一、应用层自定义协议与序列化
1. 理解TCP协议
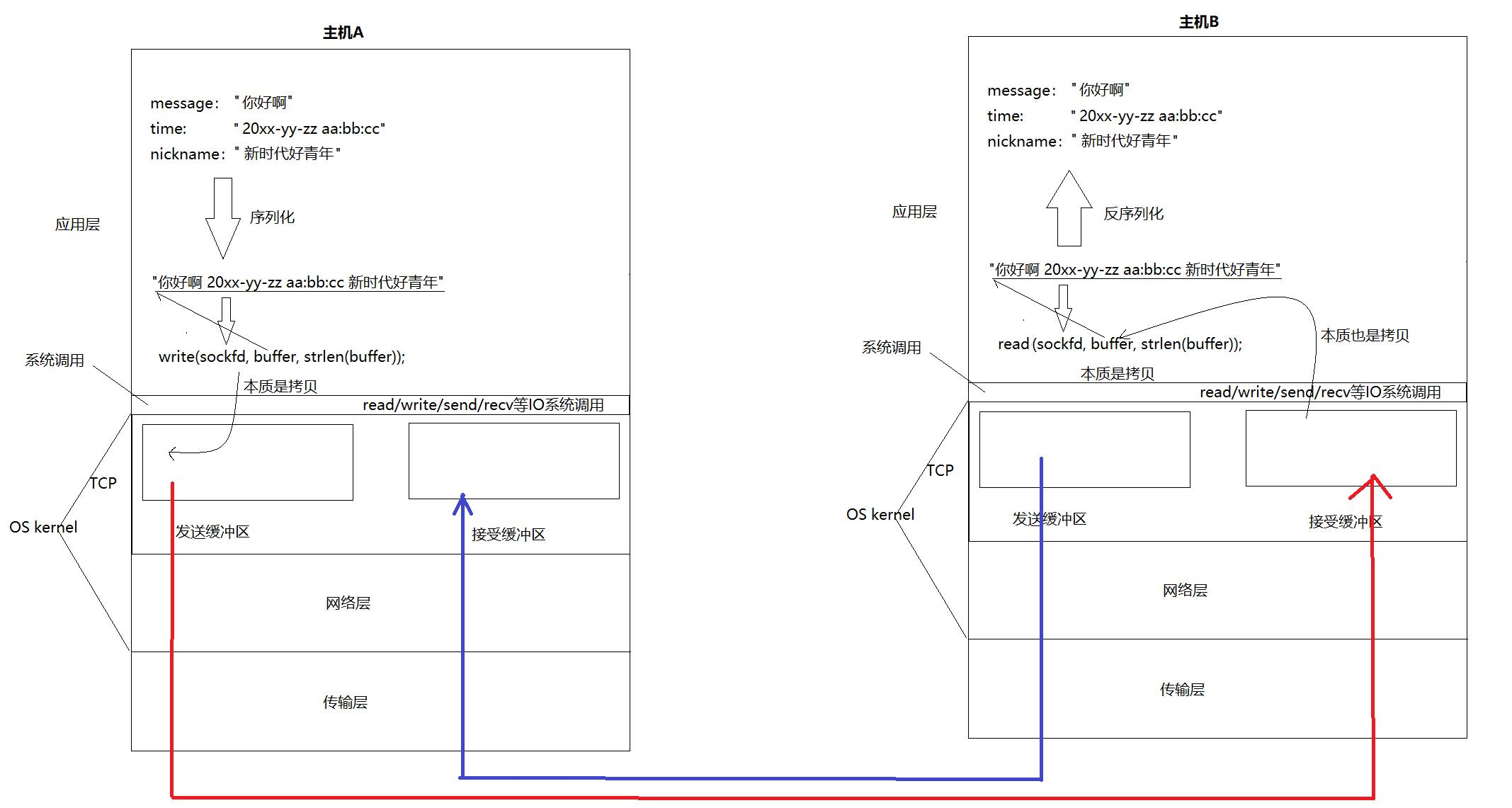
我们在使用read,write接口时,是把数据写到了网络里吗 ?当然不是了,这个问题我们以前回答过,它们是把数据拷贝到了内核的缓冲区里。
TCP/IP...协议它们都是属于OS的一部分 ,TCP协议有发送缓冲区和接收缓冲区,将来write函数将用户缓冲区的内容拷贝到内核缓冲区中(这里指TCP的发送缓冲区),write函数的功能就执行完了。所以,write函数并不是将数据发送到了网络里,而是将数据发送到了TCP的发送缓冲区里。
那么,数据什么时候发送到网络里呢 ?这就是TCP协议要做的事情了。什么时候发,发多少,发送过程中出错了怎么办?都由TCP协议自主控制。
所以TCP协议叫传输控制协议。
每台主机上都会有TCP协议,也就是说发送端与接收端都有发送缓冲区与接收缓冲区 。网络通信的本质就是两个进程间在通信,数据要从发送端的TCP协议里发送到接收端的TCP协议里进行解析,在发送给接收端的上层用户 。本质是把数据从发送端的发送缓冲区里通过网络拷贝到对端的接收缓冲区里。
