湖仓系统必须能够在分布式存储之上、面对复杂且常常不可预测的变更模式时,仍然同时保持写入效率与查询性能,去管理 PB 级数据集。这类系统运行规模巨大,需要同时支持分析型与事务型混合负载。为满足这些要求,湖仓表需要类似 OLTP 数据库的多样化索引能力。在写入路径上,索引必须随新写入一同维护,并被用于在海量数据集中高效定位要更新与删除的既有记录;在读取路径上,索引需要同样高效地处理多样化的查询模式:范围谓词受益于基于文件统计信息的剪枝,等值谓词受益于索引查找,而函数类谓词需要专门的表达式处理。
在撰写本文时,Apache Hudi 是唯一原生支持索引能力的湖仓存储系统。本章将讨论 Hudi 如何通过索引技术在规模化场景下保持读写高效,并说明为何正确制定索引策略正是实现"准实时"湖仓性能的关键。我们将涵盖:
- 湖仓表索引的基础要点,及读写两侧如何借助索引技术优化性能
- 通过 Hudi 元数据表实现的"多模态索引"机制及其支持的不同索引类型
- 面向写入路径、用以在不增加太多存储开销的情况下优化写入的写侧索引,并给出选型指导
读完本章,你将全面理解 Hudi 强大而灵活的索引能力。更重要的是,你将学会如何分析自身工作负载,并在性能、成本与运维复杂度之间做权衡,从而选出最合适的索引。Hudi 将分布式存储上实现索引这一艰巨工程进行抽象与封装,让你可以把精力放在作出更高层的性能决策上。
Hudi 中的索引概览
Hudi 的索引大体分为两类。第一类是驻留于元数据表 中的"多模态索引"子系统,提供多种索引共同提升读与写性能。第二类是写侧专用索引,专为特定场景加速写入。表 5-1 总结了 Hudi 中最常用的索引类型。
表 5-1. 常见 Hudi 索引类型概览
| 类别 | 索引类型 | 存放位置 | 使用位置 | 工作方式 |
|---|---|---|---|---|
| 多模态索引 | 文件(Files) | 元数据表 | 读 & 写 | 提供分区与文件列表,支持写入、索引及查询规划 |
| 分区统计(Partition stats) | 元数据表 | 读 | 提供分区级统计,用于查询规划阶段的分区剪枝 | |
| 列统计(Column stats) | 元数据表 | 读 | 提供文件级统计,用于查询规划阶段的文件剪枝 | |
| 布隆过滤器(Bloom filter) | 元数据表 | 读 & 写 | 针对记录键字段提供布隆过滤,加速 SQL DML 与查询时的定位 | |
| 记录索引(Record) | 元数据表 | 读 & 写 | **读:**对记录键等值谓词提供文件组的精确匹配;**写:**校验记录-到-文件的映射以识别更新/删除与插入 | |
| 二级索引(Secondary) | 元数据表 | 读 | 对指定的非记录键字段的等值谓词提供文件的精确匹配 | |
| 表达式索引(Expression) | 元数据表 | 读 | 基于指定列上的表达式提供剪枝能力 | |
| 写侧索引 | 简单索引(Simple) | 隐式(随文件切片) | 写 | 通过对新旧记录做 join 来定位更新/删除的目标文件组 |
| 布隆索引(Bloom) | 隐式(随基文件) | 写 | 结合键范围与布隆过滤,在既有记录上高效查找传入记录键 | |
| 分桶索引(Bucket) | 隐式(随文件组) | 写 | 使用一致性哈希将传入记录直接定位到精确的文件组 |
在接下来的内容中,我们先从写入路径 的角度审视索引:先回顾写入流程的高层脉络,再深入能优化写入的具体索引类型,说明其适用场景与取舍。随后转向读取路径,回顾读取流程,并探讨用于加速查询规划的索引,同样分析其适用性与权衡。
写入加速的索引
当 Hudi 处理一批传入记录时,必须高效判断每条记录是新增 还是对既有记录的修改。将传入记录映射到表中的物理位置,正是写入侧索引要完成的事情。对于更新与删除,写入侧索引尤为关键:写入器必须精确定位包含该记录的文件组,才能正确地进行修改。
如图 5-1 所示,写入过程中的索引包含两个主要步骤:
- 查找(Lookup) :用传入批次的记录键查询索引,以确定既有记录的当前所在位置。
- 更新(Update) :在数据写入过程中,同步更新索引,以反映已写入记录的最新位置信息。
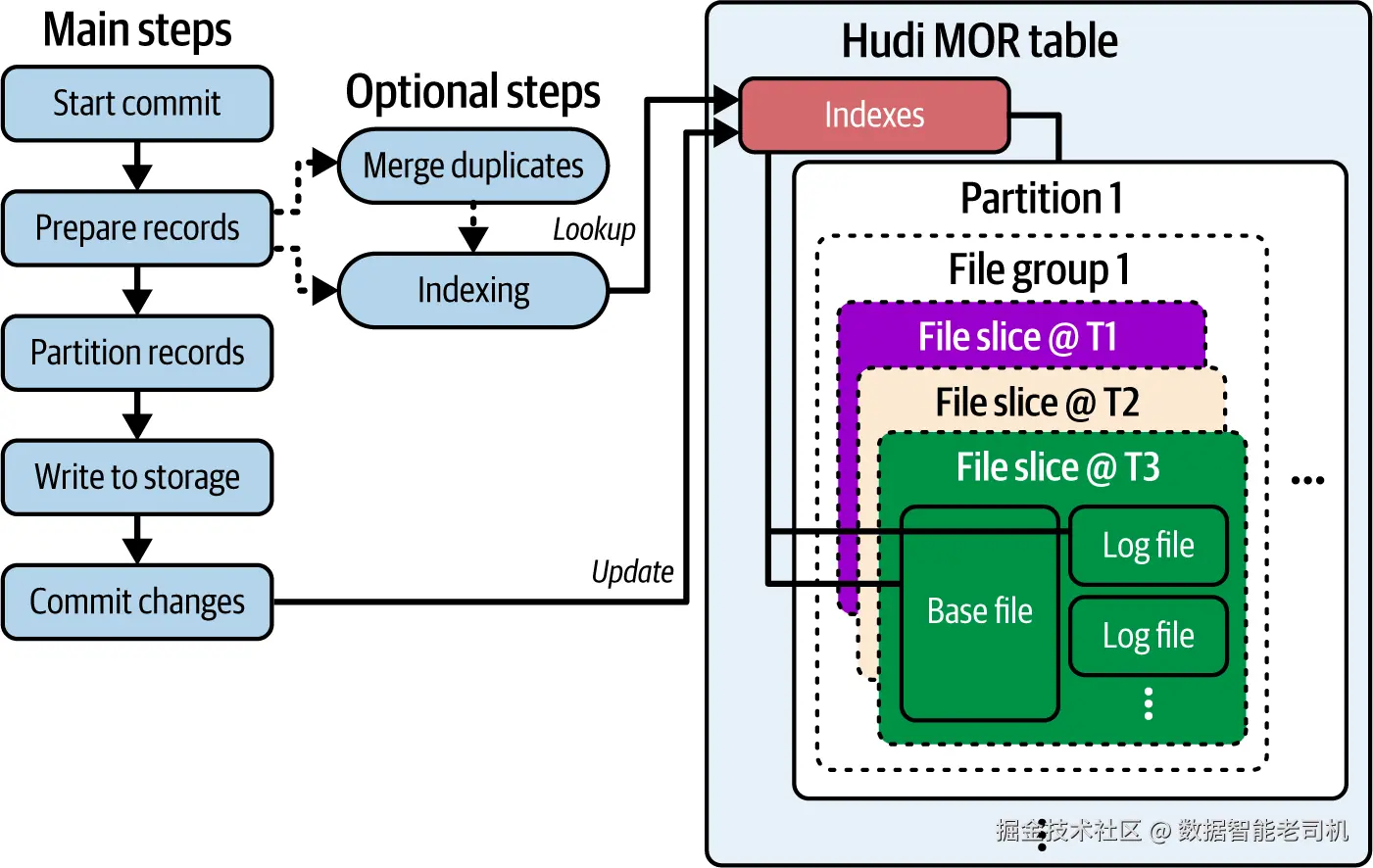
注:写侧索引是隐式存放于表内数据文件的一部分,无需显式维护步骤;但它们无法被查询以通用方式直接利用。
由于索引是写入路径的组成部分,索引策略的选择将直接影响整体写入性能。低效的索引会引入不必要的开销,拉长写入时延。因此,为你的工作负载选择合适的索引,是构建高性能、可及时产出业务洞察的数据管道的关键。
