标题:VBench: Comprehensive Benchmark Suite for Video Generative Models
作者:Ziqi Huang、Yinan He、Jiashuo Yu、Fan Zhang、Chenyang Si、Yuming Jiang、Yuanhan Zhang、Tianxing Wu、Qingyang Jin、Nattapol Chanpaisit、Yaohui Wang、Xinyuan Chen、Limin Wang、Dahua Lin、Yu Qiao、Ziwei Liu
单位:1. 南洋理工大学 S-Lab;2. 上海人工智能实验室;3. 香港中文大学;4. 南京大学
发表:arXiv 预印本,arXiv:2311.17982v1 cs.CV
论文链接 :https://arxiv.org/pdf/2311.17982
项目主页链接 :https://vchitect.github.io/VBench-project/
代码链接 :https://github.com/Vchitect/VBench
关键词:视频生成模型、评估基准、细粒度评估、人类感知对齐、时间一致性、语义一致性、文本到视频生成(T2V)、视觉语言模型(VLM)
在视频生成技术飞速发展的当下,如何客观、全面地评估这些模型的性能成为了领域内的关键难题。现有评估指标如 FID、FVD 等不仅与人类主观感知存在偏差,还无法精准揭示模型在不同维度的优劣。为此,来自南洋理工大学、上海人工智能实验室等机构的研究团队提出了VBench------ 一个涵盖多维度、与人类感知高度对齐且能提供深度洞察的视频生成模型评估基准套件,为视频生成提供技术参考。
一、研究背景与动机
1.1 视频生成技术的发展现状
近年来,图像生成模型(如 VAE、GAN、扩散模型等)取得了突破性进展,这也推动了视频生成技术的快速演进。当前主流的视频生成模型多基于扩散架构,支持文本到视频(T2V)、图像到视频(I2V)、视频到视频(V2V)等多种任务,能够生成具有动态效果的视频内容。然而,随着模型数量的增多和能力的提升,如何科学评估其性能成为了亟待解决的问题。
1.2 现有评估方法的局限性
现有视频生成评估方法存在两大核心缺陷:
- 与人类感知脱节:传统指标(如 IS、FID、FVD、CLIPSIM)仅从数据分布或特征相似度角度衡量性能,与人类对视频质量的主观判断偏差较大。例如,FVD 仅关注视频帧间的统计差异,却无法捕捉 "运动流畅性""主体一致性" 等人类敏感的维度。
- 缺乏细粒度洞察:现有指标多以单一数值概括模型性能,无法揭示模型在特定维度(如背景一致性、风格匹配度)的优势与短板,难以指导后续模型优化(如数据选择、架构设计)。
此外,视频质量评估(VQA)方法主要针对真实视频设计,未考虑生成模型特有的问题(如 temporal flickering、主体形变等)。因此,构建一个专为视频生成模型设计、与人类感知对齐的综合评估框架迫在眉睫。
二、VBench 的核心设计:三大核心组件