TCP协议之所以支持全双工 ,本质是因为TCP协议有一对发送缓冲区和接收缓冲区。通过文件描述符可以发送数据也可以接收数据。
发送端将数据拷贝到内核缓冲区里,OS把内核缓冲区里的内容拷贝给对端,这不就是生产者消费者模型吗!这不就是用户在和OS在做同步吗!将来对端读取数据的时候,直接从接收缓冲区里读取,OS给对端接收缓冲区里发送数据,对端进行读取,这不就是用户在和OS在做同步吗!发送端发送数据,发送缓冲区写满之后就不会再进行写入,write不就阻塞了,对端读取数据的时候,接收缓冲区里没有数据,read不就阻塞了。
每一个发送单元,都是一个生产者消费者模型,是用户和内核之间进行生产和消费。
比如今天我们向发送缓冲区里写入 ls -a -l,TCP协议会管我们写入的数据是什么意思吗?不会的。它只知道要发送的数据是8个字节,如果今天对端的接收缓冲区里只有5个字节的空间了,那么TCP协议就会只发送5个字节的数据过去,有一部分数据就没有办法发送过去。
我们把这种情况叫做数据粘报问题。数据有没有读完整,tcp并不关心,而是由用户自己控制维护,这就叫做面向字节流 。
2. 序列化与反序列化
假设今天我们实现了一个结构体,里面包含3个整数,分别表示两个运算数以及存储结果,客户端要如何把一个结构体的数据发送给对端呢?首先可以肯定的是,客户端要把这个数据发送给对端,就要求对端也必须有这个结构体(相同的协议) ,可以直接把这个结构体对象发送给对端,对端用该结构体指针指向这块空间,再依次提取即可。这样做可不可以呢?答案是可以的,但是要面临许多问题。比如内存对齐,大小端问题,跨语言问题。这样做是非常麻烦的。OS是这样做的,OS都是由C语言写的,不存在跨语言问题,其次大小端问题网络也考虑到了,而内存对齐问题不应该由系统内存对齐策略决定,而应该由特定协议报文应该多大决定,标准规定了报文的大小。
既然这么麻烦,所以在应用层就不会这样做了。那要怎么做呢?序列化与反序列化。
比如今天你给你的好朋友发送消息,给你显示的不仅仅只有你发送的数据,还会有时间等数据,所以其实发送的数据包含多个字符串。那么,要如何实现通信呢?只需要在发送端和接收端定义一个相同的消息结构体,我们把多个字符串合并成一条字符串,假设以空格作为分隔符,发送给对端,对端按照空格作为分割符进行依次提取就可以了。
