#数据集来源:kaggle Animal 10
#模型: yolo11x-cls.pt (这个是用来做图像分类的)
-------------第二次编辑-------------------------
博主在这里发现YOLO11s-cls的效果是比yolo11x-cls的效果好一些,这里不知道具体原因。
可能是yolo11x-cls容易过拟合的原因,所以可尝试从5轮开始训练.
对于YOLO模型训练,分为两步:准备并处理好训练集,写脚本训练模型
我们需要把数据集处理好,一个好的数据集往往能提高模型整体质量,识别率也比较高。
训练集处理部分
由于我们从Kaggle---animal 10获取的数据集,它们的图片像素大小都是未经过处理的,如果直接拿去训练,它们的效果会很差。所以先处理图片的像素为第一步。
| 图片尺寸 | 优点 | 缺点 | 推荐场景 |
|---|---|---|---|
| 128×128 | 快速训练 | 丢失细节 | 测试模型 |
| 224×224 | 速度与精度平衡 | 几乎无 | 分类任务标准尺寸 |
| 320×320 | 捕捉更多细节 | 占显存 | 动物体型差异大时 |
| 640×640 | 极高精度 | 慢、显存大 | 检测任务(非分类) |
像素大小,自己选择,我这里选的是224x224。
像素重置
python
import cv2
import os
from tqdm import tqdm
import numpy as np
# ===== 路径配置 =====
input_root = r"your_jpg_path" # 原始图片路径
output_root = r"the_path_you_need" # 输出路径
target_size = (224, 224) # 最终尺寸
fill_color = (0, 0, 0) # 填充颜色:黑色,可改成 (255,255,255) 白色
# ===== 函数:等比例缩放并填充 =====
def letterbox_image(image, target_size, fill_color=(0,0,0)):
h, w = image.shape[:2]
target_w, target_h = target_size
# 按比例缩放
scale = min(target_w / w, target_h / h)
new_w, new_h = int(w * scale), int(h * scale)
resized = cv2.resize(image, (new_w, new_h), interpolation=cv2.INTER_AREA)
# 创建背景并填充图像
result = np.full((target_h, target_w, 3), fill_color, dtype=np.uint8)
x_offset = (target_w - new_w) // 2
y_offset = (target_h - new_h) // 2
result[y_offset:y_offset + new_h, x_offset:x_offset + new_w] = resized
return result
# ===== 批量处理所有图片 =====
for category in os.listdir(input_root):
category_path = os.path.join(input_root, category)
if not os.path.isdir(category_path):
continue
output_category = os.path.join(output_root, category)
os.makedirs(output_category, exist_ok=True)
print(f"正在处理类别: {category}")
images = [f for f in os.listdir(category_path)
if f.lower().endswith(('.jpg', '.jpeg', '.png'))]
for img_name in tqdm(images, desc=f"{category}", ncols=80):
src_path = os.path.join(category_path, img_name)
dst_path = os.path.join(output_category, img_name)
try:
img = cv2.imread(src_path)
if img is None:
continue
processed = letterbox_image(img, target_size, fill_color)
cv2.imwrite(dst_path, processed)
except Exception as e:
