一、把数据集划分成训练集、验证集和测试集?
我们通常将数据集划分为训练集、验证集和测试集,每个部分都有其特定的作用
-
训练集(Training Set):模型直接从这个数据集学习特征和模式。
-
用于训练模型,即通过训练集的数据来学习模型的参数(如权重和偏置)。
-
模型在训练集上通过反向传播和优化算法(如Adam)来最小化损失函数。
-
-
验证集(Validation Set):模型不直接从这个数据集学习,但影响训练决策。
-
用于在训练过程中评估模型的表现,以便进行模型选择和调参。
-
通过验证集,我们可以监控模型在未见过的数据上的表现,避免过拟合。
-
例如,我们可以根据验证集上的表现来决定早停(Early Stopping)的时机,或者调整超参数(如学习率、隐藏层维度等)。
-
-
测试集(Test Set):在整个训练过程中完全不被使用,确保评估的客观性。
-
用于最终评估模型的泛化能力。测试集在训练过程中完全不被使用,直到训练结束。
-
测试集上的表现反映了模型在真实世界中未知数据上的表现。
-
注意:由于在训练时需要前向传播求损失,然后再反向传播更新模型参数;而在验证时仅仅通过前向传播求验证损失。
在下面的任务中我们就是为了设置早停策略,通过比较验证损失val_loss来保存最佳
为什么要把训练集再分成训练集和验证集?


- 如果我们只使用训练集和测试集,那么我们在训练过程中无法知道模型是否过拟合了训练集。因为测试集只能用于最终评估,我们不能使用测试集来调整模型或选择模型,否则会导致测试集被间接地用于训练,从而高估模型的泛化能力。
只有训练损失与验证损失同时递减,才能说明模型泛化能力好;
如果训练损失在下降,而验证损失一直不下降说明如果再继续训练就会出现过拟合了,这个时候要提前停止训练并保存最优模型(验证损失最低的)。
- 使用验证集,我们可以在训练过程中定期评估模型,根据验证集上的表现来调整超参数,并选择最佳的模型。然后,我们使用测试集来评估最终模型的泛化能力。
训练集+验证集+测试集 VS 训练集+测试集的区别:
-
训练集+验证集+测试集:我们将原始数据分成三部分,训练集用于训练,验证集用于模型选择和调参,测试集用于最终评估。这是一种标准的做法,可以更好地评估模型的泛化能力。
-
训练集+测试集:我们只将数据分成两部分,训练集用于训练,测试集用于评估。这种情况下,我们无法在训练过程中使用验证集来监控模型和调参 ,容易导致过拟合,并且无法进行模型选择(比如早停)。
二、LSTM实战案例(模型逆向攻击日志数据集)
0.导入相关的库。
这里面有一个新见的库:seaborn 用于绘制混淆矩阵的热力地图。
Seaborn 是一个基于 matplotlib 且数据结构与 pandas 统一的统计图制作库。
1.加载数据集

上面是图片是我的特征向量和标签的json格式的数据集文件,由于数据集加载这部分不是本章重点,所以不再赘述。
假设现在已经通过一个封装好的load_data()方法,已经返回了特征向量X和标签y。其中X.shape(200,150,7)、y.shape(200,)
2.划分数据集(80%训练+20%验证, 30%测试)
一次划分:先划分出来训练集和测试集(7:3)

二次划分:再从训练集中划分出验证集(8:2)

返回X_train、y_train;X_val、y_val;X_test、y_test;
3.特征缩放(标准化)
对X_train、X_val、X_test分别进行标准化处理,返回X_train_scaled、X_val_scaled、X_test_scaled。

具体过程:以X_train为例,X_train.shape为(112,150,7)
1.首先,先将三维的X_train通过reshape(-1,7)方法转换为2D数组。
(-1,7) 等价于(112*150,7)
2.使用fit_transform()方法计算均值和标准差,并转换数据。
fit_transform()方法 == 先使用fit()方法 + 再使用transform()方法
- fit()方法:计算均值和标准差,以便后续的缩放操作。它不会对数据进行转换,只是计算并存储这些参数。
- transform()方法:转换数据。
3.再通过reshape(X_train.shape)方法还原回来特征形状。
注意:在训练集上使用fit_transform(),在测试集和验证集上只使用transform()

