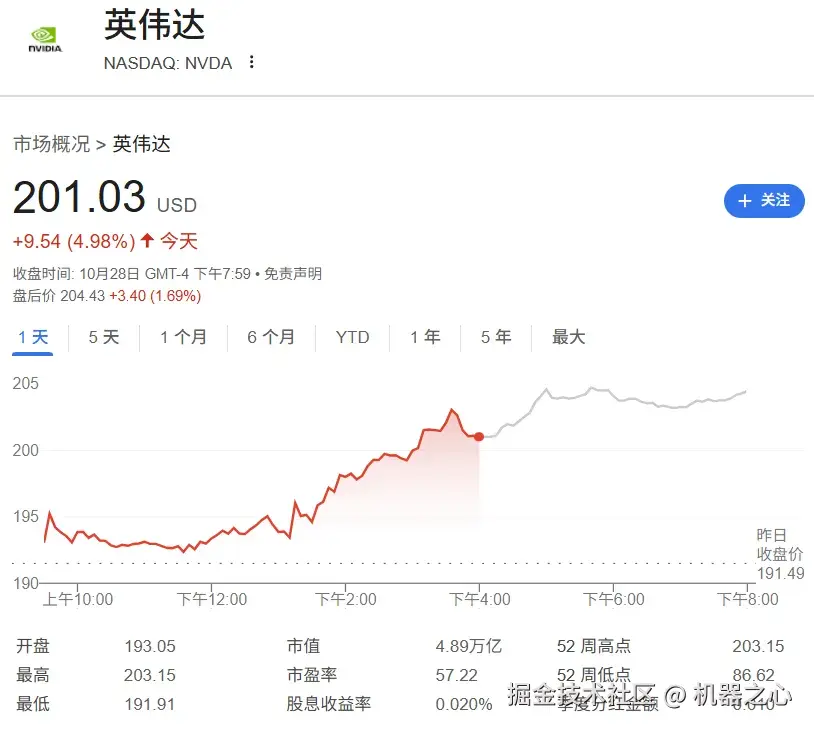
昨夜,英伟达让人眼花缭乱。
从大规模 GPU 部署和量子突破,到安全的 AI 工厂、机器人技术和自动驾驶,黄仁勋在 NVIDIA GTC Washington 的舞台上勾勒出了美国 AI 世纪 (America's AI century) 的蓝图。
黄仁勋 Keynote 演讲后,英伟达股价应声上涨,今天涨幅已经达到 4.98%,这也使得英伟达的市值增加 2300 多亿美元,来到了前所未有的 4.89 万亿美元,此前甚至触及 4.94 万亿美元!
这也意味着,英伟达即将成为首家市值达到 5 万亿美元的公司。
黄仁勋的演讲以一段视频开场,这段视频是对美国的创新精神以及过去、现在和未来的美国创新者们的致敬。这不仅仅是又一场科技演讲 ------ 这是一份宣言,一个美国在人工智能基础设施和创新领域保持领先地位的蓝图。
「欢迎来到 GTC,」黄仁勋在人群的欢呼声中宣布,「很难不对美国感到动情和自豪。」

接下来,黄仁勋主要介绍了以下内容:
-
Vera Rubin 超级芯片亮相
-
借助实体 AI 和数字孪生推动美国再工业化
-
凭借 AI 原生的 6G 制定全球标准
-
依靠 NVIDIA NVQLink 巩固量子领域的领先地位
-
利用安全且可随时部署的 AI 设施设计实现政府现代化
-
通过日常贡献构建美国的开放模型支柱
-
借助统一的 DRIVE Hyperion 生态系统加速实现自主化
以下是详细内容。
Vera Rubin 超级芯片亮相
在 GTC 大会上,黄仁勋展示了下一代 Vera Rubin 超级芯片。这是我们首次实际看到这款「超级芯片」。它搭载了 Vera CPU 和两颗强大的 Rubin GPU。该主板还搭载了大量 LPDDR 系统内存(共 32 个),将与 Rubin GPU 上的 HBM4 显存配合使用。