在后续小节中,我们将介绍最常用的索引,并演示如何针对不同的真实场景选择最优索引。
通用多模态索引(General-Purpose Multimodal Indexing)
能够将记录键 直接映射到其物理位置 的索引,能提供近乎极致的查找速度。为达成这一点,Hudi 在湖仓领域率先引入了记录索引(record index) :一种通用、高性能、且适用于大多数真实场景(尤其是大规模场景)的索引方案。记录索引存放在 Hudi 的**元数据表(metadata table)**中(第 2 章已介绍)。要理解本章的记录索引及其相关概念,首先需要弄清元数据表的结构与功能。
借助元数据表进行索引存储
元数据表位于 .hoodie/metadata/(见图 5-2),本身就是一张 Hudi 的 MOR(Merge-on-Read) 表。它包含若干为特定索引目标而设计的分区,用于支撑读路径、写路径,或两者兼有。创建 Hudi 表时,元数据表默认启用,并自动建立三类索引(对应三个分区):
- files (在
files/分区):追踪表中的分区列表与文件列表; - column stats (在
column_stats/分区):提供文件级统计信息; - partition stats (在
partition_stats/分区):提供分区级统计信息。
记录索引 位于record_index/分区,需要显式启用。
为确保数据表与索引 条目保持同步,对主数据表的任何写入,都会在同一原子事务内更新元数据表。对元数据表的读写遵循标准 MOR 表的相同流程。
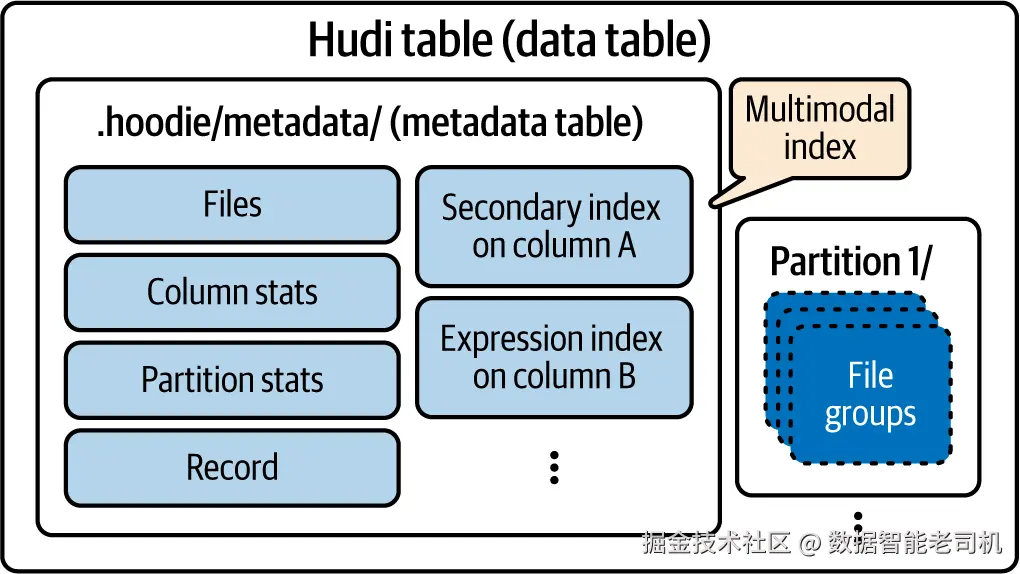
图 5-2. 元数据表的组织结构(示意:files、column stats、partition stats、record index 以及基于指定列表达式的索引;分区中的文件组等)
元数据表的基文件 采用行式、查找优化 的 HFile 格式。HFile 是一种有序且不可变 的键值(KV)文件格式,结构类似 SSTable ,带有内部多级索引,可在不用全表扫描的情况下按键高效定位。这与元数据表的典型访问模式(例如批量查找)高度契合。比如在摄入大批数据时,写入器可以批量用记录键查询 HFile 中的有序数据,大幅提升索引性能。
作为 MOR 表,元数据表非常适合高频写入 。要获取最新索引信息,索引读取会执行快照查询 (将基文件与日志文件合并)。但若日志文件过多,会降低读取性能 。为此,Hudi 会像维护普通 MOR 数据表那样,自动对元数据表做压缩(compaction) (第 4 章已介绍):默认每 10 次写入 触发一次,可通过 hoodie.metadata.compact.max.delta.commits 调整。
因为元数据表在不同分区中承载了多样索引类型,它也被称为多模态索引(multimodal index) 。如图 5-2 所示,已支持的索引包括:files、column stats、partition stats、record、secondary,并支持为指定列构建表达式索引 。后续在写入侧索引 部分,我们将深入讲解记录索引 及其他写侧索引;主要面向读取加速的索引将于"读路径索引加速"章节详述。
记录索引(Record Index)
Hudi 的记录索引在 record_index/ 分区中存放数据表每条记录 的位置映射 。每个索引项都包含关键元数据------分区路径、文件 ID、提交时间 ------从而让写入器能精确定位包含该记录的文件切片 (见图 5-3)。因为对元数据表的更新与数据表同事务 进行,任何插入、更新、删除都会自动同步 更新记录索引,保持强一致 。记录索引是记录位置的"单一事实来源 ":如果查不到条目,就表明传入记录是新插入。
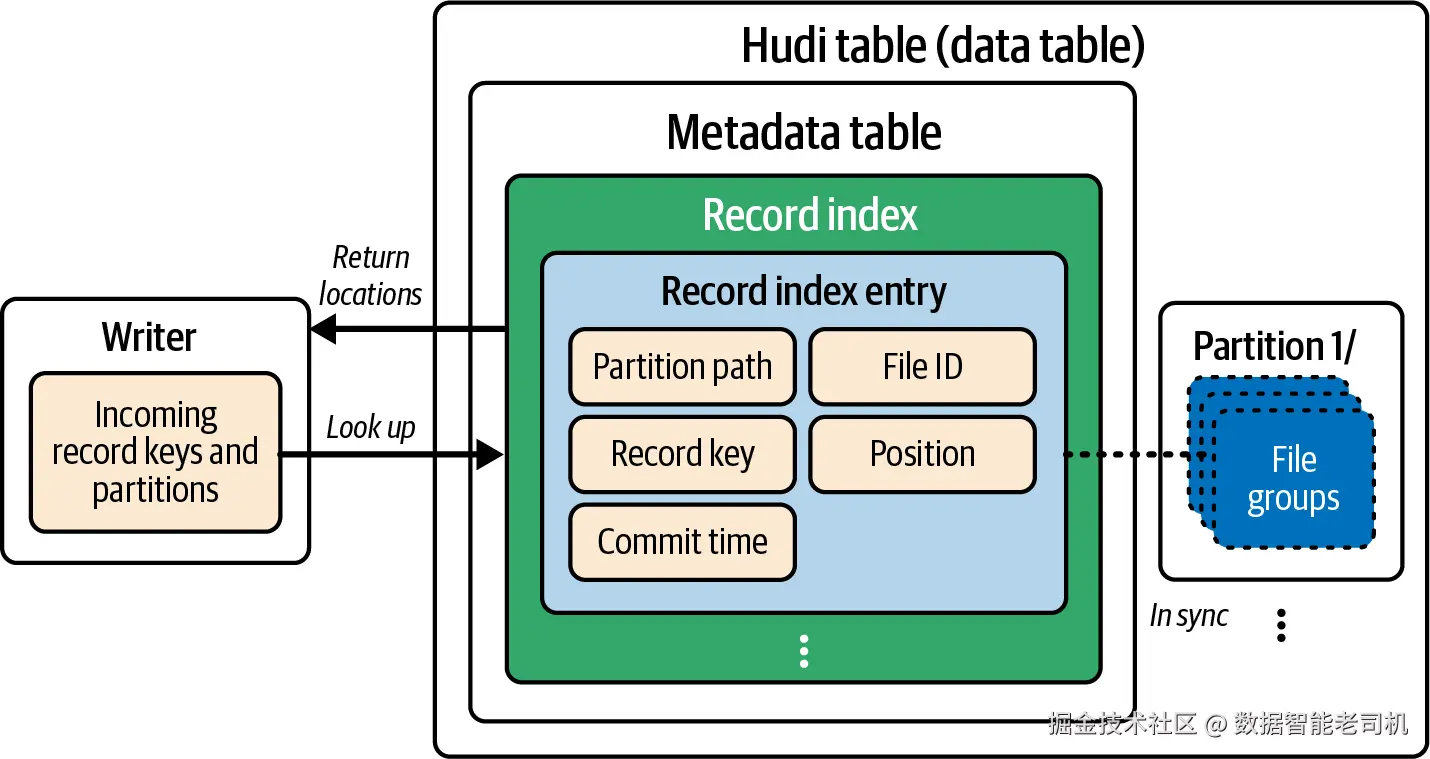
图 5-3. 写入器如何利用元数据表中的记录索引对传入更新/删除做位置查找(返回分区路径、文件 ID、提交时间等)
除了对写入有帮助,记录索引在查询存在等值谓词 时也能显著提升读性能 (参见"Equality Matching"小节)。记录索引条目采用固定模式 并做了压缩 ,平均约 48 字节/条 。举例而言,100 TB 规模、含 10 亿 行记录的表,其记录索引也有 10 亿条目,但仅约 48 GB 存储,占比 < 0.05% 。相对于它带来的巨大性能收益,这点开销极具性价比。
启用记录索引可在建表时设置表属性:
ini
CREATE TABLE user_profile (
id STRING,
name STRING,
age INT,
update_ts BIGINT,
country STRING
