
笔记整理:李子晨,天津大学硕士,研究方向为知识图谱
论文链接:https://doi.org/10.1609/aaai.v39i22.34510
发表会议:AAAI 2025
1. 动机
尽管大型语言模型在知识图谱上的推理展现出巨大潜力,但仍然面临若干挑战:首先,知识图谱的内容通常以大量文本内容的形式直接表示,这无法有效传达其图结构中对推理至关重要的丰富逻辑关系。其次,在知识图谱上进行检索和推理需要大量的LLM调用和相当高的LLM推理能力。之前的研究使用了一种迭代的方法,从问题实体开始,逐渐获取推理所需的信息。这增加了LLM调用的次数,牺牲了推理效率,减少了可行性。因此,亟需一种适用于大型语言模型(LLM)的学习推理框架,为小规模LLM提供稳定的检索和高效的推理能力。
2. 贡献
本文的主要贡献有:
(1)首个提出将知识图谱(KGs)的文本内容和图结构转化为用于提示大语言模型(LLMs)的嵌入的框架。
(2)提出了LightPROF,这是一个轻量级和高效的提示学习推理框架,为小规模的LLM提供稳定的检索和高效的推理能力,相比于LLM本身需要的训练参数少得多。
(3)在两个KGQA数据集上进行的大量实验表明,提出的LightPROF优于使用大规模LLM(例如LLaMa-2-70B,ChatGPT)的方法。进一步分析表明,LightPROF在输入令牌数量和推理时间方面具有显著的效率优势。
3. 方法
总体框架如图1所示,提出的检索-嵌入-推理框架包含三个阶段:推理图检索、知识嵌入和知识提示混合推理。通过精准检索和细粒度结构化数据处理能力,在小规模大型语言模型下实现高效的复杂知识图谱问题推理。
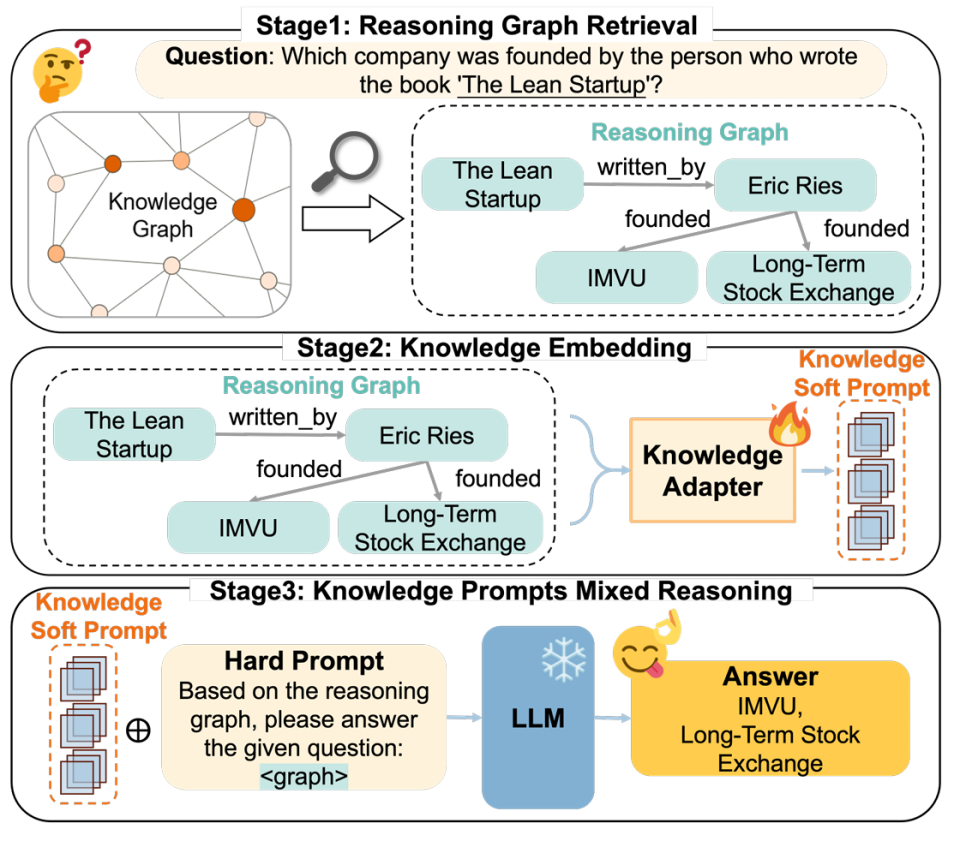
图1 总体框架图
(1)为了解决复杂多跳知识图谱问答任务的推理图检索,问题"如何有效、准确且稳定地从知识图谱中根据问题检索信息?"这一关键问题,将检索模块分为三个步骤:语义提取、关系检索和推理图采样,如图2所示:
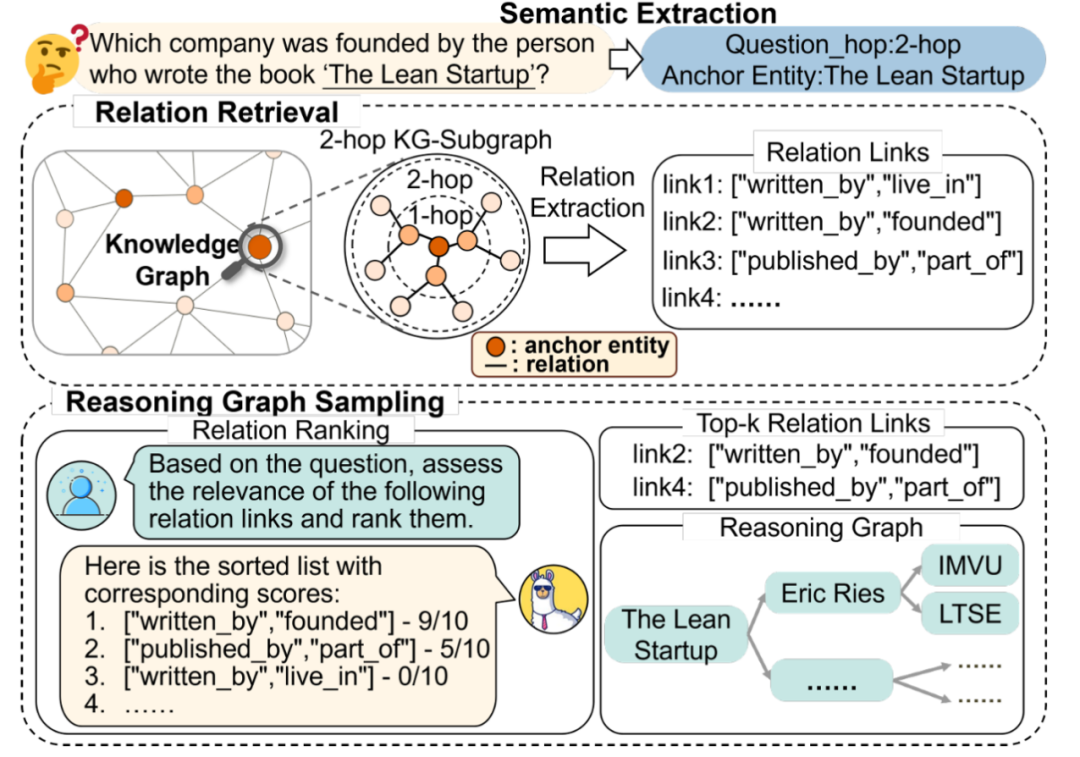
图2 三步检索模块
(2)为了应对知识图结构信息的自然语言表达包含冗余和混淆,无法直接揭示其内在本质,从而妨碍大型语言模型有效利用这些信息的问题。提出了一种优化和紧凑的知识适配器,该适配器可以在推理图中编码文本信息,同时提取其结构信息,如图3所示。