我们把多个字符串合并成一条字符串的过程叫做序列化,对端按照指定的分割符进行提取的过程叫做反序列化。
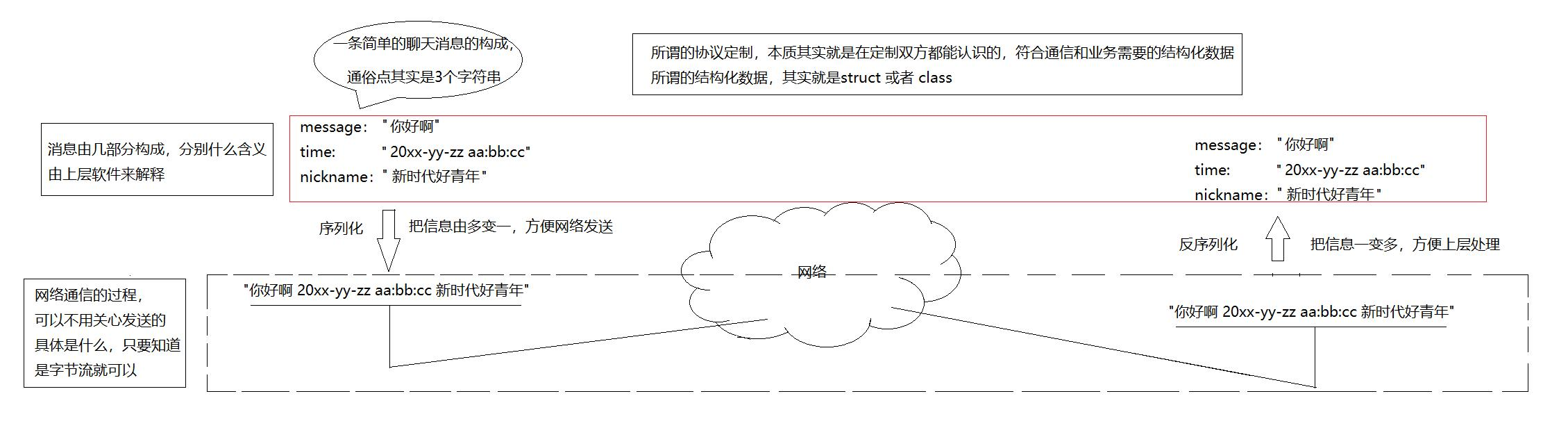
为什么要序列化?
1.方便网络发送(本来要发送多个字符串,现在只发送一个字符串)
2.方便协议的可扩展性和可维护性(如果协议里面还包含日期等信息呢,只需要添加描述日期的字段即可,对于序列化来说,无非是多了几个字节而已)。
3.方便上层处理(按照指定的格式进行提取数据就可以了)。
3. TCP接口

TCP协议是面向字节流的,所以读取数据时可以用read接口,也可以用recv函数。前面我们已经了解了read,现在就来理解一下recv函数。
sockfd是文件描述符,buf是用户自定义缓冲区,len是缓冲区的大小,flags标志位,0默认行为代表阻塞,MSG_DONTWAIT代表非阻塞操作。

成功的话,返回的是读取到的字节数,失败了返回-1设置错误码。返回值为0代表读到文件末尾。

