

🔥@晨非辰Tong: 个人主页
👀专栏:《C语言》、《数据结构与算法入门指南》
💪学习阶段:C语言、数据结构与算法初学者
⏳"人理解迭代,神理解递归。"
文章目录
- 引言
- [一、 计数排序的理念精髓:什么是"以数为据"?](#一、 计数排序的理念精髓:什么是“以数为据”?)
-
- [1.1 计数排序的"异类"的体现](#1.1 计数排序的“异类”的体现)
- 二、计数排序的底层逻辑:"统计与映射"取代比较?
-
- [2.1 算法逻辑:简单起步,理解计数统计](#2.1 算法逻辑:简单起步,理解计数统计)
- [2.2 算法逻辑:进阶核心,掌握映射定位](#2.2 算法逻辑:进阶核心,掌握映射定位)
- 三、计数排序的性能优势:"非比较"如何带来线性时间?
-
- [3.1 算法核心:时间O(n+k) 的深度解读](#3.1 算法核心:时间O(n+k) 的深度解读)
- 总结
引言
计数排序是排序算法中的"异类"------它不通过比较元素大小,而是通过统计计数来实现排序。这种基于"鸽巢原理"的独特思路,让它在特定场景下能达到惊人的线性时间复杂度
O(n+range)。本文将从基础原理出发 ,通过C语言实战代码,详细讲解计数排序的"统计-映射-回收"核心步骤,帮助您彻底掌握这种高效排序算法的实现技巧和应用场景。
一、 计数排序的理念精髓:什么是"以数为据"?
1.1 计数排序的"异类"的体现
计数排序是一种非比较排序算法。顾名思义,它的核心思想不是通过比较元素的大小来确定顺序,而是通过计数 的方式来实现排序。
计数排序别名又叫"鸽巢原理",其本质体现是:如果鸽子的数量比鸽巢多,那么至少有一个鸽巢里面不止一个鸽子 。那么就引出排序原理:将数组本身作为数组的索引,通过统计每个整数出现的次数,来直接确定每个整数在排序后的数组中的正确位置。
| 特性维度 | 比较排序 | 非比较排序 |
|---|---|---|
| 核心原理 | 通过比较元素之间的相对大小来确定元素位置 | 利用算术运算、映射等特定数据本身的性质来确定位置 |
| 决策基础 | 元素间的序关系 | 元素本身的实际值 |
| 代表性算法 | 快速排序、归并排序、堆排序 | 计数排序 |
| 使用场景 | 通用场景,数据范围大或类型复杂 | 数据有明显特征,整数、范围小 |
二、计数排序的底层逻辑:"统计与映射"取代比较?
在这里,你将会看到的是最全面、最系统地对计数排序的算法思路的解释(附图解)。
操作步骤:
- 统计数组中相同元素出现的次数;
- 根据统计结果将序列回收到原序列中;
2.1 算法逻辑:简单起步,理解计数统计
为了能够将计数排序操作步骤先理解清楚,先从一个较为简单的数组arr[6,1,2,4,9,4,2,4,1,4],演示从统计相同数据重复出现的次数到回归原数组全过程。
图示如下:
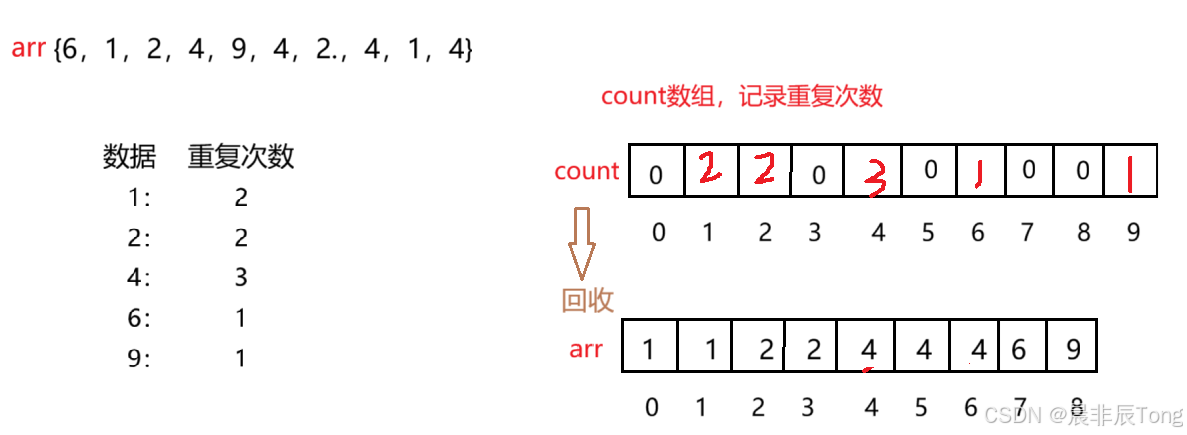
过程剖析(大致思路):
- 先进行一次循环遍历原数组的每个元素,同时将每个元素出现的次数进行记录------>这就是所谓的"统计 "操作。
- 下一步就是将记录到的每个元素出现的次数存放在新创建的数组
count中(当然要根据数据与count数组下标进行匹配后再进行存放,存放结果如上图)。
c
int arr[n] = {//.....//};
