1. 基本信息

-
标题: Run, Don't Walk: Chasing Higher FLOPS for Faster Neural Networks
2. 核心创新点
-
颠覆传统优化思路:论文指出,单纯降低浮点运算量(FLOPs)不一定能带来同等程度的延迟降低。实现网络加速的关键在于提升单位时间内的有效计算速度,即每秒浮点运算次数(FLOPS)。
-
提出新型高效算子PConv:为解决深度可分离卷积(DWConv)因频繁内存访问导致的低FLOPS问题,论文提出了一种全新的部分卷积(Partial Convolution, PConv)。该算子仅对部分输入通道进行卷积,从而同时减少了冗余计算和内存访问,实现了更高的硬件利用效率。
-
构建极简高速网络FasterNet:基于PConv,论文设计了一个新的通用网络家族FasterNet。该网络架构简洁,没有复杂的模块,却能在GPU、CPU和ARM等多种硬件平台上实现顶尖的推理速度,同时在各类视觉任务上保持高精度。
➔➔➔➔点击查看原文,获取本文及其他精选即插即用模块集合![]() https://mp.weixin.qq.com/s/I9bw6kt_yjTijlIcBYZxpA
https://mp.weixin.qq.com/s/I9bw6kt_yjTijlIcBYZxpA
3. 方法详解
整体结构概述
FasterNet是一个分层的网络架构,共包含四个阶段(Stage)。数据首先通过一个嵌入层(Embedding Layer,一个步长为4的4x4卷积)进行降采样和通道扩展。接着,数据依次流经四个阶段。每个阶段都由一个用于空间降采样和通道扩展的归并层(Merging Layer,一个步长为2的2x2卷积)和一堆FasterNet模块构成。论文发现网络后两个阶段的内存访问较少且FLOPS更高,因此将更多的计算量(即堆叠更多的FasterNet模块)分配给了后两个阶段。最后,通过全局平均池化、1x1卷积和全连接层进行分类。
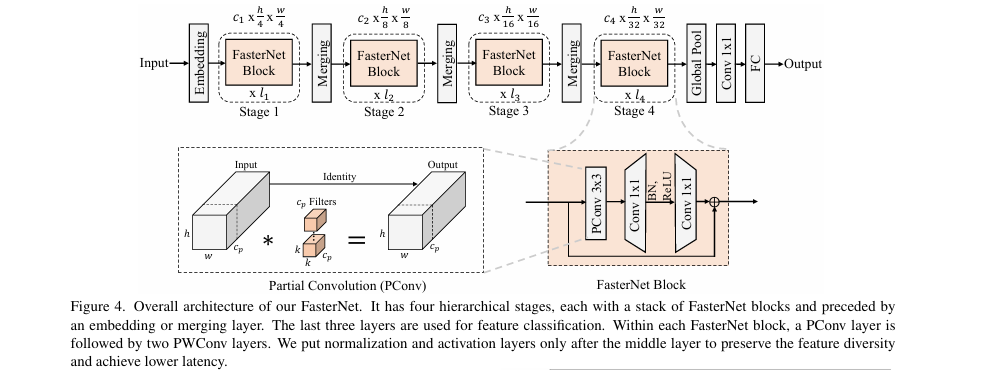
步骤分解
-
部分卷积 (PConv) 的设计:
-
动机: 论文观察到深度可分离卷积(DWConv)虽然FLOPs低,但为了维持精度需要扩展通道数,这导致内存访问量(Memory Access)剧增,从而使得有效计算速度(FLOPS)极低。同时,特征图在通道维度上存在大量冗余(如论文图3所示)。
-
原理 : PConv利用特征图的冗余性,只对一部分连续的输入通道(例如前1/4的通道,即
c_p个)应用常规卷积进行空间特征提取,而其余通道保持不变。 -
优势 : 相比常规卷积,PConv的FLOPs和内存访问量都大幅降低。以部分率
r = c_p/c = 1/4为例,其FLOPs仅为常规卷积的1/16,内存访问量仅为1/4。 -
FLOPs:
-
内存访问量:
-
-
PConv 与 PWConv 的结合:
-
为了有效利用所有通道的信息,PConv之后紧跟一个逐点卷积(Pointwise Convolution, PWConv,即1x1卷积)。
-