VBench 通过评估维度套件(Evaluation Dimension Suite) 、提示词套件(Prompt Suite) 和评估方法套件(Evaluation Method Suite) 的协同设计,实现了对视频生成模型的细粒度、客观化评估。其整体框架如图 1 所示:
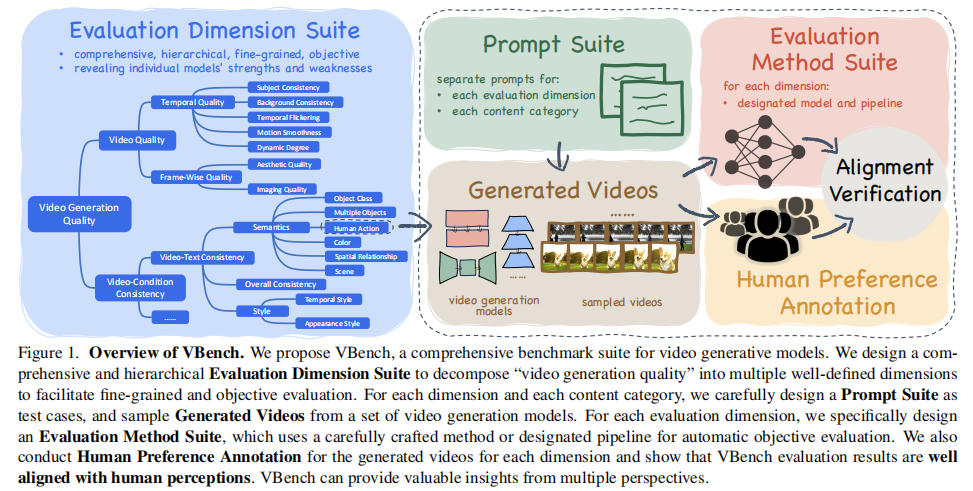
图 1:VBench 整体框架。VBench 将 "视频生成质量" 拆解为多维度,为每个维度和内容类别设计专属提示词,通过自动化评估方法打分,并结合人类偏好标注验证与人类感知的对齐性。
2.1 评估维度套件:16 个细粒度维度的分层设计
VBench 突破了传统 "单一数值评估" 的局限,将 "视频生成质量" 自上而下拆解为两大一级维度 和16 个二级维度,确保每个维度独立评估视频的某一特定属性,避免相互干扰。
2.1.1 一级维度 1:视频质量(Video Quality)
聚焦视频本身的感知质量(不考虑与输入条件的匹配度),进一步分为 "时间质量(Temporal Quality)" 和 "帧级质量(Frame-Wise Quality)":
| 二级维度 | 核心评估目标 | 评估方法 | 示例 |
|---|---|---|---|
| 主体一致性(Subject Consistency) | 视频中主体(如动物、人物)的外观是否全程一致 | 计算 DINO 特征在帧间的余弦相似度 | 生成 "一只猫跑过草地" 的视频,需确保猫的毛色、体型无突变 |
| 背景一致性(Background Consistency) | 背景场景的帧间一致性 | 计算 CLIP 特征在帧间的余弦相似度 | 生成 "城市街道夜景" 的视频,需确保建筑、路灯等背景元素无突然变化 |
| 时间闪烁(Temporal Flickering) | 局部高频细节的帧间闪烁(如光影突变) | 静态帧的帧间平均绝对误差(MAE) | 生成 "静态风景" 视频,避免像素值突然跳变导致的闪烁感 |
| 运动流畅性(Motion Smoothness) | 运动是否符合物理规律、无卡顿 | 基于视频帧插值模型(AMT),计算插值帧与原帧的 MAE | 生成 "人骑自行车" 的视频,需确保车轮转动、身体姿势变化流畅 |
| 动态程度(Dynamic Degree) | 视频是否包含合理的动态内容(避免 "伪静态") | 用 RAFT 估计光流,统计非静态视频比例 | 生成 "海浪拍打沙滩" 的视频,需体现海浪的自然动态,而非静止画面 |
| 美学质量(Aesthetic Quality) | 帧的艺术感、色彩和谐度、构图合理性 | LAION 美学预测器(0-10 分归一化) | 生成 "日落山景" 视频,评估画面的色彩搭配、视觉吸引力 |
| 成像质量(Imaging Quality) | 帧的低阶失真(如模糊、过曝、噪声) | MUSIQ 图像质量预测器(基于 SPAQ 数据集) | 生成 "清晰的汽车特写" 视频,避免画面模糊或过曝 |
2.1.2 一级维度 2:视频 - 条件一致性(Video-Condition Consistency)
聚焦视频与输入条件(如文本提示)的匹配度,进一步分为 "语义一致性(Semantics)" 和 "风格一致性(Style)":