) USING hudi
TBLPROPERTIES(
primaryKey = 'id',
preCombineField = 'update_ts',
'hoodie.metadata.record.index.enable' = 'true'
)
PARTITIONED BY (country);也可对已有表启用/禁用记录索引:
sql
CREATE INDEX record_index ON user_profile (id); -- 1
DROP INDEX record_index ON user_profile; -- 2- 创建记录索引时,必须指定正确的记录键字段 (本例为
id)。CREATE INDEX会触发索引构建并与数据表对齐的过程。 DROP INDEX会永久删除 索引文件及元数据表中的record_index/分区。
提示
对于超大表 ,首次构建索引可能耗时较长。为避免阻塞后续写入 ,可使用索引表服务(indexing table service)进行异步构建(第 6 章将详细介绍)。
写侧索引(Writer-Side Indexes)
在接下来的小节中,我们将根据不同的写入模式来选择写侧索引。在此之前,先深入讲解一下 bucket index(桶索引) ------它是实现实时写入高速度的绝佳选择。
Bucket Index(桶索引)
与记录索引类似,Hudi 的 bucket index 也提供记录键 → 文件 的直接映射,从而获得极佳的查找性能。但与将索引条目持久化在元数据表不同,bucket index 通过哈希机制 将记录路由到特定的文件组(file group) 。每条记录的键会被哈希,以确定性地映射到某个"桶"(bucket),而该桶就对应一个文件组(见图 5-4)。这保证了相同的记录键始终落在同一文件组 ,查找因此简化为常数时间的内存哈希计算。
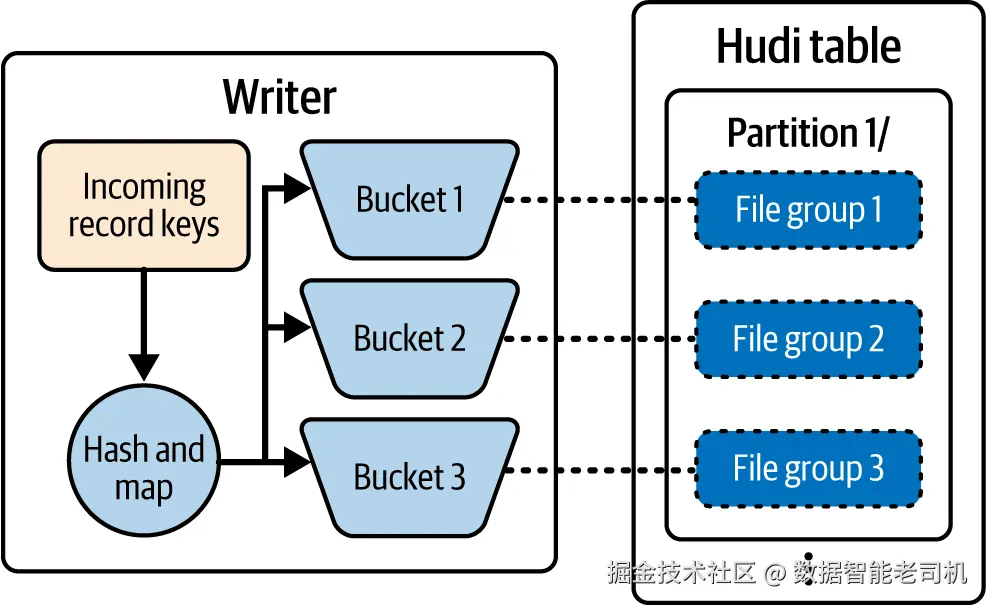
图 5-4. Bucket index 如何对传入记录键做哈希并映射到数据表分区内的具体文件组
Bucket index 有两种变体:
- Simple bucket index(简单桶索引)
默认变体;为每个分区设置固定数量 的桶。适用于数据量可预期的工作负载,同时支持 COW 与 MOR 表。 - Consistent hashing bucket index(一致性哈希桶索引)
能动态调整桶数量 以适配数据增长或倾斜,对不断演化的负载更灵活。但仅适用于 MOR 表。
使用 bucket index 时,需要在写入前设置相应配置,例如:
ini
-- 使用简单桶索引
SET hoodie.index.type=BUCKET;
SET hoodie.index.bucket.engine=SIMPLE;
SET hoodie.bucket.index.num.buckets=64;
-- 使用一致性哈希桶索引
SET hoodie.index.type=BUCKET;
SET hoodie.index.bucket.engine=CONSISTENT_HASHING;
SET hoodie.bucket.index.min.num.buckets=32;
SET hoodie.bucket.index.max.num.buckets=128;优势 在于其轻量化设计 :依赖内存哈希计算,而非访问磁盘索引。由于哈希函数具有确定性,记录位置可即时计算 ,相同键总是映射到相同文件组。这使得 bucket index 属于隐式索引,无需单独的更新步骤,始终与数据保持一致。
取舍在于:
- 简单桶索引 的桶数需预先固定,若选择不当易产生数据倾斜。
- 一致性哈希变体 可缓解倾斜,但仅支持 MOR ,并且需要运行聚类(clustering)表服务(第 6 章介绍)进行再均衡,带来运维复杂度。
- 另外,这两类变体尚未与读路径集成,无法像记录索引那样加速等值谓词查询。
Simple Index(简单索引)
在数仓中,维度表 存放业务实体的描述性参考数据(如用户画像、商户信息、商品属性)。这类表通常比事实表 小、变更频率低,但会有小批量、离散(随机)的更新或删除(见图 5-5)。维度表常常不分区(也可基于查询模式、更新频率、平台能力等考虑分区,而不只是表大小)。
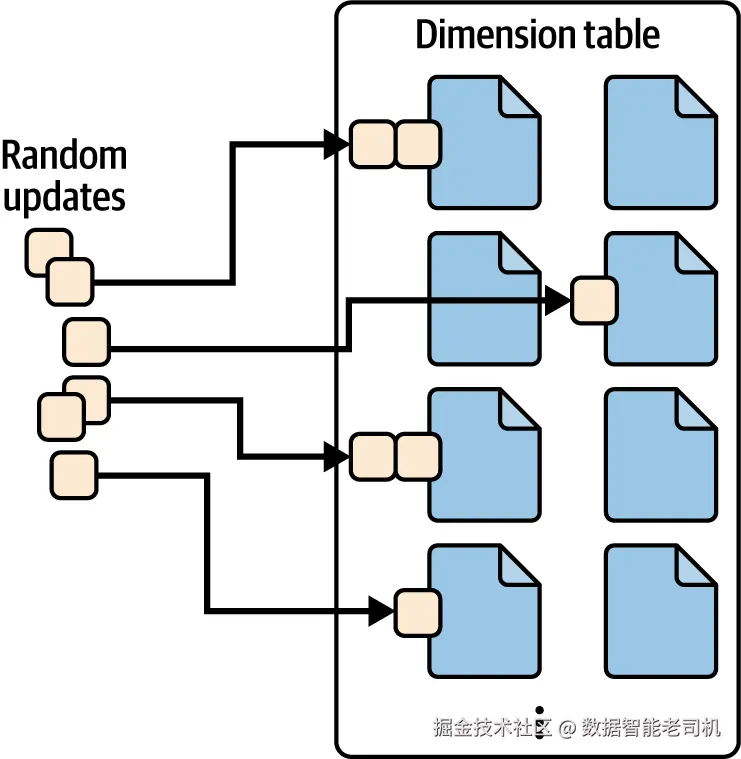
图 5-5. 维度表上的随机更新分布到各个文件
对于小到中等规模 的维度表,simple index / global simple index 是直接又有效的方案。顾名思义,这类索引通过将传入批数据与当前表做左连接来定位既有记录。两者的差异在于扫描范围:
- simple index 仅在相关分区内查找匹配键;
- global simple index 在整张表 范围内查找。
下文统称为"简单索引"。其机制如图 5-6 所示。
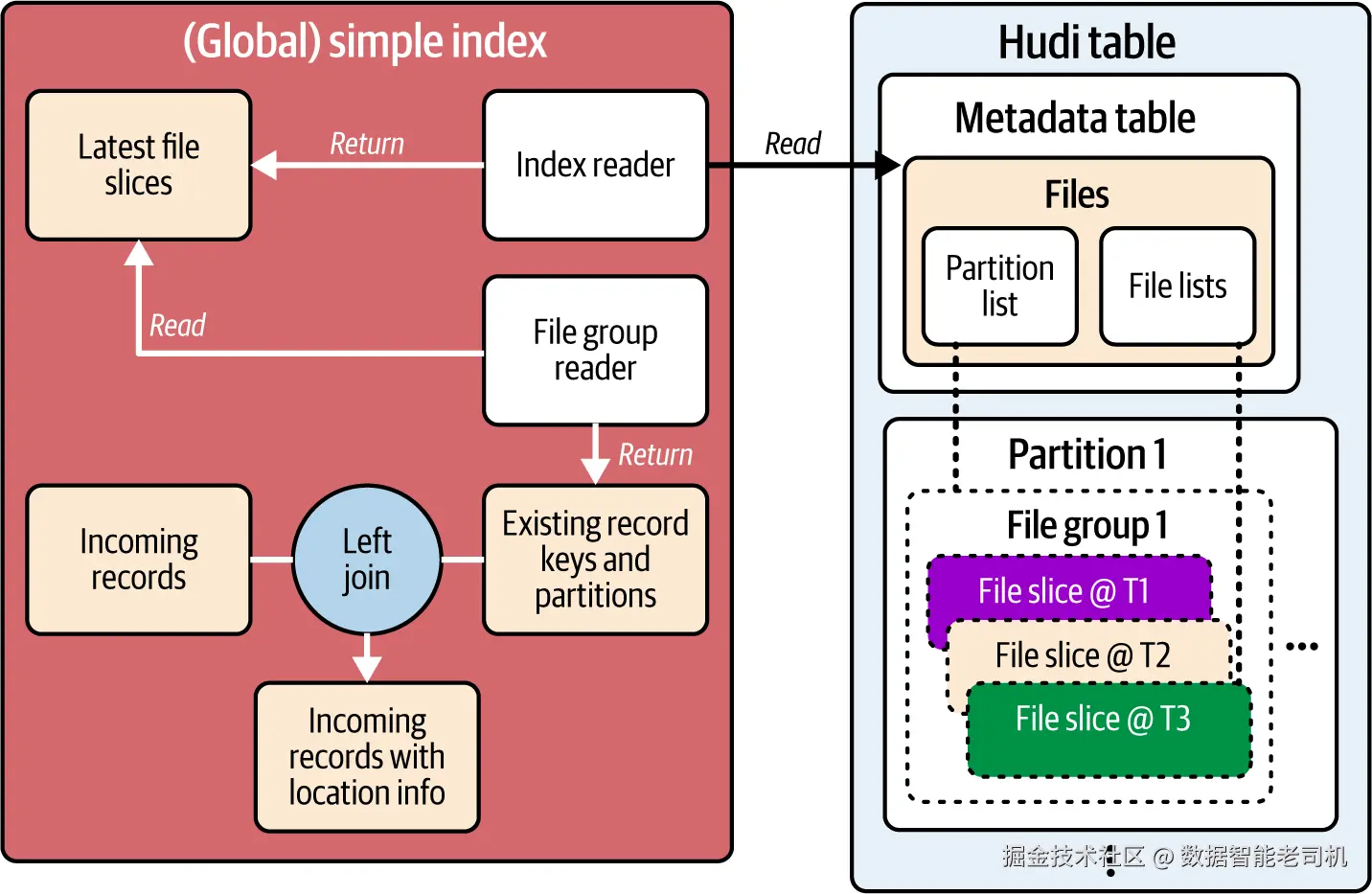
图 5-6. 简单索引的索引流程:读取并连接传入记录与现有记录(及分区)
流程包含三步:
- 文件切片发现 :索引读取器查询元数据表的 files 索引,获取最新文件切片列表。simple 只取与传入记录对应分区的切片;global simple 取整表所有切片。
- 键提取 :文件组读取器仅从相关文件切片中提取记录键与分区路径,形成用于连接的最小数据集。
- 位置标注 :将传入批记录与提取出的键/分区做左连接 。连接成功表示匹配到更新/删除目标并标注其位置;连接失败则视为新插入。
该连接式 方法的效果取决于命中率 ------扫描的文件切片中有多少包含传入批的匹配记录。对于随机更新/删除 (散落在众多切片),命中概率高,扫描相关分区的成本是值得的。也就是说,更新越分散 ,简单索引往往越高效。
配置方式(尽管 simple 为默认值):
ini
-- 使用 simple index(默认)
SET hoodie.index.type=SIMPLE;
-- 使用 global simple index
SET hoodie.index.type=GLOBAL_SIMPLE;与 bucket 一样,简单索引也是隐式存储:只要文件切片正确生成,后续索引查找直接读取这些文件即可。
局限在于:当表的文件切片数量非常大 时,连接式索引的性能会下降,尤其是 global simple 需要扫描整表 所有文件组的最新切片。尽管只加载键和分区路径,对小输入批做大规模连接仍可能成为写入瓶颈。
Bloom Index(布隆索引)
事实表 通常按时间字段分区(如订单按创建日分区)。这类场景下,写入往往严重倾斜 :大多数新数据(包含更新/删除)都打向最新分区 (如当日),仅有较少延迟到达的数据落到旧分区(见图 5-7)。
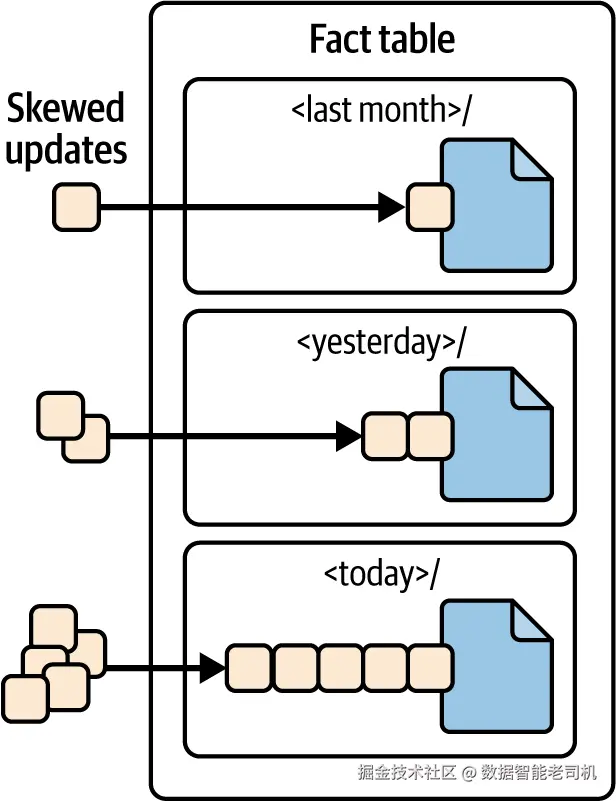
图 5-7. 事实表上的倾斜更新:当日分区相对前几日分区写入更集中
针对这种倾斜写模式 ,bloom / global bloom 索引 非常有效。它利用布隆过滤器(Bloom filter)快速判定某文件中必不含 某键,从而避免不必要的文件读取;并利用数据文件中保存的记录键最小/最大值 进一步收缩候选文件 ,仅对这些候选的布隆过滤器做检查。与 simple 类似,bloom 只作用于相关分区,global bloom 作用于整表。下文统称"bloom 索引"。流程见图 5-8。
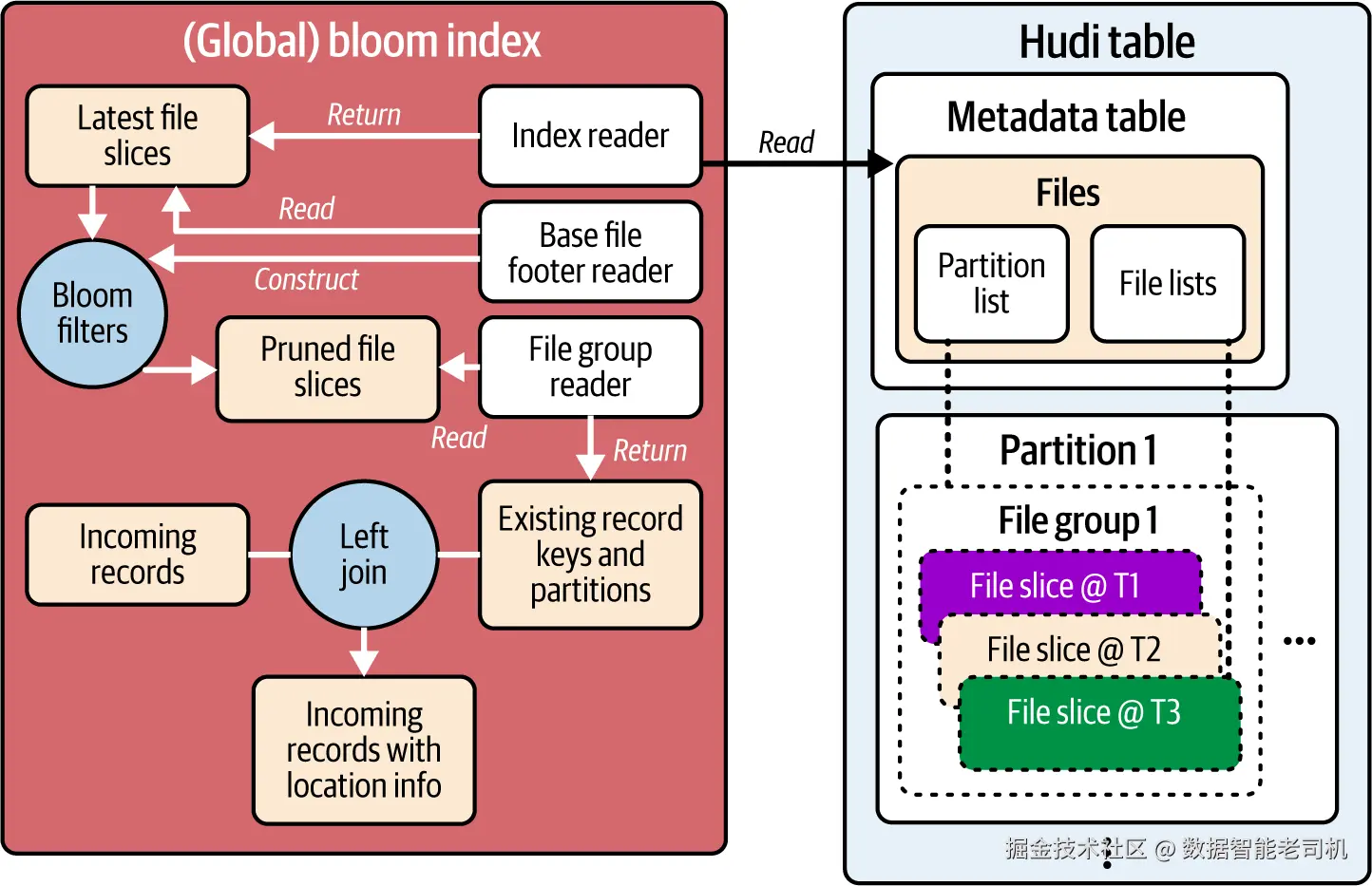
图 5-8. Bloom 索引的索引流程:布隆过滤器、文件切片与记录处理步骤
主要步骤:
- 文件切片发现:同简单索引。通过元数据表的 files 索引获取候选切片列表------bloom 针对匹配分区,global bloom 针对整表。
- 文件切片裁剪 (关键):对按记录键范围 初步筛出的候选切片,读取其基文件(base file)页脚中的布隆过滤器。布隆过滤器是一种空间高效的概率结构 ,可判断元素一定不在 集合或可能在 集合(有可调的假阳性率 )。将传入记录键与过滤器比对后,Hudi 得到一个保证包含 更新/删除目标的裁剪切片列表。
- 键提取:与简单索引相同。从裁剪后的切片中提取记录键与分区信息。
- 位置标注:与简单索引相同。对提取结果做左连接,命中则标注为更新/删除,未命中则为新插入。
注意
仅文件切片中的基文件 在页脚保存布隆过滤器;在 MOR 场景下,裁剪时无需考虑日志文件(除非使用了 bucket 索引会把插入也写入日志)。也就是说,基文件上的布隆过滤器可代表该文件切片,用于是否存在的判断。
bloom 索引之所以高效,是因为它能借助布隆过滤器在倾斜负载 下显著提高命中率 :当更新集中在少数分区时,从其他分区读取到的过滤器能快速判定 "不包含",从而跳过绝大多数文件切片,把昂贵的连接仅集中在很小的候选集合 上。此过滤过程只需读取轻量的基文件页脚,因此即使表很大,也能高效应对倾斜的更新/删除模式。
配置方式:
ini
-- 使用 bloom index
SET hoodie.index.type=BLOOM;
-- 使用 global bloom index
SET hoodie.index.type=GLOBAL_BLOOM;与简单索引一样,bloom 索引也是隐式更新:某个基文件的布隆过滤器存于其页脚,并在写数据时一并写出,确保索引与数据同步。
