论文标题: LLM+AL: Bridging Large Language Models and Action Languages for Complex Reasoning About Actions
作者: Adam Ishay 1 ^{1} 1, Joohyung Lee 1 , 2 ^{1,2} 1,2
代码: https://github.com/azreasoners/llm-al
5. 总结
大型语言模型 (LLM) 在自然语言理解方面表现出色,但在需要系统性搜索和严格遵守约束的复杂规划任务中,其表现并不稳定。LLM+AL 框架提出了一种神经符号方法,旨在解决这一核心问题。该框架的核心思想是职责分离:利用 LLM 将自然语言描述的问题转化为一种形式化的符号表示------行动语言 (Action Language) BC+;然后,将规划和推理任务交由专门的符号求解器处理。
此方法最具价值的部分在于其闭环自我修正机制 (closed-loop self-revision)。LLM 生成的符号代码由 BC+ 求解器执行,求解器的输出(包括语法错误、逻辑矛盾或规划结果)被反馈给 LLM,指导其进行迭代式修正。这种架构将符号求解器转变为一个外部验证工具,显著提升了生成代码的准确性和鲁棒性。实验结果表明,在经典的"传教士与野人"问题及其复杂变体上,LLM+AL 的性能远超 GPT-4 等顶级模型,尤其是在处理问题约束变化和判断问题可解性方面,展现了其作为更可靠、更具适应性的人工智能系统的潜力。
1. 思想
- 大问题 :
- 如何使 LLM 在需要系统性搜索、长时序规划和严格约束遵守的复杂推理任务中,实现可靠、可验证的性能,克服其固有的逻辑不稳定和"幻觉"问题?
- 小问题 :
- LLM 难以持续遵守复杂的状态约束(例如,在传教士与野人问题中,任何一侧岸上野人的数量不能超过传教士)。
- LLM 无法可靠地区分可解与不可解的问题实例,常常为不可解的问题生成看似合理的错误方案。
- 由 LLM 直接生成的用于规划的程序式代码(如 Python)难以调试,且对问题的微小变动非常脆弱。
- 如何为 LLM 的推理过程引入一个外部的、形式化的反馈和验证机制?
- 核心思想 :
- 职责分离 (Separation of Concerns) : 将任务分解为两个部分。LLM 负责其擅长的语义理解和翻译 ,即将自然语言描述的问题转换为声明式的行动语言 BC+ 代码。符号求解器 (Symbolic Reasoner) 负责其擅长的部分,即在形式化知识的基础上进行高效、可靠的约束求解和规划搜索。
- 以符号语言为桥梁 (Symbolic Language as a Bridge): 选用行动语言 BC+ 作为 LLM 和符号求解器之间的中间表示。BC+ 是一种声明式语言,它仅描述世界的因果法则和约束,而不规定求解的具体步骤。这种特性使其比程序式代码更易于生成和修正。
