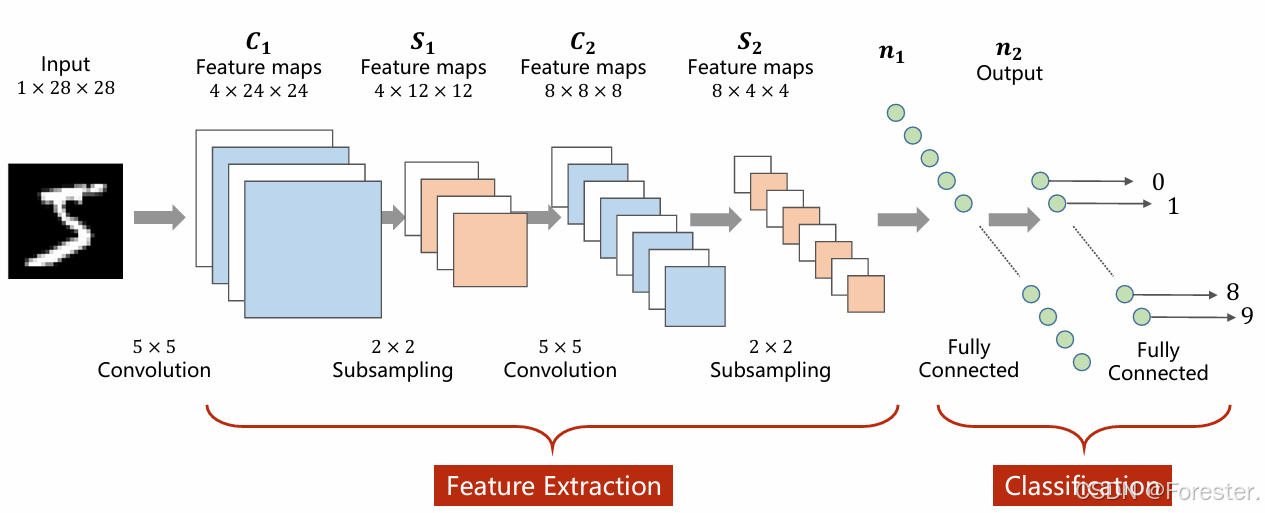
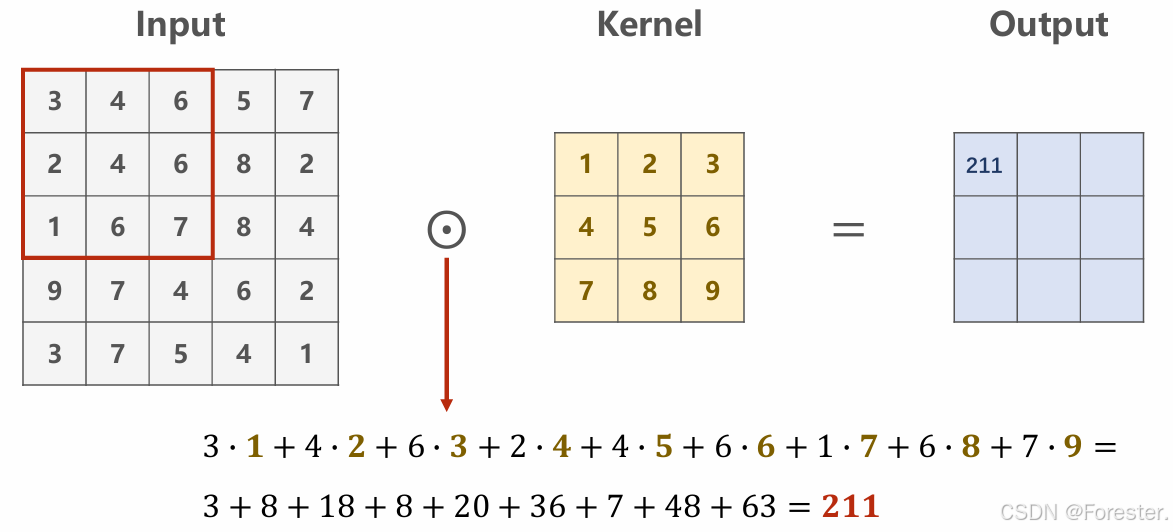
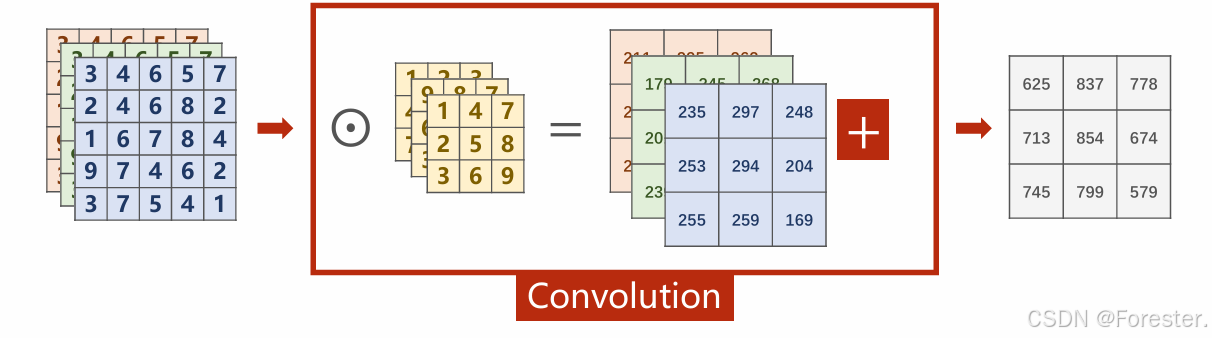
ReLU (Rectified Linear Unit)是目前 CNN 中最常用的激活函数:
f ( x ) = m a x ( 0 , x ) f(x)=max(0,x) f(x)=max(0,x)