send发送数据,sockfd代表文件描述符,buf发送的数据,len代表发送数据的大小,flags标志位,0默认行为代表阻塞,MSG_DONTWAIT:代表非阻塞操作。

成功了,返回发送的字节数,失败了返回-1设置错误码。
4. 序列化的现成工具
cpp
ubuntu:sudo apt install libjsoncpp-dev
Centos: sudo yum install jsoncpp-devel序列化是指将数据结构或对象转换为一种格式,以便在网络上传输或存储到文件中。Jsoncpp提供了多种方式进行序列化。上面的命令是分别在Centos和ubuntu系统下安装jsoncpp的方法。
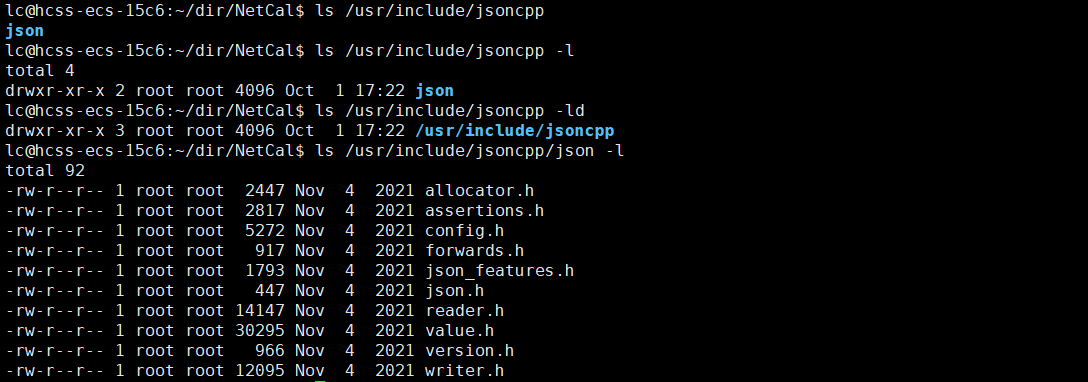
这是jsoncpp的头文件。

jsoncpp的库文件。
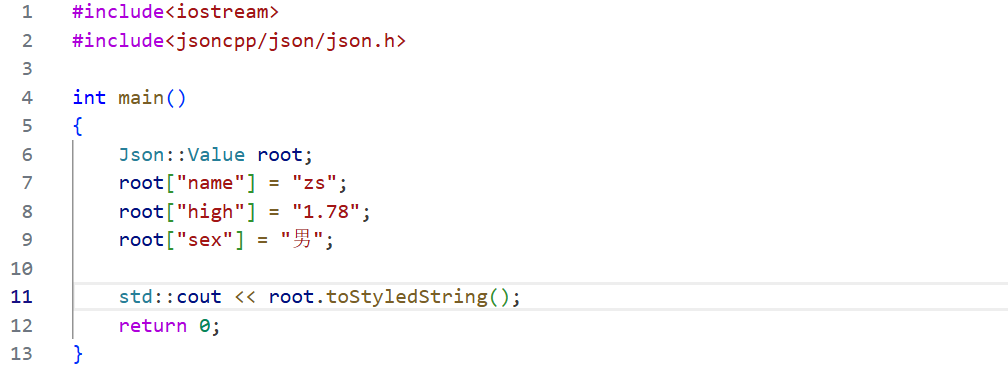
用Json::Value创建出来的对象称之为万能对象,将来可以使用[]的方式来插入数据,括号中的值为键值,= 右边的值为Value,可以插入不同的数据。
