这篇会写得比较粗糙,但基本操作会讲到(*^-^*)
1.JDBC编程的前置准备
1.1 jdbc的简单介绍
JDBC --java针对不同数据库上的API不同给出的一个解决方案
JDBC本质上是Java标准库提供的一套类/方法,通过这组类/方法,把数据库C的原生API 进行封装,转换成Java版本的,同时也对不同数据库厂商的API进行了风格的统一
1.2 数据库的驱动程序的下载
1)通过 maven 仓库下载
maven仓库可以简单理解为是一个应用商店
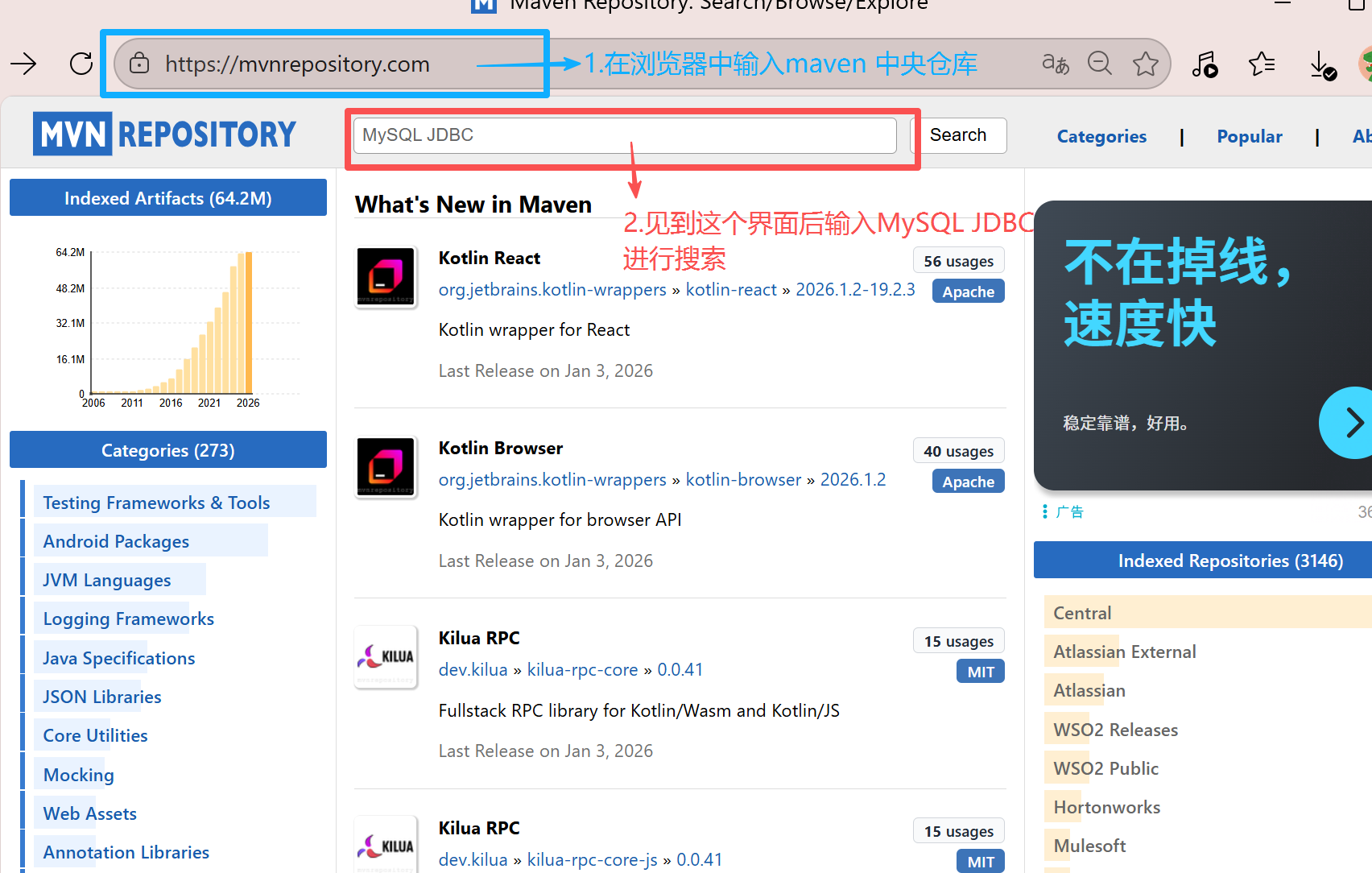
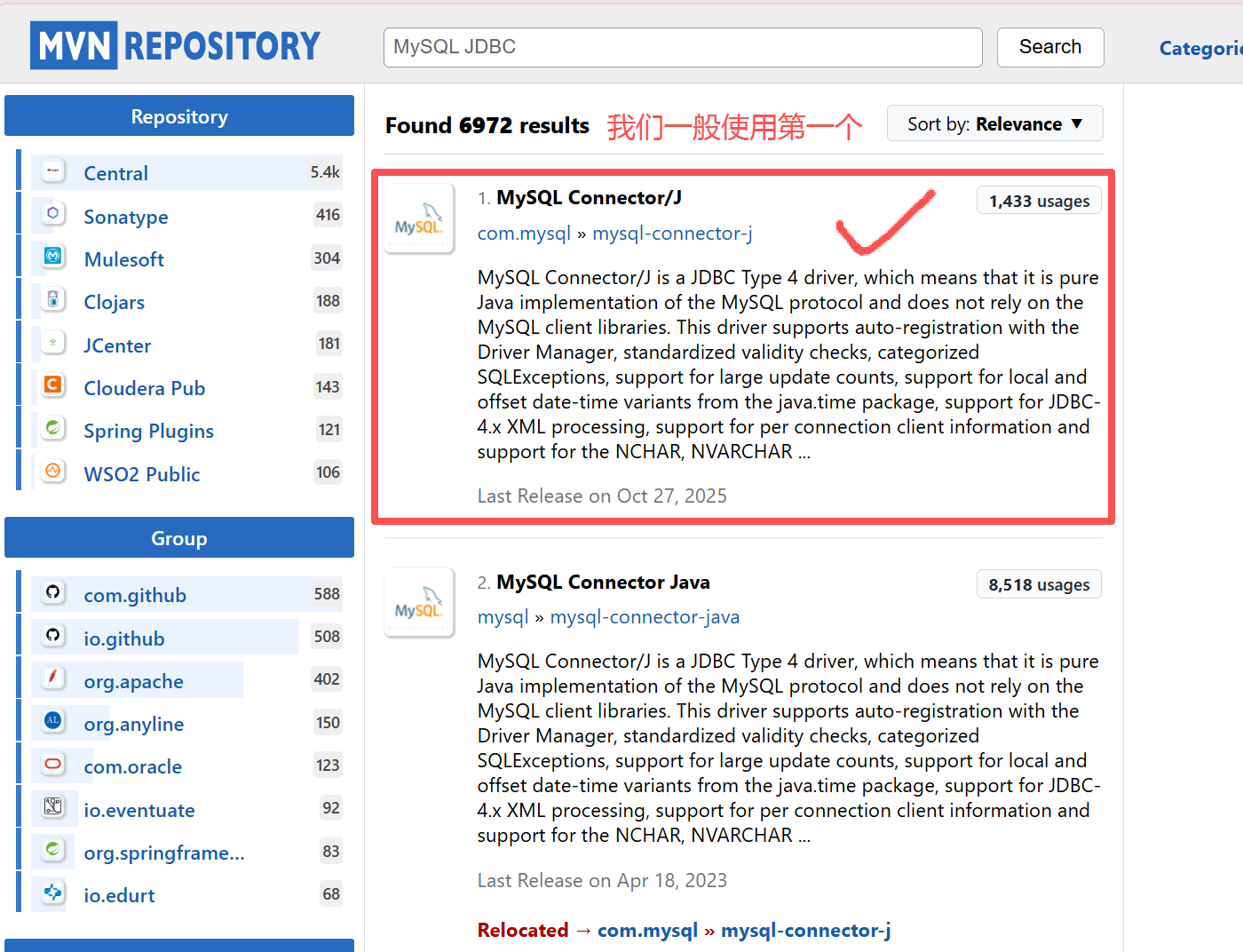
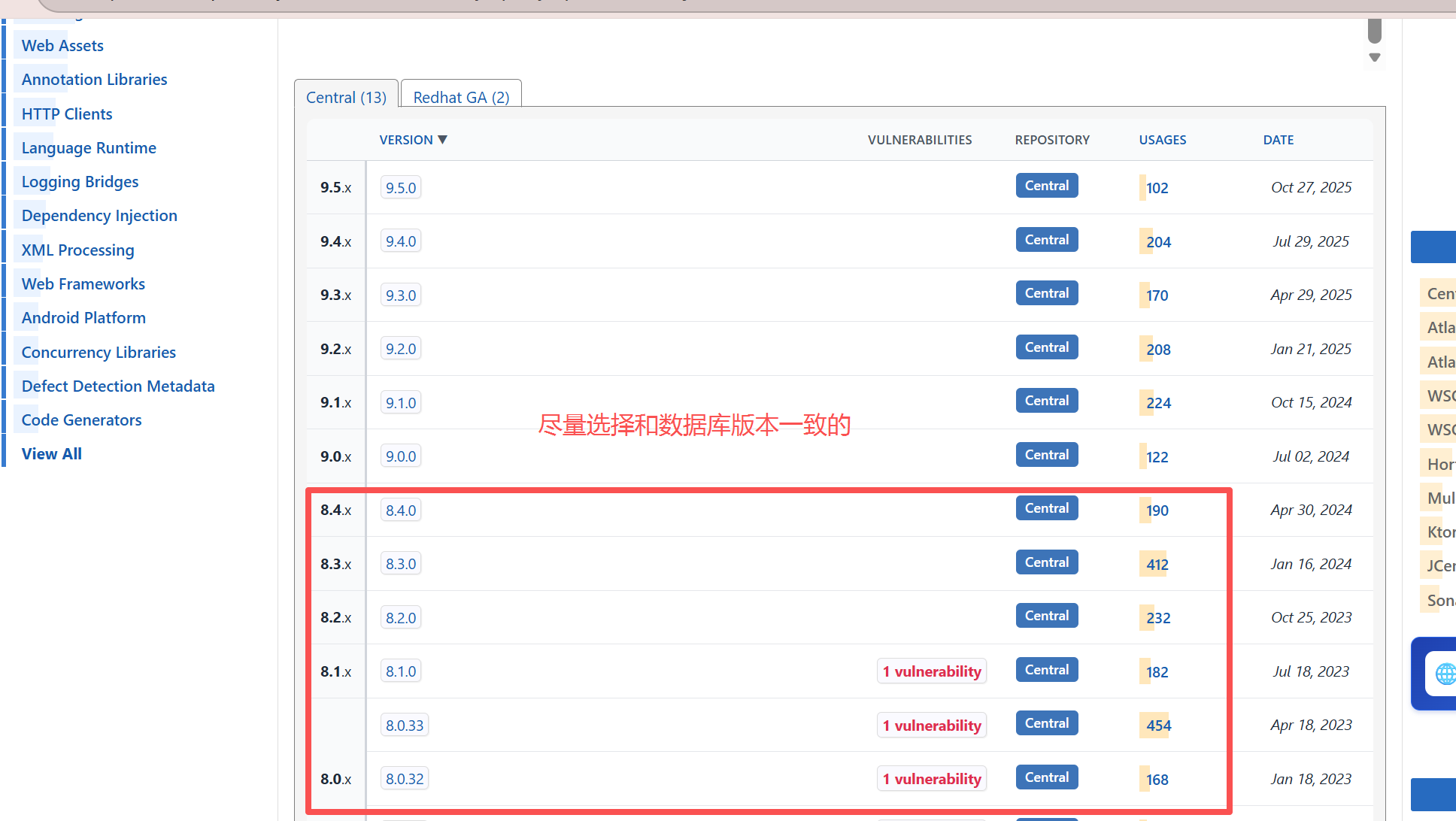
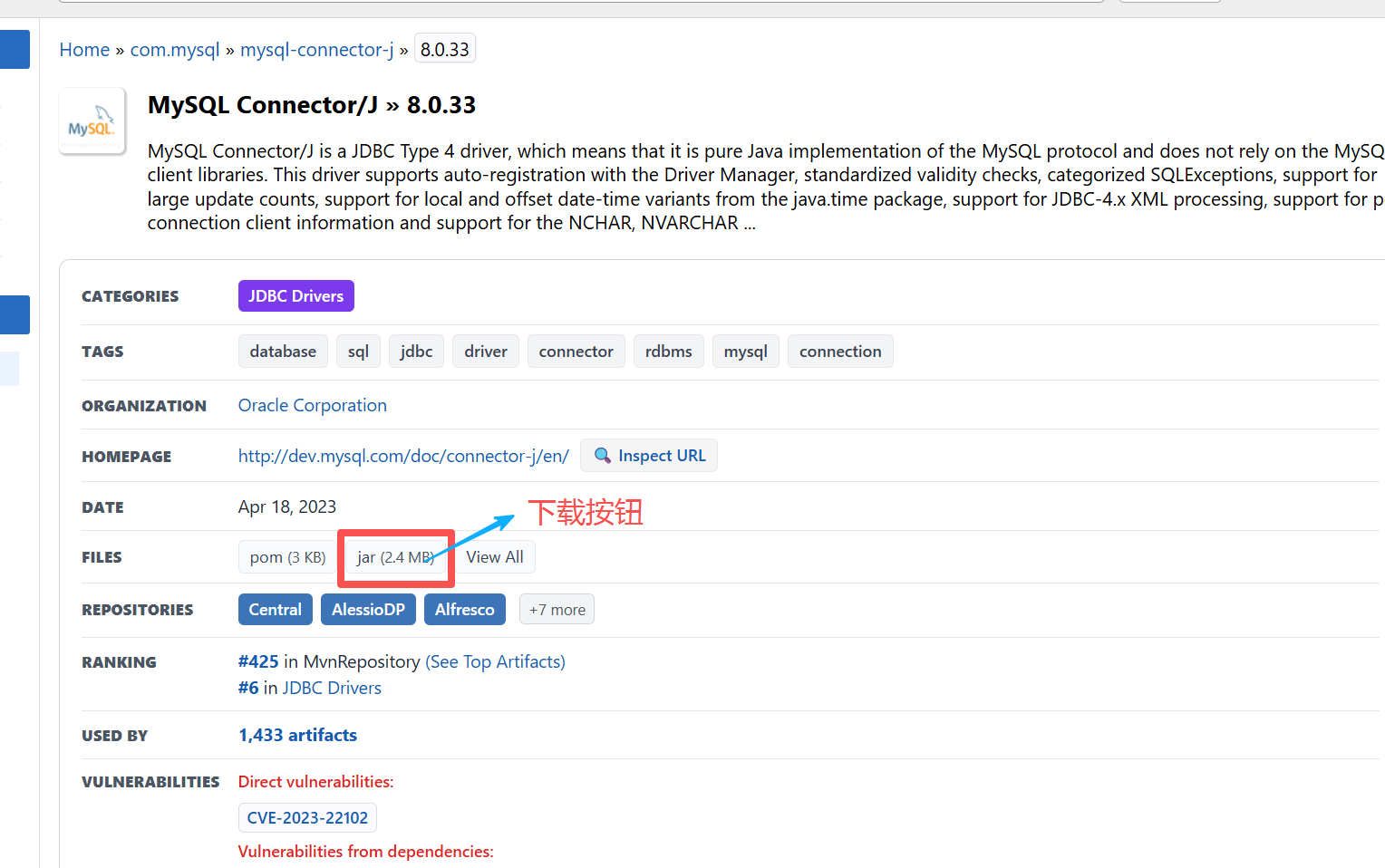

这个jar包当然也可以通过其他方式进行下载,其他方式这里就不介绍了
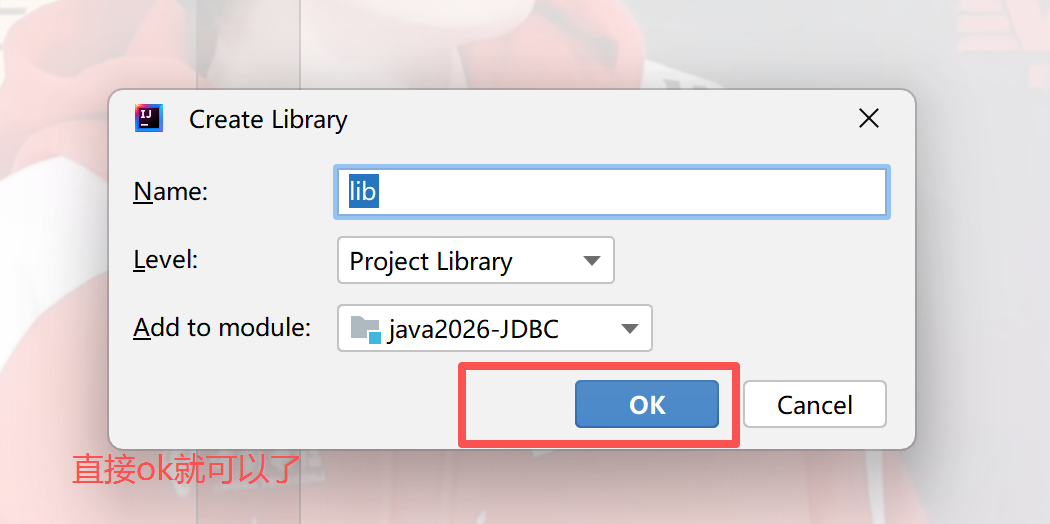
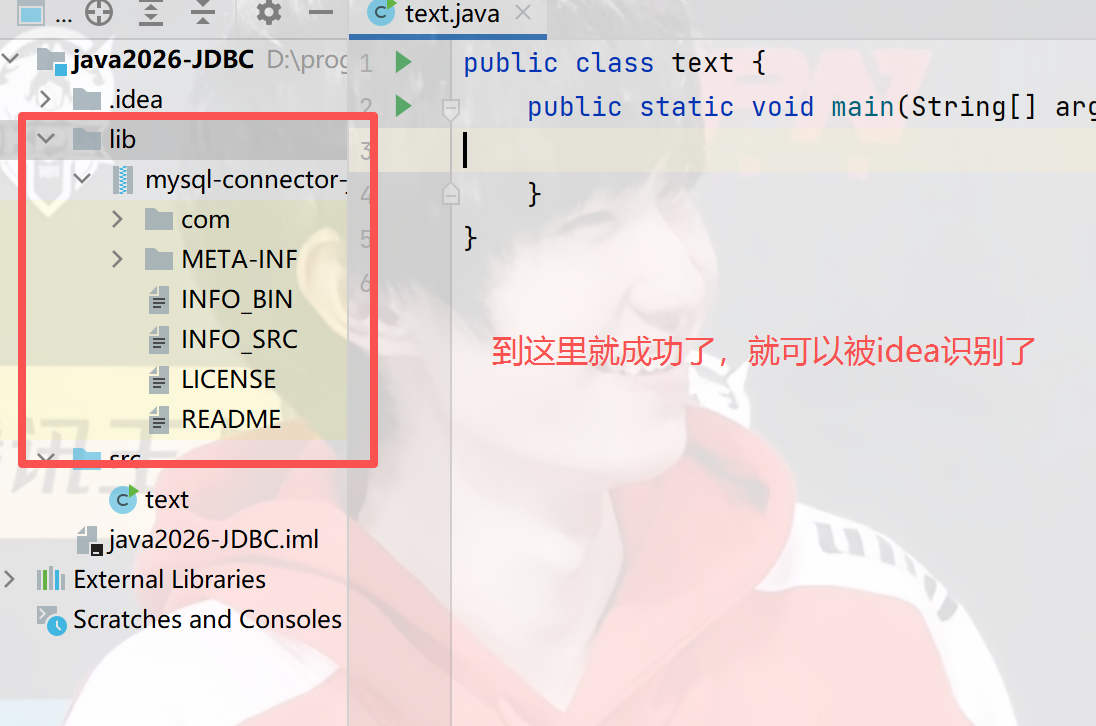
2)在项目中创建一个目录(名字可以随便起,这里叫lib),把这个jar包复制进去
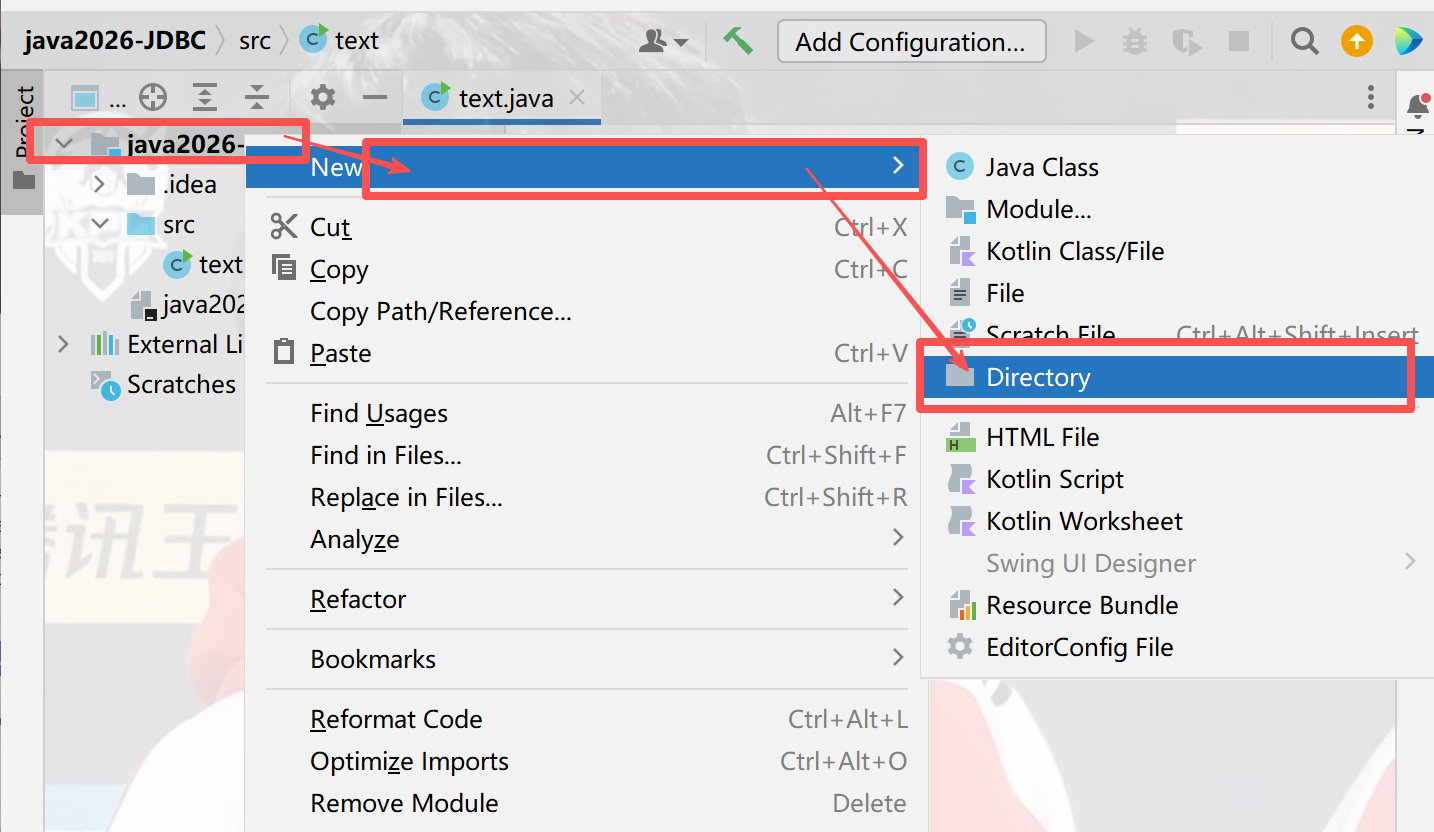
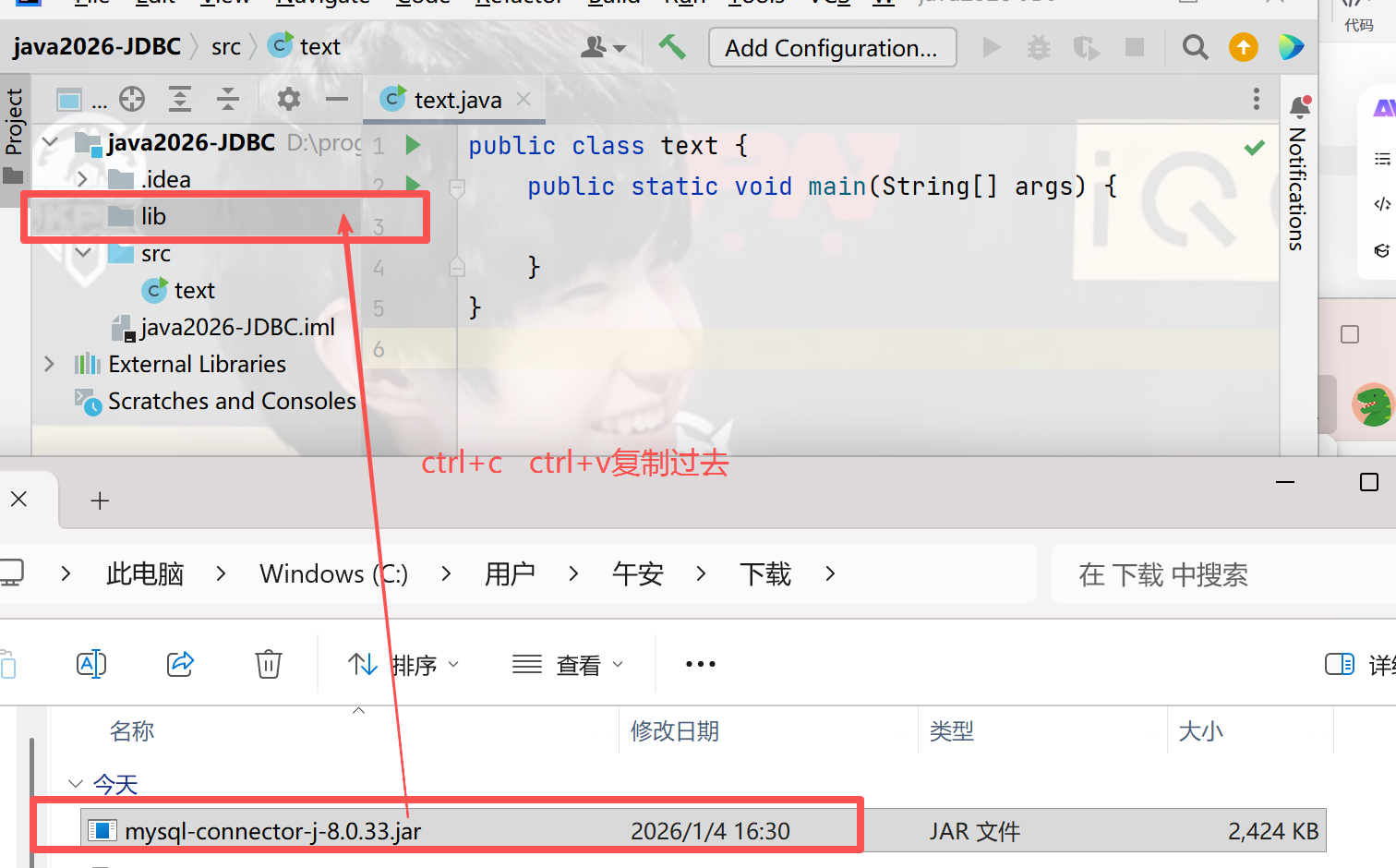
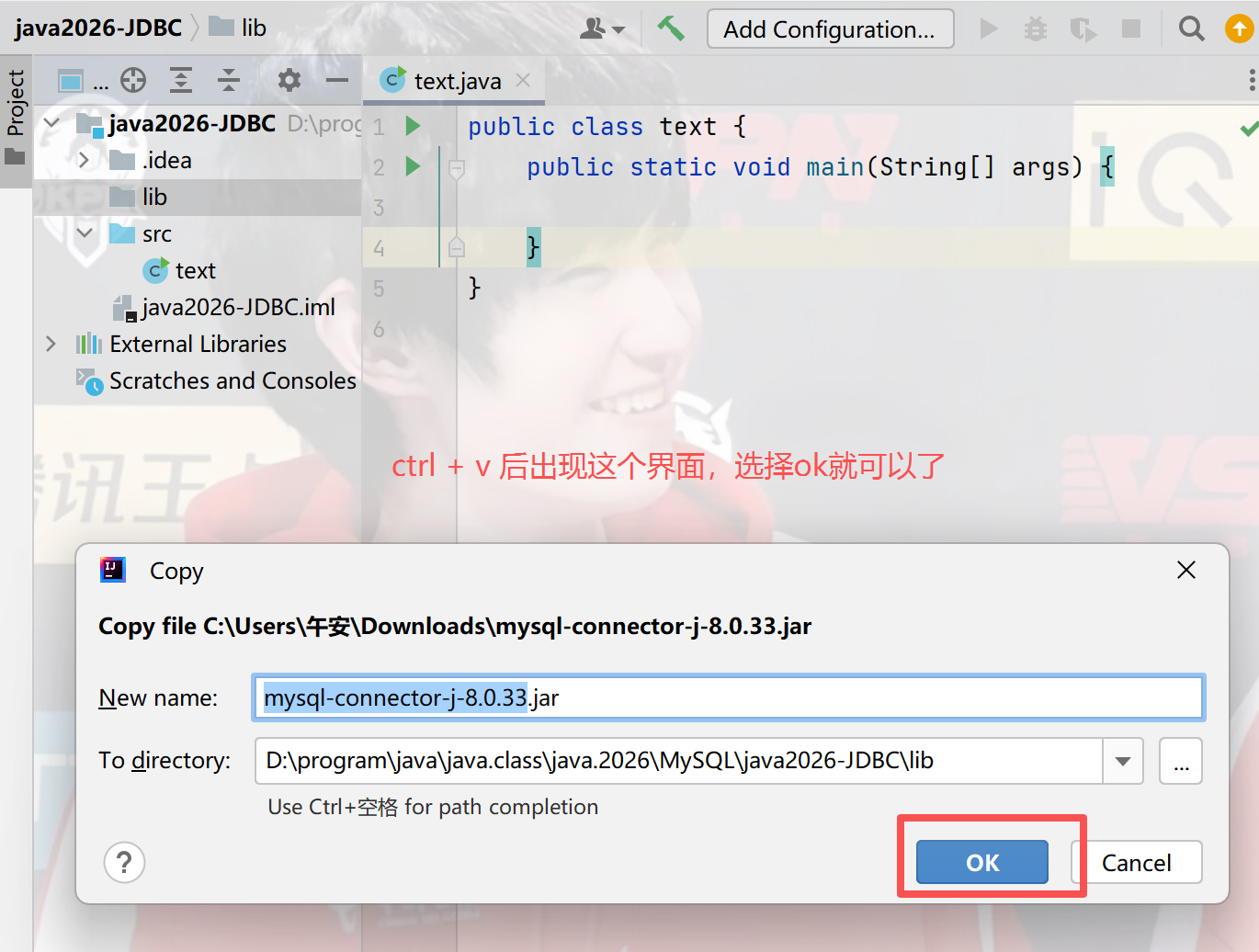
3)让项目能够识别到这个lib