4.创建 DataLoader批次加载器
接下来我们需要将(X_train_scaled, y_train)、(X_val_scaled, y_val)、(X_test_scaled, y_test)分别传入我们自定义的DataSe类,分别返回train_dataset、val_dataset、test_dataset;
再将train_dataset、val_dataset、test_dataset传入torch.utils.data.DataLoader类,分别返回train_loader、val_loader、test_loader。
为什么要这样做?这个知识点详细请跳转到下面这篇博客中的三、小批量梯度下降章节https://blog.csdn.net/m0_59777389/article/details/153636175?spm=1011.2124.3001.6209
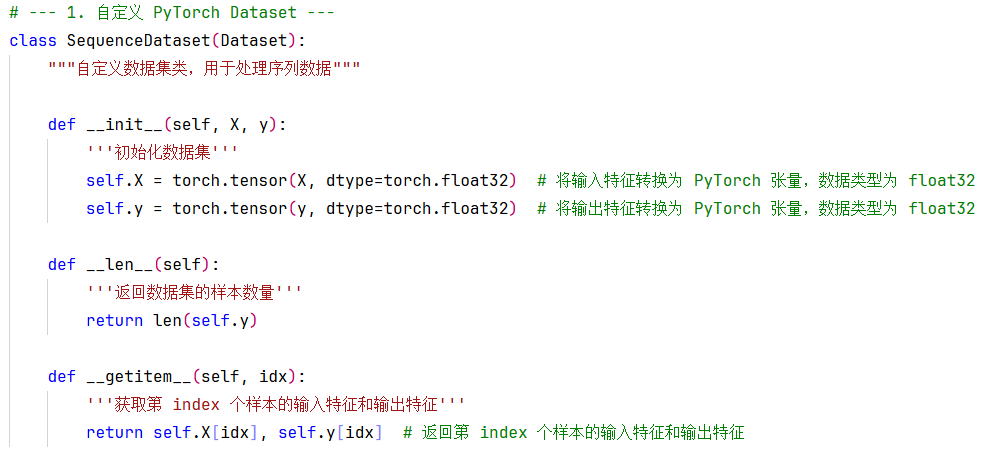
在封装我们的数据集时,必须继承实用工具(utils)中的 DataSet 的类,这个过程需要重写__init__、getitem、__len__三个方法,分别是为了加载数据集、获取数据索引、获取数据总量。

5.构建模型(重点)
"""自定义LSTM分类模型
参数:
input_dim: 输入特征的维度
hidden_dim: 隐藏层的维度
output_dim: 输出层的维度(通常为1,因为这是一个二分类问题)
n_layers: LSTM层的数量
dropout: Dropout层的dropout概率
"""
init()方法:主要是用于初始化模型参数的,并且搭建整个神经网络模型的。如下图所示:

这里的神经网络模型结构为:
->nn.LSTM(input_dim, hidden_dim, n_layers,batch_first=True, dropout=dropout) # 定义LSTM层
->nn.Dropout(dropout) # 定义Dropout层(作用:防止过拟合)
->nn.Linear(hidden_dim, output_dim) # 定义全连接层(将hidden_dim映射到output_dim)
->nn.Sigmoid() # 定义Sigmoid激活函数(将输出映射到(0,1)区间)
在定义LSTM层时我将batch_first=True了,但是__init__()的参数中我并没有指定batch_first参数,这样写对吗?另外你再解释一下batch_first=True是什么意思?有什么作用?
答:
1.batch_first=True是什么意思?
在PyTorch中,LSTM层的输入默认维度顺序是(seq_len, batch, input_size),即序列长度在前,批次大小在后。
但是,当我们设置
batch_first=True时,输入和输出的维度顺序将变为(batch, seq_len, input_size),即批次大小在前。
当
batch_first=False(默认值)时:输入形状: (seq_len, batch, input_size)
输出形状: (seq_len, batch, hidden_size)
当
batch_first=True时:输入形状: (batch, seq_len, input_size)
输出形状: (batch, seq_len, hidden_size)
2.为什么我们要使用
batch_first=True呢?通常,我们的数据组织方式是以批次为第一个维度的,比如我们有一个张量,形状为(batch_size, sequence_length, features)。这样更符合我们的直观理解,因为我们在处理数据时通常先按批次处理。
例如,我们有一个包含32个样本的批次,每个样本有10个时间步,每个时间步有5个特征,那么我们的输入张量形状就是(32, 10, 5)。
如果我们使用默认的
batch_first=False,那么我们需要将输入张量转换为(10, 32, 5)才能输入LSTM层,这可能会带来一些不便。因此,设置
batch_first=True可以让我们避免在输入LSTM之前调整维度顺序,使得代码更加直观。3.在定义LSTM层时我将batch_first=True了,但是__init__()的参数中我并没有指定batch_first参数,这样写是正确的,本来就应该这样写。
不需要 在
__init__方法参数中添加batch_first,因为:
batch_first是LSTM层的参数,不是模型类的参数(用于外部传参,可以改变的)你在创建LSTM层时已经直接设置了它(内部固定写死的)
总之,一般使用DataLoader批量加载数据的时候,都要在定义nn.LSTM层时设置batch_first=True
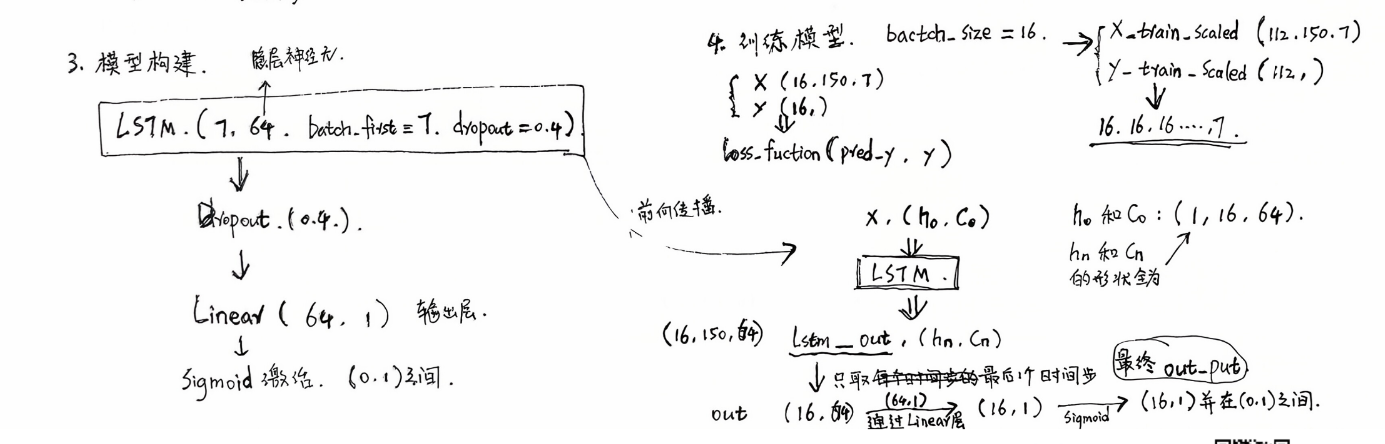
forward()方法:用于前向传播过程中,具体的操作。

在上图中我们可以看到,
首先需要初始化隐藏状态h0和细胞状态c0(这里是用0填充的)并将h0和c0放到GPU上,h0 和 c0 的形状: (n_layers, batch_size, hidden_dim);
然后将x, (h0, c0)输入到LSTM,返回lstm_out, (hn, cn);(这个过程比较复杂,如果感兴趣请去看LSTM的原理,这里我们不赘述)
接着,我们需要通过**lstm_out:, -1, :**操作取每个序列的最后一个时间步的输出last_lstm_out;(-1表示序列的最后一个时间步的下标),通过这个操作相当于降维了:lstm_out(16,150,64) -> last_lstm_out(16,64)。
注意:取每个序列的最后一个时间步的输出last_lstm_out之后,要记得对last_lstm_out使用dropout,防止过拟合。
最后就是分别通过全连接层、再通过Sigmoid激活函数,此时返回形状为 (batch_size, 1);
我在这里做了一个squeeze操作,移除了最后一个维度,形状变为 (batch_size,)。这是因为真实标签是一维数组,为了后面在做测试的时候,让模型输出的pred_y与真实标签y维度一致。(当然这里也可以直接返回通过Sigmoid激活函数之后的输出,不做squeeze操作,不过后面在做测试的时候需要把真实标签y的形状reshape成二维的列向量就行了)
想要深入了解LSTM模型构建的话请跳转:https://blog.csdn.net/m0_59777389/article/details/149350040?spm=1011.2124.3001.6209
6.训练模型
训练模型前,需要提前初始化模型、并指定损失函数和优化器。
并将模型移动到GPU上。