int count[a] = {//.....//};
//遍历统计
for(int i = 0; i < n; i++)
{
//将原数组元素作为下标,这就实现了数据与下标匹配
count[arr[i]]++;
}- 整个过程的最后,再次进行循环遍历,但这次遍历的对象是
count数组。由于未涉及到的数据在count数组中体现为0,等遍历到!0时就将当前位置的下标数字(原数组数据)放入原数组(注意,此操作也是循环内)。
c
//......
int index = 0;//定义下标变量
for(int i = 0; i < a; i++)
{
while(count[i]--)
{
//这里的i就是count数组的下标-->数据
arr[index++] = i;
}
}关键点解析(精准定位):
count数组的大小是如何确定的?
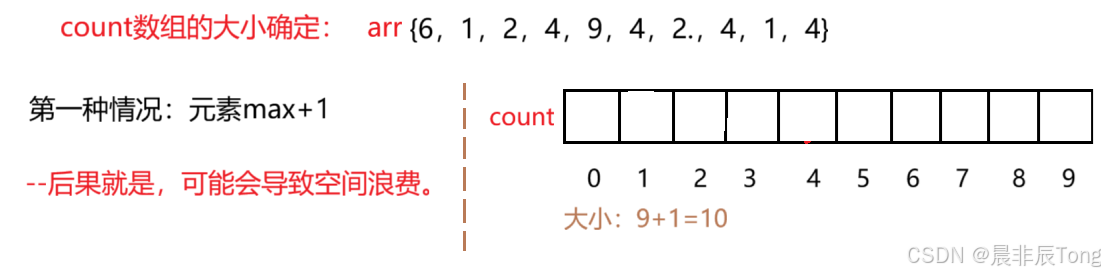
第一种 :在上面的思路中:是数组arr的数据对应着数组count 的下标存放出现次数。那么很容易想到------>原数组元素max+1(数组下标从0开始,max 对应最大下标,空间大小就是max+1)来申请count数组的大小。
C语言代码实战:
--大家自行将代码分文件(其中打印函数代表不在演示)。
c
//非比较排序------计数排序
void CountSort(int* arr, int n)
{
//找最大值
int max = arr[0];
for (int i = 0; i < n; i++)
{
if (arr[i] > max)
{
max = arr[i];
}
}
//确定count数组的空间大小
int range = max + 1;
int* count = (int*)malloc(sizeof(int) * range);
if (count == NULL)
{
perror("malloc fail");
exit(1);
}
//因为malloc,先对数组初始化
memset(count, 0, sizeof(int) * (range));
//进行"统计"
for (int i = 0; i < n; i++)
{
count[arr[i]]++;//确定大小的第一种情况
}
//"回收"
int index = 0;
for (int i = 0; i < range; i++)
{
//当count数组元素!0在进入
while (count[i]--)
{
//数据匹配下标,将下标存放
arr[index++] = i;
}
}
}
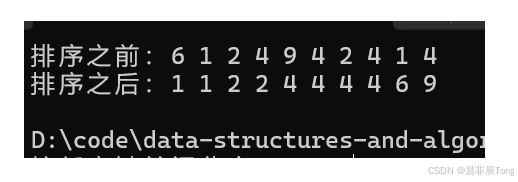
test01()
{
int arr[] = {6, 1, 2, 4, 9, 4, 2, 4, 1, 4};
int n = sizeof(arr) / sizeof(arr[0]);
printf("排序之前:");
PrintArr(arr, n);
//计数排序
QuickSort(arr, 0, n - 1);
CountSort(arr, n);
printf("排序之后:");
PrintArr(arr, n);
}
2.2 算法逻辑:进阶核心,掌握映射定位
关键点解析(精准定位):
count数组的大小是如何确定的?