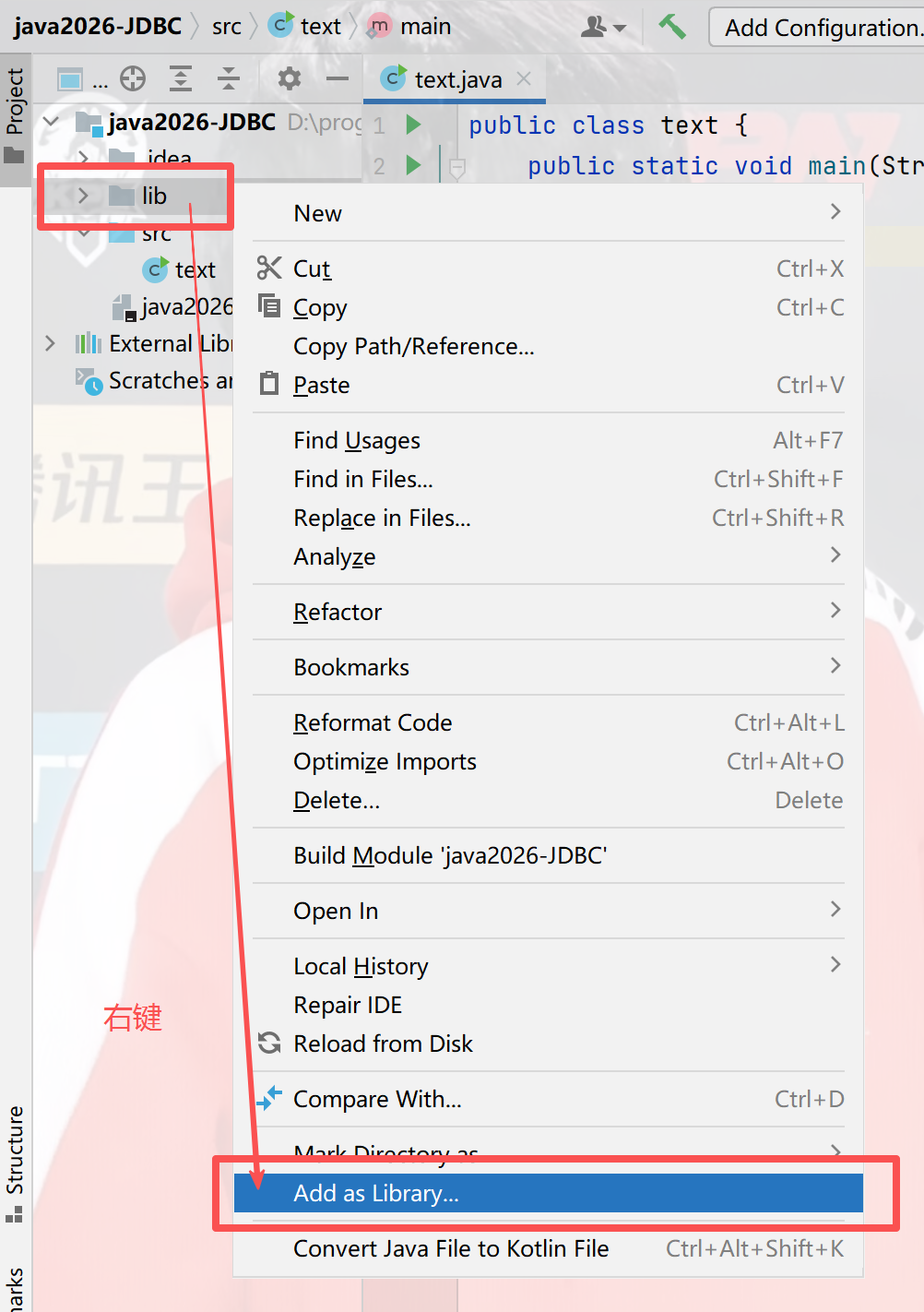
2.JDBC编程
2.1 过程
1)创建数据源(DataSource)对象
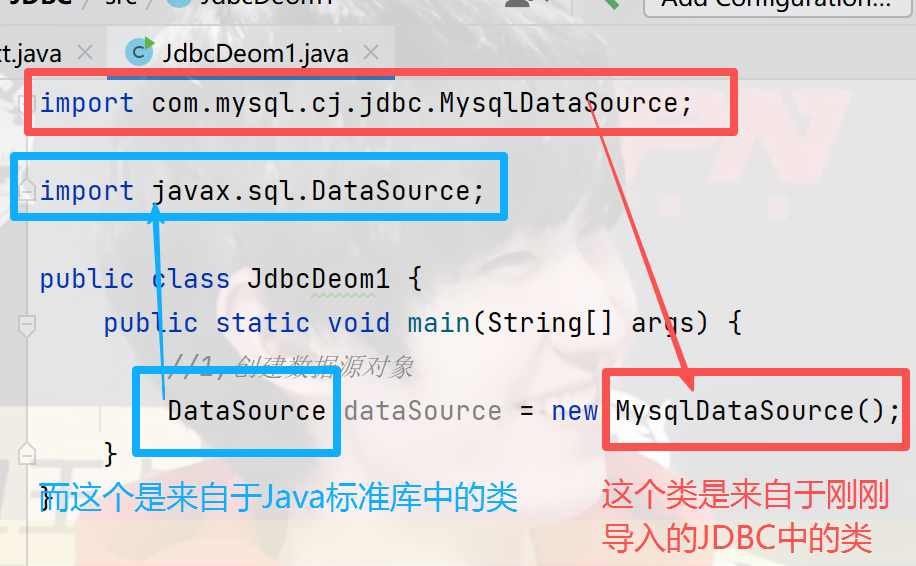
设置属性:
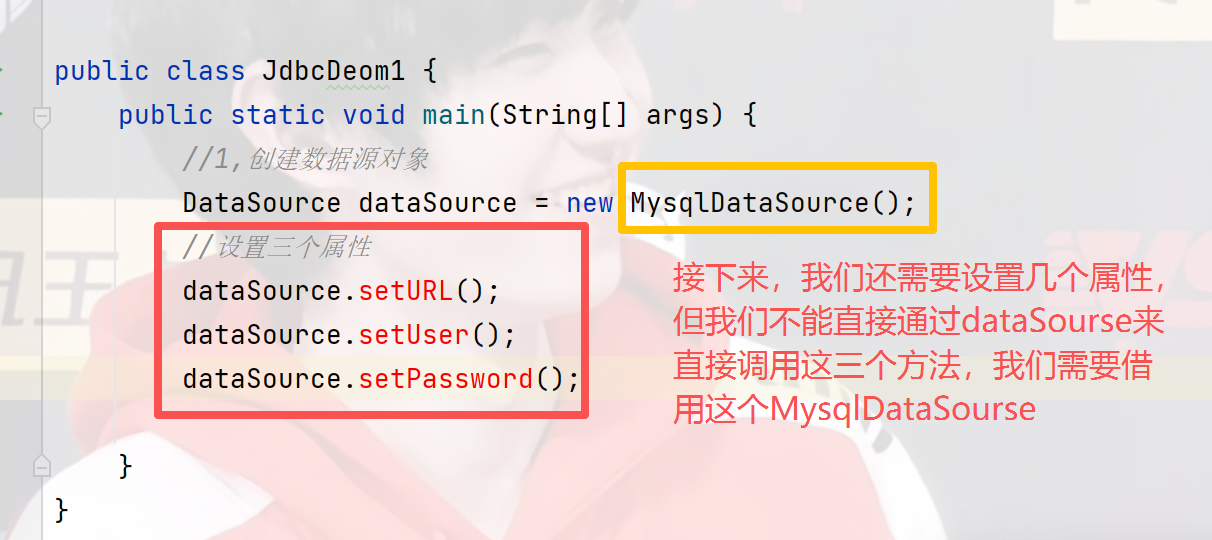
正确调用方法设置属性的格式:
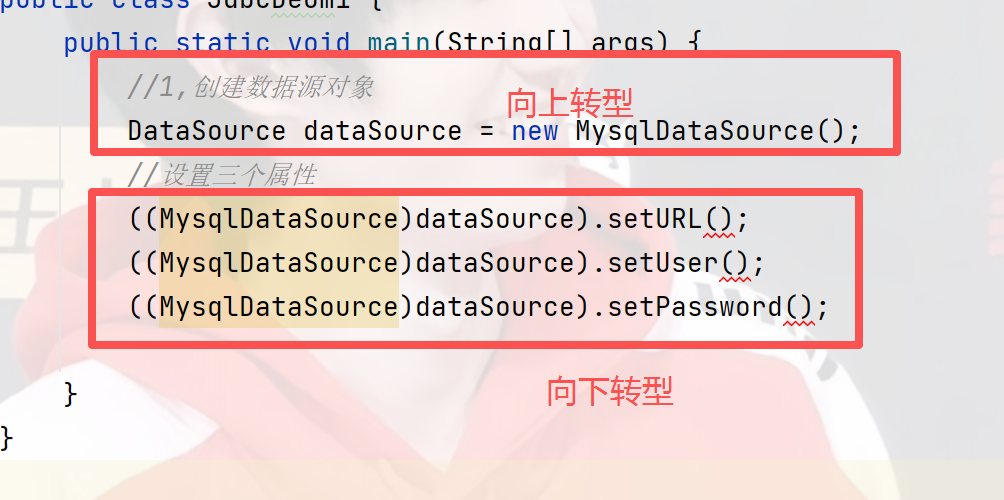
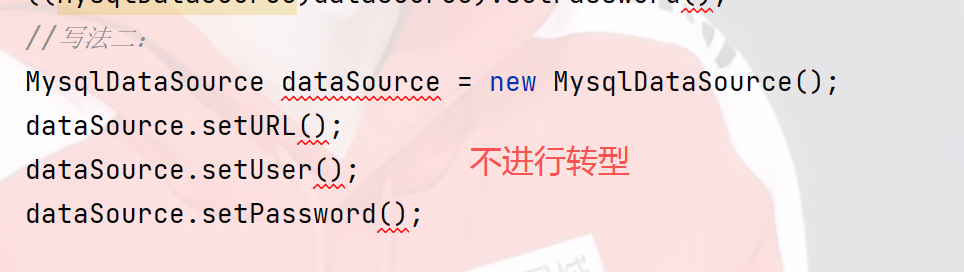
还有一种写法,如果不进行转型也是可以的,但有观点认为使用转型可以降低代码的**耦合性,**我们大概率都使用第一种写法
设置属性参数:
这里面的Url是一个字符串,作用于标识一个网络上的唯一资源地址,下面的Url可以不用背,只需要存一个地方,你需要用的时候能找到就可以了
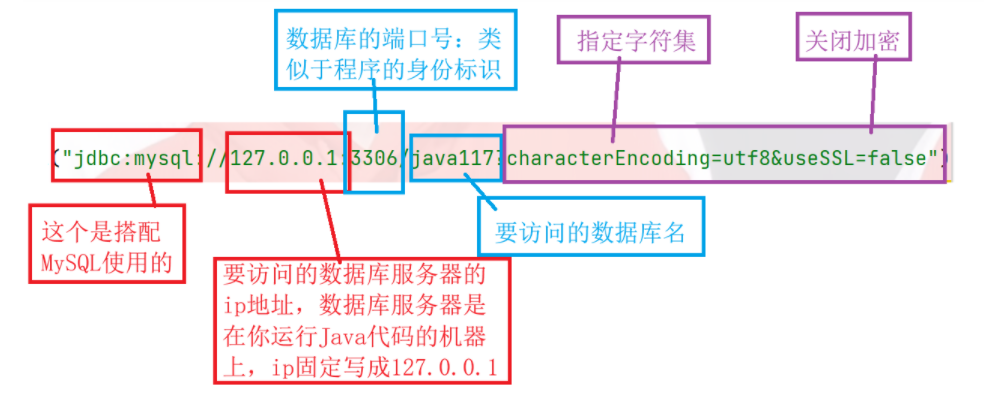
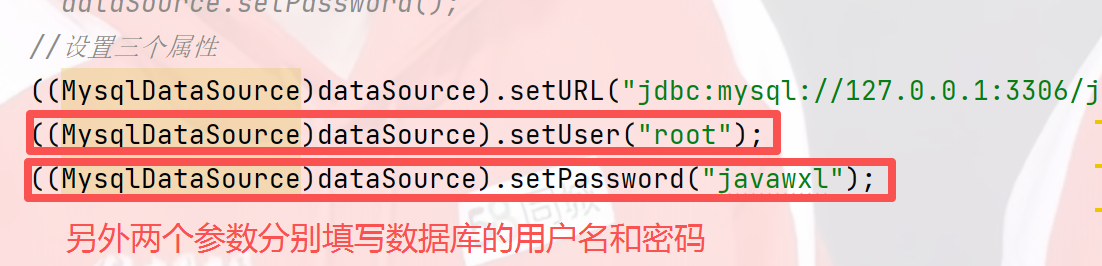
上述所有的setURL()方法更正为setUrl()
2)和数据库服务器进行通信,建立网络连接
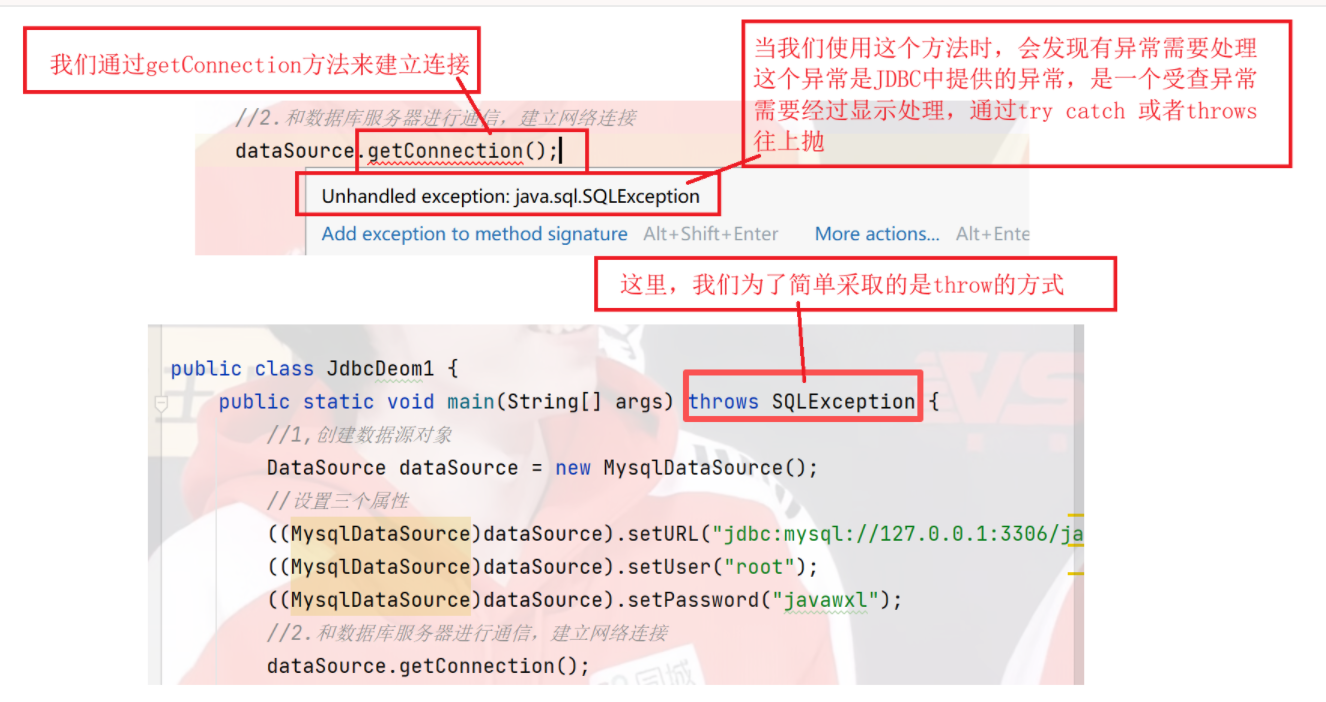
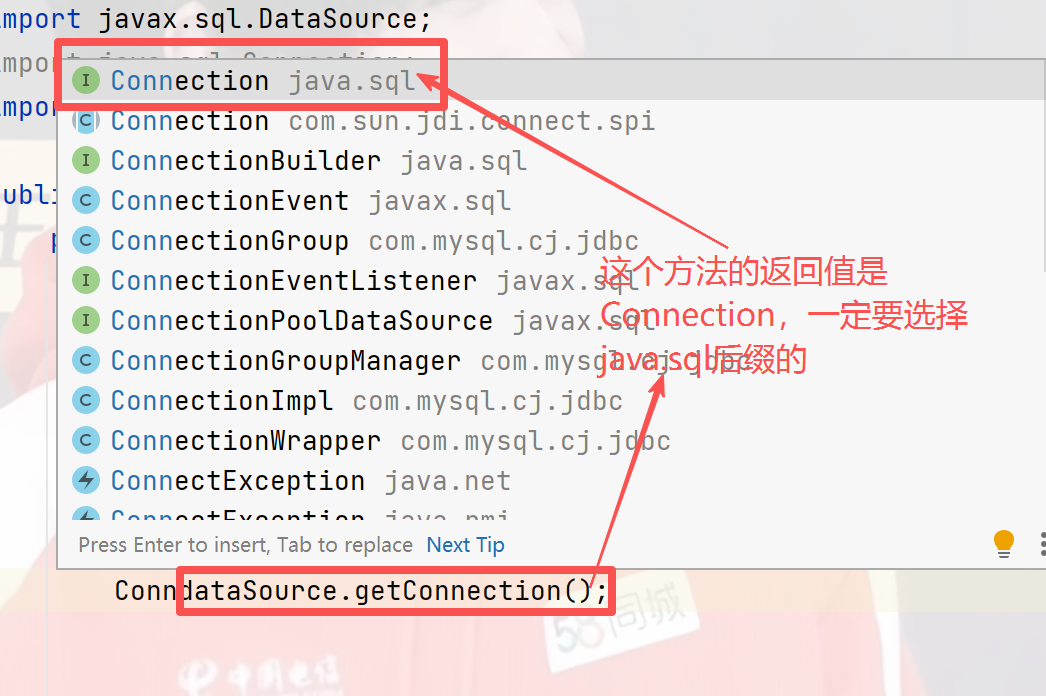
3)构造SQL语句

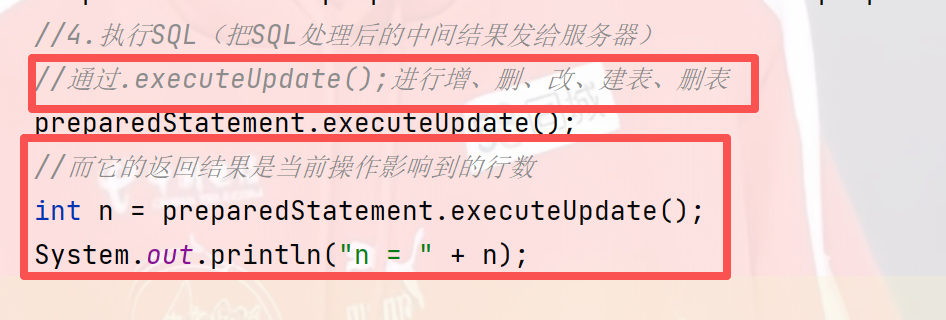
4)执行SQL(把SQL处理后的中间结果发给服务器)
