资源下载:https://download.csdn.net/download/vvoennvv/92360949
目录
一,概述
传统的单一RNN或LSTM时序预测模型在处理高维、多步预测任务时,常出现局部依赖捕捉不足、长距离信息衰减以及对不同时间片贡献无法区分等问题。为提升预测精度与鲁棒性,当前模型将卷积神经网络(CNN)、双向长短期记忆网络(BiLSTM)与注意力机制(Attention)进行融合,构建出一个 CNN-BiLSTM-Attention 组合模型,用于多特征输入的多步电力负荷(或类似时序变量)预测。
整体思想:CNN负责从局部时间窗口中提取短期形态与局部模式;BiLSTM双向捕捉前后时序关联以缓解信息单向流动的不足;注意力机制自适应分配不同时间步的权重,突出对未来预测更关键的时刻特征;最后通过全连接层输出多步预测结果。该融合结构能在保持局部与全局时序信息的同时,提高对关键时间片的判别能力,从而获得更精确、稳定的多步预测表现。
CNN-BiLSTM-Attention算法的流程如下:
(1)数据准备:首先,我们需要准备历史数据作为训练集。
(2)数据预处理:对于训练集中的数据,我们需要进行一些预处理操作,比如去除异常值、归一化等,以提高预测模型的准确性。
(3)网络构建:根据预处理后的训练集,我们构建CNN-BiLSTM-Attention网络模型。该模型包括输入层、局部特征提取(CNN)、序列双向编码(BiLSTM)、注意力机制(Attention)和输出层。
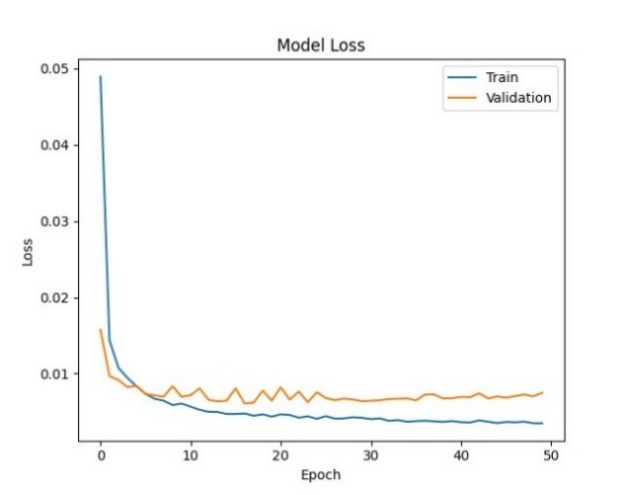
(4)模型训练:采用 MSE 作为回归损失,Adam 优化器提升收敛速度与鲁棒性,同时监控 MAE 作为评估指标。
(5)模型评估:在训练完成后,我们需要对模型进行评估。这可以通过将训练集中的一部分数据作为测试集,来计算模型的预测误差和准确率。
CNN-BiLSTM-Attention 模型通过"局部模式 + 双向序列 + 动态注意力"三者协同,提升了多特征、多步时序预测的精度与稳定性。其结构在保证表达能力的同时保持较好的可解释性与拓展空间,是面向复杂时序预测任务的一种有效组合范式。
二,代码
代码中文注释非常清晰,按照示例数据修改格式,替换数据集即可运行,数据集可以是csv或者excel表格。
部分代码如下:
if __name__ == "__main__":
warnings.filterwarnings("ignore") # 取消警告
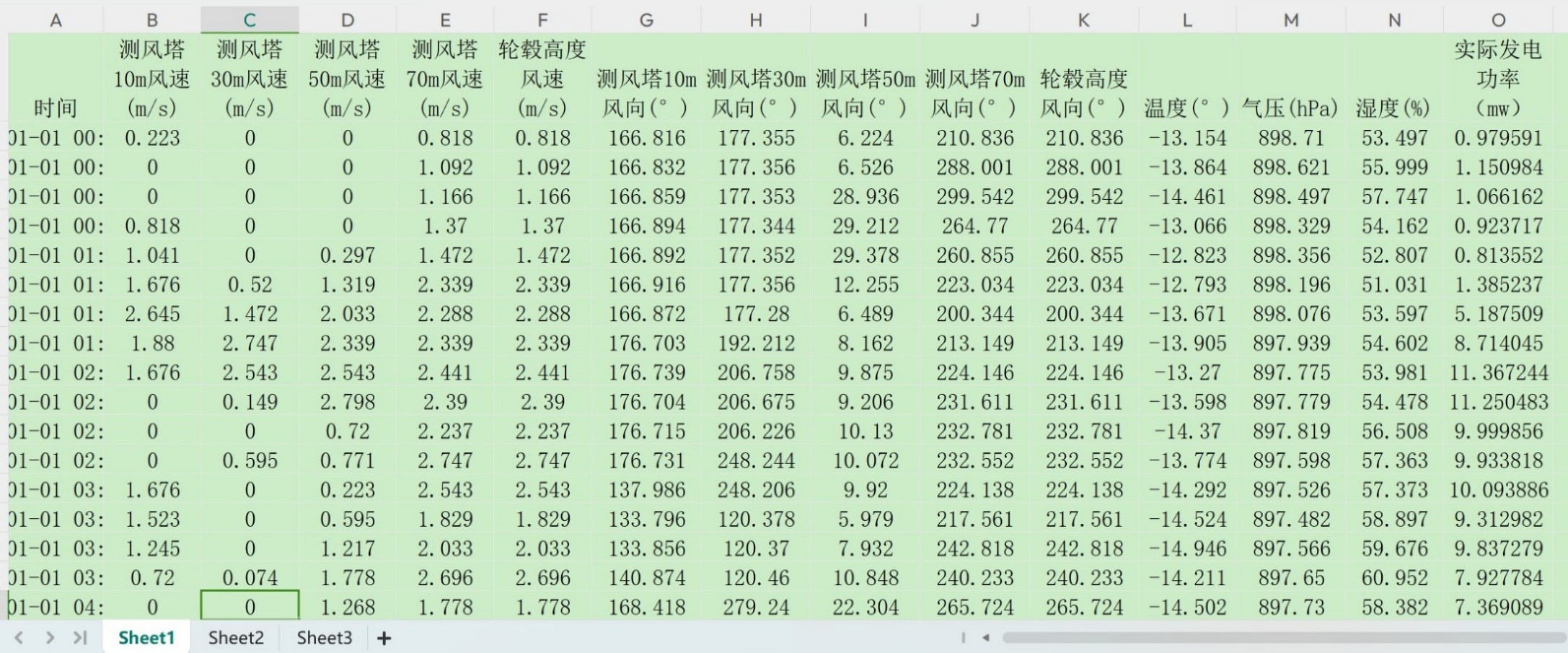
# 使用pandas模块的read_csv函数读取名为"电力负荷预测数据.csv"的文件。
# 参数 'encoding' 设置为 'gb2312',这通常用于读取中文字符,确保文件中的中文字符能够正确读取。
# 读取的数据被存储在名为 'dataset' 的DataFrame变量中。
dataset = pd.read_csv("电力负荷预测数据.csv", encoding='gb2312')