在随机更新 负载下,bloom 的表现可能不如 simple:因为记录键分布在大量文件组中,布隆过滤器更容易给出"可能存在 ",从而裁剪效果变差 。这会导致仍需对大量文件切片做读取与连接,使加载过滤器与裁剪这一步反成额外开销。
此外,当表包含极多文件切片 时,bloom 也会产生额外性能负担:尽管其可有效裁剪搜索空间,但为每个候选基文件读取页脚 这一步本身就可能成为瓶颈,尤其是 global bloom 需要考虑整表的每个文件组。大量页脚 I/O 的累积会拖慢整体写入过程。
写入索引选择对比(Comparison of Writer Indexing Choices)
到目前为止,我们已经介绍了四类主要的写侧索引:record(记录) 、bucket(桶) 、simple(简单) 和 bloom(布隆) 。要想在 Hudi 表上获得最佳的写入效率,理解它们各自的优劣与适用场景至关重要。每一种索引都在"定位记录"这一核心目标上采用了不同路径,在性能、成本与运维复杂度之间体现出不同权衡。
为帮助你选择,表 5-2 将它们的关键特性进行了并排比较。
表 5-2. 写侧索引摘要
| 索引类型 | 优点 | 缺点 |
|---|---|---|
| Record(记录索引) | 通用且高性能;适用于各种规模与负载;可加速等值匹配查询;可用 SQL 便捷管理 | 会带来一定存储开销 ;需要维护索引的额外开销 |
| Bucket(桶索引) | 对更新密集 写入最快;适用于各种规模;无存储开销 | 可能导致对查询不友好 的存储布局(如丧失时间局部性);一致性哈希桶索引仅支持 MOR |
| Simple(简单索引) | 简单、无存储与维护 开销;可复用引擎的连接优化;适合随机更新/删除 | 不适合倾斜 的更新/删除;不适合大规模表 |
| Bloom(布隆索引) | 对倾斜 更新/删除表现好;即使超大表也合适------查找开销与写入模式 成正比而非与表规模成正比 | 为存放 Bloom 过滤器与键范围会有小存储与维护 开销;对随机更新/删除表现不佳 |
如表所示,最佳选择强烈依赖你的具体负载:包括表规模、更新模式以及性能要求。
此外,Hudi 还提供 flink state index ,其工作方式与 record 索引类似,但索引数据的存放位置不同 ------record 索引使用与数据湖相同存储空间的元数据表 ,而 flink state index 则把记录位置映射保存在 Apache Flink 写入作业的状态后端数据库中。
我们也简要提到过全局(global)与非全局(nonglobal)索引的概念,它源自记录键唯一性 的作用域。在为 Hudi 表配置 upsert 时,你必须定义记录键字段 ,Hudi 依赖它来唯一标识记录;对于分区表,你还需要定义分区路径字段 。记录唯一性的作用域取决于记录键是在整表唯一 ,还是仅在各自分区内唯一 。这一区别至关重要,它直接决定了应当选择全局 还是非全局 索引。由于湖仓表通常比 RDBMS/OLTP 表大 10--100 倍 ,在这种数据量下,非全局索引可以利用"已知分区"的信息缩小查找范围,从而更易扩展。
根据数据特征,你的表大致会落入以下两种情形之一:
- 情形 1 :仅凭记录键 即可确定唯一性------整张表中不会存在相同记录键的多条记录。
- 情形 2 :必须将记录键与分区路径字段联合 起来才能确定唯一性------同一个记录键可能出现在不同分区。这也意味着写入时用户需同时提供键与分区路径。
鉴于这两种情形取决于数据本身 ,Hudi 引入了全局与非全局索引 的选择规则:若满足情形 1 ,为写入选择全局索引 ;若满足情形 2 ,选择非全局索引。表 5-3 总结了各写侧索引的这一属性。
表 5-3. 写侧索引的全局/非全局属性
| 索引类型 | 是否为全局(Global)? |
|---|---|
| Simple | 否 |
| Global simple | 是 |
| Bloom | 否 |
| Global bloom | 是 |
| Bucket(simple) | 否 |
| Bucket(consistent hashing) | 否 |
| Record | 是 |
全局索引 假设整表唯一 ,因此查找时可能需要扫描整表 的文件。对于 global simple ,当表变大时性能可能下降;而 record 索引 由于提供直接的键→文件映射,受影响较小。
非全局索引 只假设分区内唯一 ;因此 simple 与 bloom 相比其全局变体通常更高效 ,因为查找范围被限制在与传入记录相关的分区。
注意