| 二级维度 | 核心评估目标 | 评估方法 | 示例 |
|---|---|---|---|
| 物体类别(Object Class) | 是否生成提示词中指定类别的物体 | GRiT 目标检测,统计目标出现的帧比例 | 提示 "一只狗",需确保视频中出现狗的帧比例高 |
| 多物体生成(Multiple Objects) | 是否同时生成提示词中多个指定物体 | GRiT 检测,统计所有物体同时出现的帧比例 | 提示 "一只狗和一只猫",需确保狗和猫在同一帧中同时出现 |
| 人类动作(Human Action) | 人类主体是否执行提示词中的指定动作 | UMT 动作分类(基于 Kinetics-400),统计动作匹配率 | 提示 "人在跳舞",需确保视频中人类动作被分类为 "跳舞" |
| 颜色一致性(Color) | 物体颜色是否与提示词匹配 | GRiT 颜色描述,对比生成颜色与提示颜色 | 提示 "红色的苹果",需确保生成的苹果被 GRiT 标注为红色 |
| 空间关系(Spatial Relationship) | 物体间空间位置是否符合提示词 | GRiT 检测物体边界框,验证 "左右 / 上下" 关系 | 提示 "苹果在桌子左边",需确保苹果边界框的 x 坐标小于桌子 |
| 场景一致性(Scene) | 场景是否与提示词描述匹配 | Tag2Text 场景标注,对比标注与提示场景 | 提示 "海滩场景",需确保 Tag2Text 标注包含 "海滩" 关键词 |
| 外观风格(Appearance Style) | 帧的视觉风格(如油画、赛博朋克)是否匹配提示 | CLIP 特征相似度(帧与风格描述的余弦相似度) | 提示 "梵高风格的星空",需确保帧特征与 "梵高风格" 文本特征高度相似 |
| 时间风格(Temporal Style) | 视频的时间动态风格(如缩放、摇镜)是否匹配提示 | ViCLIP 特征相似度(视频与时间风格描述的余弦相似度) | 提示 "镜头缓慢放大",需确保视频特征与 "缩放" 文本特征高度相似 |
| 整体一致性(Overall Consistency) | 视频与提示词的整体匹配度(语义 + 风格) | ViCLIP 视频 - 文本特征相似度 | 提示 "未来城市的雨夜",综合评估场景、风格、动态是否匹配 |
2.2 提示词套件:精准覆盖维度与内容类别
为确保评估的有效性和代表性,VBench 设计了两类提示词套件,分别针对 "评估维度" 和 "内容类别":
2.2.1 按评估维度设计的提示词(~100 条 / 维度)
每个维度的提示词均经过精心设计,以精准测试该维度的能力。例如:
- 主体一致性:提示词需包含 "可移动主体 + 动态动作"(如 "一只兔子跳过草地"),确保主体在运动中可能出现一致性问题;
- 时间闪烁:提示词需包含 "静态场景"(如 "静止的花瓶"),避免运动干扰闪烁评估;
- 人类动作:提示词中的动作均来自 Kinetics-400,且语义无重叠(如 "跑步""游泳""弹钢琴")。
2.2.2 按内容类别设计的提示词(8 类,100 条 / 类)