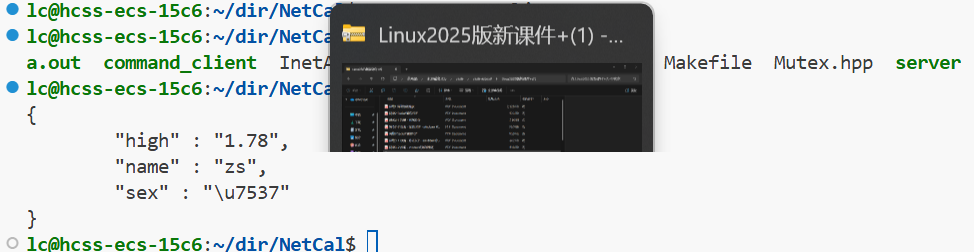
第二种方法 :StreamWriter是一个抽象类,StreamWriterBuilder是一个独立的类,newStreamWriter是它的一个函数,用来创建StreamWriter子类的对象,用来初始化对象,write函数是将Json::Value对象的内容可以写到流对象中的。
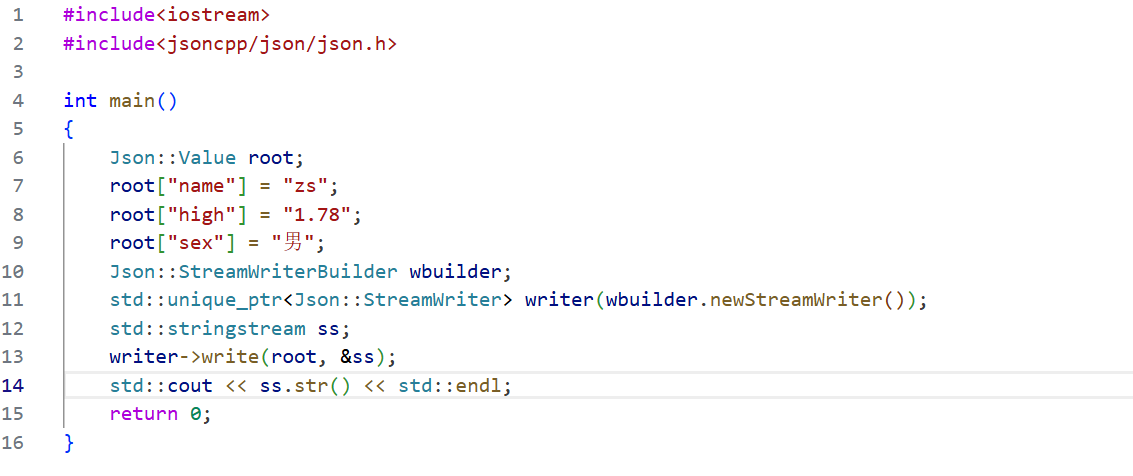
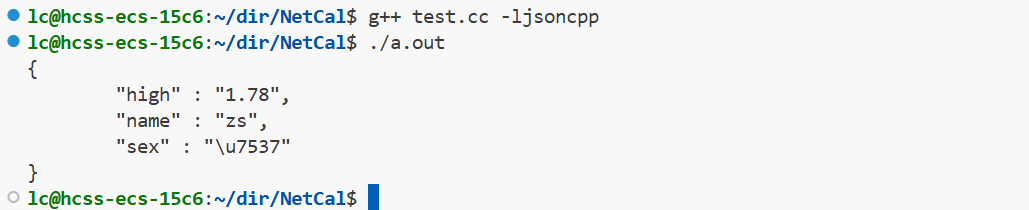
第三种方法 :创建一个FastWriter对象,通过这个对象调用write函数,该函数返回一个序列化后的string对象。
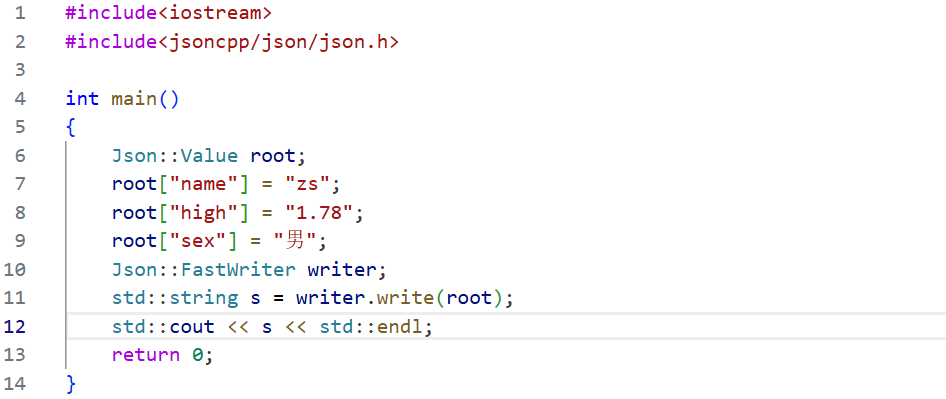

第四种方法 :创建StyledWriter对象。
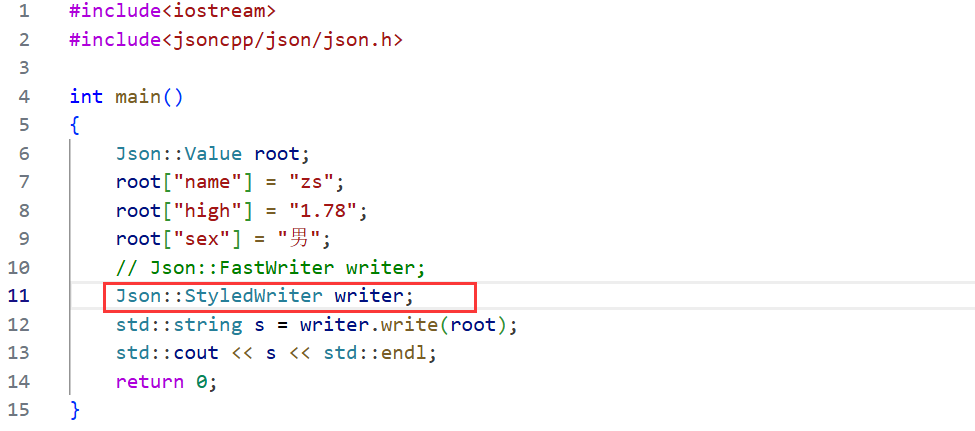
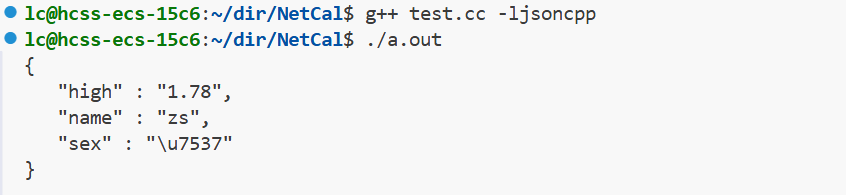