5)资源的释放(关闭连接)
通常情况下,在Java中的内存资源不需要手动释放,Java内置了**" 垃圾回收机制 "** 可以自动回收内存资源,但是这个机制并不是万能的,在有些情况例外,和数据库交互时,此时申请的资源不仅仅是内存的资源,还包括一些和网络通信相关的资源,所以我们还是通过**close()**释放比较好

这里还有一个关注点,这两个的释放先后顺序问题,我们应该遵循先申请 的资源,后释放的规则

6)运行
修改完后,我们尝试进行执行,执行成功后,返回结果我们影响了一行
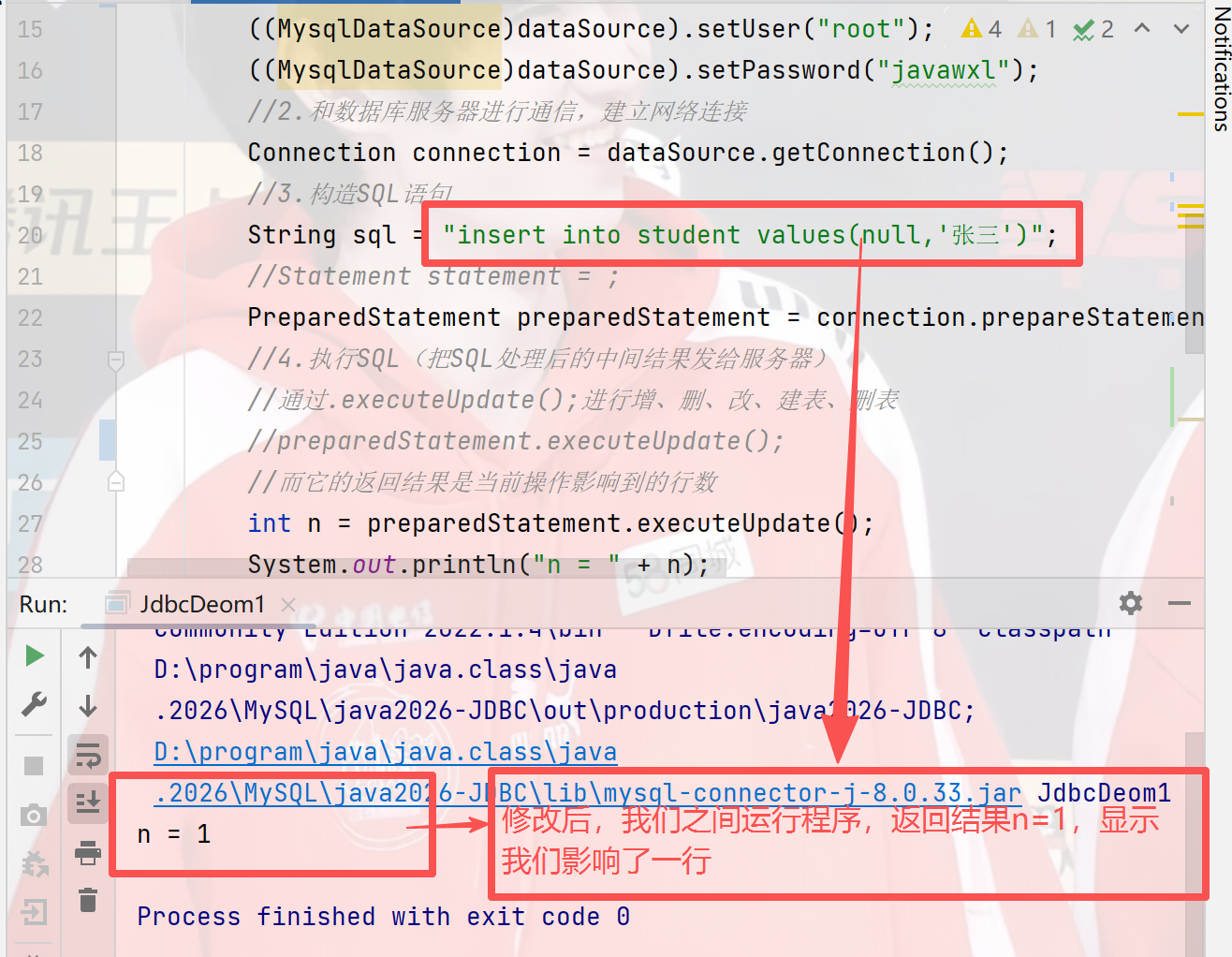
我们可以返回Navicat中查看结果
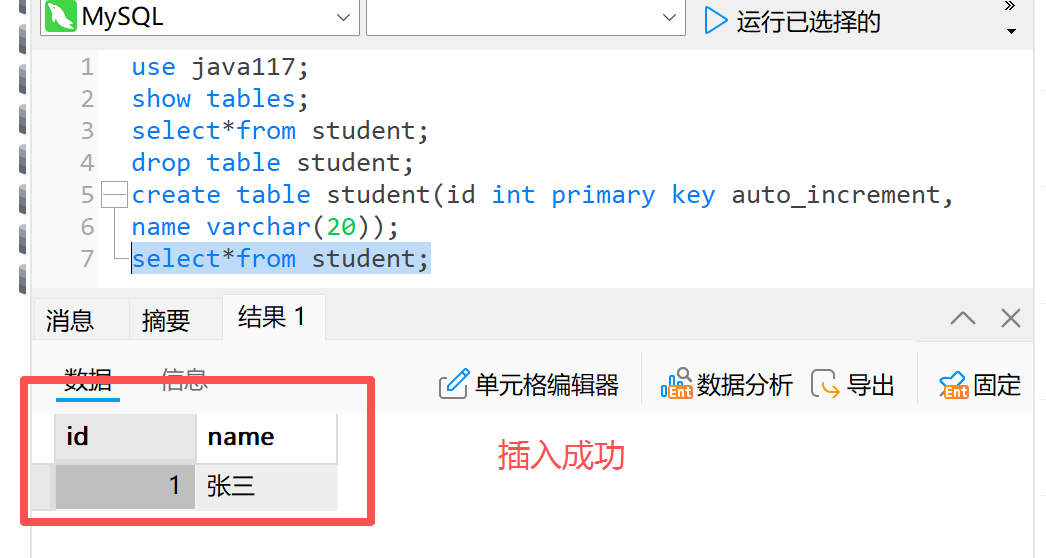
我们不难发现,我们想要其他操作,就要修改一次代码,重新编译,但在现实生活中,我们更希望由用户来输入他们想要的修改操作
7)优化修改操作
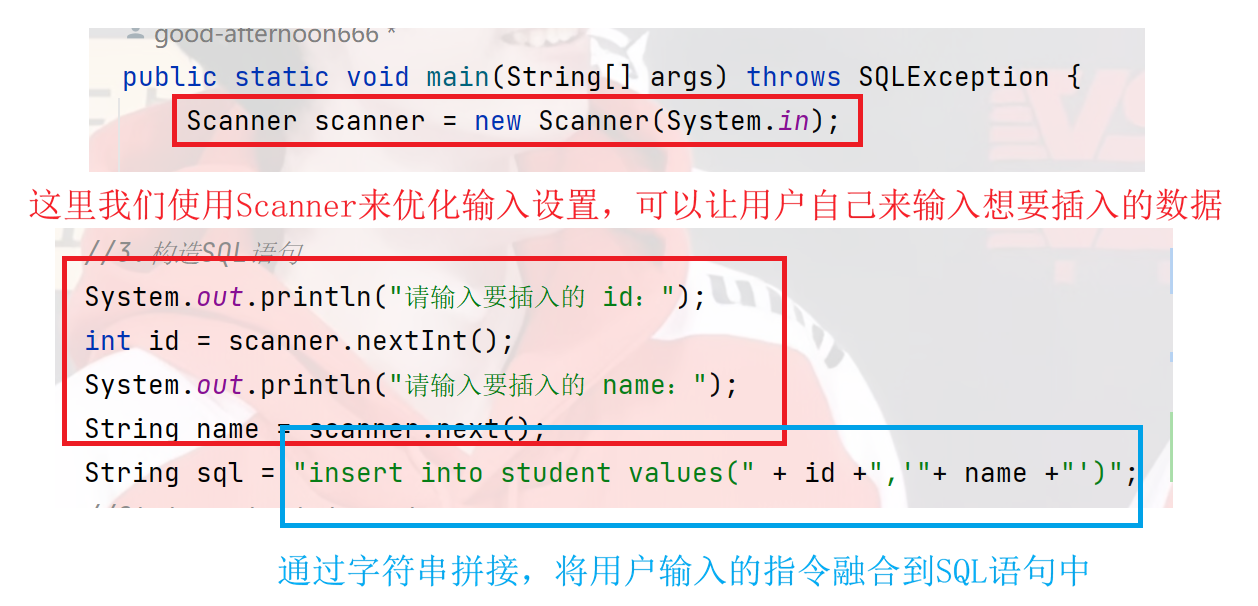

虽然这个代码能解决一些问题,但在字符串拼接部分,我们不难发现,这个代码非常的繁琐,有各种的引号,使用起来非常不方便,为此我们引入了preparedStatement的占位符来帮我们解决这个问题
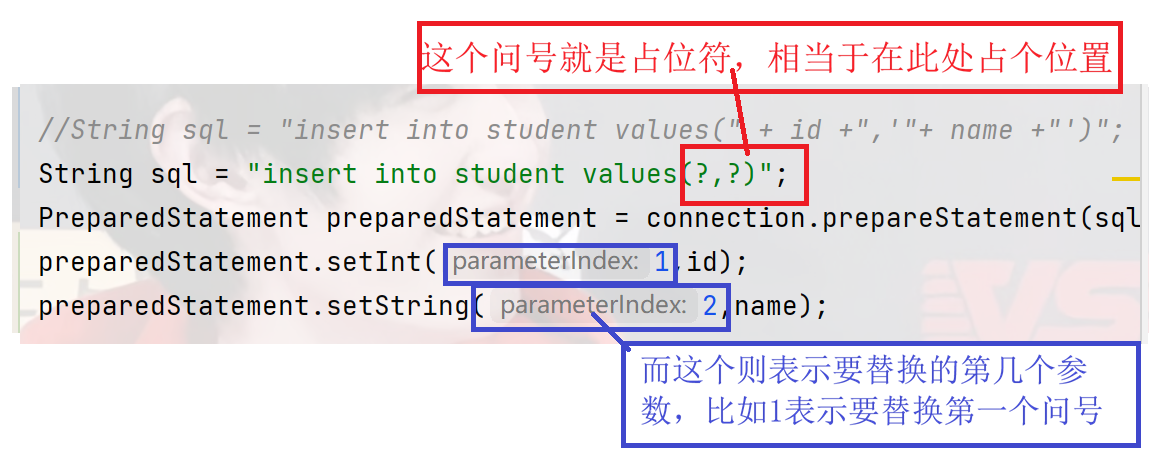
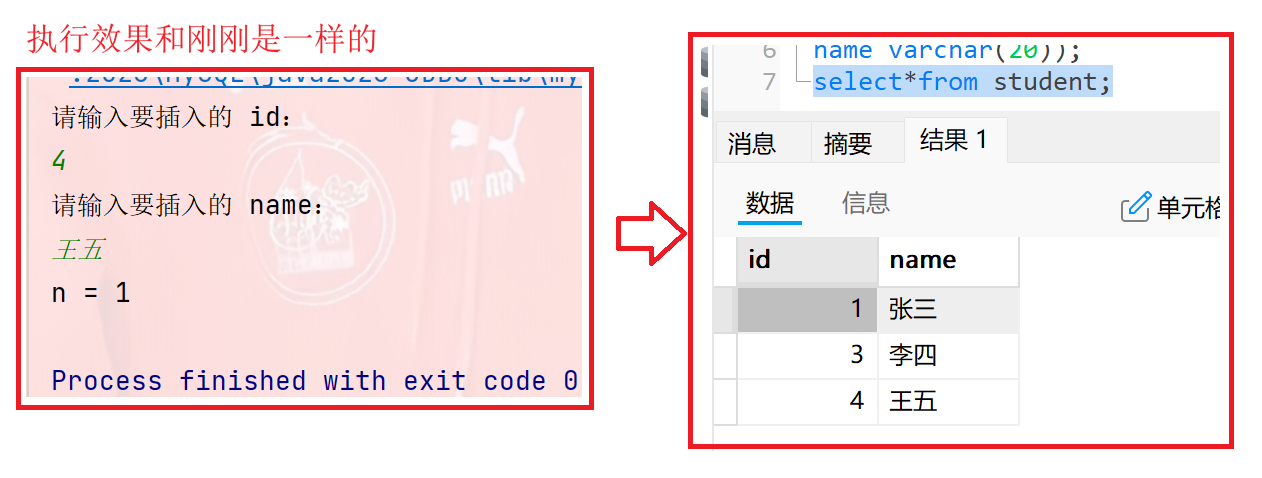
代码示例:
sql