可见,每块 Rubin GPU 都由大量的电源电路包围,每个芯片将配备 8 个 HBM4 显存位点和两个 Reticle 大小的 GPU 芯片。Vera CPU 将配备 88 个定制 ARM 核心,共计 176 个线程。
谈到推出计划,老黄透露,他预计 Rubin GPU 将在明年 10 月或更早进入量产阶段,也就是 2026 年第三季度或第四季度。所有这一切都发生在 Blackwell Ultra GB300 超级芯片平台全速推出的同时。
规格方面,Vera Rubin NVL144 平台将采用两颗全新芯片。Rubin GPU 将采用两颗 Reticle 大小的芯片,FP4 性能高达 50 PFLOP,并配备 288 GB 的下一代 HBM4 显存。此外,这些芯片还将搭载一颗 88 核 Vera CPU,该 CPU 采用定制的 Arm 架构,拥有 176 个线程,以及高达 1.8 TB/s 的 NVLINK-C2C 互连。

在性能扩展方面,Vera Rubin NVL144 平台将具有 3.6 Exaflops 的 FP4 推理能力和 1.2 Exaflops 的 FP8 训练能力,比 GB300 NVL72 提升 3.3 倍,13 TB/s 的 HBM4 内存和 75 TB 的快速内存,比 GB300 提升 60%,并且 NVLINK 和 CX9 功能增加 2 倍,额定速度分别高达 260 TB/s 和 28.8 TB/s。
加强版本的平台 Rubin Ultra 将于 2027 年下半年推出,其 NVL 系统将会从 144 个扩展到 576 个。CPU 架构保持不变,但 Rubin Ultra GPU 将采用四个小芯片,提供高达 100 PFLOPS 的 FP4 性能,以及分布在 16 个 HBM 位置上的 1 TB HBM4e 总容量。

在性能扩展方面,Rubin Ultra NVL576 平台将具有 15 Exaflops 的 FP4 推理能力和 5 Exaflops 的 FP8 训练能力,比 GB300 NVL72 提升 14 倍,4.6 PB/s 的 HBM4 内存和 365 TB 的快速内存,比 GB300 提升 8 倍,NVLINK 能力提升 12 倍,CX9 能力提升 8 倍,额定速度分别高达 1.5 PB/s 和 115.2 TB/s。

英伟达的转向:从 CPU 到 GPU 加速计算
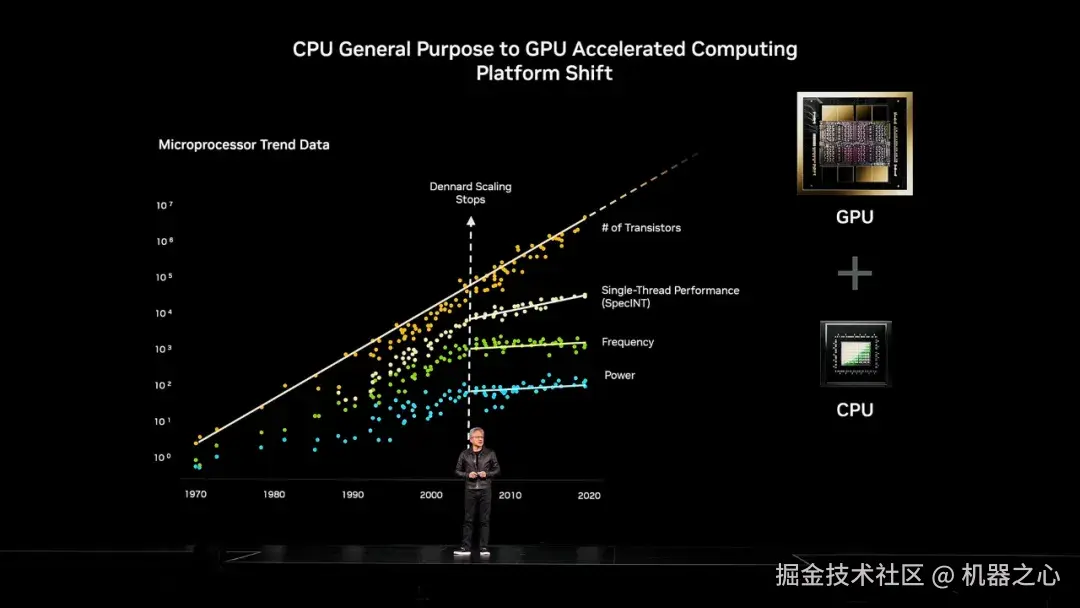
几十年来,CPU 的性能增长一直如时钟般精准 ------ 直到登纳德缩放定律(Dennard scaling)失效。英伟达的答案是:并行计算、GPU 和加速计算。摩尔定律也不可能永远持续下去。
「我们发明这种计算模型,是因为我们想解决通用计算机无法解决的问题。」黄仁勋说。「我们观察到,如果我们能增加一个可以利用越来越多晶体管的处理器,并应用并行计算,再将其添加到顺序处理的 CPU 上,我们就能远远扩展计算的能力 ------ 而那个时刻真的到来了。」
加速计算始于英伟达贯穿整个技术栈的 CUDA-X 库 ------ 从用于深度学习的 cuDNN 和 TensorRT-LLM,到用于数据科学的 RAPIDS (cuDF/cuML),用于决策优化的 cuOpt,用于计算光刻的 cuLitho,以及用于量子和混合量子经典计算的 CUDA-Q 和 cuQuantum 等等。
「这确实是我们公司的宝藏。」 黄仁勋在播放一段展示 CUDA-X 功能的视频前说道。
美国 AI 原生 6G 技术栈与 ARC-Pro
黄仁勋表示,电信是我们经济和国家安全的命脉。
然而,如今全球范围内的无线技术在很大程度上「依托外国技术部署,我们的基础通信技术建立在外国技术之上,这种情况必须停止 ------ 而且我们有机会做到这一点。」
黄仁勋宣称,是时候「重返赛场」了。
黄仁勋宣布了一个以美国为核心的 AI 原生 6G 无线协议栈 ------NVIDIA ARC,该协议栈基于 NVIDIA Aerial 平台构建,并由加速计算提供支持,而诺基亚将整合 NVIDIA 的这项技术。
黄仁勋表示:「我们将与诺基亚合作,他们将把 NVIDIA ARC 用作其未来的基站。」

