
Java 大视界 -- Java 大数据机器学习模型在游戏用户行为分析与游戏平衡优化中的应用
- 引言
- 正文
-
-
- 一、游戏行业现状与挑战
-
- [1.1 行业现状](#1.1 行业现状)
- [1.2 面临挑战](#1.2 面临挑战)
- [二、Java 大数据机器学习模型技术支撑](#二、Java 大数据机器学习模型技术支撑)
-
- [2.1 大数据存储与管理](#2.1 大数据存储与管理)
- [2.2 机器学习模型基础](#2.2 机器学习模型基础)
- [三、Java 大数据机器学习模型在游戏用户行为分析中的应用](#三、Java 大数据机器学习模型在游戏用户行为分析中的应用)
-
- [3.1 数据采集与预处理](#3.1 数据采集与预处理)
- [3.2 用户行为分析模型构建](#3.2 用户行为分析模型构建)
- [四、Java 大数据机器学习模型在游戏平衡优化中的应用](#四、Java 大数据机器学习模型在游戏平衡优化中的应用)
-
- [4.1 游戏内数值平衡优化](#4.1 游戏内数值平衡优化)
- [4.2 付费与免费玩家平衡优化](#4.2 付费与免费玩家平衡优化)
-
- 结束语
- 🗳️参与投票和联系我:
引言
嘿,亲爱的 Java 和 大数据爱好者们,大家好!我是CSDN(全区域)四榜榜首青云交!在技术发展的广袤天地里,我们已一同见证 Java 大数据在众多领域闪耀光芒。
如今,从智慧养老服务需求分析,到舆情分析的情感倾向判断;从工业自动化生产线质量检测,到影视内容推荐与用户兴趣挖掘;从智能建筑能耗监测,到电商高并发场景下的性能优化,再到智慧水利水资源调度与水情预测,Java 大数据均发挥着关键作用。如今,游戏行业蓬勃发展,用户对游戏体验要求日益严苛,游戏平衡成为决定游戏成败的核心要素。Java 大数据机器学习模型凭借卓越的数据处理与分析能力,为游戏用户行为分析及游戏平衡优化带来全新契机,接下来,让我们深入探索其在游戏领域的精彩应用。

正文
一、游戏行业现状与挑战
1.1 行业现状
当下,游戏行业正处于迅猛发展的黄金时期。随着智能手机、高性能电脑等设备的普及,游戏用户群体呈现爆发式增长,横跨各个年龄段与社会阶层。据知名市场调研机构 Statista 数据显示,截至 2024 年末,全球游戏玩家数量已突破 35 亿大关,游戏市场规模持续扩张,仅 2024 年全球游戏市场收入便高达 2500 亿美元。各类游戏百花齐放,休闲类游戏如《糖果传奇》,以其简单易上手的玩法吸引了海量玩家,月活跃用户数达数亿之多;大型多人在线角色扮演游戏(MMORPG)《最终幻想》系列,凭借精美的画面、丰富的剧情,拥有庞大且忠实的玩家群体;竞技类游戏《DOTA2》,全球范围内的赛事吸引着无数电竞爱好者关注,其每年的赛事奖金池高达数千万美元。同时,游戏的社交属性愈发凸显,玩家通过游戏内语音、社交平台分享等方式紧密相连,形成了活跃的游戏社区,例如《我的世界》玩家在游戏外的论坛、社交媒体上分享创意建筑作品、游戏攻略,极大地增强了玩家间的互动与粘性。
1.2 面临挑战
然而,繁荣背后也暗藏诸多挑战。游戏平衡问题尤为突出,不同玩家在游戏技巧、投入时间及消费能力上差异巨大。在部分竞技类付费游戏中,付费玩家可凭借购买强力装备或道具,轻易战胜免费玩家,破坏了游戏公平性。以某热门射击手游为例,付费玩家购买高等级武器后,在游戏中的击杀效率提升了 50%,导致免费玩家的游戏胜率大幅下降,部分玩家因体验不佳选择弃玩,该游戏在一个月内流失了约 10% 的免费玩家用户。此外,随着游戏内容不断丰富更新,海量用户行为数据的处理与分析成为难题。传统数据分析手段难以从繁杂数据中精准提取有价值信息,无法及时洞察游戏平衡问题及玩家潜在需求,急需更先进的技术助力游戏开发者优化游戏体验。
二、Java 大数据机器学习模型技术支撑
2.1 大数据存储与管理
游戏运行过程中,会产生海量用户行为数据,如玩家登录登出时间、操作记录、付费信息等。Java 生态系统为高效存储与管理这些数据提供了坚实工具。
Hadoop 分布式文件系统(HDFS)采用分布式存储架构,将数据分散存储于多个节点,提升了数据可靠性与访问速度。以下是使用 Java 代码向 HDFS 上传游戏用户行为日志数据的详细示例:
java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
public class HDFSDataUpload {
public static void main(String[] args) {
// 创建Hadoop配置对象,用于加载Hadoop相关配置参数
Configuration conf = new Configuration();
try {
// 通过配置对象获取HDFS文件系统实例,以便后续操作HDFS
FileSystem fs = FileSystem.get(conf);
// 定义本地文件路径,这里假设为游戏用户行为日志文件路径
Path localFilePath = new Path("/local/path/to/user_behavior_log.txt");
// 定义HDFS目标路径,指定数据要上传到HDFS的具体位置
Path hdfsFilePath = new Path("/hdfs/path/to/user_behavior_log.txt");
// 将本地文件复制到HDFS指定路径,实现数据上传
fs.copyFromLocalFile(localFilePath, hdfsFilePath);
System.out.println("Data uploaded to HDFS successfully.");
// 操作完成后关闭文件系统连接,释放资源
fs.close();
} catch (IOException e) {
// 捕获并打印上传过程中可能出现的I/O异常信息,便于调试与问题排查
System.err.println("Error uploading data to HDFS: " + e.getMessage());
e.printStackTrace();
}
}
}Hive 作为基于 Hadoop 的数据仓库工具,通过类似 SQL 的 HiveQL 语句,方便开发者对存储在 HDFS 中的数据进行查询、分析。例如,统计某款游戏在 2024 年 1 月 1 日至 1 月 31 日期间的活跃用户数量,可编写如下 HiveQL 查询语句:
sql
-- 统计特定时间段内的活跃用户数量
SELECT COUNT(DISTINCT user_id) AS active_user_count
FROM game_user_behavior
WHERE timestamp BETWEEN '2024-01-01' AND '2024-01-31';通过该语句,可快速从存储在 Hive 中的游戏用户行为数据中筛选出目标时间段的数据,并统计出活跃用户数,为游戏运营决策提供数据支持。
2.2 机器学习模型基础
机器学习模型是洞察游戏用户行为、优化游戏平衡的核心利器。以决策树模型为例,它能依据多个特征对游戏用户进行分类或预测。在游戏场景中,可利用决策树模型判断玩家付费倾向。假设我们收集了玩家游戏时长、登录频率、历史消费金额等特征数据,以下是使用 Python 的 Scikit - learn 库构建决策树分类模型的代码示例:
python
from sklearn.tree import DecisionTreeClassifier
import pandas as pd
# 假设df是包含玩家特征和是否付费标签的数据集,从CSV文件读取数据
df = pd.read_csv('game_user_data.csv')
# 提取用于训练模型的特征列,这里选取游戏时长、登录频率、历史消费金额
X = df[['game_play_time', 'login_frequency', 'historical_spending']]
# 提取标签列,即玩家是否付费
y = df['is_paying_user']
# 创建决策树分类器实例,设置random_state为0保证每次运行结果一致
dtc = DecisionTreeClassifier(random_state = 0)
# 使用训练数据对决策树模型进行训练
dtc.fit(X, y)在 Java 中,可借助 Java - ML 库实现类似功能,代码示例如下:
java
import net.sf.javaml.classification.DecisionTree;