print(f"⚠️ 跳过文件: {img_name}, 错误: {e}")
print("\n✅ 所有图片已统一为 224x224(比例保持不变,自动填充)")
print("输出路径:", output_root)如果想改成别的像素大小的话,直接修改target_size就好了。
这里只需要改变路径还有自己想要的像素,就可以直接使用了
然后注意一点:就是我们在压缩或者拉伸图片的大小时,图片会出现失真,也就是会有白边或者模糊,这样子的照片也会使得模型训练出现问题,因此我们需要对需要拉伸或压缩的部分,进行黑边补齐,图片等比例缩小。这样子就不会实际影响到图片质量。
所有图片最终都是 224×224,
但保持原图比例不变,
不拉伸、不压扁,
多余的空白部分自动填充(通常为黑色或白色)。
这种操作叫做 Letterbox Padding(信箱填充)。
图片改名
这部分图片是否改名,其实没有那么重要。但是如果你是要进行成果展示的话。最好还是改一下图片的名称。不过这个也有脚本可以直接使用。
python
import os
base_dir = r"E:\HomeWork\archive\demo\dataset\images"
#这里改成你想要的文件的位置。
for cls in os.listdir(base_dir):
cls_path = os.path.join(base_dir, cls)
if not os.path.isdir(cls_path): # 跳过非文件夹
continue
# 筛选图片文件(不区分大小写)
files = [f for f in os.listdir(cls_path) if f.lower().endswith(('.jpg','.png','.jpeg'))]
for i, f in enumerate(files):
ext = os.path.splitext(f)[1] # 获取原扩展名(如 .jpg)
new_name = f"{cls}_{i:04d}{ext}" # 生成新文件名(如 "cat_0000.jpg")
os.rename(os.path.join(cls_path, f), os.path.join(cls_path, new_name))我这里的路径结尾 images 这里下面是存放自己的数据集的类别文件夹。
然后你这些子文件夹中的图片都会被改成与这个子文件同名+后缀数字。
训练集划分
这一步就是进行划分我们的数据集,分别为train和val。
datasets/
animals/
train/
cat/
dog/
horse/
val/
cat/
dog/
horse/
python
import os, random, shutil
base_dir = r"E:\HomeWork\archive\demo\dataset\images"
output_dir = r"E:\term_middle\animals_yolo"
train_ratio = 0.8 # 80% 用于训练,20% 用于验证
for cls in os.listdir(base_dir):
src_dir = os.path.join(base_dir, cls)
if not os.path.isdir(src_dir):
continue
imgs = [f for f in os.listdir(src_dir) if f.lower().endswith(('.jpg','.png','.jpeg'))]
random.shuffle(imgs)
n_train = int(len(imgs) * train_ratio)
train_imgs = imgs[:n_train]
val_imgs = imgs[n_train:]
for phase, subset in [('train', train_imgs), ('val', val_imgs)]:
dst_dir = os.path.join(output_dir, phase, cls)
os.makedirs(dst_dir, exist_ok=True)
for img in subset:
shutil.copy(os.path.join(src_dir, img), os.path.join(dst_dir, img))
print("✅ 数据集划分完成")这里只需要你改变基地址以及结果存放地址即可,同时你也可以改变训练集的比例。
然后就是可以直接使用。
模型训练部分
模型训练脚本
python
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO("yolo11x-cls.yaml")
results = model.train(data="E:/term_middle/animals_yolo", epochs=10, imgsz=224)对代码解释:
epochs = 10 这里是训练轮数,这个轮数并不是越多越好的,可能会出现过拟合。需要自己抉择,你的数据集越多基本上训练的轮数就可以越少。 一般取10轮。
batch
imgsz --- 图像的像素大小, 让yolo进行训练的时候,把用于训练的图像压缩到该像素大小224
对于 if__name__ == 'main':
Windows 系统下使用 PyTorch 多进程 DataLoader 时的经典问题 ,根本原因是:在 Windows 上,multiprocessing 默认使用 spawn 而不是 fork,而 spawn 会重新导入主模块,如果主模块直接执行了训练代码(而不是放在 if __name__ == '__main__': 保护块中),就会无限递归地启动新进程,导致崩溃。
所以我们一定要把训练放到这个判断语句下面
在YOLO训练过程中,会自动生成训练和验证的损失曲线
这里需要改变的部分是分类模型,需要你自己去github下载一个到此文件夹中。
一个tarin.py 这里都是需要放到该项目文件夹中的。
这里是具体训练过程。

----------后续更新训练曲线-验证--------------
模型验证部分
模型验证环节,非常简单的代码。 这里就直接提供代码了
python
from ultralytics import YOLO
if __name__ == '__main__':
# Load a model
model = YOLO("yolo11x-cls.pt") # 加载官方的模型
model = YOLO("C:/Users/madao/runs/classify/train3/weights/best.pt") # 你自己训练好的best.pt模型
# Validate the model
metrics = model.val() # no arguments needed, dataset and settings remembered
metrics.top1 # top1 accuracy
metrics.top5 # top5 accuracy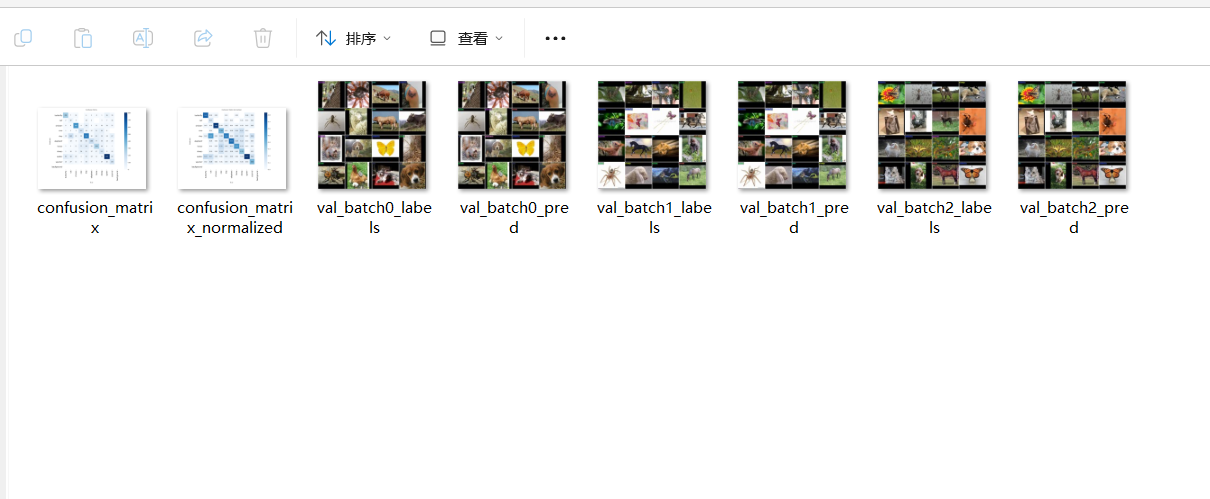
以上就是验证环节会给到的一些数据。
实时检测部分
python
import cv2
from ultralytics import YOLO
# ===========================
# 1. 加载您自己的训练好的模型
# ===========================
# 替换为您的模型路径(可以是本地路径或官方模型名)
model = YOLO("C:/Users/madao/runs/classify/train3/weights/best.pt") # 例如:yolo11x-cls.pt 或 ./best.pt
# ===========================
# 2. 打开摄像头(默认摄像头编号0)
# ===========================
cap = cv2.VideoCapture(0) # 0表示默认摄像头,如果您有多个摄像头,可以尝试1,2等
# 检查摄像头是否成功打开
if not cap.isOpened():
print("无法打开摄像头,请检查设备连接。")
exit()
# ===========================
# 3. 实时检测循环
# ===========================
while True:
# 从摄像头读取帧
ret, frame = cap.read()
if not ret:
print("无法获取视频帧,请检查摄像头。")
break
# ===========================
# 4. 模型推理(预测)
# ===========================
results = model(frame)
# ===========================
# 5. 绘制检测结果
# ===========================
annotated_frame = results[0].plot()
# ===========================
# 6. 显示结果
# ===========================
cv2.imshow("YOLO实时检测", annotated_frame)
# 按ESC键退出(ASCII码27)
if cv2.waitKey(1) == 27:
break
# ===========================
# 7. 释放资源
# ===========================
cap.release()
cv2.destroyAllWindows()
print("实时检测已停止。")