量子飞跃:NVQLink
四十年前,量子物理学家理查德・费曼设想了一种新型计算机,能够直接模拟自然现象,因为它基于量子原理运行。
黄仁勋表示,现在已经可以制造出一种相干、稳定且能纠错的逻辑量子比特(qubit)。但这些量子比特「极为脆弱」,因此需要强大的技术来进行量子纠错并推断量子比特的状态。
为了连接量子计算和 GPU 计算,黄仁勋宣布推出 NVIDIA NVQLink------ 一种量子 GPU 互连技术,可实现从 QPU 进行实时 CUDA-Q 调用,延迟低至约 4 微秒。

黄站在一张幻灯片前说道:「几乎每个能源部实验室都在与我们的量子计算公司生态系统以及这些量子控制器合作,以便将量子计算融入到未来的科学发展中。」幻灯片重点展示了 17 家量子计算公司和多个美国能源部实验室的支持。
加速美国科学
黄仁勋表示,得益于对 AI 基础设施史无前例的投资,美国的国家实验室正在进入一个科学发现的新时代。他宣布,美国能源部 (DOE) 正与英伟达合作,建造七台新的超级计算机,以推动未来科学的发展。

英伟达正与美国能源部和甲骨文 合作,在阿贡国家实验室建造能源部最大的 AI 超级计算机。
关键信息:
-
位于阿贡的新型 Solstice 系统将部署 100,000 个 NVIDIA Blackwell GPU。这将使其成为有史以来为公共研究构建的、最大的由「智能体 AI」驱动的科学平台。
-
Equinox 系统将额外配备 10,000 个 Blackwell GPU,为百亿亿次级 (exascale) 科学、模拟和开放研究提供高达 2,200 exaflops 的 AI 性能。
-
这项投资开启了由「智能体 AI」驱动的科学新纪元,将极大地提高美国在安全、能源和科学应用领域的生产力,并加速突破性进展。