import net.sf.javaml.core.Dataset;
import net.sf.javaml.core.DefaultDataset;
import net.sf.javaml.tools.data.FileHandler;
import java.io.File;
import java.util.List;
public class JavaMLDecisionTreeExample {
public static void main(String[] args) {
try {
// 从CSV文件读取数据,创建数据集对象,4表示数据集中特征数量,","为分隔符
Dataset data = FileHandler.loadDataset(new File("game_user_data.csv"), 4, ",");
// 创建决策树分类器实例
DecisionTree dt = new DecisionTree();
// 使用数据集训练决策树模型
dt.buildClassifier(data);
// 假设要预测的数据,创建一个新的数据集对象
Dataset newData = new DefaultDataset();
// 添加一个新的数据点,包含游戏时长100小时,登录频率5次/周,历史消费金额200元
newData.add(new double[]{100, 5, 200});
// 使用训练好的决策树模型对新数据进行分类预测
List<Object> predictions = dt.classify(newData);
System.out.println("Prediction: " + predictions.get(0));
} catch (Exception e) {
// 捕获并打印模型构建或预测过程中可能出现的异常信息
e.printStackTrace();
}
}
}通过构建此类模型,游戏开发者能够明确哪些因素对玩家付费行为影响显著,进而针对性地优化游戏付费策略,提升游戏收益。例如,若模型显示游戏时长与付费倾向高度相关,开发者可设计延长玩家游戏时长的玩法,如增加游戏剧情深度、推出更多有趣任务,从而提升玩家付费可能性。
三、Java 大数据机器学习模型在游戏用户行为分析中的应用
3.1 数据采集与预处理
游戏用户行为数据来源广泛,游戏客户端可详细记录玩家每次操作,如点击屏幕坐标、移动方向、技能释放顺序等;服务器端则记录玩家登录登出时间、游戏进度、交易记录等关键信息;玩家在游戏社区的互动数据,如聊天内容、论坛发帖、点赞评论等,也蕴含着丰富信息。通过 Java 编写的数据采集程序,可将这些分散数据汇聚至统一存储平台。例如,利用 Java 的 Socket 编程实现游戏客户端与服务器实时数据传输,确保数据及时、完整。以下是一个简单的 Socket 数据传输示例(仅为示意,实际应用需更复杂的逻辑与安全机制):
java
// 客户端代码示例
import java.io.IOException;
import java.io.OutputStream;
import java.net.Socket;
public class GameClientDataSender {
public static void main(String[] args) {
try {
// 创建Socket对象,连接到服务器指定IP与端口
Socket socket = new Socket("192.168.1.100", 8080);
// 获取输出流,用于向服务器发送数据
OutputStream os = socket.getOutputStream();
// 假设要发送的游戏用户行为数据
String userBehaviorData = "Player clicked at (100, 200)";
// 将数据转换为字节数组并发送
os.write(userBehaviorData.getBytes());
// 关闭输出流与Socket连接
os.close();
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
// 服务器端代码示例