import com.mysql.cj.jdbc.MysqlDataSource;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Scanner;
public class JdbcDeom1 {
public static void main(String[] args) throws SQLException {
Scanner scanner = new Scanner(System.in);
//1,创建数据源(DataSource)对象
DataSource dataSource = new MysqlDataSource();
//设置三个属性
((MysqlDataSource)dataSource).setUrl("jdbc:mysql://127.0.0.1:3306/java117?characterEncoding=utf8&useSSL=false");
((MysqlDataSource)dataSource).setUser("root");
((MysqlDataSource)dataSource).setPassword("javawxl");
//2.和数据库服务器进行通信,建立网络连接
Connection connection = dataSource.getConnection();
//3.构造SQL语句
System.out.println("请输入要插入的 id:");
int id = scanner.nextInt();
System.out.println("请输入要插入的 name:");
String name = scanner.next();
String sql = "insert into student values(?,?)";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
preparedStatement.setInt(1,id);
preparedStatement.setString(2,name);
//4.执行SQL(把SQL处理后的中间结果发给服务器)
//通过.executeUpdate();进行增、删、改、建表、删表
//preparedStatement.executeUpdate();
//而它的返回结果是当前操作影响到的行数
int n = preparedStatement.executeUpdate();
System.out.println("n = " + n);
//5.资源的释放(关闭连接)
preparedStatement.close();
connection.close();
}
}2.2 查找
我们刚刚写的代码是有关于增、删、改的,现在我们来写一下查找的代码,和之前的有一点点的不一样,但基本步骤还是一样的
略有不同的是执行SQL,查询我们使用到的是executeQuery() ,此时这个方法返回的是一个resultSet()结果集,想要查询到临时表,我们就需要遍历这个结果集

这里还要注意,需要多关闭一个结果集

代码示例:
sql
import com.mysql.cj.jdbc.MysqlDataSource;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class JdbcDemo2 {