为评估模型在不同内容上的泛化能力,VBench 参考 YouTube 分类,将提示词分为 8 个类别,覆盖常见视频内容:
- 动物(Animal):如 "一只松鼠吃坚果";
- 建筑(Architecture):如 "悉尼歌剧院的夜景";
- 食物(Food):如 "新鲜出炉的饼干";
- 人类(Human):如 "一家人在公园野餐";
- 生活方式(Lifestyle):如 "室内酒吧的装修";
- 植物(Plant):如 "植物园中的热带植物";
- 风景(Scenery):如 "沙漠日出的全景";
- 交通工具(Vehicles):如 "火车驶入车站"。
提示词分布的词云图和数量统计如图 3 所示:
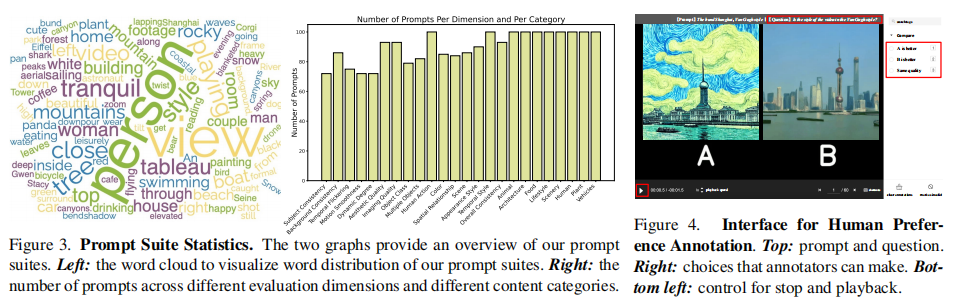
图 3:提示词套件统计。左图为提示词词云,右图为各评估维度和内容类别的提示词数量分布。
2.3 评估方法套件:自动化与人类对齐的双重保障
VBench 为每个维度设计了专属的自动化评估方法(如 DINO、CLIP、GRiT 等),同时通过人类偏好标注验证评估结果与人类感知的一致性。
2.3.1 自动化评估方法的设计原则
- 针对性:方法需与维度目标高度匹配(如用 RAFT 光流评估动态程度,而非通用特征);
- 可复现性:基于开源工具和预训练模型(如 DINO、CLIP),确保其他研究者可复现;
- 客观性:避免主观判断,所有评估均基于量化指标(如相似度、检测率)。
2.3.2 人类偏好标注:验证与人类感知的对齐性
为证明 VBench 评估结果的可靠性,研究团队进行了大规模人类标注:
- 数据准备:选择 4 个主流 T2V 模型(LaVie、ModelScope、VideoCrafter、CogVideo),对每个提示词生成 5 组视频(每组 4 个模型各 1 个视频),共产生 "提示词 ×5 组 ×6 对(4 模型两两配对)" 的 pairwise 比较样本;
- 标注规则:标注者仅关注当前评估维度(如 "主体一致性"),从一对视频中选择更优者,或判定 "质量相当";
- 质量控制:通过 "预标注培训→标注后随机抽查(误差率>10% 则重标)" 确保标注质量。
三、实验验证:VBench 的有效性与可靠性
研究团队基于 4 个主流 T2V 模型(LaVie、ModelScope、VideoCrafter、CogVideo)进行了全面实验,验证 VBench 的三大核心价值:维度区分度 、人类对齐性 、跨类别泛化性。
3.1 实验设置
- 模型选择:覆盖不同架构的 T2V 模型(扩散模型:LaVie、ModelScope、VideoCrafter;Transformer 模型:CogVideo);
- 参考基线:
- Empirical Max:各维度可达到的理论最高分(如静态视频在 "主体一致性" 上得 100%);
- Empirical Min:各维度可达到的理论最低分(如高斯噪声视频在 "外观风格" 上得 0%);
- WebVid-Avg:WebVid-10M 数据集(常用 T2V 训练数据)在各维度的平均分,反映真实视频的基准水平;
- 评估指标:各维度得分(百分比,越高越好)、模型胜率(pairwise 比较中模型被选中的比例)、Spearman 相关系数(衡量 VBench 得分与人类偏好的相关性)。
3.2 核心实验结果
3.2.1 维度区分度:精准揭示模型优劣
4 个模型在 16 个维度的评估结果如图 2 所示(数值结果见表 1):
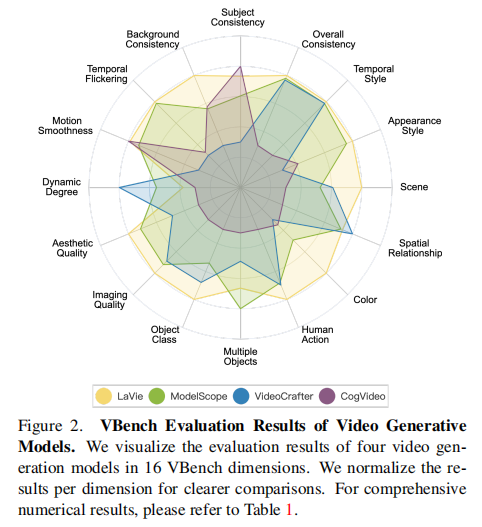
图 2:4 个 T2V 模型在 16 个维度的归一化得分。每个维度的得分已归一化,便于跨维度比较。
从结果可观察到模型的显著差异:
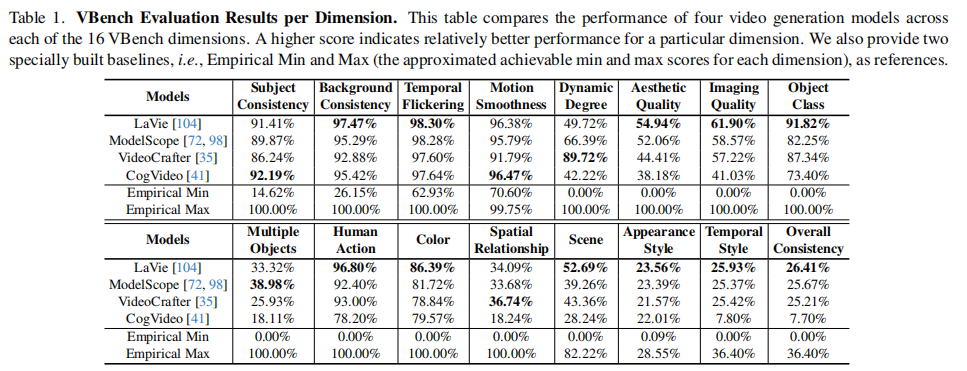
- LaVie:在时间一致性维度(主体一致性 91.41%、背景一致性 97.47%、时间闪烁 98.30%)表现最优,但动态程度较低(49.72%);
- VideoCrafter:动态程度最高(89.72%),但时间一致性维度(主体一致性 86.24%、背景一致性 92.88%)表现较差;
- CogVideo:在人类动作(96.80%)和场景一致性(86.39%)上有优势,但美学质量(19.35%)和成像质量(7.74%)垫底;
- ModelScope:综合表现均衡,在多物体生成(38.98%)和颜色一致性(33.68%)上优于其他模型。
这一结果证明,VBench 能够精准捕捉模型在不同维度的强弱,为模型优化提供明确方向。
3.2.2 人类对齐性:VBench 得分与人类偏好高度相关
研究团队计算了 "VBench 预测的模型胜率" 与 "人类标注的模型胜率" 的 Spearman 相关系数,结果如图 5 所示:
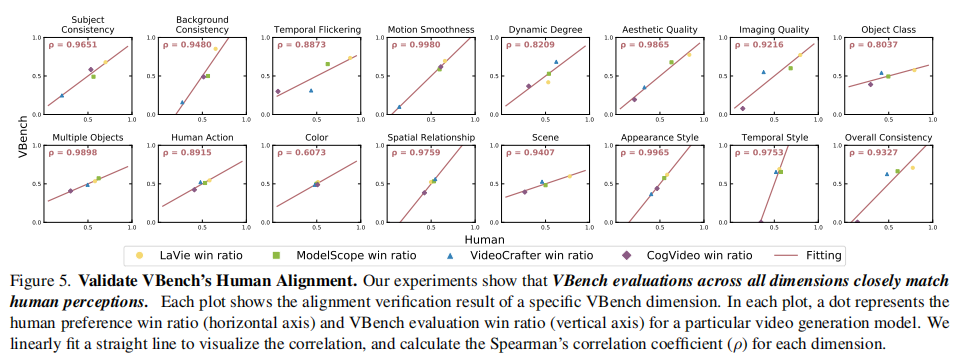
图 5:各维度下 VBench 胜率与人类胜率的相关性。每个点代表一个模型的 "人类胜率(横轴)" 与 "VBench 胜率(纵轴)",拟合线的 Spearman 系数均>0.6,证明高度相关。
关键结论:
- 所有 16 个维度的相关系数均>0.6,其中 "运动流畅性"(0.998)、"外观风格"(0.9965)等维度的相关性接近 1;
- 平均相关系数达 0.92,证明 VBench 的自动化评估结果与人类主观判断高度一致,解决了传统指标 "与人类感知脱节" 的问题。
3.2.3 跨类别泛化性:模型在不同内容上的能力差异
4 个模型在 8 个内容类别的评估结果如图 7 所示:
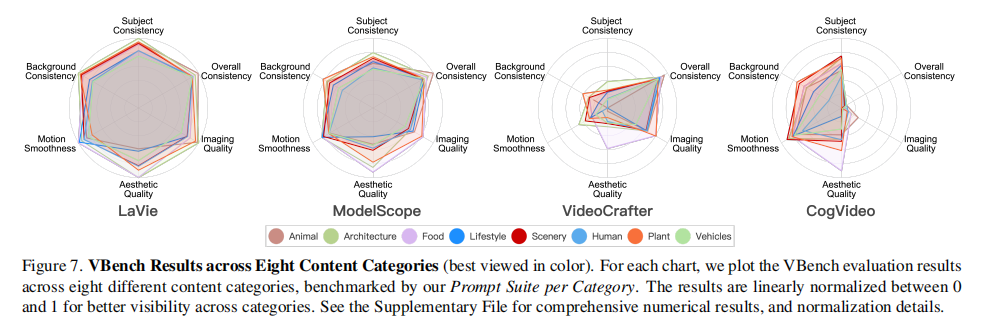
图 7:4 个模型在 8 个内容类别的归一化得分。每个雷达图代表一个模型在不同类别的综合表现。
核心发现:
- 内容类别对模型性能影响显著:例如 CogVideo 在 "食物" 类别的美学质量(52.79%)远高于 "动物" 类别(45.37%),说明模型在特定内容上有隐藏优势;
- 复杂类别性能瓶颈:"人类""交通工具" 等包含复杂动态的类别,所有模型在 "美学质量""成像质量" 上得分均较低,原因是动态建模误差导致画面模糊或失真;
- 数据质量>数量:WebVid-10M 中 "食物" 类别仅占 11%(见图 A27,附录图这里就不放了,需要的话可以去原文中查看哦,下同),但所有模型在 "食物" 类别的美学质量最高(见图 A28),证明数据质量对模型性能的影响大于数量。