现在,序列化方式我们已经学习了四种,接下来就看反序列化。
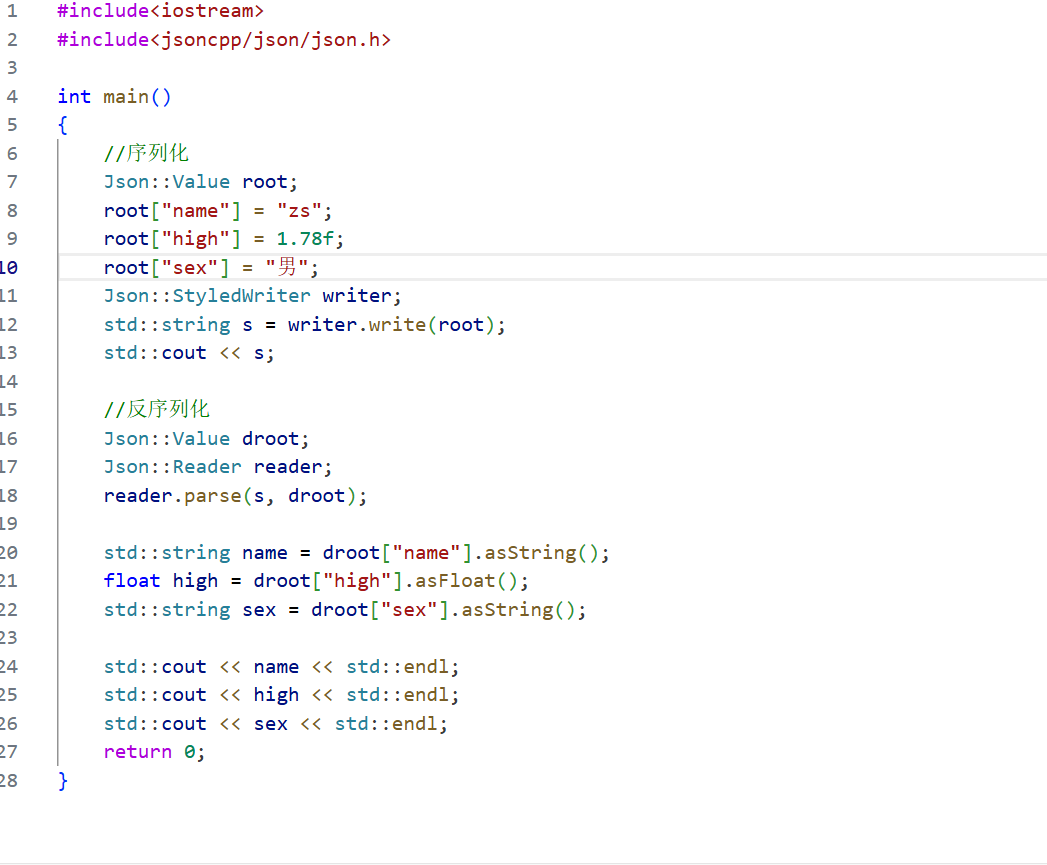
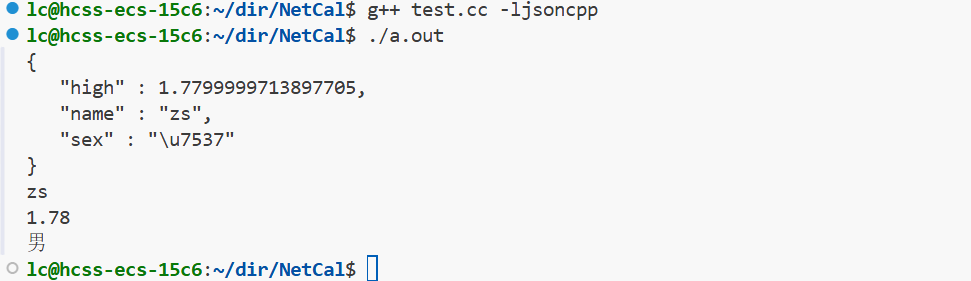
创建Reader类的对象,通过parse函数进行反序列化,将结果写入到Json::Value的对象中,最后在根据键值提取结果即可。
5. 守护进程
在谈守护进程之前,我们先来说说前台进程和后台进程。
前台进程和后台进程前面我们简单了解过。一个系统内只能有一个前台进程,用来获取键盘上的输入数据。


后台进程不影响bash,用户可以在进程运行期间,继续访问linux。
那我们一次性启动一批进程。


可以看到,这些进程的ppid是bash进程,那还有一个PGID呢?它又是什么呢?
PGID是进程组ID,进程组ID一般是以多个进程中的第一个进程ID作为进程组ID的。
那为什么要有进程组呢?
是为了启动一个进程组,共同完成一个任务。

那这个1代表什么呢 ?代表的是任务号。
那进程组和任务号又是什么关系呢?