原因:计算简单、收敛更快、不容易梯度消失。
1.5 全连接层(Fully Connected Layer,FC Layer)
"卷积层是特征提取器,全连接层是分类器。"
保留特征图(Feature maps)形式,是没有办法判断最终类别滴,仍然需要"展平"(Flatten),将其变为一维向量,便于建立类别映射(如下),计算输出概率值。
y j = f ( ∑ i w i j x i + b j ) y_j = f\left( \sum_i w_{ij} x_i + b_j \right) yj=f(i∑wijxi+bj)
二、深入CNN
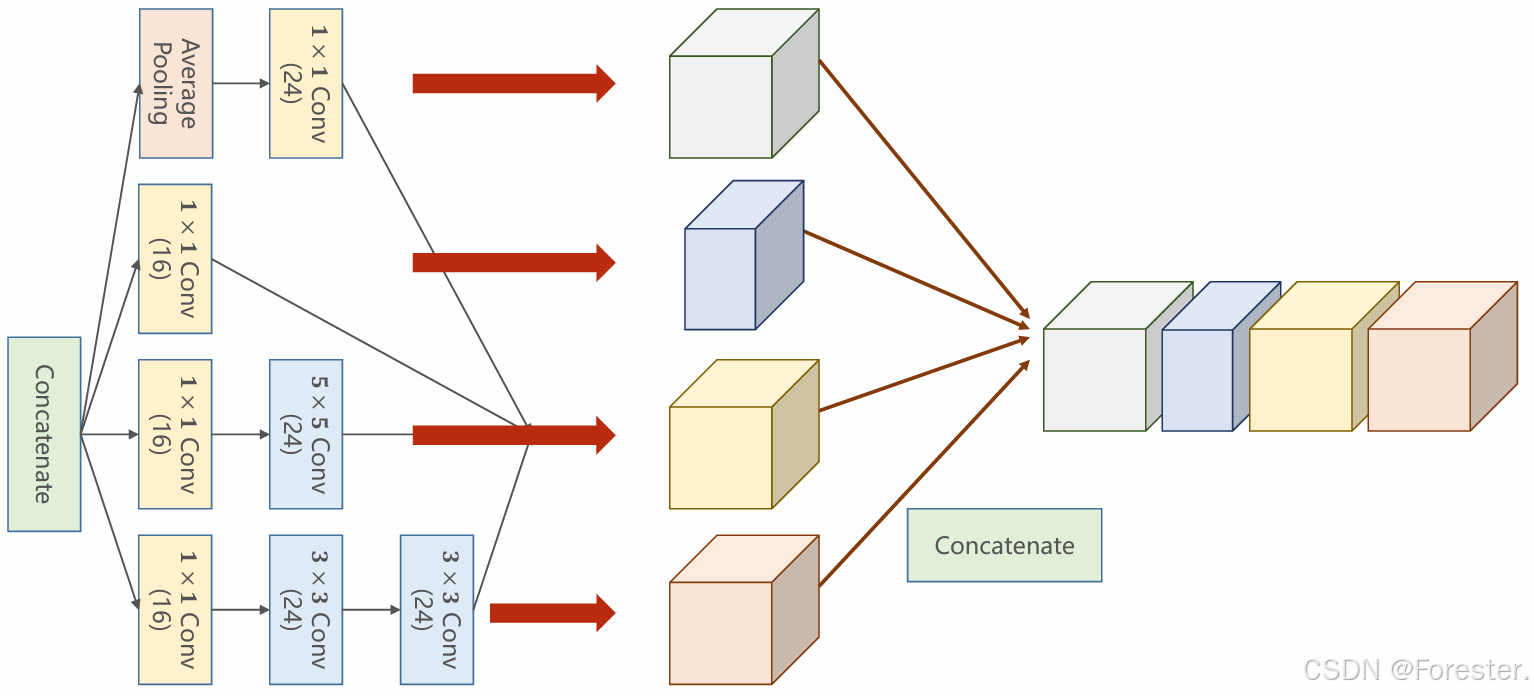
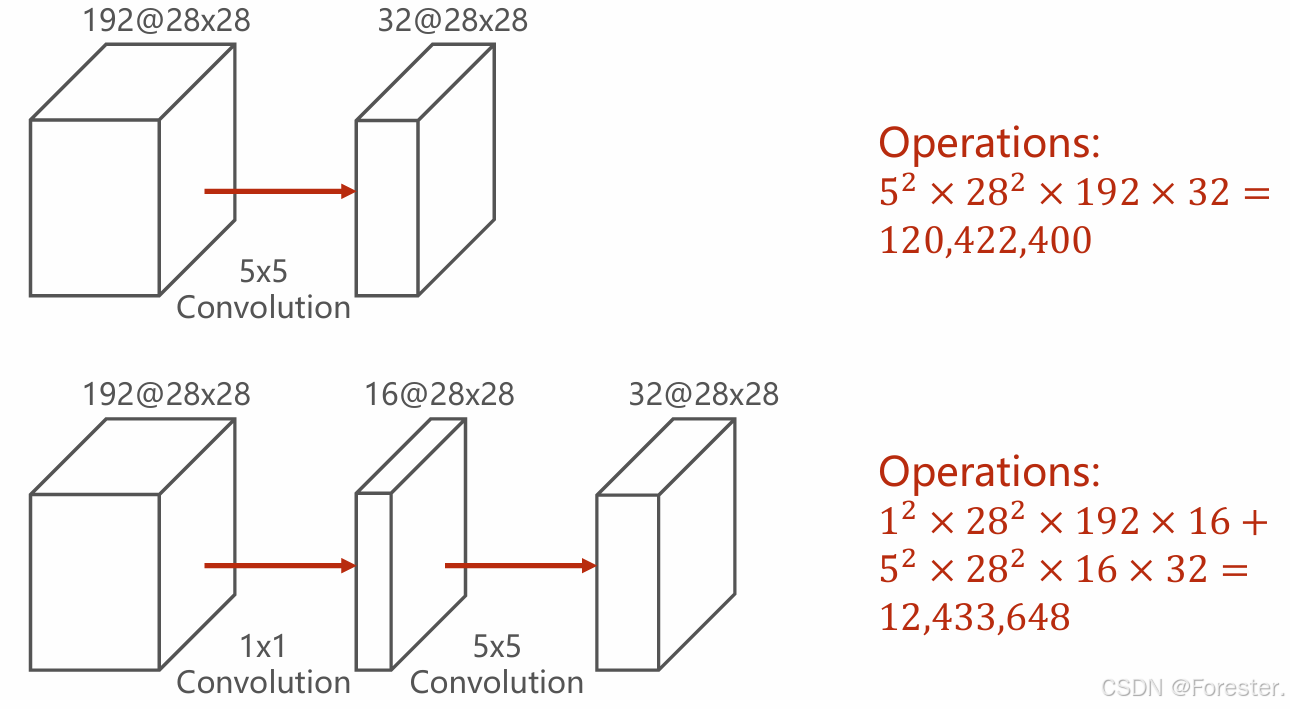
2.1 Inception Block
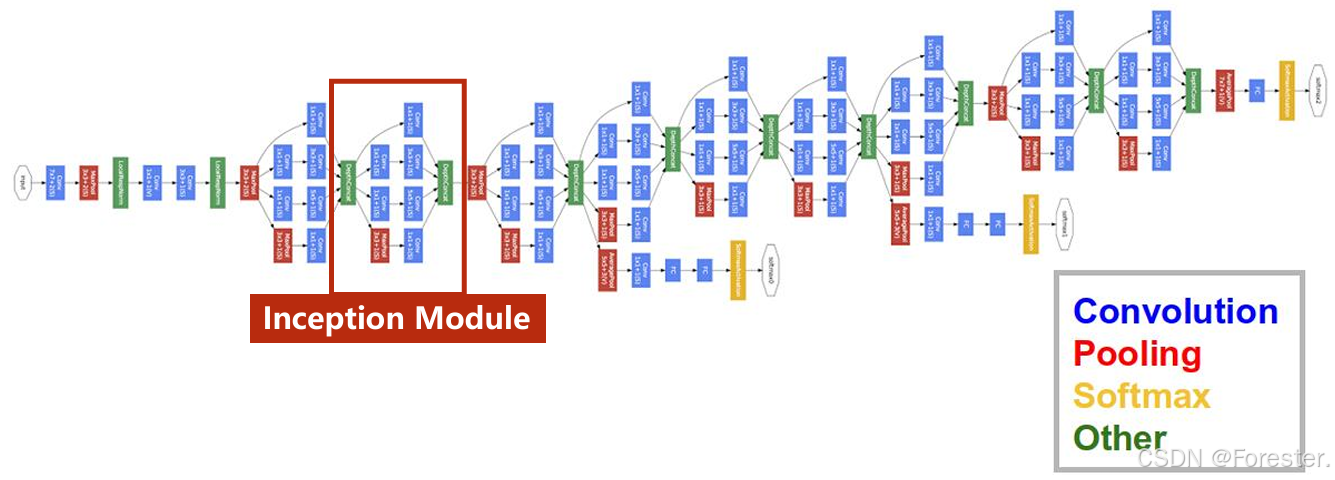
在学习完卷积神经网络常见的层次结构后,我们同样需要将其"组装"起来,以往我们学习