3.2.4 拓展实验:T2V vs T2I 模型的帧级能力对比
为探究 T2V 模型是否继承了 T2I 模型的帧级生成能力,研究团队将 T2V 模型与 3 个主流 T2I 模型(SD 1.4、SD 2.1、SDXL)在 10 个帧级维度(如美学质量、物体类别)进行对比,结果如图 6(a)所示:
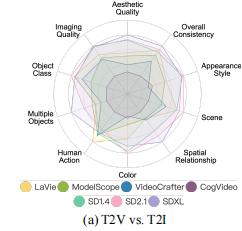
图 6(a):T2V 模型与 T2I 模型在帧级维度的归一化得分。SDXL 在多数帧级维度表现最优。
关键结论:
- T2V 模型在 "多物体生成""空间关系" 等构图维度显著落后于 T2I 模型(如 SDXL 在 "多物体生成" 上得分是 LaVie 的 2 倍),说明 T2V 模型的构图能力仍需提升;
- 差距原因:T2I 模型采用更强大的文本编码器(如 SDXL 用 CLIP ViT-L+OpenCLIP ViT-G),而 T2V 模型多仅用 CLIP ViT-L,导致文本理解精度不足。
3.2.5 拓展实验:T2V 模型与真实视频的差距
将 T2V 模型与 WebVid-Avg(真实视频基准)、Empirical Max(理论上限)对比,结果如图 6(b)所示:
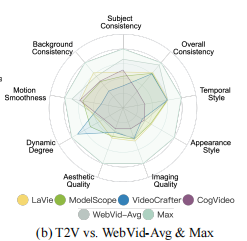
图 6(b):T2V 模型与 WebVid-Avg、Empirical Max 的归一化得分。WebVid-Avg 反映真实视频水平。
关键结论:
- T2V 模型在 "时间闪烁""运动流畅性" 等时间维度已接近真实视频(WebVid-Avg),但在 "外观风格""整体一致性" 等语义维度仍有显著差距;
- 所有模型在 "动态程度" 上均低于 WebVid-Avg,说明 T2V 模型生成的动态内容仍不够丰富。
四、关键洞察:指导视频生成领域的未来方向
通过 VBench 的实验结果,研究团队提炼出 6 个对领域发展至关重要的洞察,为后续研究提供明确指导:
4.1 时间一致性与动态程度的 trade-off
实验发现,模型在 "时间一致性"(主体 / 背景一致性、无闪烁)和 "动态程度" 间存在明显权衡:
- LaVie 通过生成相对静态的场景(动态程度 49.72%)获得高时间一致性;
- VideoCrafter 虽动态程度高(89.72%),但时间闪烁严重(31.20%)。
未来方向:需开发能同时提升时间一致性和动态程度的模型(如改进时间注意力机制,捕捉长期动态依赖)。
4.2 模型在特定内容类别的隐藏优势
传统平均得分可能掩盖模型的局部优势:例如 CogVideo 的整体美学质量较低(19.35%),但在 "食物" 类别上得分达 52.79%,接近 ModelScope(53.06%)。
未来方向:针对模型优势类别设计专项训练数据,或采用 "类别自适应生成" 策略,提升模型在弱势类别的性能。
4.3 动态复杂类别的性能瓶颈
"人类""交通工具" 等包含复杂动态的类别,所有模型在 "美学质量""成像质量" 上得分均较低,原因是:
- 动态建模误差导致画面模糊(如人物动作过快时出现拖影);