# 下面是读取xlsx的方式,根据实际数据集文件选择是read_csv还是read_excel
# dataset = pd.read_excel("数据集.xlsx", sheet_name='Sheet1', header=0)
print(dataset) # 显示dataset数据
# 从dataset DataFrame中提取数据。
# dataset.values将DataFrame转换为numpy数组。
# [:,1:],逗号前是行,逗号之后是列。这个表示选择所有行(:)和从第二列到最后一列(1:)的数据。
# 这样做通常是为了去除第一列,这在第一列是索引或不需要的数据时很常见。
# 只取第2列数据,要写成1:2;只取第3列数据,要写成2:3,取第2列之后(包含第二列)的所有数据,写成 1:
# 单输入单步预测,就让values等于某一列数据,n_out = 1,n_in, num_samples, scroll_window 根据自己情况来
# 单输入多步预测,就让values等于某一列数据,n_out > 1,n_in, num_samples, scroll_window 根据自己情况来
# 多输入单步预测,就让values等于多列数据,n_out = 1,n_in, num_samples, scroll_window 根据自己情况来
# 多输入多步预测,就让values等于多列数据,n_out > 1,n_in, num_samples, scroll_window 根据自己情况来
values = dataset.values[:, 1:]
# 如果第一列不是索引,需保留全部列的数据时,则使用下面这句代码,并把上面那句代码屏蔽
# values = dataset.values[:, :]
# 确保所有数据是浮点数
# 将values数组中的数据类型转换为float32。
# 这通常用于确保数据类型的一致性,特别是在准备输入到神经网络模型中时。
values = values.astype('float32')
# 下面是多特征输入,多步预测的案例
n_in = 5 # 输入前5行的数据
n_out = 2 # 预测未来2步的数据
or_dim = values.shape[1] # 记录特征数据维度
# 默认是全部数据用于本次网络的训练与测试,也可以设定具体是数值,比如2000,这个数值不能超过实际的数据点
num_samples = values.shape[0] - n_in - n_out
# num_samples = 2000
scroll_window = 1 # 如果等于1,下一个数据从第二行开始取。如果等于2,下一个数据从第三行开始取
res = data_collation(values, n_in, n_out, or_dim, scroll_window, num_samples)
# 把数据集分为训练集和测试集
# 将前面处理好的DataFrame(data)转换成numpy数组,方便后续的数据操作。
values = np.array(res)
# 计算训练集的大小。
# 设置80%作为训练集
# int(...) 确保得到的训练集大小是一个整数。
n_train_number = int(num_samples * 0.8)