到的神经网络设计模式都是线性,也就是将层次顺序链接起来,但实际应用中,往往需要功能更为复杂的设计模式,如下图(出自论文 《Going Deeper with Convolutions》,即 GoogLeNet ,这是 Google 在 2014 年提出的经典结构)。
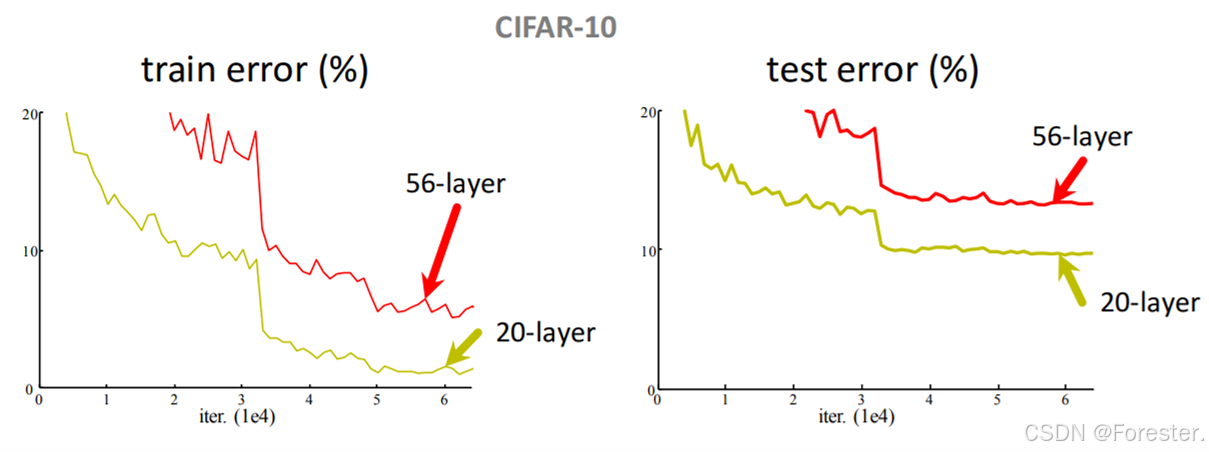
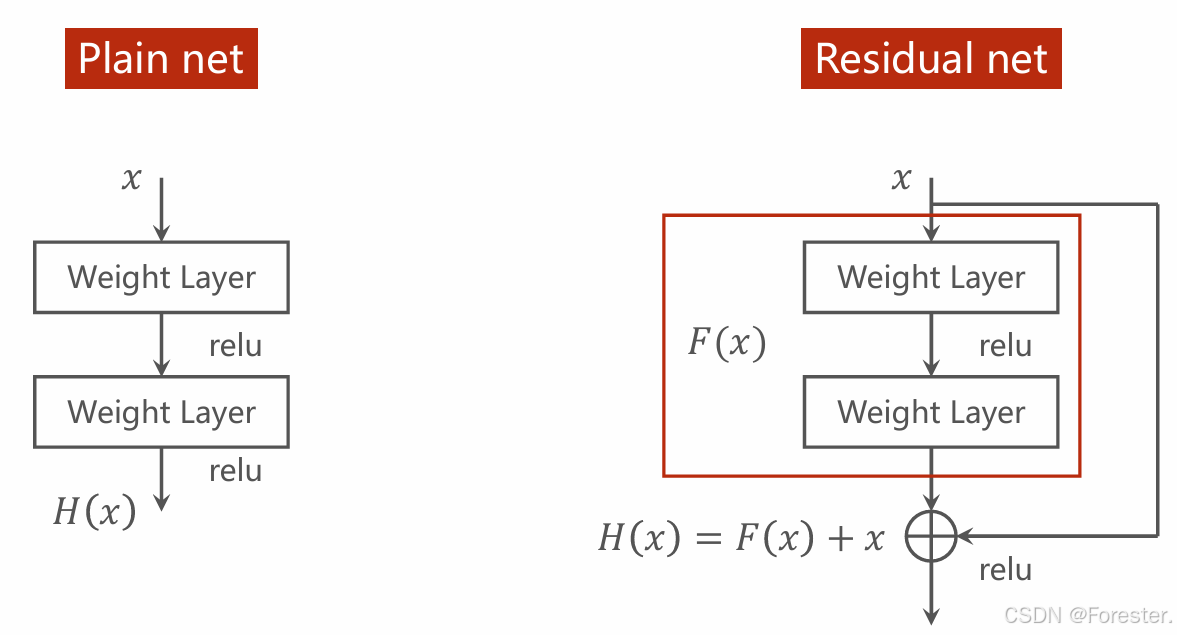
ResNet提出了一种新思想:让网络学习"残差"而不是直接学习映射 。残差定义为:
F ( x ) = H ( x ) − x F(x)=H(x)−x F(x)=H(x)−x
++这里的"残差"不同于损失函数中的残差++,因为它是映射函数输出减去输入而非真实y值,事实上我们也没法减去真实y值,ResNet在中间层而非输出层。
映射函数便为:
H ( x ) = F ( x ) + x H(x)=F(x)+x H(x)=F(x)+x
这样做为什么可以解决梯度消失问题?