全局/非全局的概念仅适用于写侧索引。对读侧索引没有这一说法,因为读取时我们总是希望在**整表范围(含分区匹配)**获取符合条件的记录。
若你的数据满足情形 1 却选择了非全局 索引(如 simple 或 bloom),由于查找只在相关分区进行,可能造成数据正确性问题 。反之,若数据满足情形 2 却选择了全局 索引(如 global simple 或 global bloom),则会在查找时浪费计算资源 扫描无关文件。经验法则是:充分理解你的数据 ,从而在全局 vs. 非全局之间做出正确选择。
提示
对于非分区表 ,可以把整表视作拥有单一分区 (分区路径为空字符串)。因此,全局与非全局索引在功能上等价,任选其一都可工作。
读路径上的索引加速(Index Acceleration for Reads)
正如第 4 章所述,Hudi 与查询引擎的集成会在查询规划阶段 利用其索引组件来优化需要读取的文件切片 列表(见图 5-9)。多数情况下,这个索引组件就是元数据表(metadata table) ,它在建表时默认启用。若在建表时通过 hoodie.metadata.enable=false 显式关闭元数据表,那么你将无法受益于本节即将介绍的这些强大的读侧索引能力。
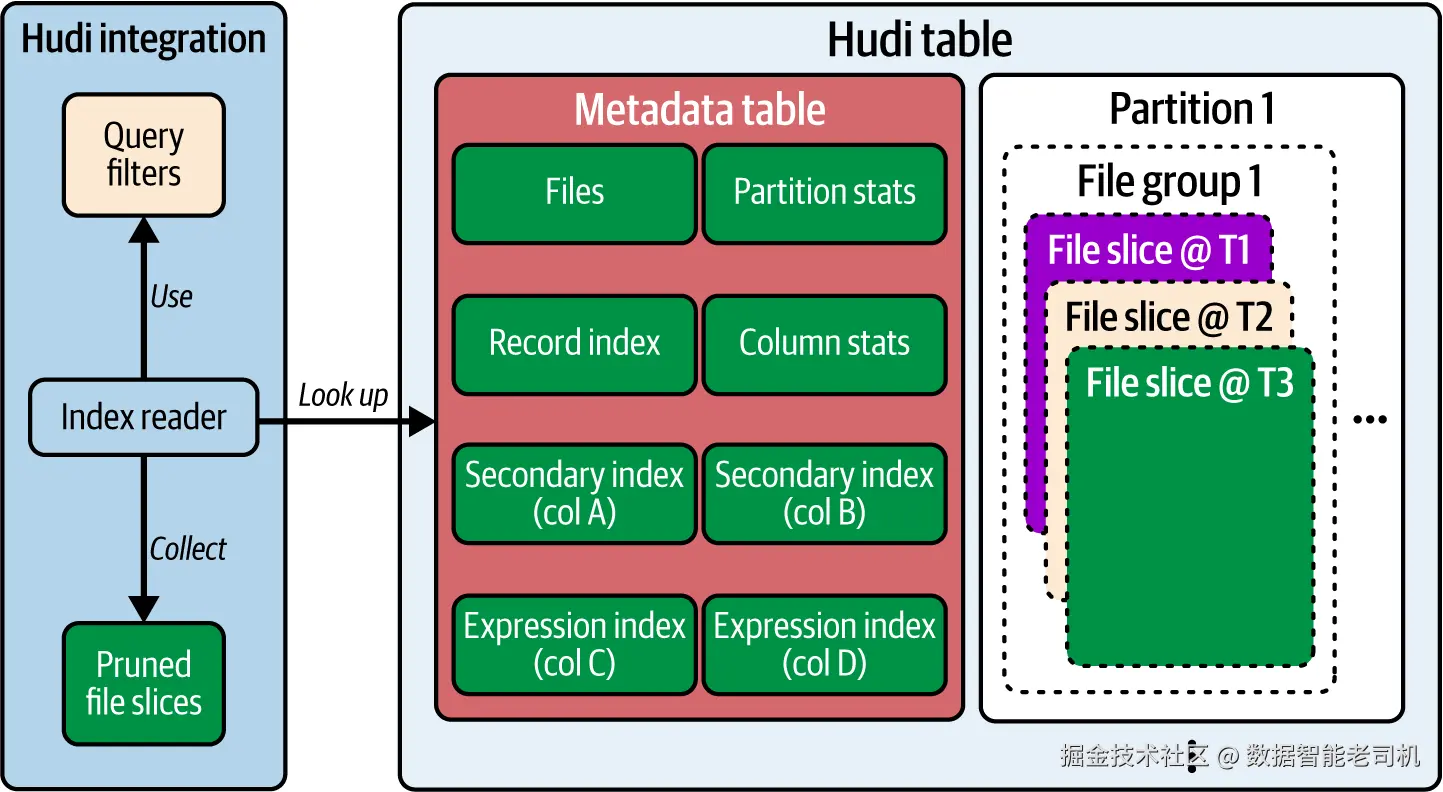
图 5-9. 查询引擎集成在规划阶段利用元数据表进行优化
在前面的写侧索引章节中,我们已将元数据表介绍为一个多模(multimodal)索引 。它之所以"多模",就在于它能根据可用的查询过滤条件提供多种索引,协同最大化优化机会,从而共同增强读取流程。
数据跳过(Data Skipping)
生产环境中的分析型 SQL 查询几乎总会带有谓词过滤(如 A >= X、B BETWEEN Y AND Z)。查询引擎可以把这些谓词下推 到 Hudi 的引擎集成层,后者再利用元数据表中的索引来优化查询计划,最小化需要读取的文件数。
三类索引------files 、column stats 与 partition stats ------协同完成文件裁剪(pruning) 。下面分别介绍它们,并展示它们如何在优化流程中协作。
files 索引
正如在写路径中所见,files 索引 为写入端提供查找所需的文件切片列表;在读路径中,它也扮演类似角色:提供全表、最新的分区清单以及各分区下的文件切片清单。这个清单构成初始候选集合,随后会基于查询谓词继续裁剪。
若没有 files 索引,读写两侧都需要执行昂贵且耗时的文件系统列举 来发现表内容。由于分区与文件信息几乎是所有 Hudi 操作的基础,只要启用了元数据表,就一定有 files 索引可用。
column stats 与 partition stats 索引
column stats 与 partition stats 存储用于数据跳过 的统计信息,这是加速查询的关键优化。例如:若某数据文件的统计显示列 A 的最大值为 100,那么在处理 A > 100 的查询时,优化器可以直接跳过该文件。
- column stats :维护文件级统计信息,包括各文件切片内列的最小值/最大值、总值数量、空值数量等。
- partition stats :维护分区级聚合统计,与 column stats 类似但粒度在分区层面。
这两类索引在默认情况下启用 ,并会在每次写入时自动更新 以与数据保持同步。也可以在建表 或某次写作业 中将它们设置为 false 来禁用:
hoodie.metadata.index.column.stats.enablehoodie.metadata.index.partition.stats.enable
注:partition stats 依赖 column stats。因此若要使用 partition stats,必须启用 column stats;但可以仅启用 column stats 而不启用 partition stats。
裁剪流程
将三类索引合在一起,我们可以得到优化阶段的文件裁剪全流程(见图 5-10):
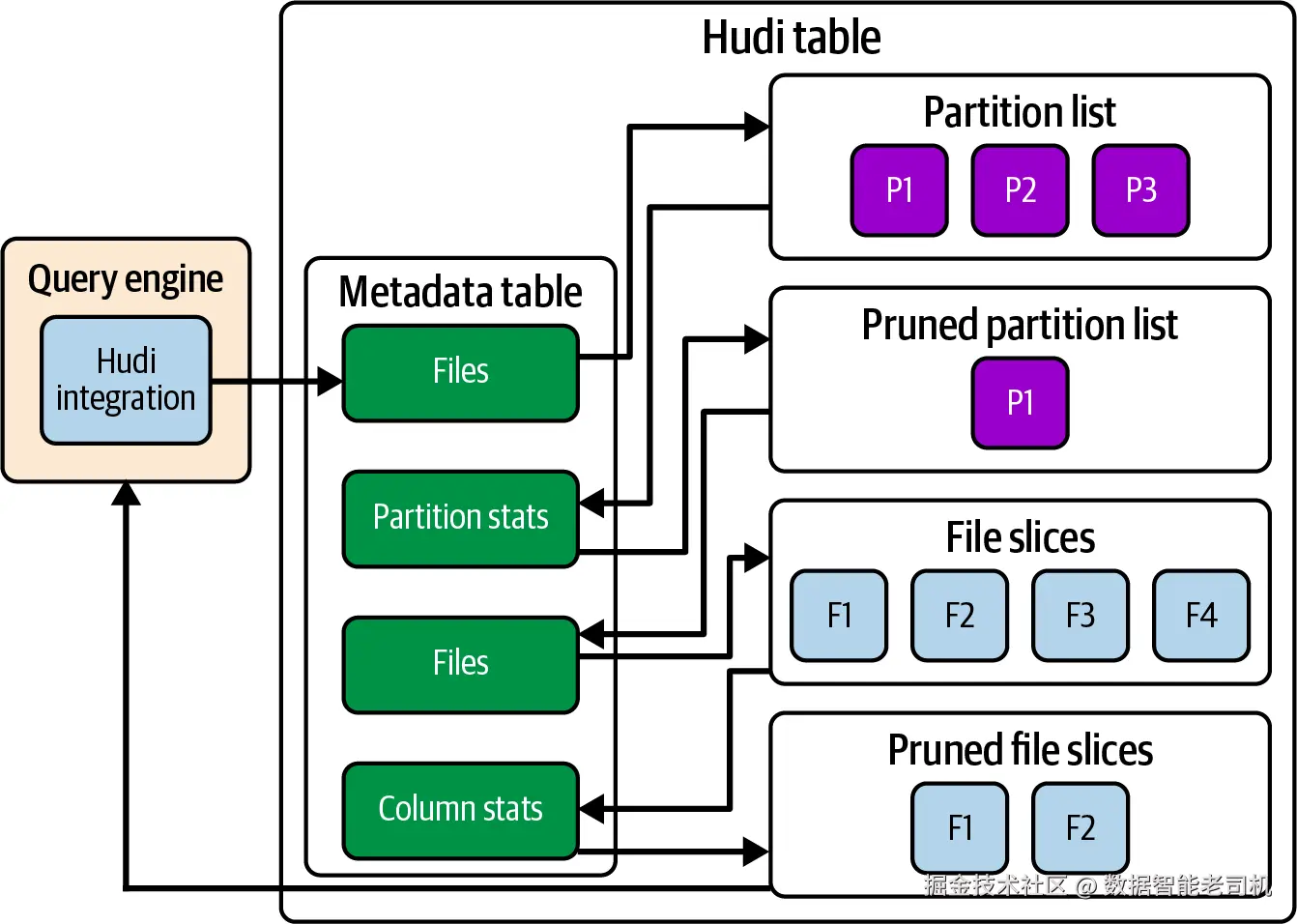
图 5-10. 文件裁剪流程
- 查询 files 索引 以获取分区列表。
- 根据传入的谓词,查询 partition stats ,裁剪超出统计范围 的分区;若谓词中包含具体分区值,则可直接选择或过滤对应分区。
- 用裁剪后的分区集合再次查询 files 索引 ,获取这些分区内的文件列表。
- 基于谓词对文件进一步应用 column stats 裁剪。
- 将最终裁剪后的文件列表返回给查询引擎继续处理。
默认情况下,前 32 列会被纳入 column stats 与 partition stats 的索引与存储,以避免在拥有数百列的"宽表"上引入不必要的索引开销。可通过如下配置调整上限:
ini
hoodie.metadata.index.column.stats.max.columns.to.index=20在很多场景中,为特定列 建立统计索引更有意义。比如订单表 order 包含 price 与 shipping_date 等字段,若经常有 price > 300 或 shipping_date BETWEEN Date'2025-06-01' AND Date'2025-06-30' 的查询,就可以只为这两列建立索引:
ini
hoodie.metadata.index.column.stats.column.list=price,shipping_date注:当设置了
hoodie.metadata.index.column.stats.column.list后,hoodie.metadata.index.column.stats.max.columns.to.index将被忽略。
等值匹配(Equality Matching)
你的查询里可能包含等值匹配谓词,例如 A = X 或 B IN (X, Y, Z)。虽然文件裁剪在这类场景下也有效,但更高效的方法是直接定位 包含这些列值的精确文件切片。
记录索引(record index)
在前文中你已了解到,记录索引 存储了"记录键 → 所在文件切片"的精确映射。它不仅能帮助 Hudi 写入端为数据写入找到目标文件组,也能在读端对以记录键字段为左操作数的等值匹配谓词加速查询。
只要已启用并生效记录索引,带有相应等值谓词的查询就会被其优化------直接使用映射出的文件切片进入后续裁剪与执行阶段,从而整体加快规划过程。
二级索引(secondary index)
当查询谓词对非记录键字段 做等值匹配(例如 name = 'X')时,记录索引就无法直接定位相关文件。为此,Hudi 提供二级索引。二级索引的作用类似倒排索引:存储"某个非记录键字段的取值 → 对应记录键集合"的映射。
对于带有可用谓词的查询,Hudi 会先查询二级索引以取回匹配的记录键集合 ,然后再借助记录索引 找到包含这些记录键的具体文件切片 。因此,启用二级索引的前提是已启用记录索引。
例如,在 user_profile 表中,有一条记录 id = '001'、name = 'X'。若在 name 列上创建了二级索引,就会生成 'X' -> '001' 的映射。查找 name = 'X' 时,会先在二级索引中高效得到记录键 '001',再通过记录索引定位这条用户记录所在的精确文件切片。
你可以在不同的非记录键字段上创建多个二级索引:
arduino
CREATE INDEX idx_on_name ON user_profile (name);对于每个二级索引,Hudi 会在元数据表中创建一个以 secondary_index_ 为前缀的专用分区来存放索引条目。CREATE INDEX 中提供的名称(如 idx_on_name)也会成为该分区名的一部分,便于管理多个索引。需要注意,名称 record_index 为保留名,不能使用。
删除二级索引可使用:
ini
DROP INDEX idx_on_name ON user_profile;元数据表的基文件采用 HFile 格式对二级索引尤为有利:其按字典序排序的键 支持高效的前缀查找 ,适用于"同一二级键值对应多个记录键"的情况。不过,二级索引在高基数列 (unique 值多)上效果最佳,此时 1:1 或高选择性的映射能显著缩小候选文件切片集合。对于低基数列 (如布尔类型),二级索引的裁剪能力有限;Hudi 社区正在推进 bitmap 索引 以更好地覆盖低基数场景。
表达式索引(Indexing on Expressions)
查询谓词里常会对列做内联变换,例如:
sql
SELECT * FROM user_profile
WHERE from_unixtime(update_ts, 'yyyy-MM-dd') = '2025-06-01';在这种情况下,单纯对 update_ts 建立的 column stats 索引并不奏效,因为谓词作用于 from_unixtime 的函数结果而非原始列值。为此专门增加一个派生列既占空间,又在格式变化时失效。
Hudi 提供表达式索引(expression index) ,将数据跳过能力扩展到带函数的谓词。
基于 column_stats 的表达式索引
创建 column_stats 类型的表达式索引,会指示 Hudi 对变换后的列值 预计算并存储统计信息。以 user_profile 为例:
ini