第二种 :当使用范围跨度较大原数组时,第一种申请数组count的空间大小,会造成空间的浪费。
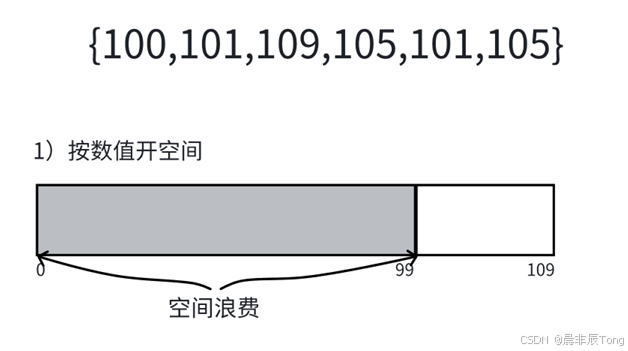
根据图示,原数组为{100,101,109,105,101,105},这样申请的数组从下标0开始到下标109结束,前面的 0~99 的空间全部浪费,这样就不太好。
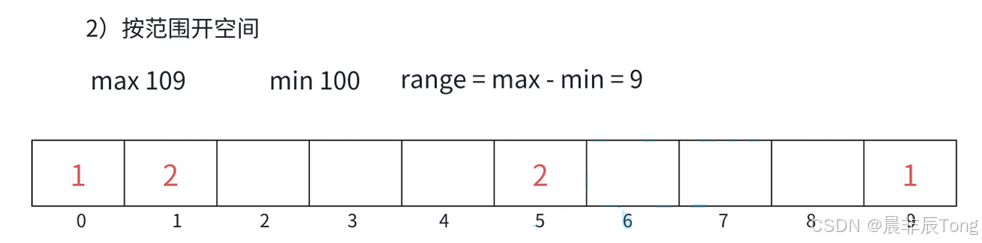
如果只考虑为100~109申请对应数量的空间------>max-min +1,那么存放数据就用到了"映射"。这里先给出"映射"公式:data-min;使用原因:前面大小范围确定了,就要对应下标放入统计的次数。使用"映射",就将计数数组的元素压缩到仅与数据的范围(max - min + 1) 的索引有关。

C语言代码实战(修改版)
c
//2.
void CountSort(int* arr, int n)
{
//找最大值、最小值
int max = arr[0], min = arr[0];
for (int i = 0; i < n; i++)
{
if (arr[i] < min)
{
min = arr[i];
}
if (arr[i] > max)
{
max = arr[i];
}
}
//确定count数组的空间大小
int range = max -min + 1;
int* count = (int*)malloc(sizeof(int) * range);
if (count == NULL)
{
perror("malloc fail");
exit(1);
}
//因为malloc,先对数组初始化
memset(count, 0, sizeof(int) * (range));
//进行"统计"、映射
for (int i = 0; i < n; i++)
{
count[arr[i] - min]++;//确定大小的第二种情况
}
int index = 0;
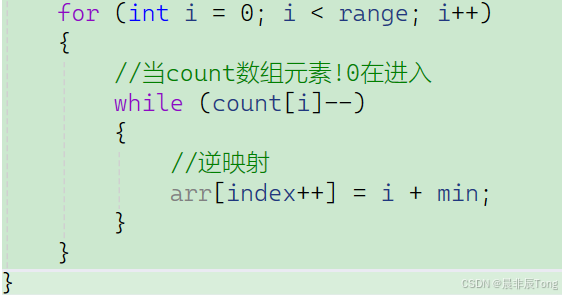
for (int i = 0; i < range; i++)
{
while (count[i]--)
{
//逆映射
arr[index++] = i + min;
}
}
}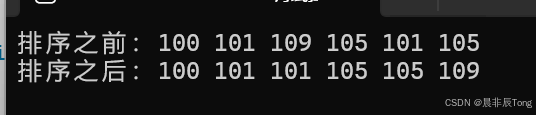
计数排序的最终版------>"映射",非常完美。
三、计数排序的性能优势:"非比较"如何带来线性时间?