这种"PConv + PWConv"的组合,其有效感受野在输入特征图上呈现出"T"形(如图5 所示),相比于常规卷积,更加关注中心位置的特征。论文通过对预训练ResNet18的卷积核进行分析,发现卷积核的中心位置权重最高,从而验证了这种"T"形计算模式的合理性(如图6所示)。
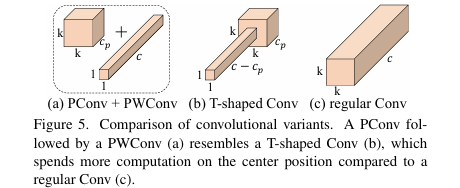

- 将T形卷积分解为PConv和PWConv两步,比直接实现T形卷积更节省计算量。
-
FasterNet 模块:
-
每个FasterNet模块由一个PConv和两个PWConv组成,构成了一个倒置残差结构(Inverted Residual Block)。
-
中间的PWConv用于扩展通道维度,并在其后接一个归一化层(BN)和激活函数(ReLU或GELU)。
-
该模块只在中间层之后使用归一化和激活,旨在保留特征多样性并降低延迟。BN层在推理时可以与卷积层融合,进一步加速。
-
-
FasterNet 整体架构:
-
分层设计: 包含4个阶段,通过归并层(Merging Layer)逐步降低空间分辨率、增加通道数。
-
模块分布: 更多的FasterNet模块被放置在网络的后两个阶段,以平衡计算负载。
-
分类头: 由全局平均池化、1x1卷积和全连接层组成,用于最终的特征变换和分类。
-
4. 即插即用模块作用
此部分主要分析核心组件 PConv 的作用。
适用场景
PConv作为一个基础算子,旨在替代现有网络中用于提取空间特征的卷积层,特别是深度可分离卷积(DWConv)。
-
通用视觉任务: 图像分类、目标检测、实例分割等。
-
轻量化网络设计: 可用于构建在移动设备(如ARM处理器)、CPU或GPU上要求低延迟、高吞吐量的模型。
-
模型加速: 可作为即插即用的模块,替换现有CNN模型(如ResNet、MobileNet等)中的DWConv或常规卷积,以提升其运行速度。
主要作用
PConv为模型设计和部署带来了直接的价值。
-
模拟/替代DWConv能力: PConv同样用于高效地提取空间特征,但避免了DWConv高内存访问和低FLOPS的陷阱。
-
大幅降低延迟和内存访问: 通过只处理部分通道,PConv直接减少了计算和数据搬运的开销,从而在各类硬件上实现更快的推理速度(如论文表1所示,PConv的FLOPS远高于DWConv)。
-
增强硬件利用率: 相比DWConv,PConv通过实现更高的FLOPS,能够更充分地利用设备的计算能力,将理论上的低FLOPs更有效地转化为实际的低延迟。
-
增强可部署性: 基于PConv构建的FasterNet架构简单,不依赖于特殊的硬件支持,使其在从服务器GPU到边缘设备ARM的多种平台上都具有普遍的高速性能。
总结
PConv是一种简单、高效且硬件友好的卷积算子,它通过利用特征冗余,以"部分处理"的智慧有效破解了"低FLOPs≠低延迟"的难题,是设计下一代高速神经网络的理想选择。
➔➔➔➔点击查看原文,获取本文及其他精选即插即用模块集合![]() https://mp.weixin.qq.com/s/I9bw6kt_yjTijlIcBYZxpA
https://mp.weixin.qq.com/s/I9bw6kt_yjTijlIcBYZxpA