之前介绍过如何使用 INFINI Gateway迁移数据,但是迁移的是整个索引的全量数据。如果我只想迁移符合查询条件的数据,该怎么做呢?别小看这个需求,因为有了这个功能再结合时间条件检索,我们就能实现增量数据迁移,当然前提是数据有时间字段。
话不多说,我们来 demo 。
测试环境
|---------------|--------|
| 软件 | 版本 |
| Easysearch | 1.13.1 |
| Elasticsearch | 7.10.2 |
| Gateway | 1.29.8 |
迁移实战
迁移步骤与之前一样,只是 Gateway 配置里多了查询条件。
pipeline 部分我们增加 query_dsl 写入过滤条件。
pipeline:
- name: source_scroll
auto_start: true
keep_running: false
processor:
- es_scroll:
slice_size: 1
batch_size: 5000
indices: "nginx"
elasticsearch: source
output_queue: source_index_dump
partition_size: 1
scroll_time: "5m"
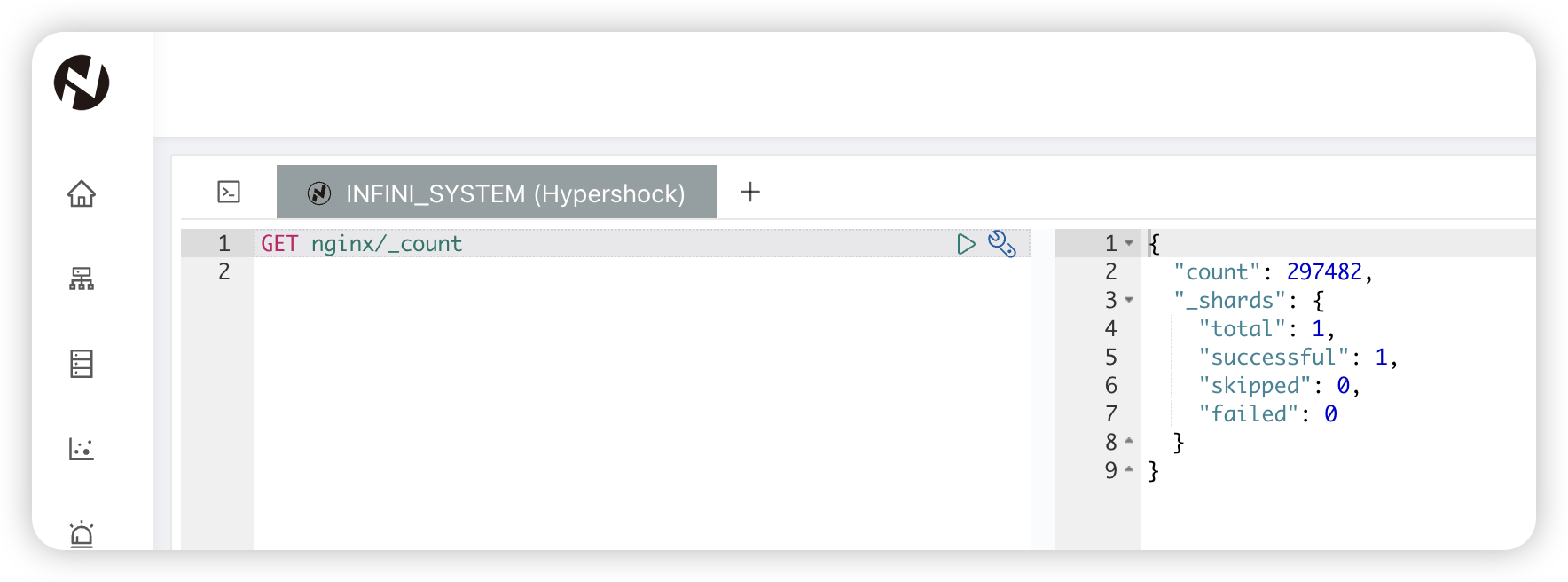
query_dsl: "{ \"query\": { \"bool\": { \"filter\": [ { \"range\": { \"timestamp\": { \"gte\": \"2024-11-16T23:59:50+08:00\", \"lte\": \"2024-11-16T23:59:59+08:00\" } } } ] } }}"我们先看看源端 nginx 索引全量数据有多少,297482 条。
再看看 nginx 索引中符合查询条件的文档有多少,21 条。
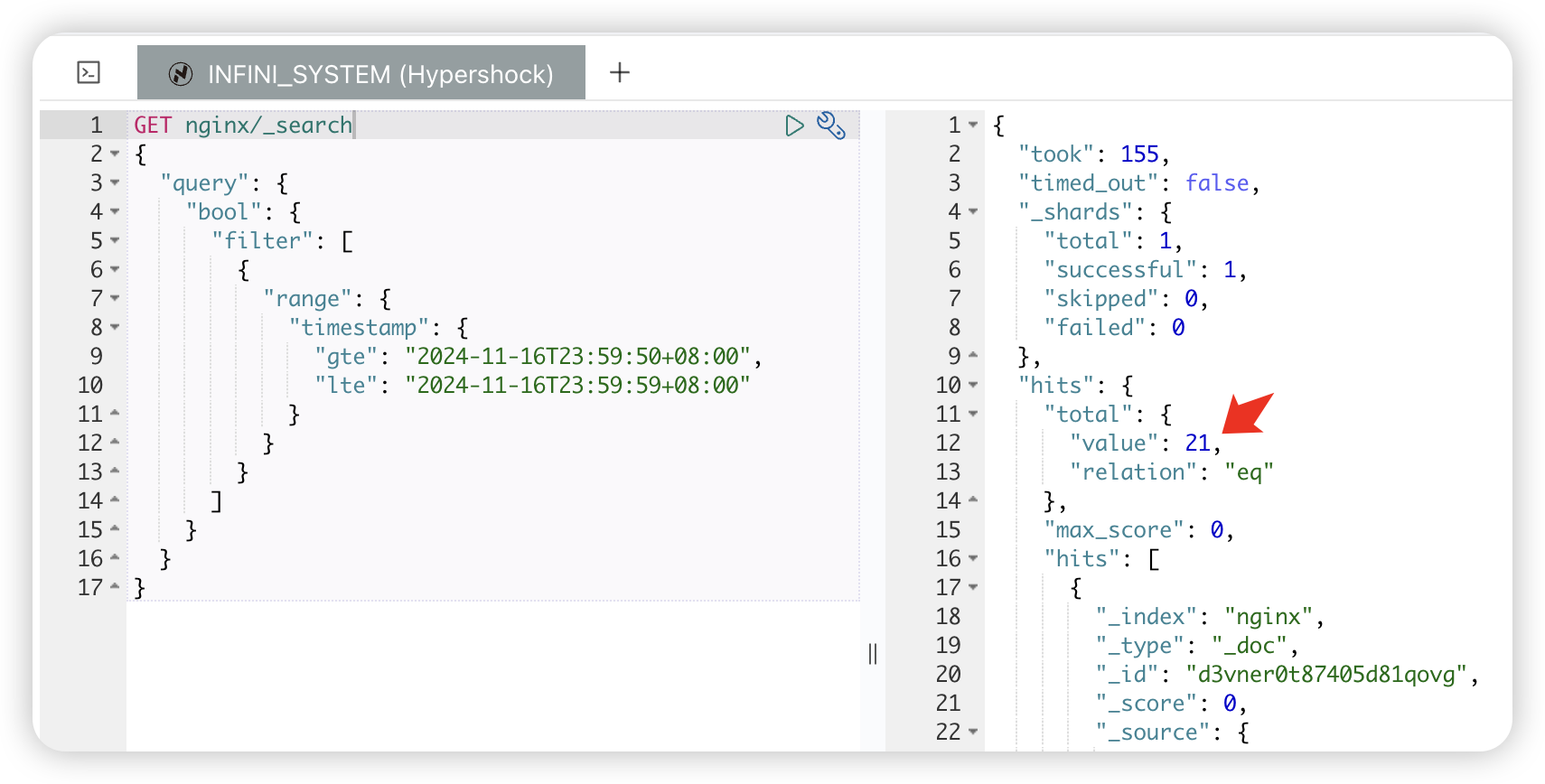
也就是说这次我们只会迁移 21 条数据,运行 Gateway 进行"增量"数据迁移。

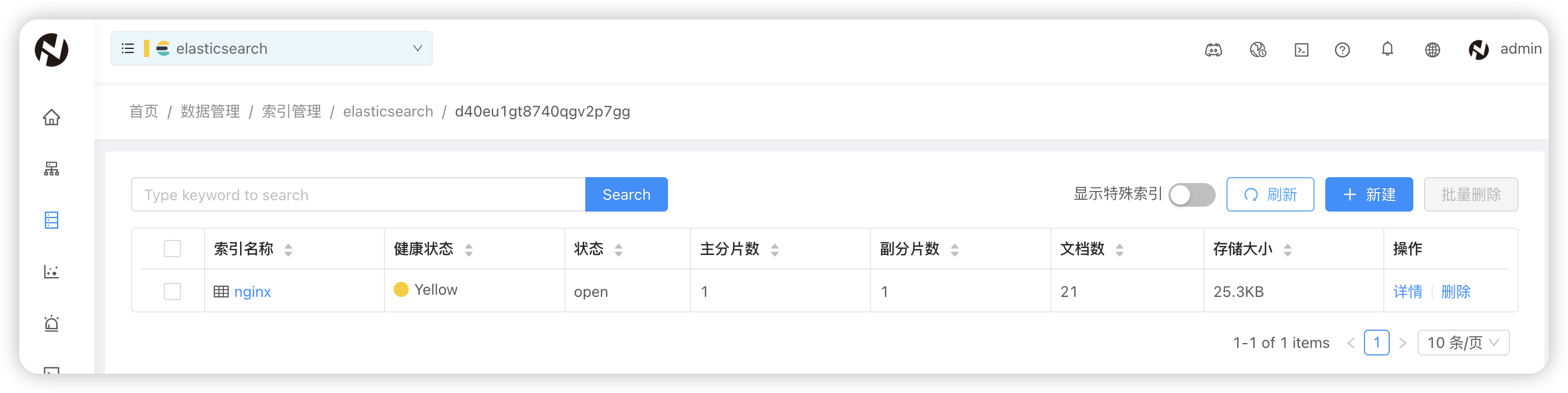
迁移完成。结合查询条件可以使 INFINI Gateway 更加灵活,当然 Gateway 还有更多实用功能,欢迎大家查阅官方文档。