输出的模型结构如下图:



由上图可以看出,
1.训练与验证是在同一个epoch中进行的,顺序是先训练后验证。但是训练和验证又分别在各自的DataLoader中分批进行的。
2.训练过程需要进行前向传播求损失,又要反向传播更新梯度;但是验证过程仅仅只需要前向传播求损失。
3.以往的案例中我都是直接losses.append(loss.item()) 将损失添加到列表中,为了后面打印损失变化曲线。在这里为啥要做累加每个批次的损失的操作?
train_loss += loss.item() * inputs.size(0) # 累加每个批次的损失(乘以样本数)
这行代码没看懂,为什么要累加每个批次的损失(乘以样本数)?这样做的目的是啥?
答:
在PyTorch中,
nn.BCELoss()默认返回的是**批次内所有样本的平均损失;**而我们通常计算一个epoch的平均损失时,是用该epoch的总损失除以样本总数。但是,由于我们每个批次的样本数可能不同(最后一个批次可能小于batch_size),所以我们需要记录每个批次的损失乘以该批次的样本数,这样累加后得到的就是整个epoch的总损失。
然后,在计算平均损失时,我们用总损失除以总样本数(即len(train_loader.dataset))。
train_loss += loss.item() * inputs.size(0) # 累加每个批次的损失(乘以样本数)
loss.item(): 获取当前批次的平均损失值
inputs.size(0): 获取当前批次的样本数量
loss.item() * inputs.size(0): 将平均损失转换为批次总损失
这样操作是为了:
正确处理不同批次大小(特别是最后一个批次可能不满)
准确计算整个数据集的平均损失
确保损失统计的数学正确性
这是一种标准的PyTorch训练模式,确保损失计算的准确性!

7.测试模型

1.之前的案例中,我们在测试过程中,将概率转换为类别 (0或1)的时候,都是将二维数组先进行布尔判断,然后再赋值的方式将模型的输出结果转换成0或1的,如下:

但是,在这里有一个更加巧妙的方法:

直接通过float()方法可以将为True的位置直接转成1,为False的位置转成0;
2.all_preds.extend(preds.cpu().numpy()) # 转换为 numpy 数组并添加到列表中
这行代码我没看懂?请一步一步的拆解。
答:
我们一步步拆解这行代码:all_preds.extend(preds.cpu().numpy())
**
preds:**这是一个PyTorch张量,包含了一个批次的预测结果(0或1)。**
cpu():**将张量从当前设备(可能是GPU)移动到CPU。如果张量已经在CPU上,这个操作不会改变什么,但为了安全起见,我们通常这样做以确保张量在CPU上,因为numpy数组只能在CPU上处理。
numpy():将PyTorch张量转换为NumPy数组。**
preds.cpu().numpy()**的结果是一个NumPy数组,其形状为(batch_size,),因为每个样本有一个预测值。
all_preds是一个Python列表,用于收集所有批次的预测结果。**
.extend():**这是Python列表的一个方法,用于将可迭代对象(如数组)中的每个元素添加到列表的末尾。所以,这行代码的意思是将当前批次的预测结果(一个NumPy数组)中的每个元素依次添加到
all_preds列表中。举例说明:
假设一个批次有3个样本,preds.cpu().numpy()得到数组:0, 1, 0
如果all_preds原来是1, 0,那么执行后all_preds变为1, 0, 0, 1, 0
extend()与append()的区别:
append()方法是将整个对象作为单个元素添加到列表末尾。如果使用append,那么上述例子就会变成:all_preds.append(0,1,0) -> 1, 0, \[0, 1, 0],这显然不是我们想要的。
因此,当我们想要将一个可迭代对象中的每个元素单独添加到列表中时,使用extend;当我们想要将整个对象作为一个元素添加时,使用append。
在机器学习中,我们通常使用extend来收集所有批次的预测结果,以便最后形成一个一维的列表,包含所有样本的预测。
最后就是打印评价指标了:
