方法
67 提出了结合多尺度判别器的对抗融合框架,在不同尺度上同时对生成结果进行真实性与结构一致性判别,使融合结果兼具全局亮度一致性与局部纹理精细度。
68 提出了基于循环一致性约束的对抗融合结构,通过红外---可见光---融合图像的循环重建保持模态一致性,进一步增强图像内容的可逆性与互补性。
3.3.4. 混合结构对抗方法
69 提出了在对抗过程中加入结构保持与梯度约束的改进模型,有效避免边缘模糊与纹理退化,使融合图像的细节结构更加清晰。
70 提出了基于多任务判别器的对抗融合方法,在常规对抗判别的基础上加入内容一致性判别与结构一致性约束,从而兼顾图像整体结构与细节保真性。
71 提出了轻量化生成器的快速对抗融合框架,通过减少通道与层数优化推理速度,在保持较高融合质量的同时显著降低计算开销。
72 提出了自监督式对抗融合方法,利用重建约束替代人工标签进行训练,在无参考条件下实现有效融合,缓解了缺乏标准参考图像的问题。
73 提出了结合 Transformer 模块的对抗融合结构,将全局上下文建模能力与对抗生成机制结合,在复杂场景下提升融合图像的真实性、边缘清晰度与细节表现力。
3.3.5. 小结
总体来看,GAN 类方法已从简单对抗生成扩展到多维度的结构增强与全局建模,显著提升了融合图像的视觉质量,但仍面临训练复杂、对抗平衡难以稳定维持等挑战。
四、总结
本文主要针对综述的IVIF方法进行了分类总结,但由于第一次整理,很多地方由于积累浅薄存在一定的问题,将会在后续的写作中持续完善。