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.ServerSocket;
import java.net.Socket;
public class GameServerDataReceiver {
public static void main(String[] args) {
try {
// 创建ServerSocket对象,监听指定端口
ServerSocket serverSocket = new ServerSocket(8080);
// 等待客户端连接
Socket clientSocket = serverSocket.accept();
// 获取输入流,用于接收客户端发送的数据
BufferedReader br = new BufferedReader(new InputStreamReader(clientSocket.getInputStream()));
// 读取客户端发送的数据
String receivedData = br.readLine();
System.out.println("Received data: " + receivedData);
// 关闭输入流、客户端Socket与ServerSocket
br.close();
clientSocket.close();
serverSocket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}采集到的数据常包含噪声、缺失值与异常值,需进行预处理。利用 Java 的 Spark 大数据处理框架,可高效清洗与转换数据。以下是使用 Spark 清洗玩家游戏时长数据的代码示例,去除游戏时长为负数或超过 10000 小时的异常值:
java
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class GameDataCleaning {
public static void main(String[] args) {
// 创建SparkSession对象,用于启动Spark应用并连接到Spark集群
SparkSession spark = SparkSession.builder()
.appName("GameDataCleaning")
.master("local[*]")
.getOrCreate();
// 从CSV文件读取游戏用户数据,设置文件格式为CSV且包含表头
Dataset<Row> gameData = spark.read()
.format("csv")
.option("header", "true")
.load("game_user_data.csv");
// 过滤掉游戏时长为负数或超过10000小时的异常记录
Dataset<Row> cleanedData = gameData.filter("game_play_time >= 0 AND game_play_time <= 10000");
// 展示清洗后的数据,便于查看清洗效果
cleanedData.show();
// 停止SparkSession,释放资源
spark.stop();
}
}经过预处理的数据,为后续精准用户行为分析筑牢基础。
3.2 用户行为分析模型构建
基于预处理后的数据,可构建多种用户行为分析模型。以聚类分析模型 K - Means 为例,其能将行为模式相似的玩家聚为一组,助力游戏开发者识别不同类型玩家群体。以下是使用 Java 的 Apache Commons Math 库实现 K - Means 聚类分析的详细代码:
java
import org.apache.commons.math3.ml.clustering.Cluster;
import org.apache.commons.math3.ml.clustering.DoublePoint;
import org.apache.commons.math3.ml.clustering.KMeansPlusPlusClusterer;
import java.util.ArrayList;
import java.util.List;
public class GameUserClustering {