public static void main(String[] args) throws SQLException {
//1.创建数据源
DataSource dataSource = new MysqlDataSource();
((MysqlDataSource)dataSource).setUrl("jdbc:mysql://127.0.0.1:3306/java117?characterEncoding=utf8&useSSL=false");
((MysqlDataSource)dataSource).setUser("root");
((MysqlDataSource)dataSource).setPassword("javawxl");
//2.和数据库服务器建立连接
Connection connection = dataSource.getConnection();
//3.构造SQL
String sql = "select*from student";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
//4.执行SQL,返回结果是一个对象,结果集(ResultSet)
ResultSet resultSet = preparedStatement.executeQuery();
while (resultSet.next()) {
//针对一行进行处理
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
System.out.println(id + " " + name);
}
//5.关闭连接和相关资源
resultSet.close();
preparedStatement.close();
connection.close();
}
}3.一些补充知识点
3.1 不是所有的数据库都是客户端服务器结构
以下是几种常见的数据库架构模式:
-
客户端-服务器架构(Client-Server)
这是最常见的数据库架构,如MySQL、Oracle等。客户端应用程序通过网络请求数据,服务器处理请求并返回结果
-
嵌入式数据库(Embedded Database)
数据库直接嵌入应用程序中运行,如SQLite。适用于桌面应用或小型系统,无需独立服务器
-
分布式数据库(Distributed Database)
数据分散存储在多台服务器上,通过网络协同工作。如Hadoop、Cassandra
-
NoSQL数据库
包括键值存储(如Redis)、文档存储(如MongoDB)、列式存储(如HBase)等,架构灵活多样
-
云数据库(Cloud Database)
数据存储在云端,如AWS RDS、Azure SQL。客户端通过API访问
-
对等网络数据库(Peer-to-Peer)
所有节点既是客户端也是服务器,如BitTorrent。适用于去中心化应用
每种架构适用于不同场景,选择需根据应用需求、性能要求和扩展性来决定
3.2 向上转型和向下转型