很容易理解------ResNet结构中求梯度时绝对值永远大于等于1:
∂ H ( x ) ∂ x = ∂ F ( x ) ∂ x + 1 \frac{\partial H(x)}{\partial x}=\frac{\partial F(x)}{\partial x} +1 ∂x∂H(x)=∂x∂F(x)+1
***初步理解:***相对于BP,BPTT中损失对参数的梯度求解时多考虑了"时间"因素。
∂ L ∂ W h h = ∑ t = 1 T ∂ L ∂ h t ⋅ ∂ h t ∂ W h h \frac{\partial L}{\partial W_{hh}} = \sum_{t=1}^{T} \frac{\partial L}{\partial h_t} \cdot \frac{\partial h_t}{\partial W_{hh}} ∂Whh∂L=t=1∑T∂ht∂L⋅∂Whh∂ht
那就需要再加上一个损失函数对W_hh的导数:
∂ L ∂ W h h = ∂ L ∂ h 3 ⋅ ∂ h 3 ∂ h 2 ⋅ ∂ h 2 ∂ h 1 ⋅ ∂ h 1 ∂ W h h \frac{\partial L}{\partial W_{hh}} \; = \frac{\partial L}{\partial h_3} \cdot \frac{\partial h_3}{\partial h_2} \cdot \frac{\partial h_2}{\partial h_1} \cdot \frac{\partial h_1}{\partial W_{hh}} ∂Whh∂L=∂h3∂L⋅∂h2∂h3⋅∂h1∂h2⋅∂Whh∂h1
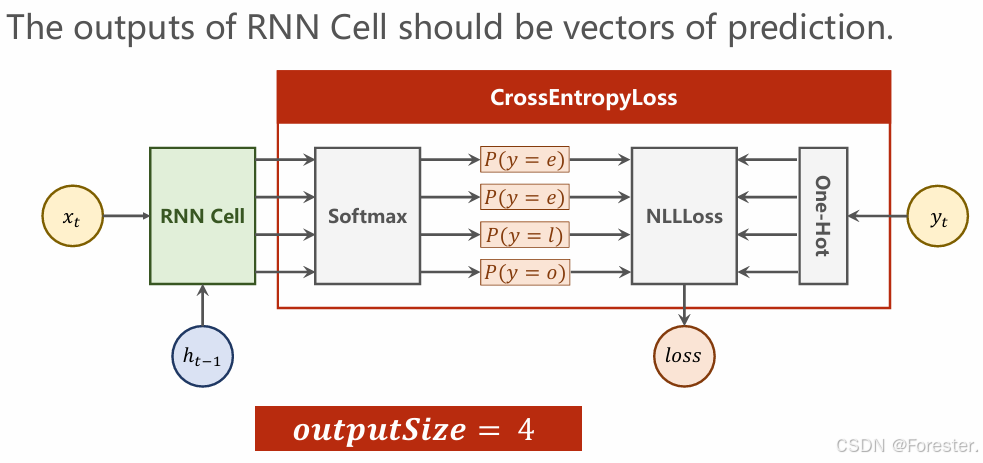
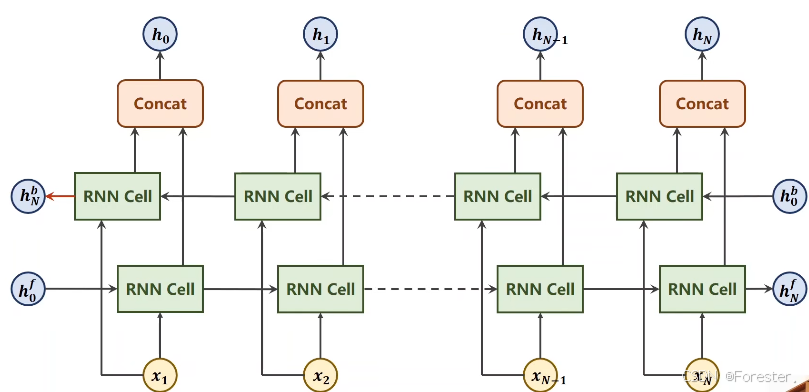
该隐藏层输出为:
h i d d e n = h N f , h N b hidden=h_N\^f,h_N\^b hidden=hNf,hNb
5.3 GRU
5.3.1 GRU的提出
对于RNN,BPTT时很容易导致梯度消失或爆炸,使模型难以记住长序列信息。
Think-Help
++RNN的特殊问题++
我们先回顾一下梯度消失和爆炸两种情况:
在所有神经网络中,反向传播的梯度更新都要用链式法则:
∂ L ∂ W = ∂ L ∂ h n ⋅ ∂ h n ∂ h n − 1 ⋅ ∂ h n − 1 ∂ h n − 2 ⋅ ... ⋅ ∂ h 1 ∂ W \frac{\partial L}{\partial W} = \frac{\partial L}{\partial h_n} \cdot \frac{\partial h_n}{\partial h_{n-1}} \cdot \frac{\partial h_{n-1}}{\partial h_{n-2}} \cdot \ldots \cdot \frac{\partial h_1}{\partial W} ∂W∂L=∂hn∂L⋅∂hn−1∂hn⋅∂hn−2∂hn−1⋅...⋅∂W∂h1
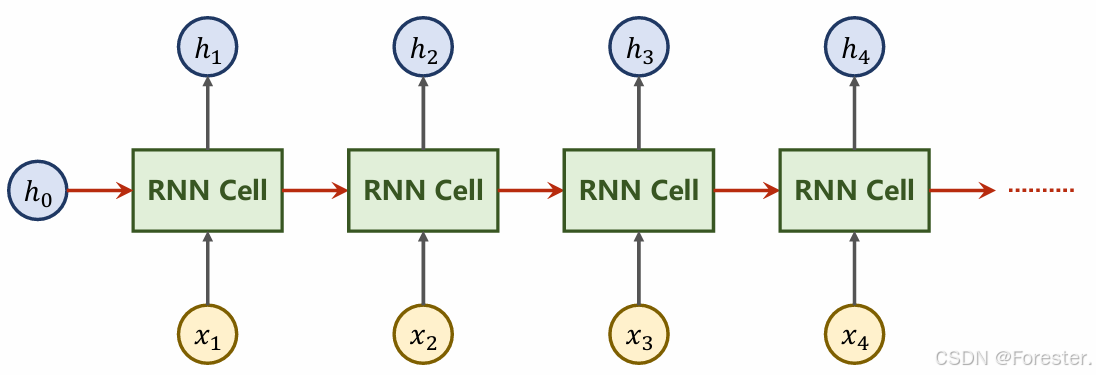
例如一个长度为 100 的序列,RNN 展开后就是 100 层的"共享权重网络":
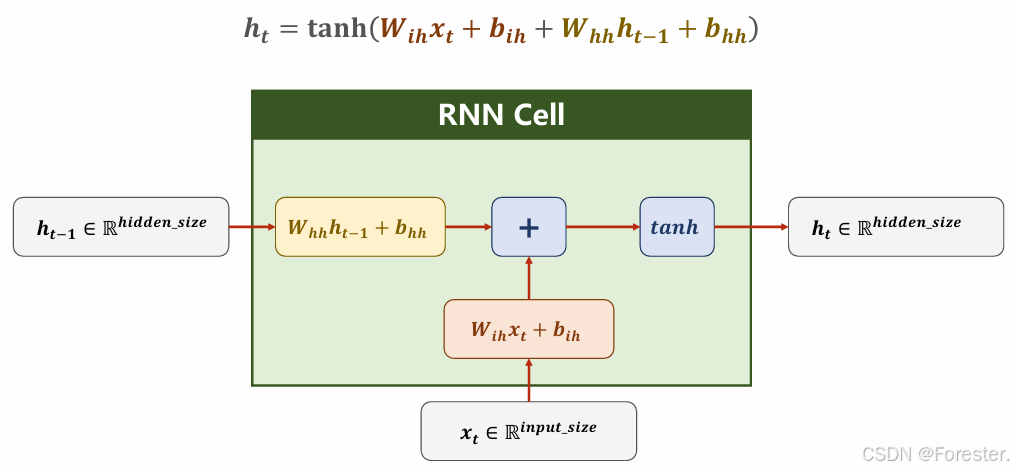
h t = f ( W h h h t − 1 + W x h x t ) h_t = f(W_{hh}h_{t-1} + W_{xh}x_t) ht=f(Whhht−1+Wxhxt)
反向传播时梯度链路是:
∂ L ∂ W h h ∝ ∏ t = 1 T ∂ h t ∂ h t − 1 \frac{\partial L}{\partial W_{hh}} \propto \prod_{t=1}^{T} \frac{\partial h_t}{\partial h_{t-1}} ∂Whh∂L∝t=1∏T∂ht−1∂ht