举一个例子:有一个包工头张三,小区里现在有一堆垃圾要进行清理,物业给了5000块钱,现在要清理垃圾,张三找了3个农民工大叔,每人给500,你们3个成立一个垃圾小组,来清理小区里的垃圾,共同完成这个任务。一会物业的人来了,张三让你清理垃圾呢,垃圾清理了吗!张三说垃圾有3个人在清理呢。物业的人说,现在有一个新的任务,东边有一堵墙要拆掉,再给你3000块钱,你去把它拆掉,张三又找了2个农民工,成立拆墙小队,你们两个每人给500块,去把东边的墙给拆掉。
所以,这么多组是为了完成不同的任务的 。创建进程组不是目的,是手段,完成任务才是目的。
cpp
jobs//查看后台进程
fg 任务号//将指定的后台进程提到前台
Ctrl + z//前台进程放到后台进程
bg 任务号//激活暂停的后台作业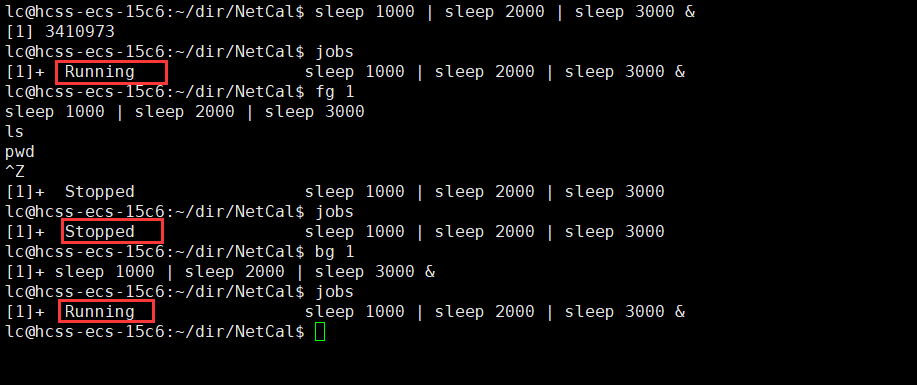
进程组的生命周期 :从进程组创建开始到其中最后一个进程离开为止。即进程组中只要还有一个进程存在,则该进程组存在,这与其组长进程是否终止无关。
注 :进程组至少应包含一个进程。
当用户登录linux云服务器的时候,就会创建一个终端文件和bash进程组(一个进程),将来在bash进程里创建各个进程组,用来执行不同的任务。bash进程自动从终端文件继承0,1,2这三个文件描述符,所以,bash的子进程也会继承这几个文件描述符。

为什么这里的文件描述符都指向了同一个终端文件呢 ?因为这是云服务器,它没有键盘,所以都指向了终端文件。
我们把用户登录linux云服务器时,创建的终端文件,各种进程组叫做一次会话 ,此时怎么证明它们是同一个会话呢?SID相同就可以了,SID(session id)。
就比如,你怎么证明你和你的舍友是属于同一个班级的呢?只要编号一样就可以了。
现在,张三要登录linux,李四也要登录linux,王五也要登录linux,那么就要给每一个用户都要创建终端文件和bash进程,即一个会话,这么多的会话,每个会话的ID也是不一样的。
以一个会话为例,用户登录成功后会有一个独立的会话,在这个会话内部可以创建多个进程组。
所以进程组完成任务,是在会话内部完成的。
进程组是为了完成任务的,如果退出了Linux云服务器,那么整个会话也要被干掉,进程组也会被释放,那么任务就收到了影响 。老版本会,现在不会了。这里我们认为任务会受到影响,所以任务是会受到用户登录和注册的影响,我们肯定是不希望这样的,该怎么办呢?
所以,我们要把它拿出来,形成一个和bash并行的独立会话,我们把这种独立会话的后台进程叫做守护进程。
一次会话中,只允许一个前台进程组,但可以同时存在多个后台进程组。
前台进程和后台进程,都可以向终端文件进行写入,但只有前台进程能够从标准输入中获取数据。
为什么只能有一个前台进程组呢 ?因为需要和用户进行交互,获取用户的标准输入,标准输入只有一个,前台进程必须只有一个。
所以,Ctrl + c只能终止前台进程。
那如何让我的进程(组)成为守护进程呢?

创建一个会话,该会话的ID就是调用该函数的ID。

成功的话,新会话的ID就是调用进程的ID,失败返回-1设置错误码。

最重要的一点,新会话的ID不能是调用进程的进程组长ID。那要怎么办呢?
所以,我们可以通过fork创建子进程,让子进程执行后续代码,父进程退出。此时该进程就成为守护进程了。所以守护进程的本质就是孤儿进程。

/dev/null文件,它就像一个文件垃圾桶一样,向里面写入数据会被丢弃掉,从该文件中读取数据什么也不会读到。
建议把守护进程的路径设置为根目录。