public static void main(String[] args) {
// 模拟游戏用户数据,每个数据点包含游戏时长和登录频率
List<DoublePoint> dataPoints = new ArrayList<>();
dataPoints.add(new DoublePoint(new double[]{100, 5}));
dataPoints.add(new DoublePoint(new double[]{200, 8}));
dataPoints.add(new DoublePoint(new double[]{300, 10}));
dataPoints.add(new DoublePoint(new double[]{50, 2}));
dataPoints.add(new DoublePoint(new double[]{150, 6}));
// 创建K - Means聚类器,设置聚类数为3,使用欧几里得距离衡量数据点间相似度
KMeansPlusPlusClusterer<DoublePoint> clusterer = new KMeansPlusPlusClusterer<>(3, new EuclideanDistance());
// 对数据点进行聚类分析
List<Cluster<DoublePoint>> clusters = clusterer.cluster(dataPoints);
// 输出聚类结果
for (int i = 0; i < clusters.size(); i++) {
System.out.println("Cluster " + i + ":");
for (DoublePoint point : clusters.get(i).getPoints()) {
System.out.println(" Game play time: " + point.getPoint()[0] + ", Login frequency: " + point.getPoint()[1]);
}
}
}
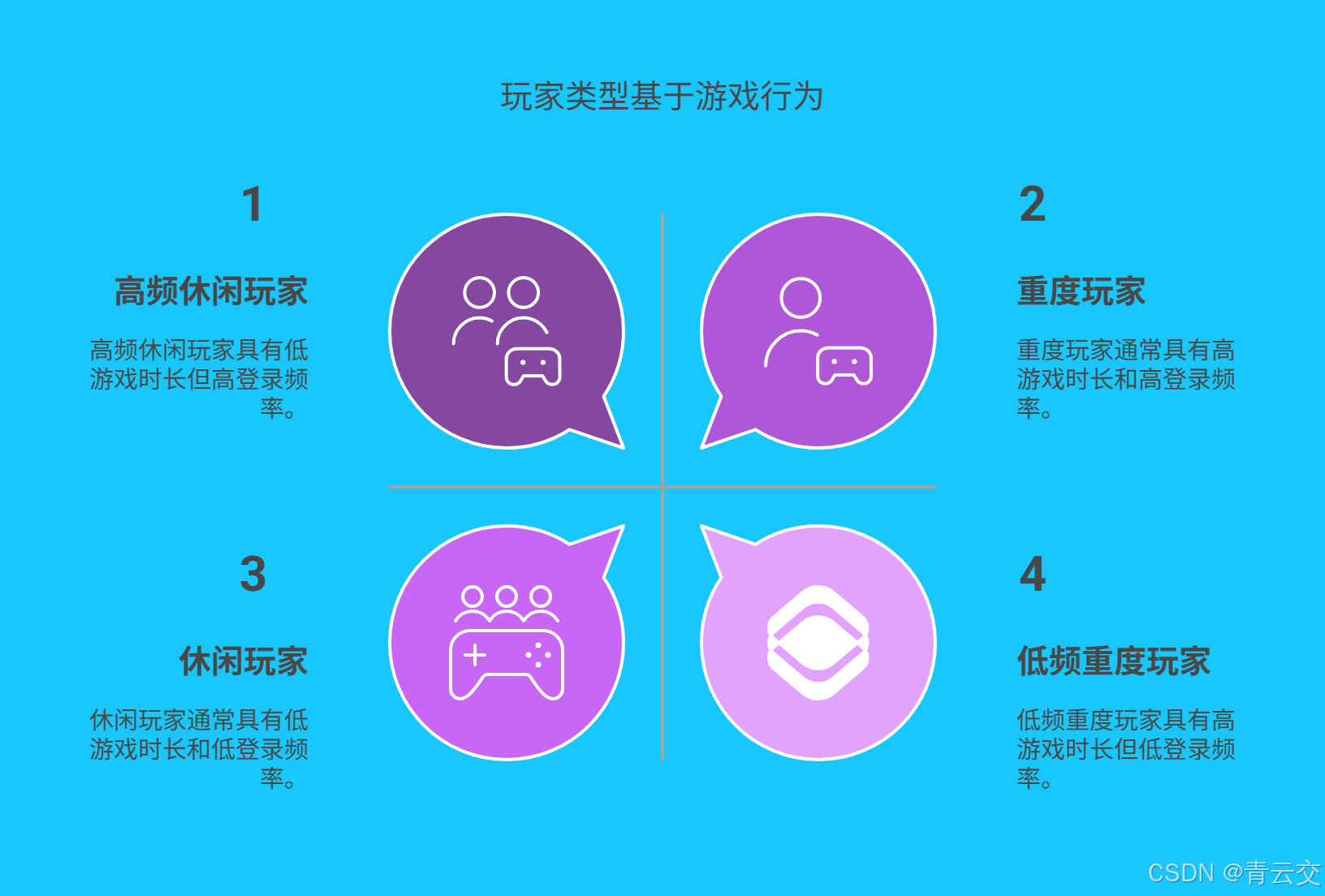
}通过聚类分析,游戏开发者可发现高频短时长的休闲玩家群体,以及低频长时间的重度玩家群体等。针对不同群体,可制定差异化运营策略。对于休闲玩家,可推出更多限时小游戏、简单日常任务,满足其碎片化娱乐需求;对于重度玩家,设计深度剧情拓展、高难度副本挑战,提升其游戏沉浸感与粘性。
四、Java 大数据机器学习模型在游戏平衡优化中的应用
4.1 游戏内数值平衡优化
游戏内数值平衡直接关乎游戏公平性与趣味性。以某热门角色扮演游戏为例,角色的生命值、攻击力、防御力等属性数值设置是否合理,极大影响玩家游戏体验。通过收集大量玩家战斗数据,包括战斗胜负结果、角色属性数值、技能使用情况等,利用线性回归模型可分析各属性对战斗结果的影响程度。以下是使用 Java 的 Apache Commons Math 库构建线性回归模型,分析角色攻击力与战斗胜率关系的代码示例:
java
import org.apache.commons.math3.stat.regression.SimpleRegression;
public class GameBalanceRegression {
public static void main(String[] args) {
// 假设attackValues是角色攻击力数组,winRates是对应的战斗胜率数组
double[] attackValues = {100, 150, 200, 250};
double[] winRates = {0.4, 0.5, 0.6, 0.7};
// 创建简单线性回归对象
SimpleRegression regression = new SimpleRegression();
// 逐个添加数据点用于模型训练
for (int i = 0; i < attackValues.length; i++) {
regression.addData(attackValues[i], winRates[i]);
}
// 获取回归直线的斜率与截距
double slope = regression.getSlope();