- 复杂结构(如人体关节、车辆部件)在运动中易发生形变。
未来方向:引入动态先验(如人体骨架、车辆运动模型),增强对复杂动态的建模能力。
4.4 复杂类别(如人类)的 "数据量陷阱"
WebVid-10M 中 "人类" 类别占比最高(26%,见图 A27),但所有模型在 "人类" 类别的表现仍最差,说明:
- 仅增加数据量无法解决复杂类别的建模难题;
- 现有数据中 "人类" 样本的标注精度(如动作、姿态)不足。
未来方向:构建高质量的 "人类视频数据集"(包含精细动作标注、骨架信息),或引入人类先验知识(如人体动力学模型)。
4.5 数据质量比数量更重要
"食物" 类别在 WebVid-10M 中仅占 11%,但所有模型在该类别上的美学质量最高(见图 A28),原因是 "食物" 样本的视觉质量(色彩、构图)普遍优于其他类别。
未来方向:利用 VBench 的维度得分筛选高质量训练数据(如优先选择 "美学质量" 高的样本),提升模型整体性能。
4.6 T2V 模型的构图能力短板
T2V 模型在 "多物体生成""空间关系" 上显著落后于 T2I 模型,原因包括:
- 文本编码器能力不足(T2I 用更大模型);
- 训练数据中缺乏 "多物体 + 明确空间关系" 的样本;
- 视频生成过程中未引入空间控制模块。
未来方向:
- 采用更强大的文本编码器(如 SDXL 的双编码器架构);
- 构建 "多物体空间关系" 专项训练数据;
- 在视频生成中加入空间控制模块(如 ControlNet)。
五、局限性与未来工作
5.1 现有局限性
- 模型覆盖有限:当前仅评估 4 个开源 T2V 模型,未包含闭源模型(如 Pika Labs、Gen-2);
- 任务覆盖有限:仅支持 T2V 任务评估,未扩展到 I2V、V2V 等其他视频生成任务;
- 伦理维度缺失:未评估模型生成内容的安全性(如是否生成有害信息)和公平性(如是否存在种族 / 性别偏见)。
5.2 未来计划
- 扩展模型库:开源 VBench,邀请社区贡献更多模型(包括闭源模型的 API 调用结果);
- 扩展任务范围:将 "视频 - 条件一致性" 维度适配到 I2V(评估视频与输入图像的匹配度)、V2V(评估编辑后视频与原视频的一致性)等任务;
- 加入伦理评估:新增 "安全性""公平性" 维度,评估模型生成内容的社会影响;
- 优化评估方法:结合人类标注数据微调视觉 - 语言模型(如 VideoChat),进一步提升自动化评估的精度。
六、总结
VBench 作为首个 "细粒度、人类对齐、洞察驱动" 的视频生成模型评估基准,通过 16 个分层维度、精准提示词套件和自动化评估方法,解决了传统评估 "与人类感知脱节""缺乏维度区分度" 的核心问题。其实验结果不仅揭示了当前 T2V 模型的性能瓶颈,还为后续研究提供了明确的优化方向(如动态一致性权衡、数据质量筛选、构图能力提升等)。
随着 VBench 的开源(包含所有提示词、评估代码、生成视频、人类标注数据),或将成为视频生成领域的核心评估工具,推动模型性能与应用场景的持续拓展。未来,结合伦理评估和多任务支持,VBench 将进一步助力视频生成技术的 "高质量、负责任" 发展。