于是人们提出了改进版 ------ GRU(门控循环单元)【Gated Recurrent Unit = 有门的循环单元】
首先给定完整公式:
z t = σ ( W z x t + U z h t − 1 ) 更新门 r t = σ ( W r x t + U r h t − 1 ) 重置门 h ~ t = tanh ( W h x t + U h ( r t ⊙ h t − 1 ) ) 候选新状态 h t = ( 1 − z t ) ⊙ h t − 1 + z t ⊙ h ~ t 最终输出 \begin{aligned} z_t &= \sigma(W_z x_t + U_z h_{t-1}) && \text{更新门} \\ r_t &= \sigma(W_r x_t + U_r h_{t-1}) && \text{重置门} \\ \tilde{h}t &= \tanh(W_h x_t + U_h (r_t \odot h{t-1})) && \text{候选新状态} \\ h_t &= (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t && \text{最终输出} \end{aligned} ztrth~tht=σ(Wzxt+Uzht−1)=σ(Wrxt+Urht−1)=tanh(Whxt+Uh(rt⊙ht−1))=(1−zt)⊙ht−1+zt⊙h~t更新门重置门候选新状态最终输出
 🤸♂️生活座右铭:勤而拂拭,莫染尘埃。 📚学习座右铭:一切烦恼来源于定义不清。 🙌留言:有任何问题欢迎交流学习,直接私信即可,一定会回!👌
🤸♂️生活座右铭:勤而拂拭,莫染尘埃。 📚学习座右铭:一切烦恼来源于定义不清。 🙌留言:有任何问题欢迎交流学习,直接私信即可,一定会回!👌