double intercept = regression.getIntercept();
System.out.println("斜率:" + slope + ",截距:" + intercept);
// 预测攻击力为300时的战斗胜率
double predictedWinRate = regression.predict(300);
System.out.println("预测攻击力为300时的战斗胜率:" + predictedWinRate);
}
}根据分析结果,游戏开发者能够对角色属性数值进行精准调整。若发现攻击力对战斗胜率影响过大,导致高攻击力角色过于强势,可适当降低攻击力增长幅度。比如原本攻击力每提升 10 点,战斗胜率提升 0.1,经调整后,攻击力每提升 15 点,战斗胜率提升 0.1,同时增加防御力对战斗结果的影响权重,使战斗过程更加平衡。通过这种方式,让不同属性配置的角色在战斗中都有合理的获胜机会,显著提升游戏的公平性和趣味性。
4.2 付费与免费玩家平衡优化
在付费游戏中,平衡付费玩家和免费玩家的游戏体验是维护游戏生态健康发展的关键。借助玩家付费行为数据和游戏内行为数据,利用逻辑回归模型能够精准预测玩家的付费意愿。以下是使用 Python 的 Scikit - learn 库实现逻辑回归预测玩家付费意愿的代码示例:
python
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 读取游戏用户数据,假设数据文件包含玩家游戏行为及付费情况等信息
data = pd.read_csv('game_user_payment_data.csv')
# 提取用于预测的特征列,这里选取游戏时长、登录频率、社交活跃度
X = data[['game_play_time', 'login_frequency','social_activity']]
# 提取标签列,即玩家是否付费
y = data['is_paying_user']
# 将数据集按70%训练集、30%测试集的比例随机划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建逻辑回归模型实例
lr = LogisticRegression()
# 使用训练集数据对逻辑回归模型进行训练
lr.fit(X_train, y_train)
# 使用训练好的模型对测试集数据进行预测
y_pred = lr.predict(X_test)
# 计算模型预测准确率
accuracy = accuracy_score(y_test, y_pred)
print("模型准确率:", accuracy)根据预测结果,游戏开发者可以制定针对性策略来平衡付费与免费玩家体验。对于预测为高付费意愿的玩家,提供专属的高价值付费内容,如稀有的游戏角色皮肤、强力且独特的武器装备,这些内容不仅能满足他们彰显个性和追求强大的需求,还能通过独特性激发他们的付费欲望。对于预测为低付费意愿的玩家,通过游戏内活动引导,如举办限时的免费道具试用活动,让他们体验到付费道具带来的乐趣,或者设置连续登录奖励,逐步提升其参与度和付费可能性。通过这些策略,避免付费玩家在游戏中过度碾压免费玩家,维护游戏的公平竞技环境,确保不同类型玩家都能在游戏中获得良好体验,进而提升游戏的整体口碑和用户粘性。
结束语
亲爱的 Java 和 大数据爱好者们,在本次对 Java 大数据机器学习模型于游戏用户行为分析及游戏平衡优化应用的深度探索中,我们全方位领略了其强大的技术实力与创新魅力。从大数据的存储管理,到机器学习模型的构建与运用,再到在用户行为洞察和游戏平衡优化上的实践,每一个环节都展现出 Java 技术在游戏领域的无限潜力。通过这些先进技术,游戏开发者能够更深入地理解玩家需求,打造出更公平、更具吸引力的游戏体验,推动游戏行业迈向新的高度。
亲爱的 Java 和 大数据爱好者们,在您的游戏项目实践中,是否已经运用 Java 大数据机器学习模型来优化游戏体验?在数据采集、模型构建或应用过程中,您遇到了哪些挑战,又是如何巧妙解决的?欢迎在评论区分享您的宝贵经验与见解。
诚邀各位参与投票,你认为 Java 大数据机器学习在游戏领域未来最具变革性的应用方向是?快来投出你的宝贵一票 。