计数排序的特性:
- 计数排序在数据范围集中时,效率很高,但是适用范围以及场景有限;
- 时间复杂度:O(n+range) 空间复杂度:O(range);
- 稳定性:稳定。
3.1 算法核心:时间O(n+k) 的深度解读
我们以第二版实现的代码为例,剖析计数排序的时间复杂度。

代码中第一个for循环,循环次数取决于原数组元素个数,时间复杂度:O(N)。

代码中第二个for循环,循环次数又是取决于原数组大小,并且两个循环为并列关系,所以前两个循环的时间复杂度:O(N)。
这次的循环就比较特殊,因为循环次数取决于range = max- min + 1,由输入数据的值域范围决定,并且这个范围可以独立于数据量 n 发生巨大变化,必须将它作为一个独立的变量来考虑。时间复杂度:O(N + range)。
- 数据
max,min差距较小。场景一:对 1,000,000 个人的年龄进行排序
- n (数据量) = 1,000,000;
- min = 0, max = 150 ;
- range (范围) = 150 - 0 + 1 = 151;
- 时间复杂度 O(n + range ) = O(1,000,000 + 151) ≈ O(n) ;
- 结论:非常高效,因为
range很小且固定。
- 数据
max,min差距较大。场景二:对 10 个随机整数排序,数值在 0 到 1,000,000,000 之间
- n (数据量) = 10;
- min = 0, max = 1,000,000,000 (假设);
- k (范围) = 1,000,000,000 - 0 + 1 = 1,000,000,001;
- 时间复杂度 O(n + k) = O(10 + 1,000,000,001) ≈ O(k) ;
- 结论:极其低效,虽然只有10个数据,但
range巨大无比
核心洞察
计数排序的效率不取决于你有多少数据,而取决于你的数据"分散"在多大的范围内。
系列博客 :
归并排序全透视:从算法原理全分析到源码实战应用
排序详解:从快速排序分区逻辑,到携手冒泡排序的算法效率深度评测
总结
html
🍓 我是晨非辰Tong!若这篇技术干货帮你打通了学习中的卡点:
👀 【关注】跟我一起深耕技术领域,从基础到进阶,见证每一次成长
❤️ 【点赞】让优质内容被更多人看见,让知识传递更有力量
⭐ 【收藏】把核心知识点、实战技巧存好,需要时直接查、随时用
💬 【评论】分享你的经验或疑问(比如曾踩过的技术坑?),一起交流避坑
🗳️ 【投票】用你的选择助力社区内容方向,告诉大家哪个技术点最该重点拆解
技术之路难免有困惑,但同行的人会让前进更有方向~愿我们都能在自己专注的领域里,一步步靠近心中的技术目标!结语:
计数排序是一种高效的非比较型排序算法,通过统计每个元素的出现频率来确定其在输出数组中的位置。算法步骤包括:统计频率、计算位置、放置元素。时间复杂度为O(n+range)线性时间。适用于小范围整数排序但需要提前知道数据范围,大范围数据可能消耗较多内存。
随着计数排序的学习完成,我们的"数据结构主线系统学习"也告一段落。这段系统学习让我们从基础的线性结构(数组、链表)到复杂的树形结构(二叉树、堆),逐步构建了完整的数据结构知识体系。重要的是,我们培养了算法思维,理解时空复杂度的权衡,掌握从理论到实践的完整实现流程。