通过以更细的颗粒度结合文本信息和结构细节,知识适配器帮助模型深入理解推理图中的知识,从而实现更精确的推理。
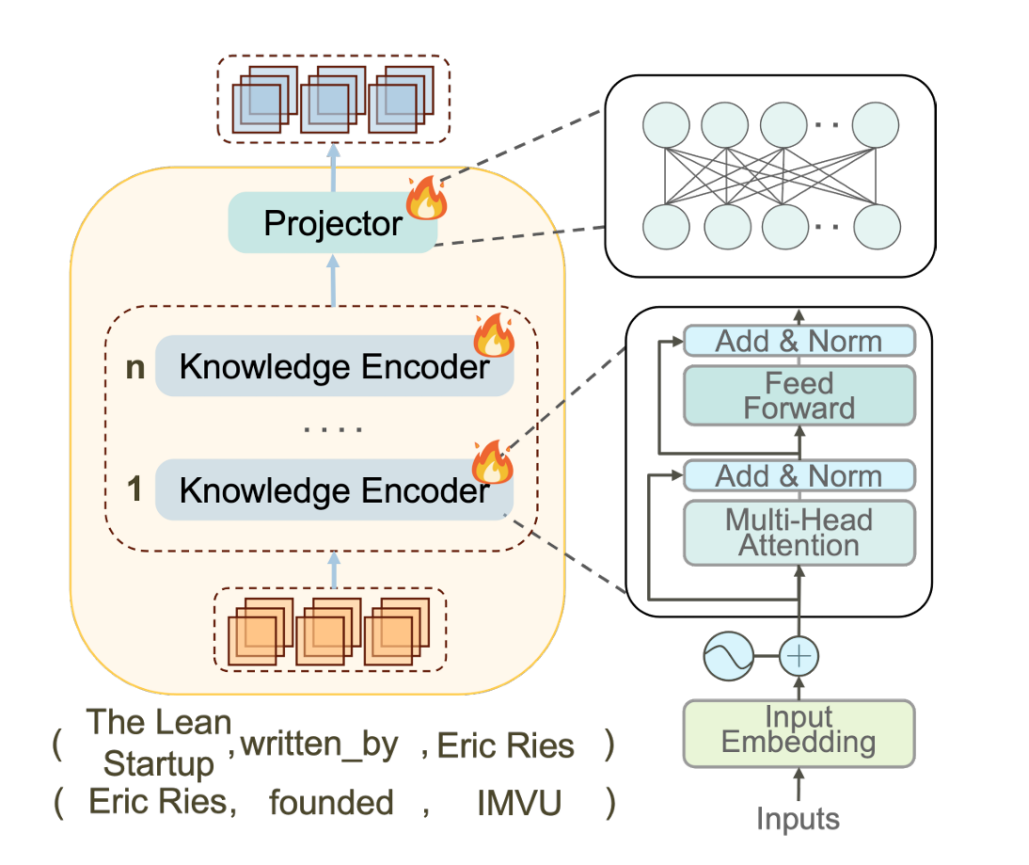
图3 知识适配器的插图及其关键组件的示意图
(3)为了避免对知识库的再训练可能导致模型中现有知识的灾难性遗忘,在LightPROF训练过程中冻结LLM的参数,并使用软提示和硬提示的组合来指导模型更准确高效地回答问题,如图1所示。LLM的输入以聊天格式组织,其中指令和问题结合使用精心设计的文本模板,我们称之为硬提示。在LLM的编码阶段,我们将表示推理图的知识软提示插入硬提示的特定位置,以有效地注入外部知识。这种方法允许LLM根据给定的输入内容自主且准确地回答问题,而无需参数更新。
4. 实验
在实验中,将深入讨论以下问题:
问题1:LightPROF在知识图谱问答(KGQA)任务中能显著提升LLM的性能吗?
问题2:LightPROF能与不同的LLM骨干模型集成以增强性能吗?
问题3:LightPROF能否在小规模LLM上实现高效输入和稳定输出?