- 迭代式自我修正 (Iterative Self-Revision) : 构建一个反馈循环,这是该框架的关键。
- LLM 生成初始的 BC+ 程序(包括符号定义、规则和查询)。
- BC+ 求解器 尝试执行该程序。
- 求解器的输出 (例如,语法错误、不可满足、或一个具体的规划方案)被反馈给 LLM。
- LLM 根据反馈信息对 BC+ 程序进行修改,此过程不断重复,直至程序正确或达到修正次数上限。
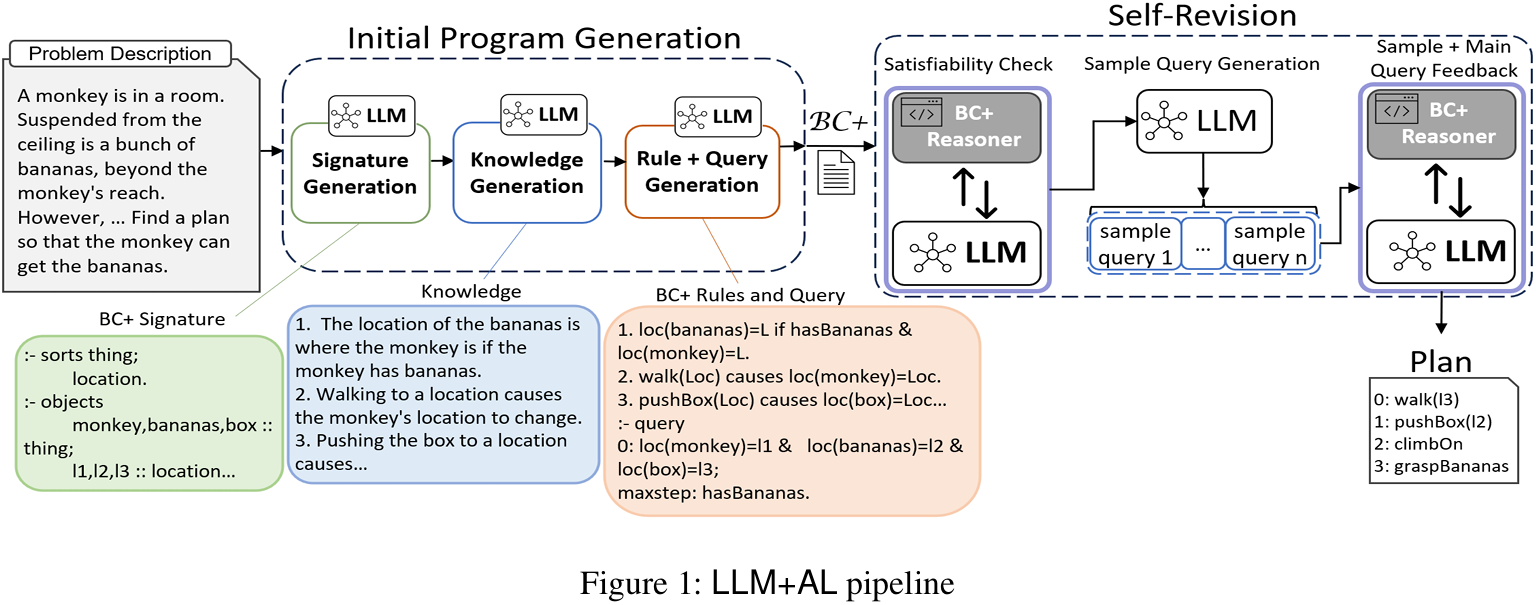
Figure 1: LLM+AL 的工作流管道,清晰地展示了从问题描述到初始程序生成,再到通过符号求解器反馈进行自我修正的闭环过程。
2. 方法
LLM+AL 框架通过一个多阶段的流水线将自然语言问题转化为可执行的 BC+ 程序并求解。
初始程序生成 (Initial Program Generation)
这个阶段利用 LLM 将自然语言问题转化为初步的 BC+ 程序,分为三个步骤:
-
BC+ 签名生成 (Signature Generation):
- LLM 首先从问题描述中识别出核心的实体类型 (sorts) 、对象 (objects) 和关系 (constants) 。例如,在"传教士与野人"问题中,LLM 会识别出
missionary和cannibal等对象,left_bank和right_bank等地点,以及描述状态的流变量 (fluent)loc(person)和描述动作的行为 (action)cross(boat)。 - 这些元素共同构成了 BC+ 程序的"签名",定义了问题的基本词汇。
- LLM 首先从问题描述中识别出核心的实体类型 (sorts) 、对象 (objects) 和关系 (constants) 。例如,在"传教士与野人"问题中,LLM 会识别出
-
知识生成 (Knowledge Generation):
- LLM 进一步从问题描述中提取领域相关的知识和常识 ,并以结构化的自然语言形式表达。这包括:
- 因果关系: "船只渡河会导致船的位置改变"。
- 状态约束: "任何一侧,只要有传教士在,野人数量就不能超过传教士数量"。
- 动作的前提条件: "船上至少要有一个人才能渡河"。
- LLM 进一步从问题描述中提取领域相关的知识和常识 ,并以结构化的自然语言形式表达。这包括:
-
规则与查询生成 (Rule and Query Generation):
- LLM 将上一步生成的自然语言知识翻译成形式化的 BC+ 因果律 (causal laws) 和约束。
- 例如,知识"船只渡河会导致船的位置改变"会被翻译成类似
cross(V) causes loc(V) = NewLoc if ...的 BC+ 规则。 - 同时,LLM 将问题的求解目标(例如"让所有人都到对岸")转化为一个 BC+ 查询 (query)。
自我修正 (Self-Revision)
初始生成的程序很可能存在语法或逻辑错误。自我修正阶段通过与 BC+ 求解器的交互来自动调试程序。
-
可满足性检查 (Satisfiability Check):
- 首先 ,不带任何具体查询,将生成的 BC+ 签名和规则送入求解器。
- 此步骤主要用于捕捉语法错误、类型不匹配或未声明的常量等问题。
- 如果求解器报告错误,其错误信息将被反馈给 LLM,提示其修正签名或规则。
-
样本查询生成与验证 (Sample Query Generation and Verification):
- 程序通过语法检查后,LLM 会被提示生成一组简单的"单元测试"式样本查询,以检验规则的逻辑正确性。
- 这些查询通常测试单个动作的效果或一个简单的约束。例如,生成一个查询测试"让4个人上船"的动作,并预期其结果为"不可满足 (unsatisfiable)",因为船的容量为2。
- 所有样本查询和主查询都被执行 ,其结果(例如,预期"可满足"但实际"不可满足")会连同查询本身一起反馈给 LLM。
-
反馈与精炼 (Feedback and Refinement):
- LLM 根据求解器的综合反馈 (语法错误、样本查询的预期与实际结果不符等),对 BC+ 程序的签名、规则和查询进行新一轮的修改。
- 整个自我修正过程(步骤1-3)会迭代进行,直到所有查询都通过、程序稳定,或达到预设的最大修正次数。
这个闭环过程将符号求解器从一个单纯的解题工具,转变为一个动态的、用于程序调试和优化的交互式环境。
3. 优势
与直接使用 LLM 或 LLM+Code (生成 Python 等代码) 的方法相比,LLM+AL 展现出以下不同:
- 声明式优于程序式: 行动语言 BC+ 是声明式的,用户只需描述"世界是如何运作的",而无需指定"如何去寻找答案"。这降低了 LLM 生成正确逻辑的难度,也使得人类专家更容易对中间代码进行修正。
- 形式化验证: 符号求解器为 LLM 的输出提供了一个无懈可击的"事实检查器"。这使得系统能够发现并修正那些在纯自然语言层面不易察觉的逻辑谬误。
- 更强的适应性: 对于问题的微小变动(例如改变船的容量,或增加新的规则),LLM+AL 框架只需修改相关的几条 BC+ 规则,而无需像重构整个 Python 搜索算法那样复杂。
- 可靠地处理不可解问题: 符号求解器能够确定性地证明一个问题在给定步数内无解。这使得 LLM+AL 能够可靠地识别不可解问题,而不是像基线 LLM 那样产生"幻觉"解。
4. 实验
实验设置旨在评估 LLM+AL 在需要复杂、多步推理的规划问题上的性能,特别是其对规则变化的适应能力。
- 基准 :
- 核心基准是 John McCarthy 提出的"传教士与野人问题 (Missionaries and Cannibals Puzzle, MCP)"及其17个"阐述 (elaborations)"。这些阐述通过修改原始问题的约束(如船的容量、人员数量、特殊规则等)来测试模型的推理和适应能力。
- 同时测试了其他经典谜题,如汉诺塔和数独的变体。
- 基线模型 :
- 顶级的闭源 LLM:
ChatGPT-4、Claude 3 Opus、Gemini 1.0 Ultra和o1-preview。 ChatGPT-4 + Code Interpreter(LLM+Code):让模型生成 Python 代码来解决问题。
- 顶级的闭源 LLM:
- LLM+AL 配置 :
- 使用
o1-preview作为底层的 LLM。
- 使用
实验结论
-
基线 LLM 表现不佳:
- 如 Table 1 所示,
Claude 3和Gemini 1.0未能正确解决任何一个 MCP 变体。ChatGPT-4仅解决了3个。 - 这些模型的主要失败点在于无法严格遵守状态约束,经常生成违反"野人数量不得超过传教士"规则的计划。
- 对于不可解的问题变体,这些模型会产生幻觉,自信地给出一个错误的解决方案。
- 如 Table 1 所示,
-
LLM+AL 性能卓越:
- LLM+AL 自动解决了7个 MCP 问题。对于剩下的10个问题,平均只需要 3.1次人工修正 即可得到正确解。这些修正通常是针对 LLM 未能完全理解的细微语义,且在声明式的 BC+ 代码上操作起来相对简单。
- 在其他谜题变体上(Table 2),LLM+AL 同样表现出远超基线模型的性能和适应性。
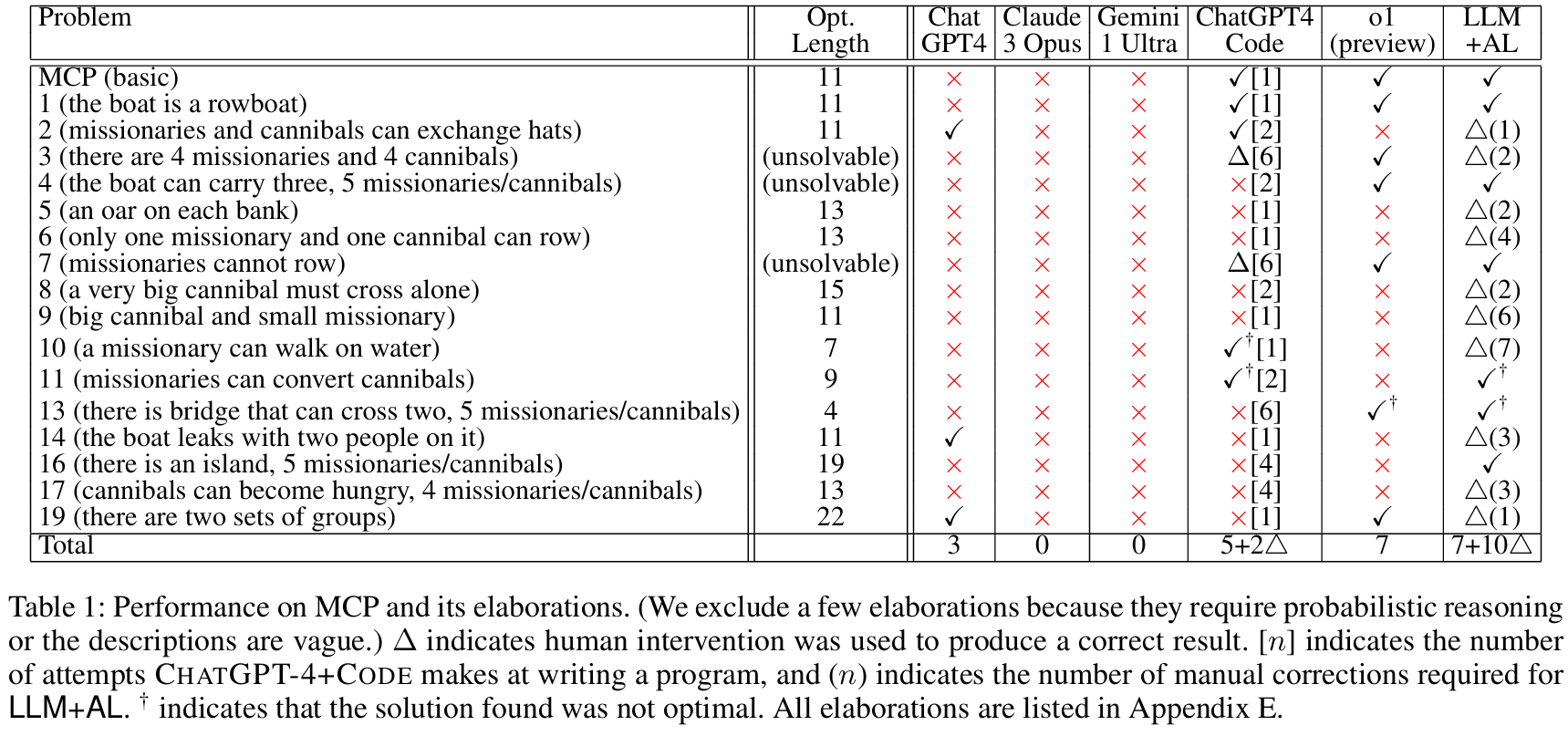
Table 1: 在 MCP 及其变体上的性能对比。✓ 表示成功,x 表示失败,Δ(n) 表示需要 n 次人工修正才能成功。LLM+AL (最后一列) 的性能显著优于所有基线模型。
-
自我修正机制的有效性:
- 自我修正步骤是 LLM+AL 成功的关键。实验数据显示,在自我修正之前,初始生成的30个程序中只有 22.3% (7/30) 是语法正确的。经过自我修正后,这一比例提高到 86.7% (26/30)。
- 在逻辑正确性方面,能够产生正确答案的程序比例从修正前的 16.6% (5/30) 提升至 50% (15/30)。这表明该机制极大地减少了对人工调试的需求。
-
LLM+Code 的局限性:
ChatGPT-4+Code虽然表现优于纯 LLM,但它在适应问题变体时同样举步维艰。它倾向于复用标准问题的代码模板,而忽略新引入的细节。生成的 Python 代码(通常是简单的广度优先或深度优先搜索)对于调试和修改来说,比 BC+ 代码要复杂得多。