向上转型(Upcasting )和向下转型(Downcasting)是面向对象编程中的关键概念,主要涉及继承关系中的类型转换
3.2.1 向上转型(Upcasting)
定义:将子类对象赋值给父类引用变量,即从子类型转换为父类型
特点:
- 安全:总是安全的,因为子类对象包含父类的所有属性和方法
- 隐式:自动进行,无需显式转换操作符
- 用途:实现多态性,通过父类引用调用子类方法
3.2.2 向下转型(Downcasting)
定义:将父类引用转换为子类引用,即从父类型转换为子类型
特点:
- 风险:可能抛出ClassCastException,需确保对象实际类型匹配
- 显式:需要使用 ( 子类类型 ) 父类引用 语法
- 用途:访问子类特有的属性和方法
3.2.3注意事项
- 类型检查:向下转型前必须使用 instanceof 检查类型,避免异常
- 性能影响:向下转型可能增加运行时开销,但现代JVM优化有限
- 设计原则:优先使用向上转型实现多态,减少向下转型的使用
通过理解这两者,可以更好地管理对象类型转换,避免运行时错误
3.3 Java的 " 垃圾回收机制 "
Java的垃圾回收机制**(GC)**是自动管理内存的,帮你省去手动释放内存的麻烦,避免内存泄漏和溢出问题。简单来说,它会自动清理不再使用的对象,释放内存空间
核心概念
-
可达性分析:从"GC Roots"(如静态变量、栈帧引用等)出发,通过引用链判断对象是否可达。不可达对象被视为垃圾
-
分代收集:将堆内存划分为新生代(Eden + Survivor)和老年代,根据对象生命周期采用不同算法优化回收效率
加油加油!!( ̄︶ ̄)↗