走进 AI 工厂:极限协同设计
「AI 不是工具,AI 本身就是工作 (work)。」黄仁勋宣称。「技术第一次能够真正干活 (do work),帮助我们提高生产力。这种从工具到 AI 工作者 (AI workers) 的转变,正在创造全新的计算形式,随之而来的是新的就业和产业。」
AI 工厂不仅仅是数据中心;它们是专门构建的平台,用于大规模生成、移动和服务 token。
「然后,因为 AI 是一个如此庞大的问题,我们对其进行了纵向扩展 (scale up)。」 黄仁勋解释说。「我们创造了一台完整的计算机...... 这是第一次,一台计算机被扩展成了整个机架。那是一台计算机,一个 GPU。然后,我们通过发明一种新的 AI 以太网技术,对其进行了横向扩展 (scale out)。」 他补充道,指的是 NVIDIA Spectrum-X。
随着这些 AI 工厂的崛起,它们正在催生 AI 工程、机器人技术、量子科学和数字运营等领域的新职业 ------ 这些职位在几年前还根本不存在。

「这个良性循环现在已经启动了。」黄仁勋说。「我们需要做的,是大幅降低成本。这样一来,首先,用户体验会更好...... 其次,通过降低成本,我们能让这个良性循环持续下去。」
黄仁勋表示,解决方案是「极限协同设计」 (extreme codesign),即同时设计全新的基础计算机架构,包括新的芯片、系统、软件、模型和应用。
为了强调这些系统的实体性(physicality),黄仁勋将一些设备带到了舞台上。此外,他还发布了全新的 NVIDIA BlueField-4 DPU。这款处理器配备了 64 核的 NVIDIA Grace CPU 和 NVIDIA ConnectX-9,为其 AI 工厂的操作系统提供动力,其计算能力约为 BlueField-3 的 6 倍。

发布 Omniverse DSX------ 千兆瓦级 AI 工厂蓝图
黄仁勋还介绍了 Omniverse DSX,这是一个用于设计和运营 100 兆瓦 (megawatt) 到数千兆瓦 (multi-gigawatt) 级别 AI 工厂的综合蓝图。该蓝图已在弗吉尼亚州马纳萨斯的 AI 工厂研究中心得到验证。
-
DSX Flex:用于动态电网协作
-
DSX Boost:用于优化每瓦性能
-
DSX Exchange:用于统一 IT/OT 集成
「AI 基础设施是一个生态系统级别的挑战,需要数百家公司协同合作。NVIDIA Omniverse DSX 是一个用于构建和运营千兆瓦级 AI 工厂的蓝图。」 黄仁勋说。「借助 DSX,英伟达在全球的合作伙伴能够以前所未有的速度构建和启动 AI 基础设施。」
英伟达开放模型、数据与库
黄仁勋解释说,开源和开放模型正在推动全球初创企业、大型企业和研究人员的创新。英伟达在模型家族和数据方面均做出了贡献 ------ 仅今年就贡献了数百个开放模型和数据集。

英伟达的模型家族包括:Nemotron (用于智能体和推理 AI)、Cosmos (用于合成数据生成和实体 AI)、Isaac GR00T (用于机器人技能和泛化) 以及 Clara (用于生物医学工作流)。这些模型为智能体 AI、机器人技术和科学突破提供了动力。
「我们致力于此,因为科学需要它,研究人员需要它,初创公司需要它,企业也需要它。」 黄仁勋此言赢得了现场观众的热烈掌声。
随后,黄仁勋重点介绍了一些基于英伟达技术构建的 AI 初创公司,以及来自谷歌、微软 Azure 、甲骨文、ServiceNow、SAP、Synopsys、Cadence、CrowdStrike 和 Palantir 的成果。
黄仁勋宣布,英伟达正与 CrowdStrike 合作,以实现「光速」 (speed of light) 般的网络安全。通过使用基于 NVIDIA Nemotron 的模型和 NVIDIA NeMo 工具,企业将能够在从云到边缘的各个节点部署专门的安全智能体。
他还宣布,英伟达和 Palantir 正在将加速计算、CUDA-X 库和 Nemotron 开放模型整合到 Palantir Ontology 平台中,以「实现规模大得多、速度快得多的数据处理」。
与全球领导者共建数字孪生平台,助力美国再工业化
实体 AI (Physical AI) 正在推动美国的再工业化 (reindustrialization)------ 通过机器人技术和智能系统改造工厂、物流和基础设施。在一段视频中,黄仁勋重点展示了合作伙伴们如何将其付诸实践。