# 先划分数据集,在进行归一化,这才是正确的做法!
Xtrain = values[:n_train_number, :n_in * or_dim]
Ytrain = values[:n_train_number, n_in * or_dim:]
Xtest = values[n_train_number:, :n_in * or_dim]
Ytest = values[n_train_number:, n_in * or_dim:]
# 对训练集和测试集进行归一化
m_in = MinMaxScaler()
vp_train = m_in.fit_transform(Xtrain) # 注意fit_transform() 和 transform()的区别
vp_test = m_in.transform(Xtest) # 注意fit_transform() 和 transform()的区别
m_out = MinMaxScaler()
vt_train = m_out.fit_transform(Ytrain) # 注意fit_transform() 和 transform()的区别
vt_test = m_out.transform(Ytest) # 注意fit_transform() 和 transform()的区别
# 将训练集的输入数据vp_train重塑成三维格式。
# 结果是一个三维数组,其形状为[样本数量, 时间步长, 特征数量]。
vp_train = vp_train.reshape((vp_train.shape[0], n_in, or_dim))
# 将测试集的输入数据vp_test重塑成三维格式。
# 结果是一个三维数组,其形状为[样本数量, 时间步长, 特征数量]。
vp_test = vp_test.reshape((vp_test.shape[0], n_in, or_dim))
# 调用cnn_bilstm_attention_model函数来建立CNN-BiLSTM-Attention模型
model = cnn_bilstm_attention_model()
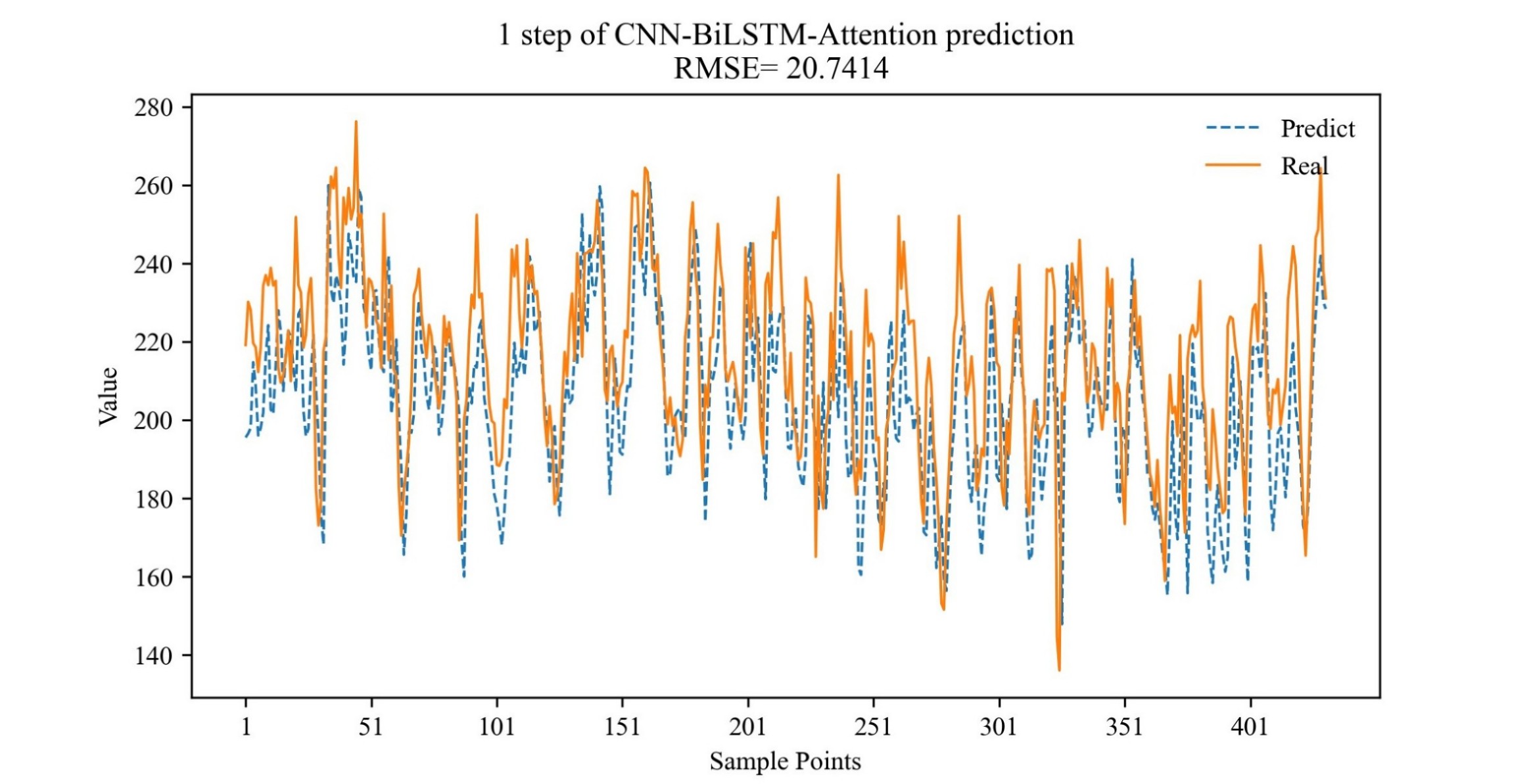
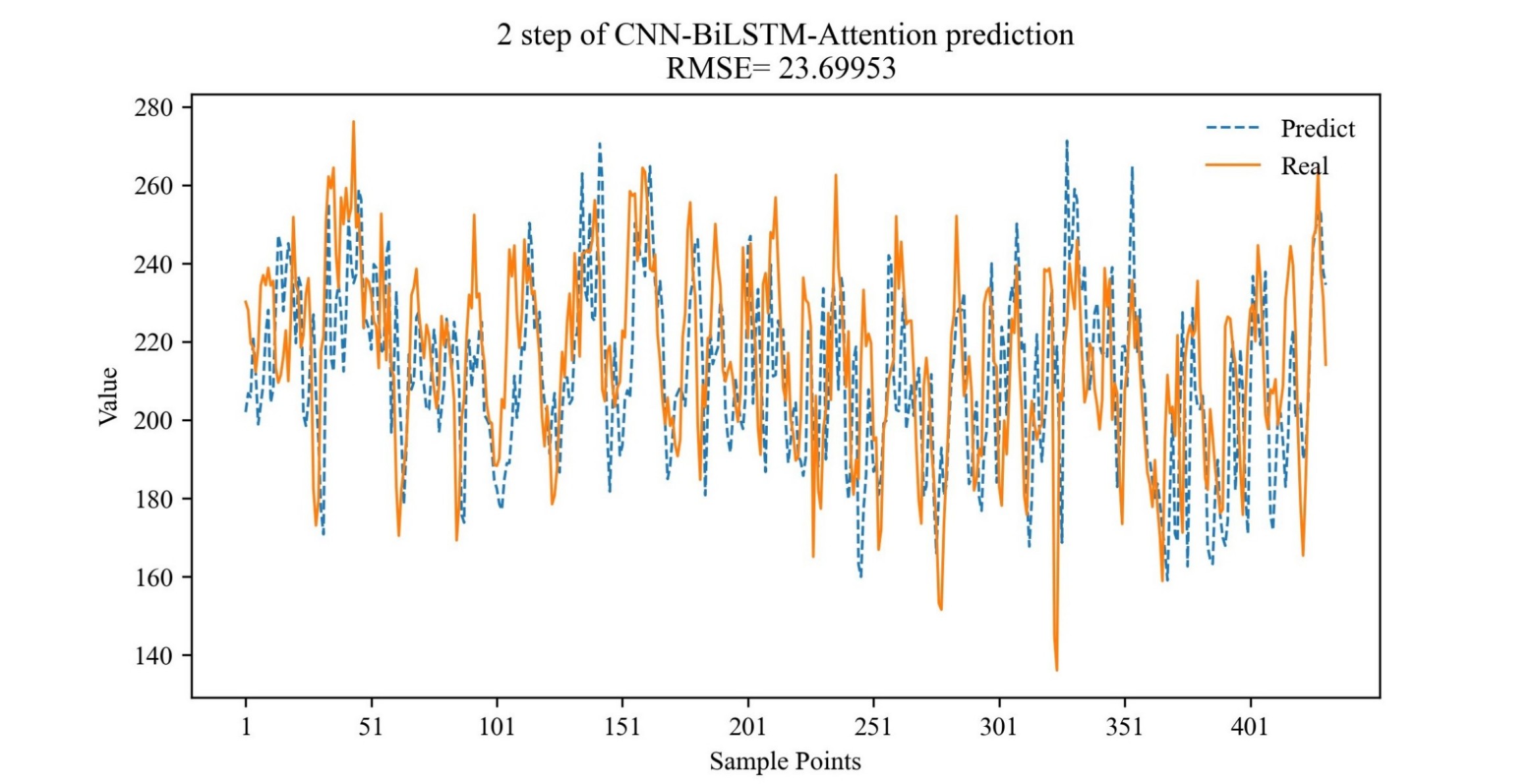
。。。。。。三,运行结果