数据集:在两个基于Freebase知识图谱的公共数据集上训练和评估LightPROF的多跳推理能力:WebQuestions-sSP(WebQSP)和Complex-WebQuestions(CWQ)。基于先前的研究,利用匹配准确率(Hits@1)来评估模型的top-1答案是否正确。
基准:考虑三种类型的基准方法:完全微调方法、原生LLM方法和LLM知识图谱方法。完全微调方法包括KV-Mem,EmbedKGQA,TransferNet,NSM,KGT5,GraftNet,PullNet,UniKGQA。原生LLM方法包括LLaMa系列模型。LLM知识图谱方法包括StructGPT,ToG,KnowledgeNavigator,AgentBench。值得注意的是,为了确保公平比较,选择的LLM知识图谱方法并不涉及对LLM的微调,即所有方法都是零样本方法,没有对LLM进行任何训练。
实施:为了展示LightPROF的即插即用便利性和参数效率,在LLaMa系列的两个小型语言模型上进行了实验:LLaMa 7B-chat和LLaMa-8B-Instruct1。模型在一个训练周期内优化,批量大小为4。初始学习率设定为2e-3,并使用余弦退火调度进行调整,以提高模型在训练过程中的学习效率。所有实验均在NVIDIA A800 GPU上使用PyTorch工具包进行。知识编码器模块基于BERT模型。该模块包括一个两层的MLP投影器,用于将维度映射到LLM的输入维度。
(1)Q1:性能比较
对LightPROF进行了评估,比较了三类基线方法:完全微调、普通LLM和LLM KG方法。如表1所示,LightPROF不仅在简单问题上表现出色,而且在需要深度推理和复杂查询处理的场景中也表现优异。值得注意的是,框架在所有实验条件下的表现均优于其他大规模模型。例如,在处理复杂问题推理时,框架特别强调与ToG使用LLaMa2-70B-Chat和Struct GPT使用ChatGPT相比的优越性。此外,即使使用较小的LLaMa2-7b版本,框架也能有效与其他大型模型竞争,突显了框架设计的效率和优化。
表1 两个数据集上,LightPROF的性能与基准线进行比较
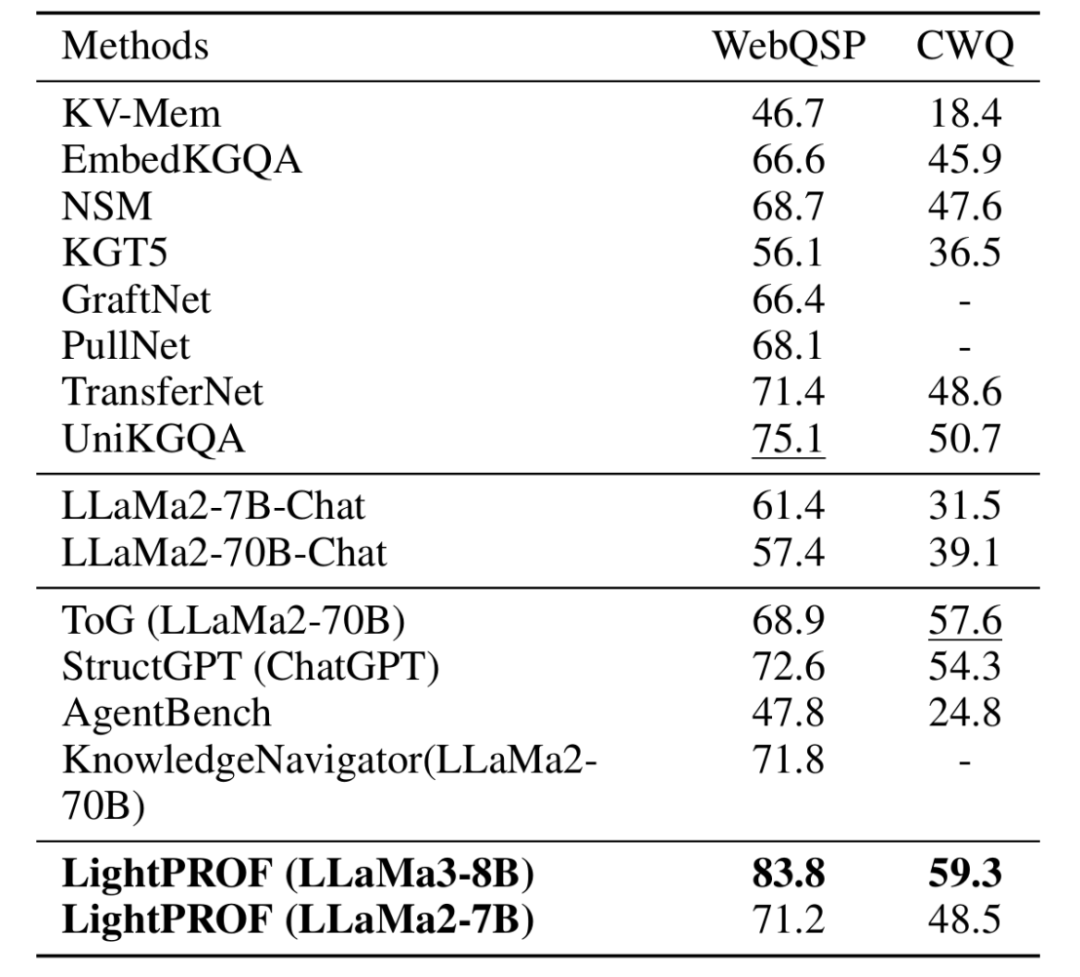
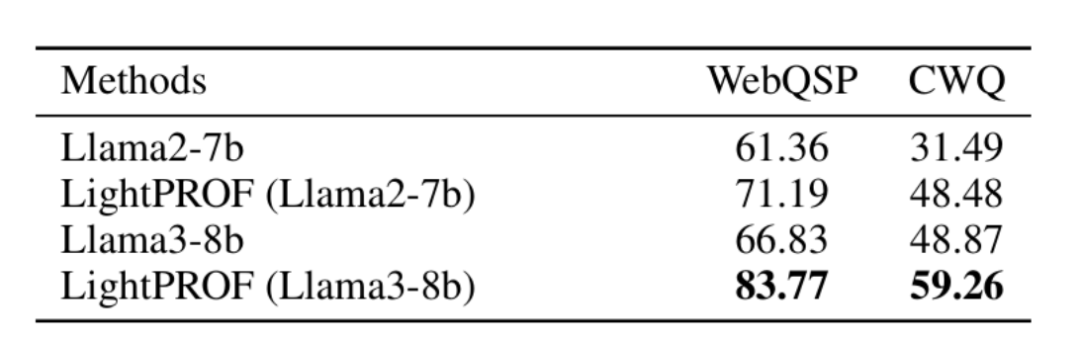
(2)Q2:Plug-and-Play
对于此框架,任何能够接受令牌嵌入输入的开源LLM都是合适的。在本节中,评估了在LightPROF中集成不同LLM的有效性。如表2所示,结果表明,LightPROF框架显著提升了集成LLM的性能,无论原始模型的基线性能如何。LightPROF通过对结构化数据的有效集成和优化,增强了模型解决复杂KG问题的能力。这种即插即用的集成策略不需要对LLM进行昂贵的微调,使其特别适合快速提升现有模型在KGQA任务上的性能。
表2 将各种大型语言模型集成到LightPROF框架中的性能
(3)Q3:高校输入与稳定输出
进行了一系列效率测试,以比较LightPROF和StructGPT在处理WebQSP数据集时的性能。具体而言,测量了模型的运行时间、输入标记的总数及每个请求的平均标记数(NPR),结果如表3所示。表中显示,LightPROF在处理相同数据集时的时间效率更高,时间成本降低了30%(1:11:49对比1:42:12)。关于输入标记的总数,LightPROF和StructGPT之间存在显著差异(365,380对比24,750,610),这表明LightPROF在输入处理上更为经济,减少了大约98%的标记使用。此外,LightPROF的NPR值为224,显著低于StructGPT的6400。这一比较进一步突显了LightPROF在每个请求所需标记数量上的优势,展示了其更精确、资源更高效地处理每个请求的能力,验证了LightPROF在整合小规模LLMs时的有效性。
表3 LightPROF 和 Struct GPTonLlama-3-8b的效率性能

5. 总结
LightPROF框架可以准确地检索和高效地编码知识图 (KGs),以增强大型语言模型 (LLM) 的推理能力。为了有效缩小检索范围,LightPROF使用稳定的关系作为单位,逐步抽样知识图。为了在参数更少的情况下实现LLM的高效推理,开发了一种精细的知识适配器,可以有效解析图结构并进行细粒度的信息整合,从而将推理图凝聚为较少的令牌,并通过投影器与LLM的输入空间实现全面对齐。实验结果表明,框架优于其他基线方法,尤其是那些涉及大规模语言模型的方法。与其他仅基于文本的方法相比,知识软提示整合了更全面的结构和文本信息,使其更易于被LLM理解。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。


点击阅读原文 ,进入 OpenKG 网站。