CREATE INDEX update_date ON user_profile
USING column_stats(update_ts)
OPTIONS(expr='from_unixtime', format='yyyy-MM-dd');创建后,Hudi 会为每个文件切片预计算 from_unixtime(update_ts, 'yyyy-MM-dd') 的 min/max 。当出现匹配的查询时,文件裁剪流程即可利用这些专用统计像常规 column stats 一样进行高效跳过。
每个表达式索引会在元数据表中建立一个以 expr_index_ 为前缀的专用分区。删除索引使用:
ini
DROP INDEX update_date ON user_profile;该类型支持的函数较广,包括 lower、regexp_extract、concat 等。完整列表可参见官方文档。
基于 bloom_filter 的表达式索引
表达式索引也可指定为 bloom_filter 类型:为每个文件切片基于变换后的列值 构建 Bloom 过滤器,用于加速等值检查。例如,支持不区分大小写的查找:
ini
CREATE INDEX idx_bloom_name ON user_profile
USING bloom_filters(name) OPTIONS(expr='lower');
DROP INDEX idx_bloom_name ON user_profile;该索引会为每个文件存储小写化后的 name 值 的 Bloom 过滤器。带有 WHERE lower(name) = 'x' 的查询即可借此快速排除 不含 'x' 的文件切片。
与二级索引相似,bloom_filter 表达式索引在高基数列 上最有效:唯一值越多,某个值不存在 于某文件切片的概率越高,从而带来更多的跳过机会。若结合聚类(clustering)表服务(第 6 章将介绍)按被索引列进行排序,可将相似值集中到更少的文件切片内,进一步提升可跳过的切片数量与查询效率。
构建合适的索引(Build the Right Indexes)
元数据表为查询引擎提供了强大而通用的索引框架,帮助其充分优化查询计划。但务必根据你的数据与查询模式谨慎选择并构建索引 。不必要的索引会在每次提交(commit)时都被维护,从而拖慢写入,却未必能为读性能带来相应收益。
对存储开销 要格外留意,尤其是记录索引(record index)与二级索引(secondary index) ,它们的体量会随表中记录数量线性增长 。如果在过多列上创建二级索引,会导致过度的存储消耗。
同时要注意能力重叠 。二级索引 与基于 bloom_filter 的表达式索引 都能加速等值匹配谓词 。对同一列,通常只需其一 。二级索引通常表现更佳,因为它能将搜索精确缩小 到包含目标数据的具体文件切片 ;而 Bloom 过滤器只能增强候选文件切片的裁剪 。二者的权衡在于存储 :二级索引更精确,但以 O(记录数) 的代价占用更多空间;而文件级 Bloom 过滤器更节省空间。
总结(Summary)
本章从写入端索引 切入,强调对通用且高性能 索引的需求,并引出了其基础------元数据表 ,这是 Hudi 最强索引能力的承载。我们介绍了记录索引 ,它在大多数工作负载下都能提供快速、可扩展的性能;并与基于哈希的轻量级存桶索引(bucket index)进行了对比。随后针对特定写入模式,介绍了用于随机更新 的基于连接的 simple 索引 ,以及用于偏斜更新 、基于过滤 + 连接 的 bloom 索引 。最后我们汇总对比了这些写入索引,并讨论了**全局(global)与非全局(nonglobal)**作用域的关键区别。
在读路径上,我们继续围绕元数据表的多模(multimodal)能力 展开:展示了files、column stats、partition stats 三类索引如何协同,实现基于范围谓词 的高效文件裁剪。对于等值匹配 ,我们指出记录索引 同样能加速读取,并引入二级索引 以支持对非记录键字段 的快速查找。最后,我们将裁剪能力扩展到带函数的谓词 ,引入表达式索引(expression index) :它既支持 column_stats 类型,也支持 bloom_filter 类型,从而覆盖更广泛的查询模式。
Hudi 的索引能力仍在不断演进,以应对新挑战。社区正积极开发诸如位图索引(bitmap index) (用于低基数字段的高效过滤)和向量检索索引(vector search index) (支持 AI 场景中对非结构化数据的相似度检索)等新特性。元数据表灵活的架构为这些能力提供了稳健且可扩展的基础,确保 Hudi 能够在未来持续吸纳并推进多样化的索引形态。