「工厂本质上是一个机器人,它指挥着其他机器人去制造机器人化的产品。」 他说。「要做到这一点,所需的软件数量是如此庞大,以至于如果你不能在数字孪生中完成它,那么几乎不可能指望它在现实中奏效。」
在舞台上,黄仁勋点名了富士康的工作,该公司正使用 Omniverse 工具来设计和验证其位于休斯顿的新工厂,该工厂将用于制造英伟达的 AI 基础设施系统。他还提到了 Caterpillar------ 该公司也正在将数字孪生技术用于制造;以及 Brett Adcock,他在三年半前创立了 Figure AI 公司,该公司致力于为家庭和工作场所打造人形机器人,目前市值已接近 40 亿美元;此外还有强生以及迪士尼,后者正使用 Omniverse 来训练「有史以来最可爱的机器人」。
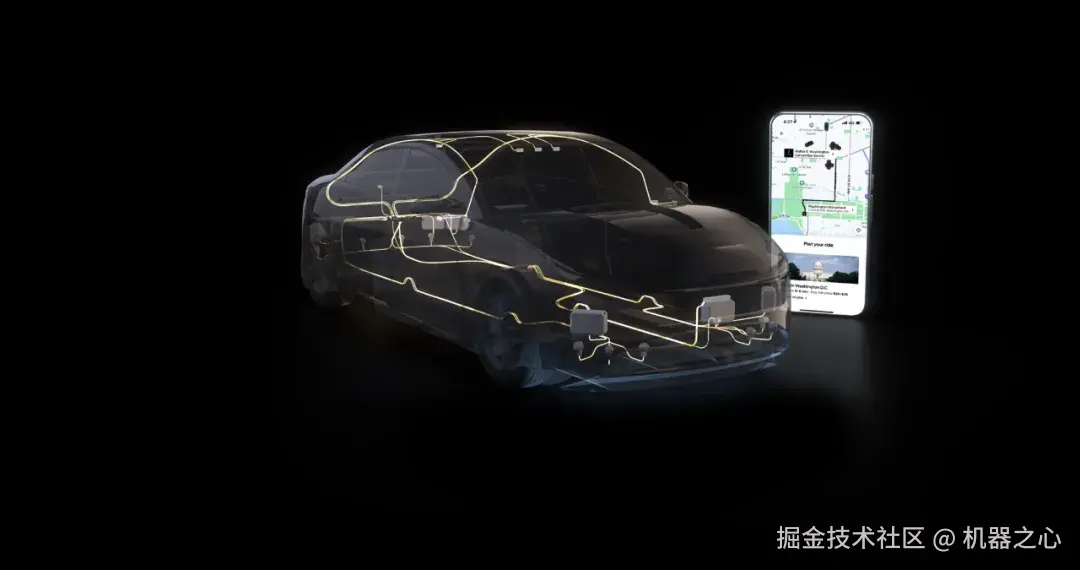
自动驾驶出行:Uber 和 DRIVE Hyperion 10
黄仁勋宣布,Uber 和英伟达正在合作构建自动驾驶出行的中坚力量 ------ 目标是部署约 100,000 辆自动驾驶汽车,并从 2027 年开始规模化。NVIDIA DRIVE AGX Hyperion 10 是 L4 级别的参考架构:它安全、可扩展、由软件定义 ------ 将人类驾驶员和机器人驾驶员统一在同一个网络上。
「在未来,你将能叫到这样一辆车。」 黄仁勋说。「这个生态系统将变得极其丰富,我们的 Hyperion 自动驾驶出租车 (robotaxi) 将遍布世界各地。」
-
目标部署约 100,000 辆自动驾驶汽车;从 2027 年开始规模化
-
DRIVE AGX Hyperion 10 是 L4 级别自动驾驶的参考设计
-
Lucid、梅赛德斯 - 奔驰和 Stellantis 集团正在为其具备 L4 级别能力的乘用车采用 DRIVE Hyperion
黄仁勋最后表示:「AI 时代已经开启。Blackwell 是它的引擎。感谢大家允许我们将 GTC 带到华盛顿特区。我们希望今后每年都能在这里举办。」
参考链接:
blogs.nvidia.com/blog/nvidia...